Spark核心原理初探
一、运行架构概览
Spark架构是主从模型,分为两层,一层管理集群资源,另一层管理具体的作业,两层是解耦的。第一层可以使用yarn等实现。
Master是管理者进程,Worker是被管理者进程,每个Worker节点启动一个Worker进程,了解每台机器的资源有多少,并将这些信息汇报各Master进程。
每个提交的作业程序对应一个Driver和多个Executor,每个Executor执行具体的任务。
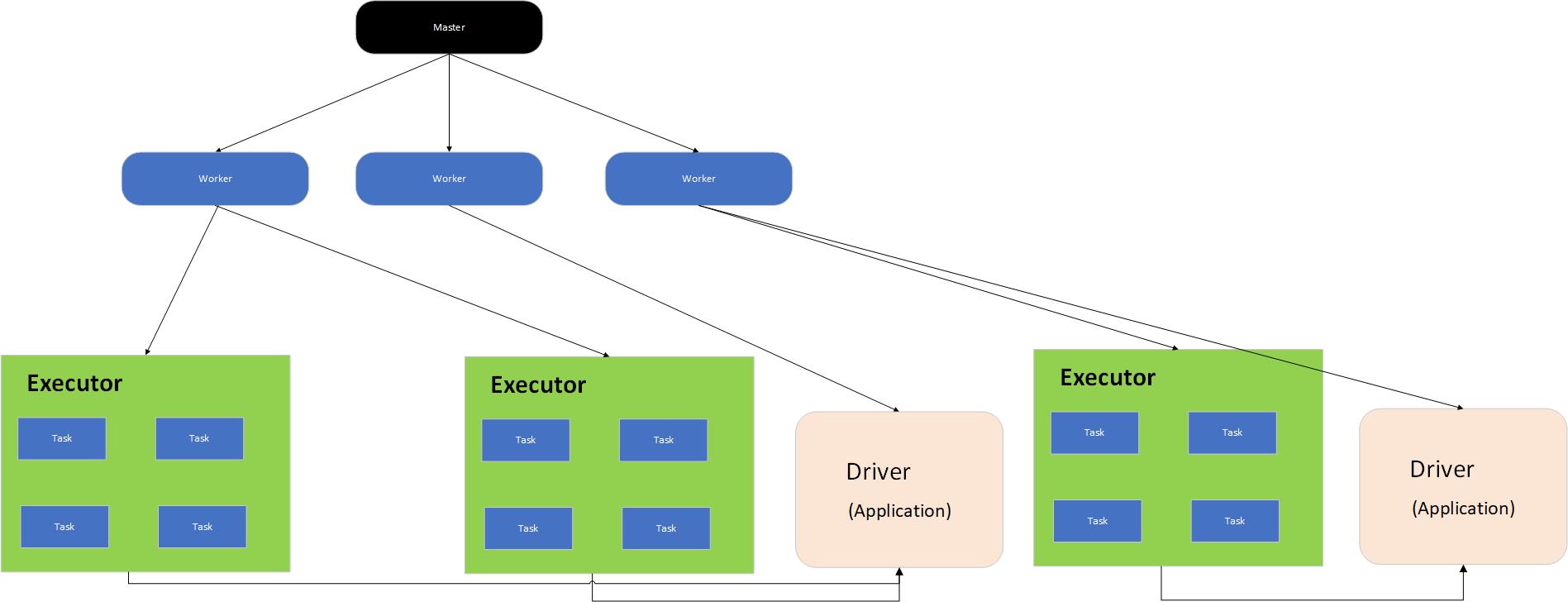
图 Spark基本运行架构
二、运行模式
- Local
- 伪分布式
- Standalone
- Yarn/K8S
三、作业执行流程
1.提交Spark应用到机器上
程序jar包提交到机器上,程序在服务器上叫Application
通过Spark-submit执行提交的Application
Application提交到公用的集群上,有两种资源分配方式:
- FIFO,先提交的先执行,后提交的等待
- FAIR,提交的作业都分配一些资源
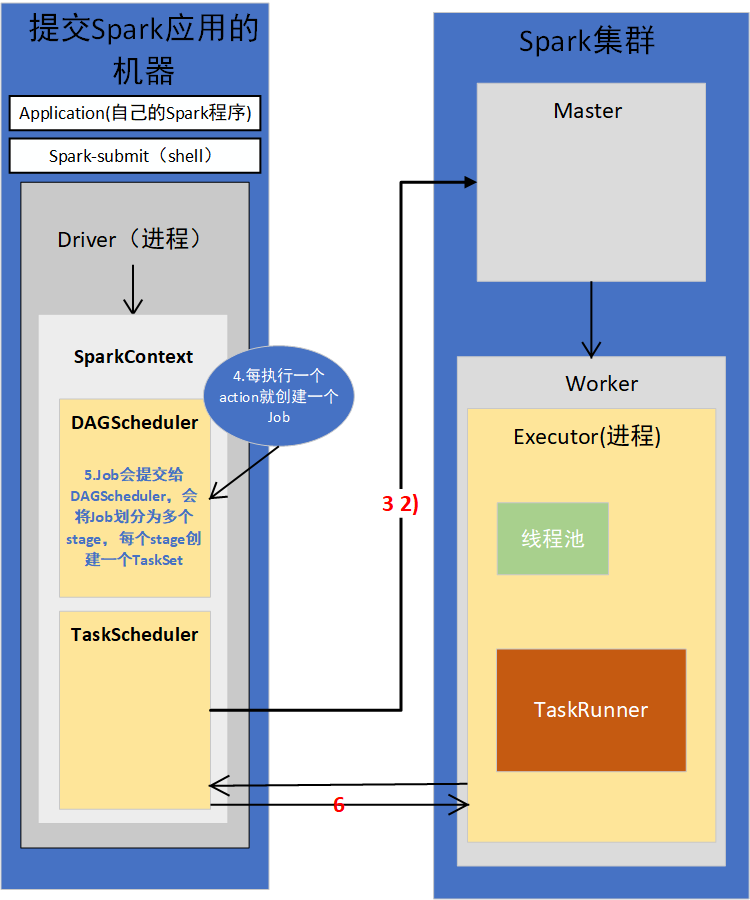
2. 提交后会在本地客户端启动Driver进程
standalonde会通过反射的方式,创建和构造一个DriverActor进程出来
Driver进程会执行我们的Application应用程序,也就是我们编写的代码。
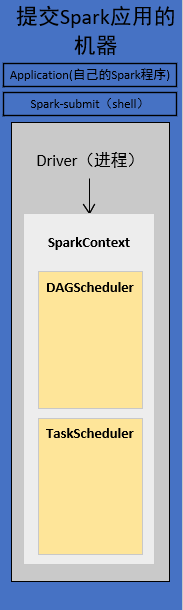
3.构造SparkContext
代码首先构造SparkConf,再构造SparkContext
1)SparkContext初始化
SpakrContext初始化时,最重要的两件事是构造出DAGSchedule和TaskSchedule。
2)TaskScheduler会通过对应的后台进程去连接Master
TaskScheduler有自己的后台进程
会向Master注册Application
