记2018最后一次问题诊断-Spark on Yarn所有任务运行失败
2018的最后一个工作日,是在调式和诊断问题的过程中度过,原本可以按时下班,毕竟最后一天了,然鹅,确是一直苦苦挣扎。
废话不多说,先描述一下问题:有一套大数据环境,是CDH版本的,总共4台机子,我们的应用程序与大数据集群之前已经集成完毕,调试没有问题,可以运行Spark任务。而与这个集群集成是17年下半年的事了,这次升级后,发现无法正确的执行任务,不管是程序提交的还是用示例程序SparkPi,或者手动用spark-submit提交,都是执行失败,且Yarn框架调度执行两次。主要错误提示如下:
- Diagnostics: java.lang.NoSuchMethodError: org.apache.commons.io.FileUtils.isSymlink(Ljava/io/File;)Z
截图如下:
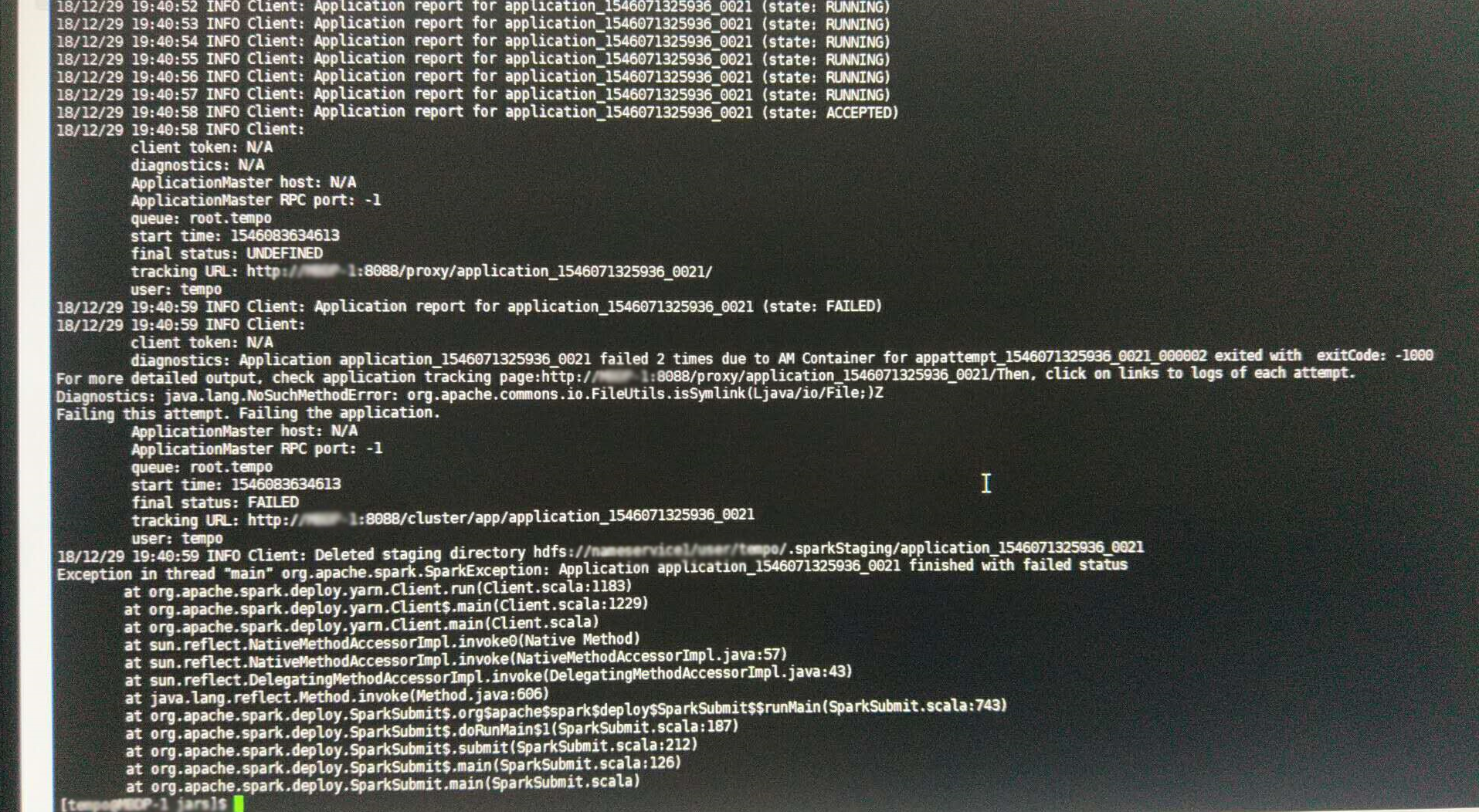
sprak-submit提交客户端日志截图
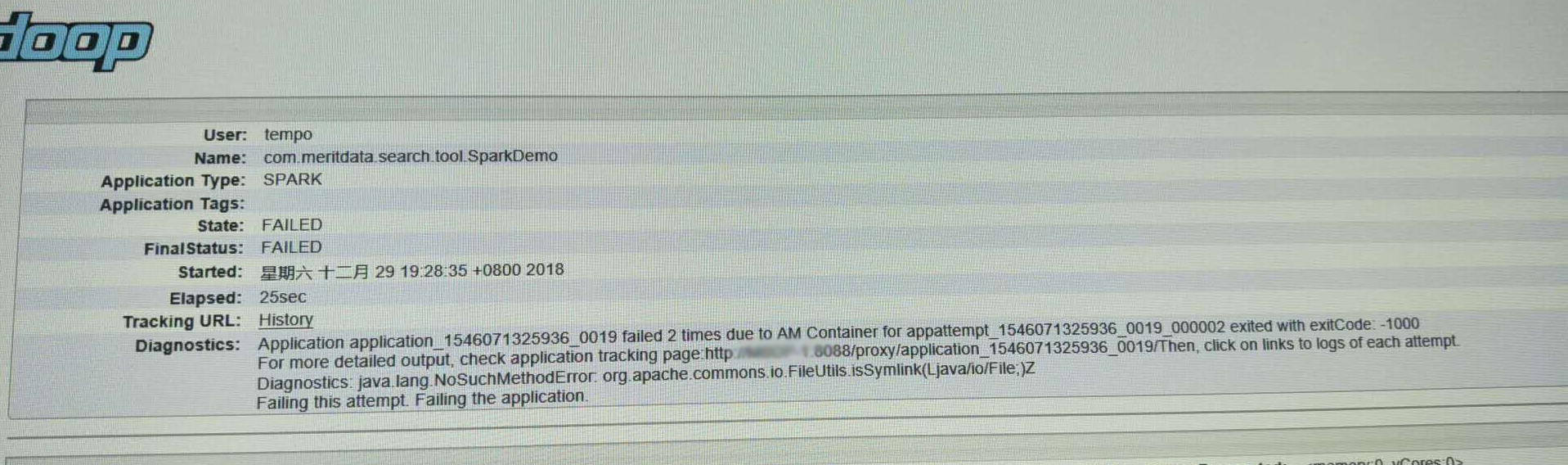
yarn:8088任务监控页面任务(与上图不是一个任务,但错误信息一致)
其实,从任务日志错误提示,可以看出,肯定是加载了低版本的包,用了高版本的方法,NoSuchMethod异常再也熟悉不过了,这一点确信后,就需要找这个包在哪里?FileUtils类属于commons-io包,目前有1.4和2.4版本的,其中,1,4中的FileUtils类确实没有isSymlink方法。好了,基本可以确认,程序在使用了这个commons-io-1.4.jar包。
虽然问题确认,但是还是让人很头疼,因为我可以确认,我们自己的应用程序中,只用了2.4的包。为了排序一些常规影响,我们分别使用cdh自带的sparka提交、使用最简单的SparkPi来运行,但都运行失败,并且我还写了一个搜索类所在的包的工具,来运行排查问题。
- package com.meritdata.search.tool;
- import java.io.PrintStream;
- import java.security.CodeSource;
- import java.security.ProtectionDomain;
- public class Utils
