[pytorch笔记] 调整网络学习率
1. 为网络的不同部分指定不同的学习率
class LeNet(t.nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.features = t.nn.Sequential(
t.nn.Conv2d(3, 6, 5),
t.nn.ReLU(),
t.nn.MaxPool2d(2, 2),
t.nn.Conv2d(6, 16, 5),
t.nn.ReLU(),
t.nn.MaxPool2d(2, 2)
)
# 由于调整shape并不是一个class层,
# 所以在涉及这种操作(非nn.Module操作)需要拆分为多个模型
self.classifier = t.nn.Sequential(
t.nn.Linear(16*5*5, 120),
t.nn.ReLU(),
t.nn.Linear(120, 84),
t.nn.ReLU(),
t.nn.Linear(84, 10)
) def forward(self, x):
x = self.features(x)
x = x.view(-1, 16*5*5)
x = self.classifier(x)
return x
这里LeNet被拆解成features和classifier两个模型来实现。在训练时,可以为features和classifier分别指定不同的学习率。
model = LeNet()
optimizer = optim.SGD([{'params': model.features.parameters()},
{'params': model.classifier.parameters(), 'lr': 1e-2}
], lr = 1e-5)
对于{'params': model.classifier.parameters(), 'lr': 1e-2} 被指定了特殊的学习率 'lr': 1e-2,则按照该值优化。
对于{'params': model.features.parameters()} 没有特殊指定学习率,则使用 lr = 1e-5。
SGD的param_groups中保存着 'params', 'lr', 'momentum', 'dampening','weight_decay','nesterov'及对应值的字典。
在 CLASS torch.optim.Optimizer(params, defaults) 中,提供了 add_param_group(param_group) 函数,可以在optimizer中添加param group. 这在固定与训练网络模型部分,fine-tuning 训练层部分时很实用。
2. 动态调整网络模块的学习率
for p in optimizer.param_groups:
p['lr'] = rate()
如果需要动态设置学习率,可以以这种方式,将关于学习率的函数赋值给参数的['lr']属性。
还以以上定义的LeNet的optimizer为例,根据上面的定义,有两个param_groups, 一个是model.features.parameters(), 一个是{'params': model.classifier.parameters()。
那么在for的迭代中,可以分别为这两个param_group通过函数rate()实现动态赋予学习率的功能。
如果将optimizer定义为:
optimizer = optim.SGD(model.parameters(), lr = 0.001, momentum = 0.9)
那么param_groups中只有一个param group,也就是网络中各个模块共用同一个学习率。
3. 使用pytorch封装好的方法
https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate
torch.optim.lr_scheduler中提供了一些给予epochs的动态调整学习率的方法。
https://www.jianshu.com/p/a20d5a7ed6f3 这篇blog中绘制了一些学习率方法对应的图示。
1)torch.optim.lr_scheduler.StepLR
import torch
import torch.optim as optim