3)Master接收到Application的注册请求后,会使用自己的资源调度算法,在Spark集群的Worker上,为这个Application启动多个Executor
4)Worker会为Application启动Executor
5)Executor启动之后会自己反向注册到TaskScheduler上去
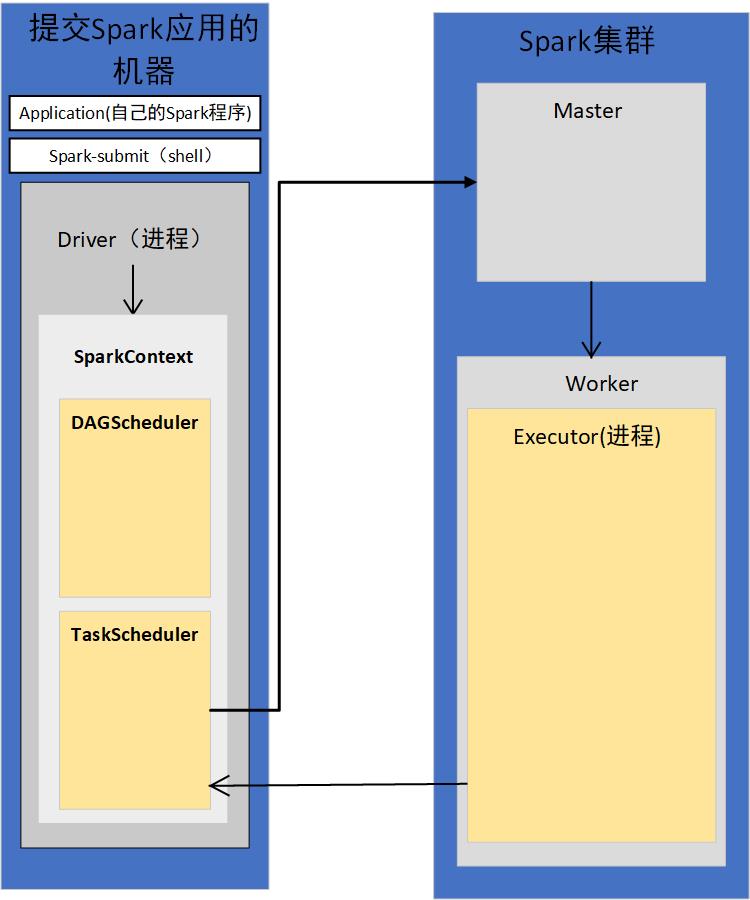
所有Executor都反向注册到Driver上之后,Driver结束Context初始化,会继续执行我们自己编写的代码。
4.每执行一个action就会创建一个Job,Job会提交给DAGScheduler
5.DAGScheduler会将Job划分为多个stage,然后每个stage创建TaskSet
stage划分算法非常重要
6.TaskScheduler会把TaskSet每一个task提交到Executor上执行
task分配算法非常重要
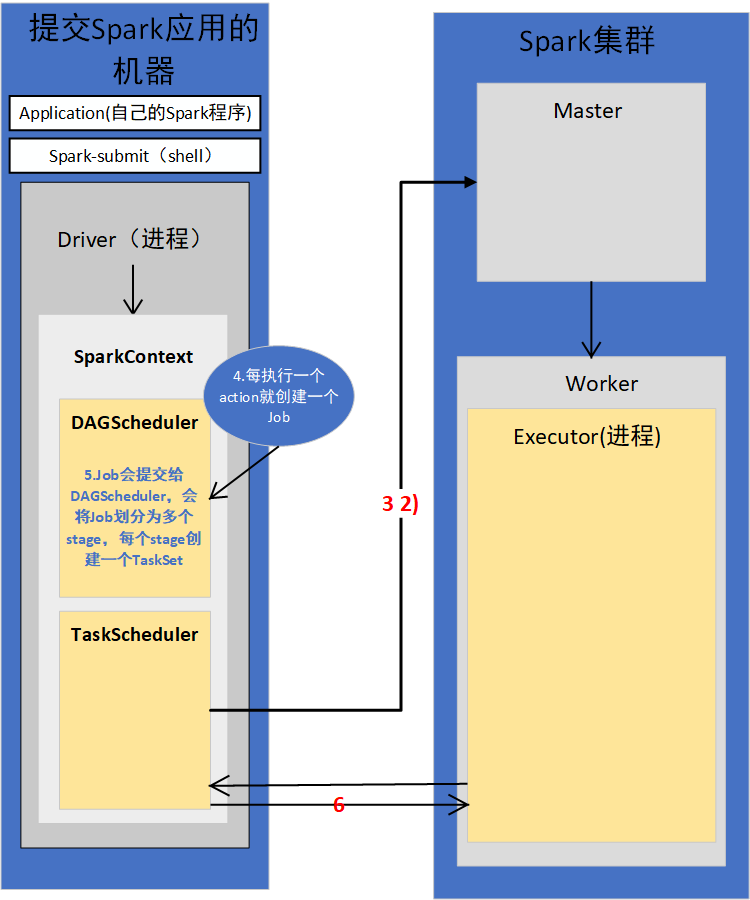
7.Executor每接收一个task,都会用TaskRunner来封装task,然后从线程池里取出一个线程,执行这个task
8.TaskRunner将我们编写的代码,也就是要执行的算子以及函数,拷贝,反序列化,然后执行Task
Task有两种,ShuffleMapTask和ResultTask,只有最后一个stage是ResultTask,之前的stage,都是ShuffleMapTask。
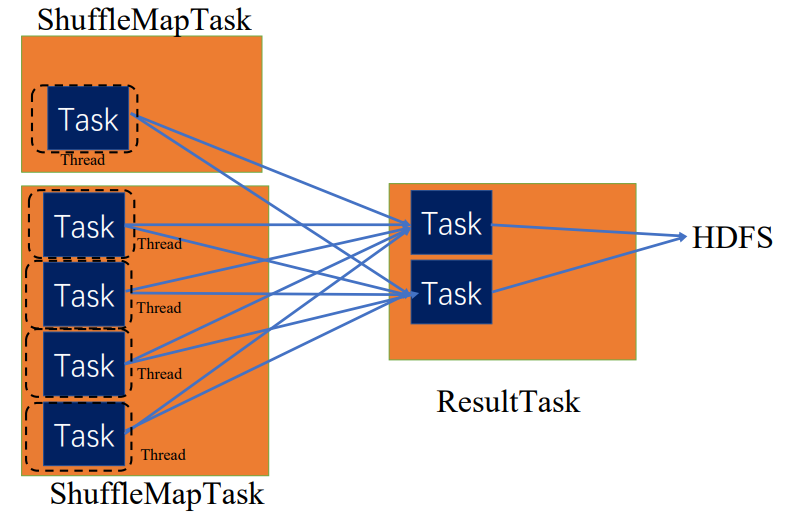
所以,最后整个Spark应用程序的执行,就是stage划分批次为TaskSet,提交到executor执行,每个task针对RDD的一个partition,执行我们定义的算子和函数。以此类推,直到所有操作都执行完为止。
四、作业流程再探讨
简单来说,是将spark程序翻译成spark core可执行的Task的过程
1.BSP(Bulk synchronous parallel)并行模型