- {
- public static void search(String name)
- {
- try
- {
- Class clazz = Class.forName(name);
- ProtectionDomain pd = clazz.getProtectionDomain();
- CodeSource cs = pd.getCodeSource();
- System.out.println(name + " location: " + cs.getLocation());
- }
- catch (Throwable e) {
- e.printStackTrace();
- }
- }
- }
- package com.meritdata.search.tool;
- public class Search
- {
- public static void main(String[] args)
- {
- String name = args[0];
- Utils.search(name);
- }
- }
这是最先开始使用的代码,想验证当前任务加载的包是不是有其他的版本,使用提交命令:
- %SPARK_HOME%>.\bin\spark-submit.cmd --master --deploy cluster --files hive-site.xml --class com.meritdata.search.tool.Search search.tool-0.0.-SNAPSHOT.jar org.apache.commons.io.FileUtils
这个任务运行的结果,打印的是commons-io-2.4.jar。确认后再想,是不是其他地方引用,而这个demo比较简单,没有使用到,因为加载顺序不一样,可能会影响。所以,又完善了一下程序:
- package com.meritdata.search.tool;
- import java.util.Collections;
- import org.apache.spark.sql.Dataset;
- import org.apache.spark.sql.Encoders;
- import org.apache.spark.sql.SparkSession;