from torch.optim import lr_scheduler
from torchvision.models import AlexNet
import matplotlib.pyplot as plt model = AlexNet(num_classes=2)
optimizer = optim.SGD(params=model.parameters(), lr=0.05) # lr_scheduler.StepLR()
# Assuming optimizer uses lr = 0.05 for all groups
# lr = 0.05 if epoch < 30
# lr = 0.005 if 30 <= epoch < 60
# lr = 0.0005 if 60 <= epoch < 90 scheduler = lr_scheduler.StepLR(optimizer, step_size=30, gamma=0.1)
plt.figure()
x = list(range(100))
y = []
for epoch in range(100):
scheduler.step()
lr = scheduler.get_lr()
print(epoch, scheduler.get_lr()[0])
y.append(scheduler.get_lr()[0]) plt.plot(x, y)
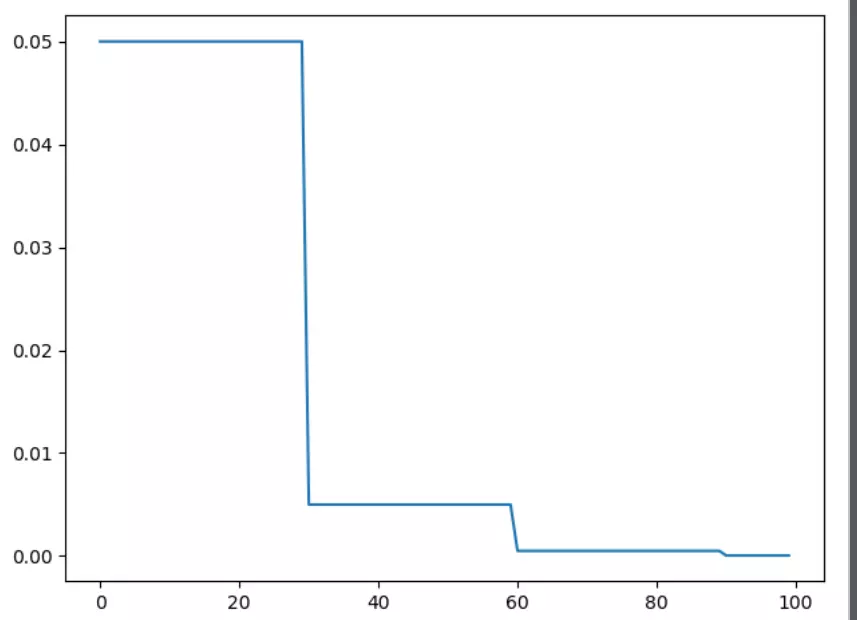
2)torch.optim.lr_scheduler.MultiStepLR
与StepLR相比,MultiStepLR可以设置指定的区间
# ---------------------------------------------------------------
# 可以指定区间
# lr_scheduler.MultiStepLR()
# Assuming optimizer uses lr = 0.05 for all groups
# lr = 0.05 if epoch < 30
# lr = 0.005 if 30 <= epoch < 80
# lr = 0.0005 if epoch >= 80
print()
plt.figure()
y.clear()
scheduler = lr_scheduler.MultiStepLR(optimizer, [30, 80], 0.1)
for epoch in range(100):
scheduler.step()
print(epoch, 'lr={:.6f}'.format(scheduler.get_lr()[0]))
y.append(scheduler.get_lr()[0]) plt.plot(x, y)
plt.show()

3)torch.optim.lr_scheduler.ExponentialLR
指数衰减
scheduler = lr_scheduler.ExponentialLR(optimizer, gamma=0.9)
print()
plt.figure()
y.clear()
for epoch in range(100):
scheduler.step()
print(epoch, 'lr={:.6f}'.format(scheduler.get_lr()[0]))
y.append(scheduler.get_lr()[0]) plt.plot(x, y)
plt.show()
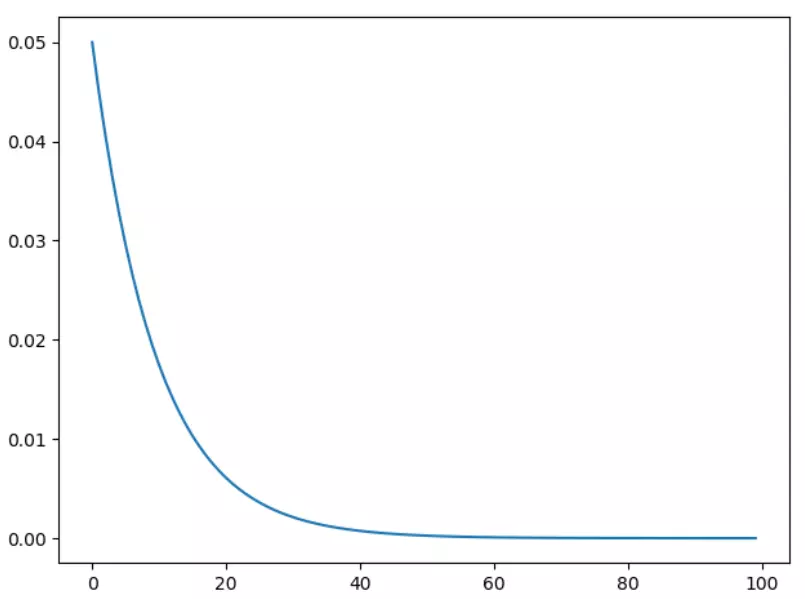
[pytorch笔记] 调整网络学习率的更多相关文章
- [Pytorch] pytorch笔记 <三>
pytorch笔记 optimizer.zero_grad() 将梯度变为0,用于每个batch最开始,因为梯度在不同batch之间不是累加的,所以必须在每个batch开始的时候初始化累计梯度,重置为 ...
- [Pytorch] pytorch笔记 <一>
pytorch笔记 - torchvision.utils.make_grid torchvision.utils.make_grid torchvision.utils.make_grid(tens ...