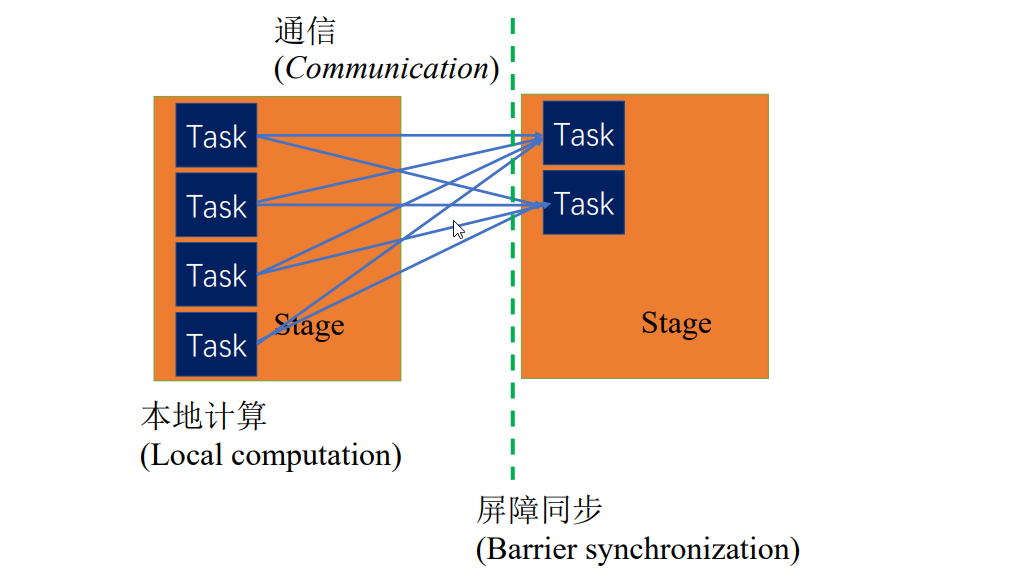
比如,wordcount程序,首先是并行的本地的过滤操作,将字符串转为单词,该过程可以拆成多个同质的Task,这些Task之间没有依赖
单词聚合的时候,就产生了依赖,会等待前一个阶段所有任务都执行完,屏障同步
分布式环境中,前后阶段可能在不同节点上,会产生通信
同步体现在上一阶段任务全执行完,下一阶段任务才可以执行
异步模型,上一阶段有些任务没执行完,有些任务执行完,下一阶段就可以启动
2.Word Count
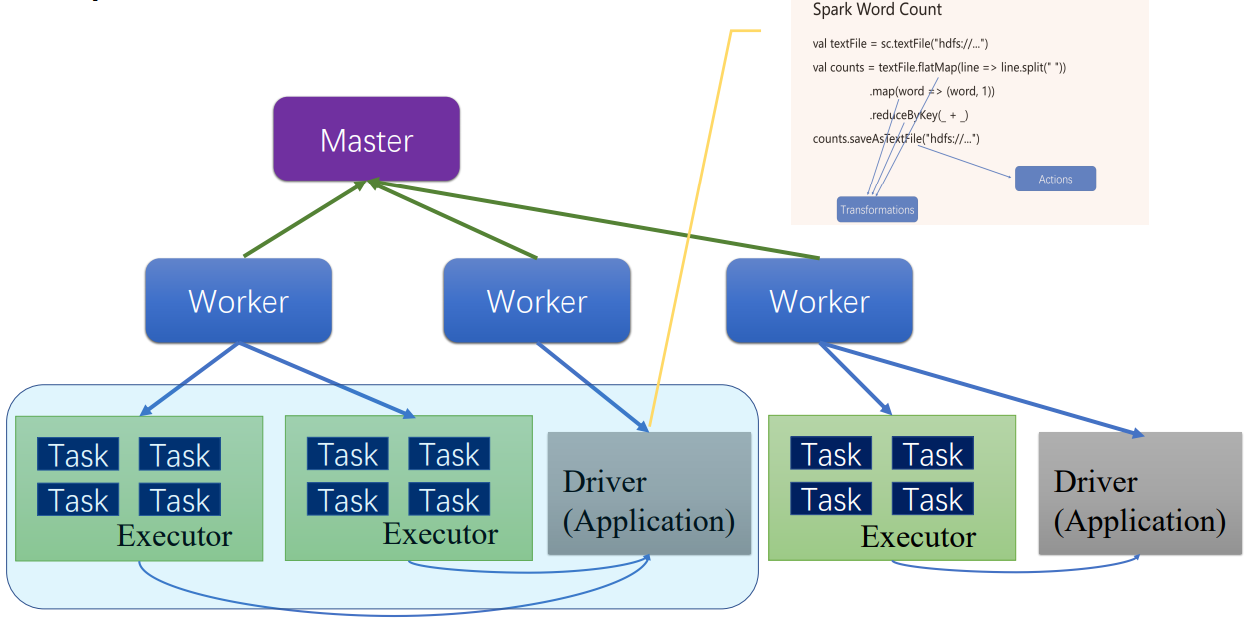
提交作业后,作业会像master请求一些资源,master会帮忙启动driver进程和Executor进程,服务于word count程序,这个程序打包为jar包,分发到driver上,driver会启动二进制打好的包,包启动之后,会将作业编译解析成细粒度的Task。Task执行顺序,由driver决定,编译成一个个stage,每个stage有具体的Task,这样一步步按顺序并行执行,直到最后顺利完成job,将作业状态汇报给管理者,可以通过日志等查询。
创建逻辑查询计划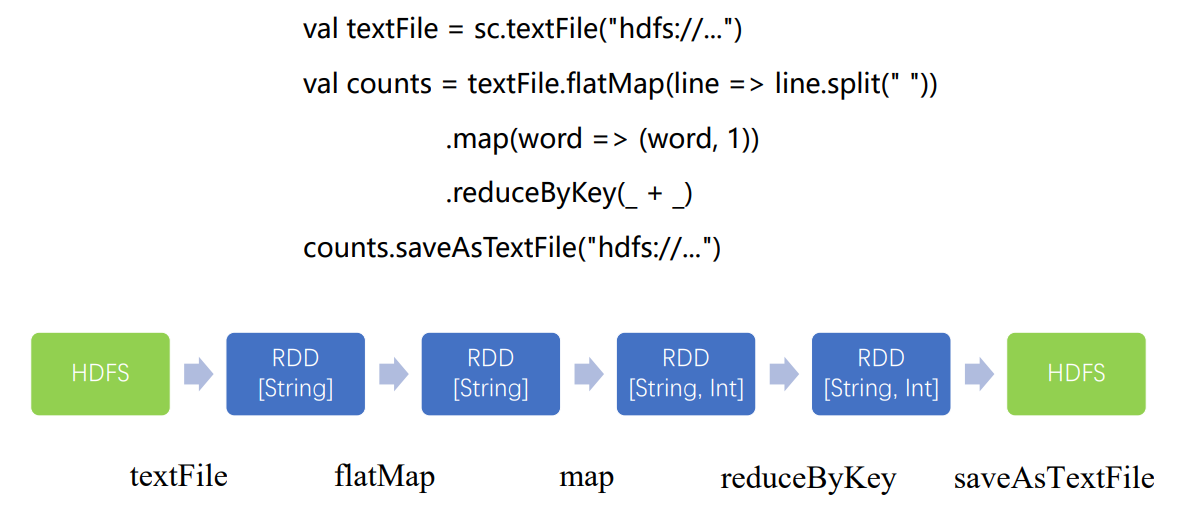
创建物理查询计划
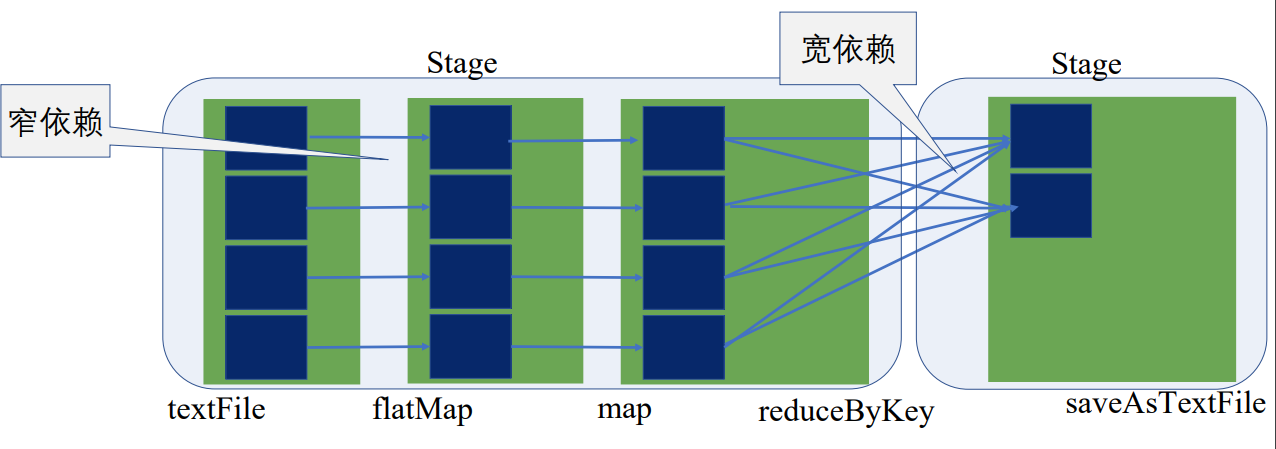
flatMap、map的操作只是将单条记录,将输入是一行的字符串转成了(String, int)类型,这一过程完全可以在本地运算,和集群上其他节点是没有关联的,可以通过操作符的合并将前三步合并为一个stage,不能合并的聚合操作成为了另一个stage
宽窄依赖是划分stage的依据
这就是创建物理查询计划,防止出现大量的RDD,减少任务的调度开销
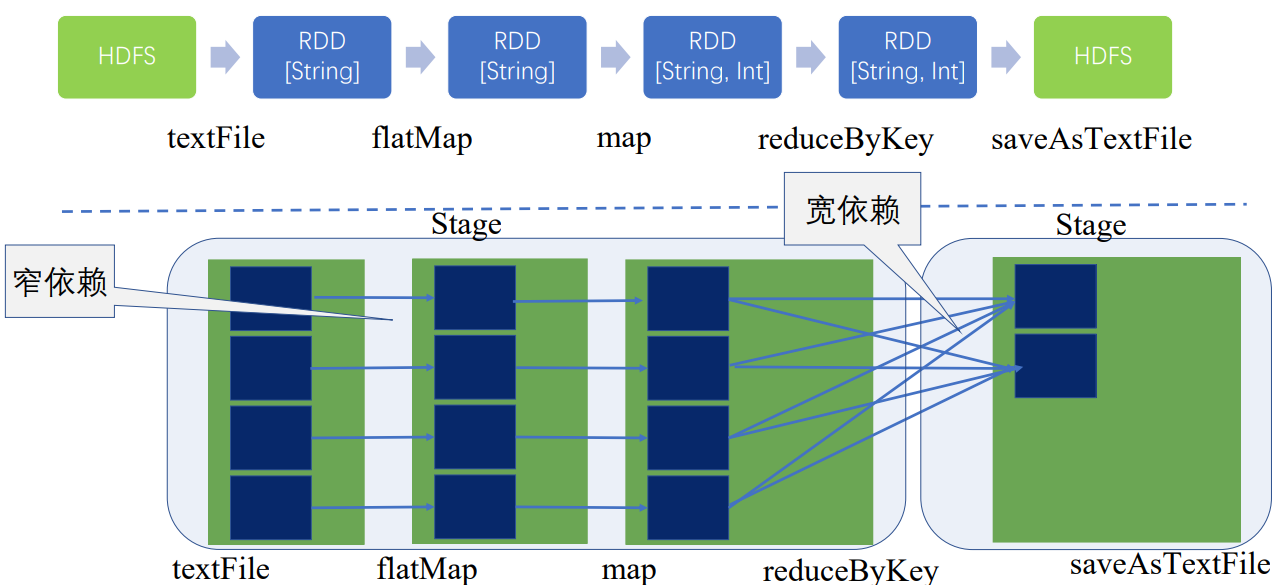
在同一个stage内,根据数据划分规则,或数据块的数量等拆分成多个并行的任务,下面拆分成了四个并行的任务,每个Task都按顺序执行了textFile、flatMap、map