- import org.apache.spark.sql.SparkSession.Builder;
- public class SparkDemo
- {
- public static void main(String[] args)
- {
- try
- {
- SparkSession spark = SparkSession.builder().appName("SparkDemo").enableHiveSupport().getOrCreate();
- Dataset dataset = spark.createDataset(Collections.singletonList("test"), Encoders.STRING());
- dataset.show();
- spark.sql("SELECT explode(Array(\"a\", \"b\", \"c\")) as v ").show();
- } catch (Throwable e) {
- e.printStackTrace();
- }
- String name = args[0];
- Utils.search(name);
- }
- }
因为实际中,要使用spark,必须初始化SparkSession,这样运行完成spark的代码后,再看看打印的包名称。但是结果令人意外,在初始化SparkSession的时候,任务就异常了,错误信息如开头提示。这下,我终于确认,是Yarn服务加载了不该加载的jar包,这下,就要排查yarn加载的包了,除过应用自己,yarn还要加载默认的包,hadoop的,hdfs的,yarn的包,配置项为 yarn.application.classpath, 在CDH的配置界面可以搜索到,有默认配置,会加载hadoop的一些基础程序包。首先想到的是,肯定是这个路径下面加载了低版本的包,想清空试试运行,结果还不行,因为有默认值,不填写每用,后来才想到的,因为当时已经调试的懵逼了。
发现不过后,想着去服务器上面,看看那些地方都有1.4的包,使用搜索命令:
- find / -name commons-io-*.jar -type f
搜索结果如图:

在大数据集群的某个节点搜索到的结果
