Scrapy学习(一)、Scrapy框架和数据流
Scrapy是用python写的爬虫框架,架构图如下:
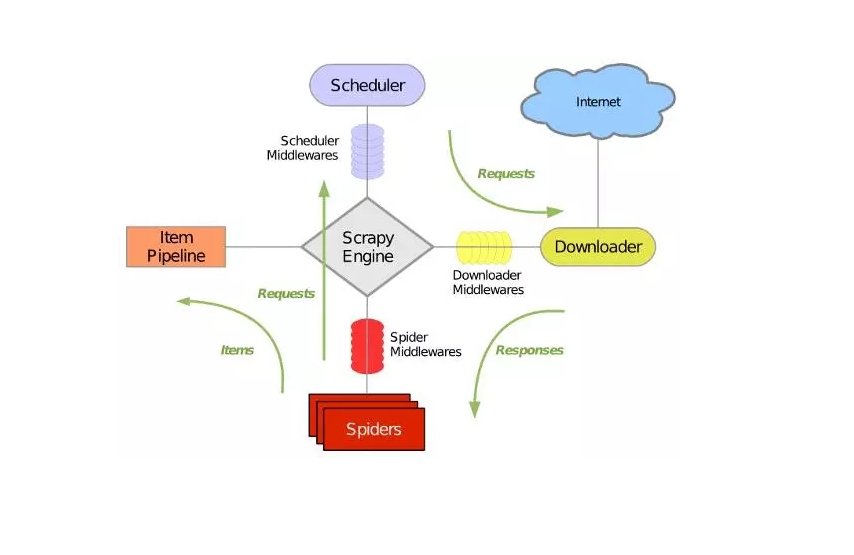
它可以分为如下七个部分:
1、Scrapy Engine:引擎,负责控制数据流在系统的所有组件中流动,并在相应动作发生时触发时间。
2、Scheduler:调度器,从引擎接收Request并将它们入队,以便引擎再次请求Request时提供给引擎。
3、Downloader:下载器,负责获取页面数据并提供给引擎,而后提供给Spiders。
4、Spider:爬虫,定义爬虫逻辑和解析规则,主要负责解析Response并生成提取结果(item)和新的请求(Request)。
5、Item Pipeline:管道,负责处理右Spider提取出来的结果(item)。主要任务是清洗,验证和存储数据。
6、Downloader middlewares:下载器中间件,位于引擎和下载器之间的特定钩子,处理引擎传给下载器的Request以及下载器传给引擎的Response。
7、Spider middlewares:爬虫中间件,位于引擎和爬虫之间的特定钩子,主要处理爬虫的输入(Response)和输出(Item和Request)
具体数据流如下:
1、引擎(Scrapy Engine)打开一个网站,找到处理该网站的Spider,并向该Spider请求第一个要爬取的URL
2、引擎(Scrapy Engine)从Spider中获取到第一个要爬取的URL后,通过调度器(Scheduler)以Request的形式调度
3、引擎(Scrapy Engine)向调度器(Scheduler)请求下一个要爬取的URL
4、调度器(Scheduler)返回下一个要爬取的URL给引擎(Scrapy Engine),引擎将该URL通过下载中间件(Downloader middlewares)转发给下载器(Downloader)
5、下载器(Downloader)下载页面,一旦页面下载完毕,下载器生成一个该页面的Response,并将其通过下载中间件(Downloader middlewares)发送给引擎
6、引擎(Scrapy Engine)从下载中间件(Downloader middlewares)接收Response,并将其通过爬虫中间件(Spider middlewares)发送给爬虫(Spider)处理
7、爬虫(Spider)处理Response,并返回处理的Item及新的Request给引擎
8、引擎(Scrapy Engine)将爬虫(Spider)返回的Item给管道(Item Pipeline),将新的Request给调度器(Scheduler)
9、重复第2步到第8步,直到调度器(Scheduler)中没有更多的Request,引擎(Scrapy Engine)关闭该网站,爬虫结束
Scrapy学习(一)、Scrapy框架和数据流的更多相关文章
- python爬虫学习之Scrapy框架的工作原理
一.Scrapy简介 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 其最初是为了 页面抓取 (更确切来说, 网 ...
- Python爬虫框架Scrapy学习笔记原创
字号 scrapy [TOC] 开始 scrapy安装 首先手动安装windows版本的Twisted https://www.lfd.uci.edu/~gohlke/pythonlibs/#twi ...