因此,同一个stage是同质同样的Task的集合
只有当前一个stage所有任务完成后,下一个stage才执行
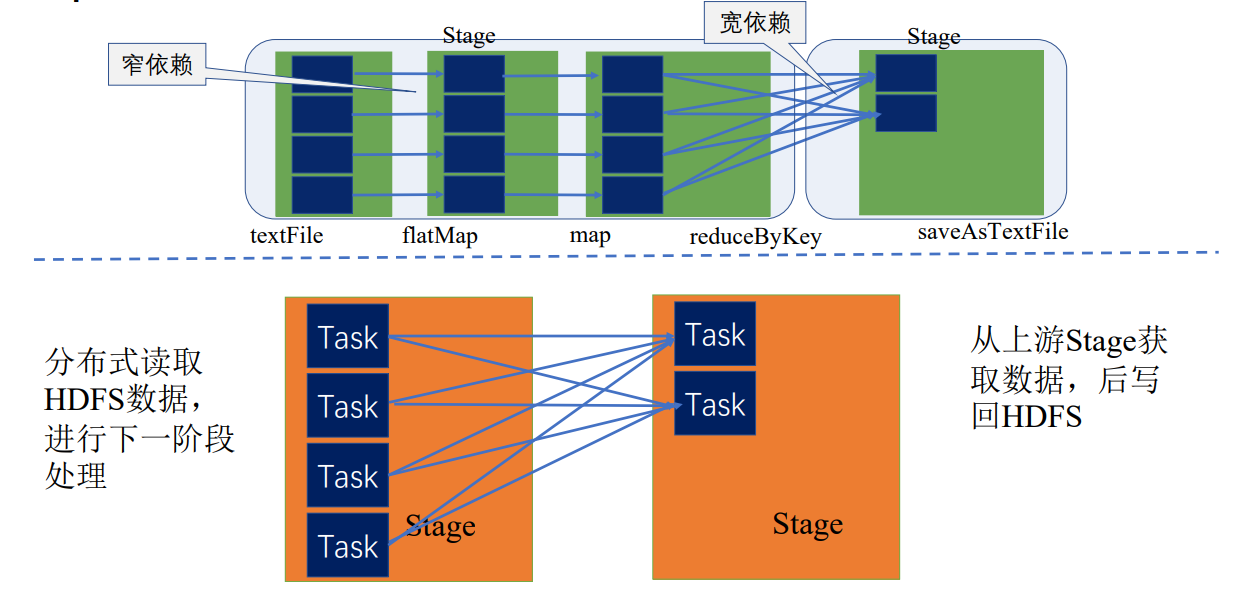
Driver中的TaskScheduler会调度Task,根据executor汇报的资源情况和stage中Task的执行情况,调度到executor上执行,executor会具体分配线程执行Task,执行完后会将Task执行正确完成状态分发返回给driver,driver再根据情况去调度,直到该stage所有Task执行完毕,才执行下一个stage的Task
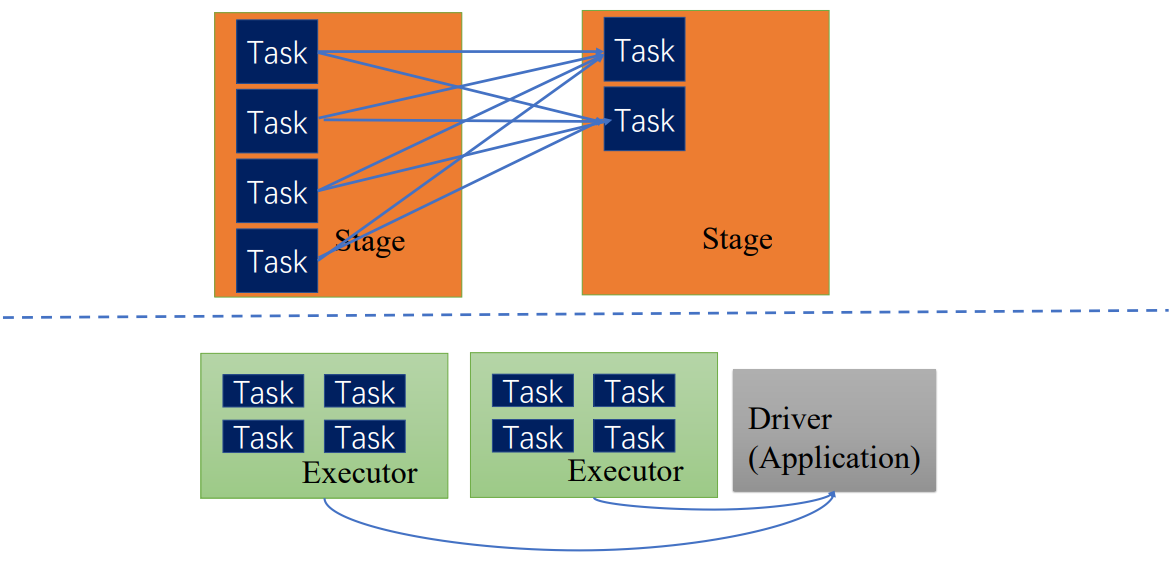
DAGScheduler和TaskScheduler
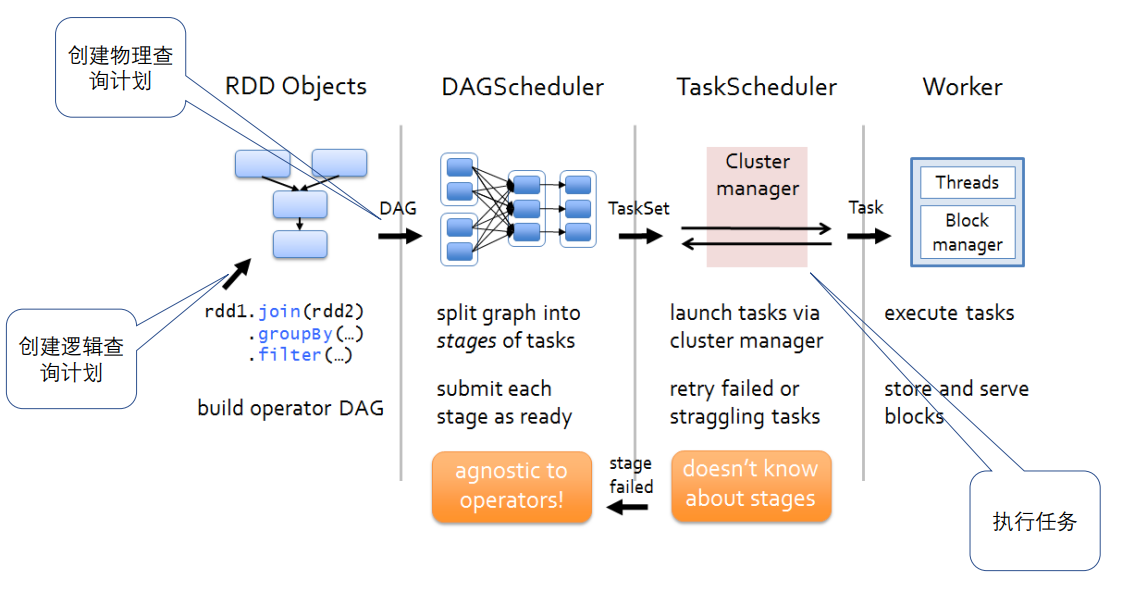
DAGScheduler将逻辑查询计划转为物理查询计划,切分为stage,stage内部会产生TaskSet
TaskScheduler调度TaskSet中具体的Task
Executor上由Block manager管理它能对应执行的数据块,即相应的partition,分配给Task,分配线程执行具体任务,执行过程组件会汇报状态给相应调度器
Spark作业层级
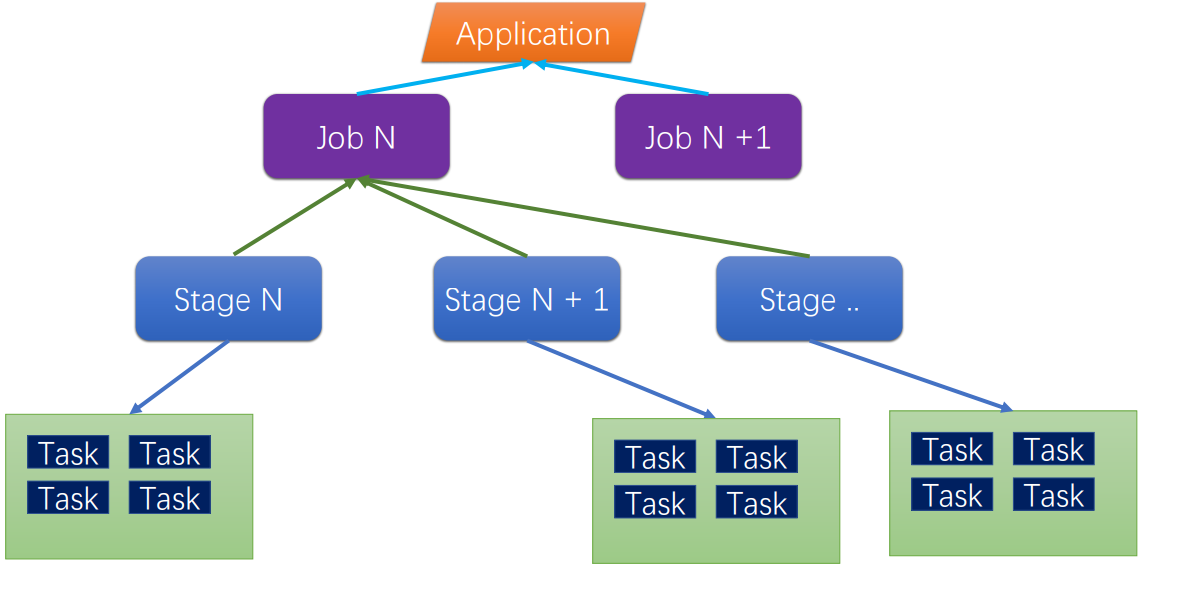
- job : A job is triggered by an action, like count() or saveAsTextFile(). Click on a job to see information about the stages of tasks inside it. 所谓一个 job,就是由一个 rdd 的 action 触发的动作,可以简单的理解为,当你需要执行一个 rdd 的 action 的时候,会生成一个 job。