从搜索结果来看,在cdn的jars下面有个1.4的包,我想,会不会是这样包引起的呢?但是,我在其他的环境中也发现这个包,不可能是这个包引起的,要不然,都得有问题。既然这个包没有影响,任务加载的包也是正确的,哪到底是哪里的影响了任务的执行?
此时,这个问题已经搞得人头疼,尝试了却没有发现问题,明明很简单,就包冲突,却无法解决。在领导的提示下,替换1.4中的FileUtils类,看看到底是不是这个包的问题,也不管了,只能试试了,司马当活马医。修改完成,打包,在四个节点搜索所有的1.4包,准备替换。
突然,发现了一个让人惊喜的意外,在大数据集群的某个节点,在Hadoop的子目录,搜索到了一个1.4的包,而且不是软链接。
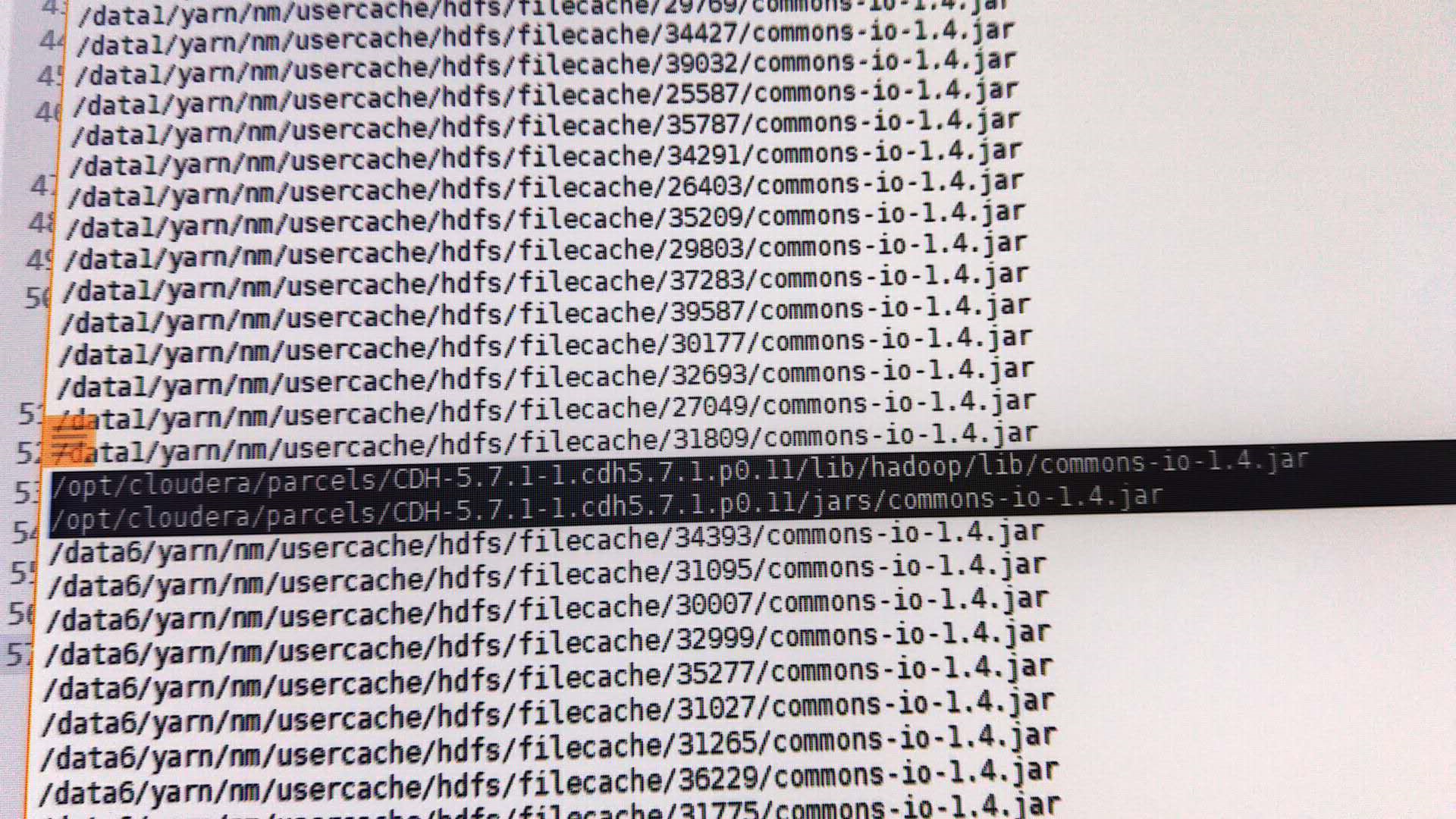
从搜索结果可以看出来,在执行的时候,每个任务下临时目录会复制jar包,hadoop/lib/commons-io-1.4.jar就是这个原因,查看其他节点,均为有类似情况。毫无疑问,删除这个包,重启集群,执行demo,成功,终于松了一口气。不知道是什么原因导致,现场环境复杂,所以也没办法追究,也没有必要,问题出现,就得解决。其实,很早之前,就应该检查四个节点,这样的话,就不会在那瞎想,可以尽早的发现异常包。
由于是客户现场,调试不方便,同事也比较辛苦,在现场的滋味,我深有体会。问题虽然简单,但是对整理的了解和调试方法也是很重要的,否则,会做很多无用功。
仅此来纪念和告别2018的辛勤工作,2019继续奋发前行,让自己更强。
本文地址:https://www.cnblogs.com/flowerbirds/p/10205185.html
记2018最后一次问题诊断-Spark on Yarn所有任务运行失败的更多相关文章
- Spark on YARN两种运行模式介绍
本文出自:Spark on YARN两种运行模式介绍http://www.aboutyun.com/thread-12294-1-1.html(出处: about云开发) 问题导读 1.Spark ...
- Spark on YARN简介与运行wordcount(master、slave1和slave2)(博主推荐)
前期博客 Spark on YARN模式的安装(spark-1.6.1-bin-hadoop2.6.tgz +hadoop-2.6.0.tar.gz)(master.slave1和slave2)(博主 ...