- python3.4学习笔记(十七) 网络爬虫使用Beautifulsoup4抓取内容
python3.4学习笔记(十七) 网络爬虫使用Beautifulsoup4抓取内容 Beautiful Soup 是用Python写的一个HTML/XML的解析器,它可以很好的处理不规范标记并生成剖 ...
- python3.4学习笔记(十三) 网络爬虫实例代码,使用pyspider抓取多牛投资吧里面的文章信息,抓取政府网新闻内容
python3.4学习笔记(十三) 网络爬虫实例代码,使用pyspider抓取多牛投资吧里面的文章信息PySpider:一个国人编写的强大的网络爬虫系统并带有强大的WebUI,采用Python语言编写 ...
- MINIST深度学习识别:python全连接神经网络和pytorch LeNet CNN网络训练实现及比较(三)
版权声明:本文为博主原创文章,欢迎转载,并请注明出处.联系方式:460356155@qq.com 在前两篇文章MINIST深度学习识别:python全连接神经网络和pytorch LeNet CNN网 ...
- [Pytorch] pytorch笔记 <二>
pytorch笔记2 用到的关于plt的总结 plt.scatter scatter(x, y, s=None, c=None, marker=None, cmap=None, norm=None, ...
- 使用Iperf调整网络
使用Iperf调整网络 Iperf 是一个 TCP/IP 和 UDP/IP 的性能测量工具,通过调谐各种参数可以测试TCP的最大带宽,并报告带宽.延迟,最大段和最大传输单元大小等统计信息.Ip ...
- PyTorch对ResNet网络的实现解析
PyTorch对ResNet网络的实现解析 1.首先导入需要使用的包 import torch.nn as nn import torch.utils.model_zoo as model_zoo # ...
- pytorch空间变换网络
pytorch空间变换网络 本文将学习如何使用称为空间变换器网络的视觉注意机制来扩充网络.可以在DeepMind paper 阅读更多有关空间变换器网络的内容. 空间变换器网络是对任何空间变换的差异化 ...
随机推荐
- 2019中山纪念中学夏令营-Day1[JZOJ]
T1 题目描述: 1999. Wexley接苹果(apple) (File IO): input:apple.in output:apple.out 时间限制: 1000 ms 空间限制: 1280 ...
- 房地产大佬潘石屹推荐学Python编程,这本从0到1就够了
潘石屹推荐学Python编程,很多人都不相信,他的微博真真切切. 连房地产都开始学Python了,因为要听懂机器,让机器为我所用. 再不学习Python真的晚了!!!! 如何学? 怎么学? 还是推荐高 ...
- python网络编程——使用UDP、TCP协议收发信息
UDP UDP是面向无连接的通讯协议,UDP数据包括目的端口号和源端口号信息,由于通讯不需要连接,所以可以实现广播发送. UDP传输数据时有大小限制,每个被传输的数据报必须限定在64KB之内. UDP ...
- 转载Spring Data JPA 指南——整理自官方参考文档
转载:https://blog.csdn.net/u014633852/article/details/52607346 官方文档 https://docs.spring.io/spring-data ...
- php运行结果设置无缓存
修改配置php.ini vim /usr/local/php/lib/php.ini opcache.enable= 重启php服务 service php-fpm restart done! 参考地 ...
- luogu题解 UVA1615 【Highway】
题目链接: https://www.luogu.org/problemnew/show/UVA1615 分析: 首先这里的距离是欧几里得距离而不是曼哈顿距离. 然后我们对于每个点,求出在公路上保持D范 ...
- 浅析HBase:为高效的可扩展大规模分布式系统而生
什么是HBase Apache HBase是运行在Hadoop集群上的数据库.为了实现更好的可扩展性(scalability),HBase放松了对ACID(数据库的原子性,一致性,隔离性和持久性)的要 ...
- 微信支付成功没有回调遇到的坑 onBridgeReady getBrandWCPayRequest wx.chooseWXPay
最近在调微信支付,遇到一个问题,就是支付成功回调不执行的. 遇到的问题就是 苹果手机 支付成功没有进到回调函数里,但是支付的时候,点击取消支付是可以进到回调函数里的. 安卓手机测试一切正常! ...
- Layedit 编辑页面赋值
1.编辑页面 $("[name=Experience]").val(data.Experience);//直接赋值然后再进行build experience = layedit.b ...
- deep_learning_LSTM长短期记忆神经网络处理Mnist数据集
1.RNN(Recurrent Neural Network)循环神经网络模型 详见RNN循环神经网络:https://www.cnblogs.com/pinard/p/6509630.html 2. ...