- python爬虫之Scrapy学习
在爬虫的路上,学习scrapy是一个必不可少的环节.也许有好多朋友此时此刻也正在接触并学习scrapy,那么很好,我们一起学习.开始接触scrapy的朋友可能会有些疑惑,毕竟是一个框架,上来不知从何学 ...
- 爬虫系列---scrapy post请求、框架组件和下载中间件+boss直聘爬取
一 Post 请求 在爬虫文件中重写父类的start_requests(self)方法 父类方法源码(Request): def start_requests(self): for url in se ...
- Scrapy学习篇(十)之下载器中间件(Downloader Middleware)
下载器中间件是介于Scrapy的request/response处理的钩子框架,是用于全局修改Scrapy request和response的一个轻量.底层的系统. 激活Downloader Midd ...
- scrapy 学习笔记1
最近一段时间开始研究爬虫,后续陆续更新学习笔记 爬虫,说白了就是获取一个网页的html页面,然后从里面获取你想要的东西,复杂一点的还有: 反爬技术(人家网页不让你爬,爬虫对服务器负载很大) 爬虫框架( ...
- scrapy学习(完全版)
scrapy1.6中文文档 scrapy1.6中文文档 scrapy中文文档 Scrapy框架 下载页面 解析页面 并发 深度 安装 scrapy学习教程 如果安装了anconda,可以在anacon ...
- scrapy学习笔记(二)框架结构工作原理
scrapy结构图: scrapy组件: ENGINE:引擎,框架的核心,其它所有组件在其控制下协同工作. SCHEDULER:调度器,负责对SPIDER提交的下载请求进行调度. DOWNLOADER ...
- Scrapy (网络爬虫框架)入门
一.Scrapy 简介: Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,Scrapy 使用了 Twisted['twɪstɪd](其主要对手是Tornado) ...
随机推荐
- CSP 俄罗斯方块(201604-2)
问题描述 俄罗斯方块是俄罗斯人阿列克谢·帕基特诺夫发明的一款休闲游戏. 游戏在一个15行10列的方格图上进行,方格图上的每一个格子可能已经放置了方块,或者没有放置方块.每一轮,都会有一个新的由4个小方 ...
- C# 面向对象5 this关键字和析构函数
this关键字 1.代表当前类的对象 2.在类当中显示的调用本类的构造函数(避免代码的冗余) 语法: ":this" 以下一个参数的构造函数调用了参数最全的构造函数!并赋值了那些不 ...
- C# 面向对象3 静态和非静态的区别
静态和非静态的区别 1.在非静态类中,既可以有实例成员(非静态成员),也可以有静态成员. 2.在调用实例成员的时候,需要使用对象名.实例成员; 在调用静态成员的时候,需要使用类名.静态成员名; 总结: ...
- JavaScript斑马线表格制作
//实现斑马线表格 //方法1: document.write('<table border="1">'); for(var i=1; i<11; i++){ i ...
- ccs之经典布局(三)(等分,等高布局)
接上篇ccs之经典布局(二)(两栏,三栏布局) 七.等分布局 等分布局是指一行被分为若干列,每一列的宽度是相同的值.两列之间有若干的距离. 1.float+padding+background-cli ...
- vue-router实现原理
vue-router实现原理 近期面试,遇到关于vue-router实现原理的问题,在查阅了相关资料后,根据自己理解,来记录下.我们知道vue-router是vue的核心插件,而当前vue项目一般都是 ...
- jQuery效果--淡入和淡出
jQuery Fading 方法 通过 jQuery,您可以实现元素的淡入淡出效果. jQuery 拥有下面四种 fade 方法: fadeIn() fadeOut() fadeToggle() fa ...
- Js实现图片点击切换与轮播
Js实现图片点击切换与轮播 图片点击切换 <!DOCTYPE html> <html> <head> <meta charset="UTF-8&qu ...
- 问题:tomcat启动后,可以访问主页面,但是无法访问dubbo-admin
原因分析: 直接查看logs中的日志文件,发现一行 [Catalina-utility-1] org.apache.catalina.startup.HostConfig.undeploy Undep ...
- LInux安装MySQL5.7.24详情
安装包下载 MySQL 的官网下载地址:http://www.mysql.com/downloads/ 我安装的是5.7版本 第二步: 选择:TAR (mysql-5.7.24-el7-x86_64. ...