- Spark on Yarn 集群运行要点
实验版本:spark-1.6.0-bin-hadoop2.6 本次实验主要是想在已有的Hadoop集群上使用Spark,无需过多配置 1.下载&解压到一台使用spark的机器上即可 2.修改配 ...
- Spark On Yarn的两种模式yarn-cluster和yarn-client深度剖析
Spark On Yarn的优势 每个Spark executor作为一个YARN容器(container)运行.Spark可以使得多个Tasks在同一个容器(container)里面运行 1. Sp ...
- spark on yarn详解
1.参考文档: spark-1.3.0:http://spark.apache.org/docs/1.3.0/running-on-yarn.html spark-1.6.0:http://spark ...
- Spark on YARN模式的安装(spark-1.6.1-bin-hadoop2.6.tgz + hadoop-2.6.0.tar.gz)(master、slave1和slave2)(博主推荐)
说白了 Spark on YARN模式的安装,它是非常的简单,只需要下载编译好Spark安装包,在一台带有Hadoop YARN客户端的的机器上运行即可. Spark on YARN简介与运行wor ...
- Spark on YARN运行模式(图文详解)
不多说,直接上干货! 请移步 Spark on YARN简介与运行wordcount(master.slave1和slave2)(博主推荐) Spark on YARN模式的安装(spark-1.6. ...
- Spark(五十一):Spark On YARN(Yarn-Cluster模式)启动流程源码分析(二)
上篇<Spark(四十九):Spark On YARN启动流程源码分析(一)>我们讲到启动SparkContext初始化,ApplicationMaster启动资源中,讲解的内容明显不完整 ...
- Spark On YARN(Yarn-Cluster模式)启动流程源码分析(二)
转自:https://www.cnblogs.com/yy3b2007com/p/11087180.html 本章将针对yarn-cluster(--master yarn –deploy-mode ...
随机推荐
- mysql时间类型
转自:http://www.cnblogs.com/Matrix54/archive/2012/05/01/2478158.html AVA中获取当前系统时间 一. 获取当前系统时间和日期并格式化输出 ...
- luogu P1399 [NOI2013]快餐店
传送门 注意到答案为这个基环树直径\(/2\) 因为是基环树,所以考虑把环拎出来.如果直径不过环上的边,那么可以在环上每个点下挂的子树内\(dfs\)求得.然后如果过环上的边,那么环上的部分也是一条链 ...
- mysql复习(1)基本CRUD操作
一.这段时间在学校,把之前的东西都好好捡起来. 0.下面介绍Mysql的最基本的增删改查操作,很多IT工作者都必须掌握的命令,也是IT面试最常考的知识点.在进行增删改查之前,先建立一个包含数据表use ...
- python 查询Neo4j多节点的多层关系
需求:查询出满足3人及3案有关系的集合 # -*- coding: utf-8 -*- from py2neo import Graph import psycopg2 # 二维数组查找 def fi ...
- 录屏状态监听之防录屏 - iOS
继之前接到电话.短信和截屏监听需求之后,在 iOS 11.0 系统之上新增了屏幕录制的新功能玩法,所以也随之迎来了新的屏幕录制监听的需求,即防录屏功能监听 ... 通过官方文档得知 capturedD ...
- JavaEE高级-Spring学习笔记
*Spring是什么? - Spring是一个开源框架 - Spring为简化企业级应用开发而生.使用Spring可以使简单的JavaBean实现以前只有EJB才能实现的功能 - Spring是一个I ...
- 20140919-FPGA-有效观察设计中的差分信号
今天回来坐在电脑前,打开Xilinx的Documentation Navigator寻找NCO相关的User Guide,但是在不经意中发现了一个这样的IP,我感觉对于观察设计中的查分信号十分有用.之 ...
- PAT Advanced 1009 Product of Polynomials (25 分)(vector删除元素用的是erase)
This time, you are supposed to find A×B where A and B are two polynomials. Input Specification: Each ...
- 前端之JavaScript:JS之DOM对象一
js之DOM对象一 一.什么是HTML DOM HTML Document Object Model(文档对象模型) HTML DOM 定义了访问和操作HTML文档的标准方法 HTML DOM 把 ...
- Java 内存结构之虚拟机栈
2.虚拟机栈 定义:虚拟机栈(Java Virtual Machine Stacks)就是每个线程运行需要的内存空间,栈由一个一个的栈帧(Frame)组成,栈帧就是每个方法运行时需要的内存(方法的参数 ...