- stage : stage 是一个 job 的组成单位,就是说,一个 job 会被切分成 1 个或 1 个以上的 stage,然后各个 stage 会按照执行顺序依次执行。
- task : A unit of work within a stage, corresponding to one RDD partition。即 stage 下的一个任务执行单元,一般来说,一个 rdd 有多少个 partition,就会有多少个 task,因为每一个 task 只是处理一个 partition 上的数据。
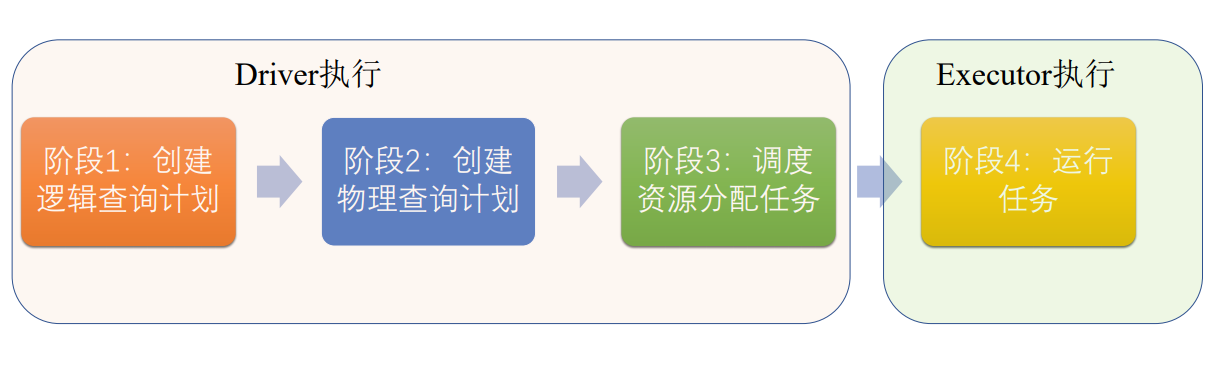
Driver阶段Spark作业翻译为可执行的任务
Executor会执行任务
阶段一: 创建逻辑查询计划,将程序翻译为一步步的RDD的操作
阶段二:根据宽窄依赖创建物理查询计划,切分出stage合并操作符
阶段三:将stage切分为同质的任务,变成可调度任务,将任务调度到空闲的资源上
阶段四:根据Executor空闲资源执行Task
五、Shuffle
根据宽窄依赖切分stage
stage和stage之间,宽依赖,由于两个stage的Task可能不在同一节点上,会在各节点间产生通信
节点间的拷贝需要Shuffle机制的支持
Spark的Shuffle经过了几次的演变
最原始的
MapTask1执行之后,才执行MapTask2
蓝色Map是一个stage
黄色Reduce是另一stage
MapTask都会输出三个文件,因为有三个ReduceTask
文件保存到磁盘,因为中间文件太多,内存无法保存;保存到磁盘,出错也容易恢复
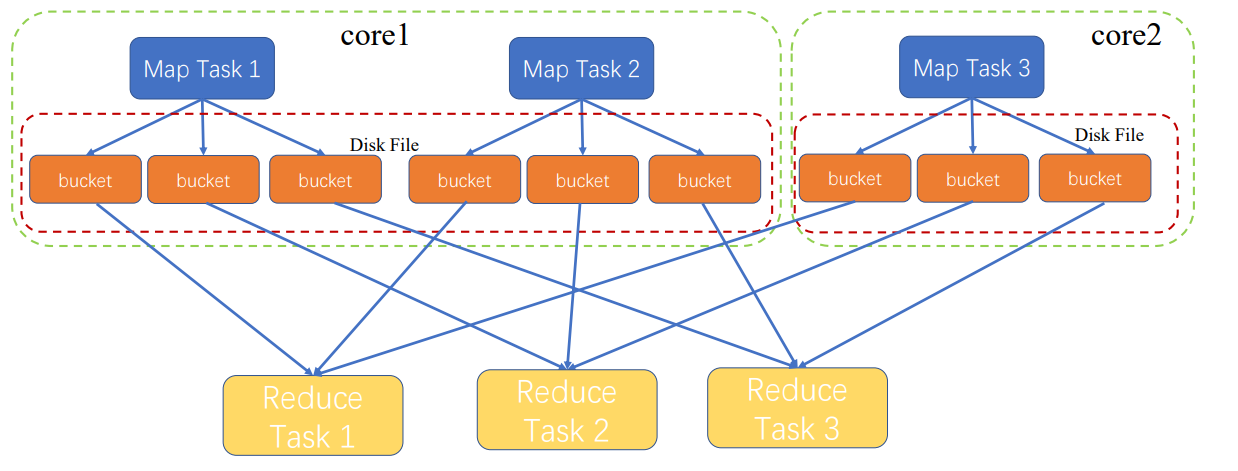
会产生MapTask数量*ReduceTask数量的文件,文件太多了
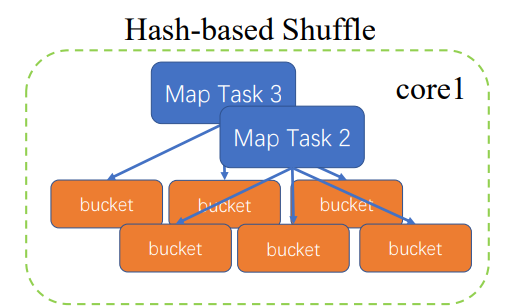
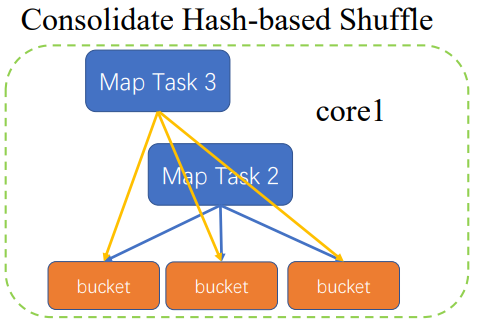
优化
MapTask2执行完,再执行MapTask3
这是只要将MapTask3的执行结果追加到MapTask2
只要生成core数量*ReduceTask数量的文件
还是会随着ReduceTask增加而性性增加
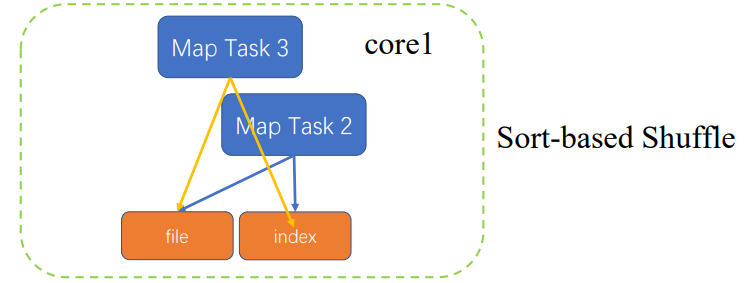
再次优化
根据partitionkey做排序,属于哪个ReduceTask,排序好之后,生成相应的文件,并根据partitionkey对文件生成索引,MapTask3也会缓存相应结果,进行排序之后,会和之前MapTask2生成的文件做mergesort,合并成一个文件,更新索引
只产生两个文件
计算开销加大了些
Spark核心原理初探的更多相关文章
- 大数据体系概览Spark、Spark核心原理、架构原理、Spark特点
大数据体系概览Spark.Spark核心原理.架构原理.Spark特点 大数据体系概览(Spark的地位) 什么是Spark? Spark整体架构 Spark的特点 Spark核心原理 Spark架构 ...
- Spark核心—RDD初探
本文目的 最近在使用Spark进行数据清理的相关工作,初次使用Spark时,遇到了一些挑(da)战(ken).感觉需要记录点什么,才对得起自己.下面的内容主要是关于Spark核心-RDD的相关 ...
- spark核心原理
spark运行结构图如下: spark基本概念 应用程序(application):用户编写的spark应用程序,包含驱动程序(Driver)和分布在集群中多个节点上运行的Executor代码,在执行 ...
- Spark核心技术原理透视一(Spark运行原理)
在大数据领域,只有深挖数据科学领域,走在学术前沿,才能在底层算法和模型方面走在前面,从而占据领先地位. Spark的这种学术基因,使得它从一开始就在大数据领域建立了一定优势.无论是性能,还是方案的统一 ...
- Spark 以及 spark streaming 核心原理及实践
收录待用,修改转载已取得腾讯云授权 作者 | 蒋专 蒋专,现CDG事业群社交与效果广告部微信广告中心业务逻辑组员工,负责广告系统后台开发,2012年上海同济大学软件学院本科毕业,曾在百度凤巢工作三年, ...
- Spark入门实战系列--7.Spark Streaming(上)--实时流计算Spark Streaming原理介绍
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Spark Streaming简介 1.1 概述 Spark Streaming 是Spa ...
- Spark 核心篇-SparkContext
本章内容: 1.功能描述 本篇文章就要根据源码分析SparkContext所做的一些事情,用过Spark的开发者都知道SparkContext是编写Spark程序用到的第一个类,足以说明SparkCo ...
- Spark 核心篇-SparkEnv
本章内容: 1.功能概述 SparkEnv是Spark的执行环境对象,其中包括与众多Executor执行相关的对象.Spark 对任务的计算都依托于 Executor 的能力,所有的 Executor ...
- Spark Shuffle原理解析
Spark Shuffle原理解析 一:到底什么是Shuffle? Shuffle中文翻译为“洗牌”,需要Shuffle的关键性原因是某种具有共同特征的数据需要最终汇聚到一个计算节点上进行计算. 二: ...
随机推荐
- Linux进程前后台管理(&,fg, bg)
将进程置于后台 xlogo & 会把进程置于后台管理,使用ps命令查看进程 PID. 使用命令jobs [1]+ Running xlogo & 可以看到正在运行的 xlogo 进程. ...
- C# json对象中包含数组对象时,如何存入数据库
前端创建的的对象例如: C#端这样将数组提取出来存入
- Java Web学习总结(6)Cookie/Session
一.会话的概念 会话可简单理解为:用户开一个浏览器,点击多个超链接,访问服务器多个web资源,然后关闭浏览器,整个过程称之为一个会话. 二.会话过程中要解决的一些问题 每个用户在使用浏览器与服务器进行 ...
- 使用juqery-ui完成联想查询功能
最近公司的项目有个需求,需要使用联想查询功能.就是一个文本输入框,在输入的时候获取值去后端模糊查询然后按照列表显示在下面.效果如下图: 经过搜索找到这个插件,查阅资料可以完成这个功能,即可以实现静态数 ...
- python练习题之随机生成验证码
#引用random模块下的randint项目#定义验证码函数.定义一个空字符串变量,分三种情况,随机产生的大写字母,随机产生的小写字母,随机产生的数字.然后#每一次执行哪一种情况,条件也是随机的,就是 ...
- C++的指针偏移
假设一个类的定义如下:class Ob{public:Ob() : a(1), b(10) {}int a;private:int b; };
- spring cloud stream集成rabbitmq
pom添加依赖 <dependency> <groupId>org.springframework.cloud</groupId> <artifactId&g ...
- 后台处理json数据
InputStream in = request.getInputStream(); BufferedReader br = new BufferedReader(new InputStreamRea ...
- Thrift报错:Error: Thrift compiler: Failed to translate files. Error: Cannot run program thrift error=2
文章目录 报错: 原因: 解决: 报错: Error: Thrift compiler: Failed to translate files. Error: Cannot run program th ...
- selenium:Xpath定位详解
xpath定位在业界被戏称为元素定位的"屠龙宝刀",宝刀在手,武林我有.现在我们就来详解xpath定位方法. 一.xpath通过元素属性定位 xpath可以通过元素的属性来定位,如 ...