MaxCompute Studio提升UDF和MapReduce开发体验
原文链接:http://click.aliyun.com/m/13990/
UDF全称User Defined Function,即用户自定义函数。MaxCompute提供了很多内建函数来满足用户的计算需求,同时用户还可以创建自定义函数来满足定制的计算需求。用户能扩展的UDF有三种:UDF(User Defined Scalar Function),UDTF(User Defined Table Valued Function)和UDAF(User Defined Aggregation Function)。
同时,MaxCompute也提供了MapReduce编程接口,用户可以使用MapReduce提供的接口(Java API)编写MapReduce程序处理MaxCompute中的数据。
通过MaxCompute Studio提供的端到端的支持,用户能快速开始和熟悉开发自己的UDF和MapReduce,提高效率。下面我们就以一个例子来介绍如何使用Studio来开发自己的UDF:
创建MaxCompute Java Module
首先,你得在intellij中创建一个用于开发MaxCompute Java程序的module。具体的,File | new | module ... module类型为MaxCompute Java,配置Java JDK和MaxCompute console的安装路径,点击next,输入module名,点击finish。
这里配置console的目的主要有两个:
编写UDF和MR需要依赖MaxCompute框架的相关jar,而这些jar在console的lib目录均存在,studio能帮您将这些lib自动导入到module的依赖库中。
studio能集成console,一些动作通过console操作将十分方便。

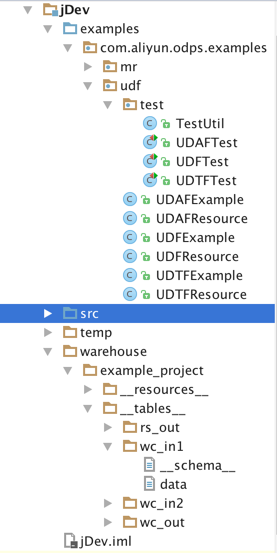
至此,一个能开发MaxCompute java程序的module已建立,如下图的jDev。主要目录包括:
src(用户开发UDF|MR程序的源码目录)
examples(示例代码目录,包括单测示例,用户可参考这里的例子开发自己的程序或编写单测)
warehouse(本地运行需要的schema和data)
创建UDF
假设我们要实现的UDF需求是将字符串转换为小写(内建函数TOLOWER已实现该逻辑,这里我们只是通过这个简单的需求来示例如何通过studio开发UDF)。studio提供了UDF|UDAF|UDTF|Mapper|Reducer|Driver的模板,这样用户只需要编写自己的业务代码,而框架代码会由模板自动填充。
1. 在src目录右键 new | MaxCompute Java

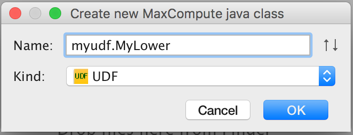
2. 输入类名,如myudf.MyLower,选择类型,这里我们选择UDF,点击OK。
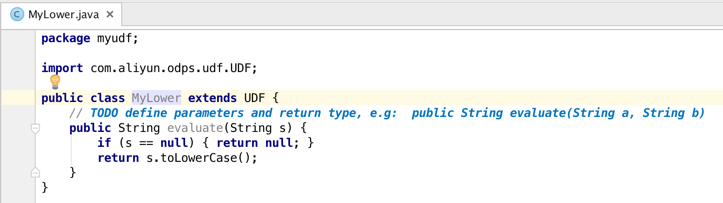
3. 模板已自动填充框架代码,我们只需要编写将字符串转换成小写的函数代码即可。
测试UDF
UDF或MR开发好后,下一步就是要测试自己的代码,看是否符合预期。studio提供两种测试方式:
单元测试
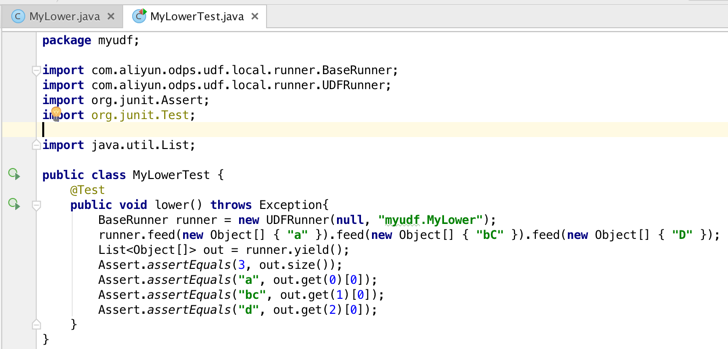
依赖于MaxCompute提供的Local Run框架,您只需要像写普通的单测那样提供输入数据,断言输出就能方便的测试你自己的UDF或MR。在examples目录下会有各种类型的单测实例,可参考例子编写自己的unit test。这里我们新建一个MyLowerTest的测试类,用于测试我们的MyLower:
sample数据测试
很多用户的需求是能sample部分线上表的数据到本机来测试,而这studio也提供了支持。在editor中UDF类MyLower.java上右键,点击"运行"菜单,弹出run configuration对话框,配置MaxCompute project,table和column,这里我们想将hy_test表的name字段转换为小写:
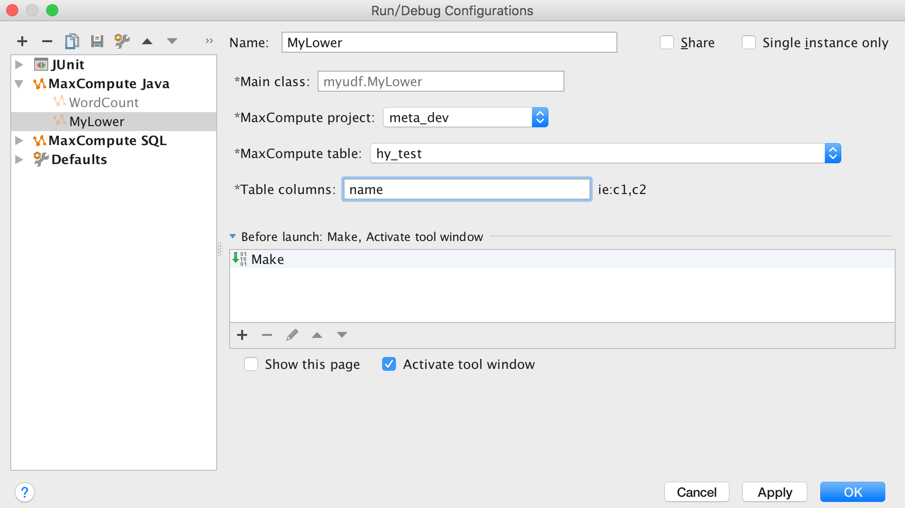
点击OK后,studio会先通过tunnel自动下载表的sample数据到本地warehouse(如图中高亮的data文件),接着读取指定列的数据并本地运行UDF,用户可以在控制台看到日志输出和结果打印:
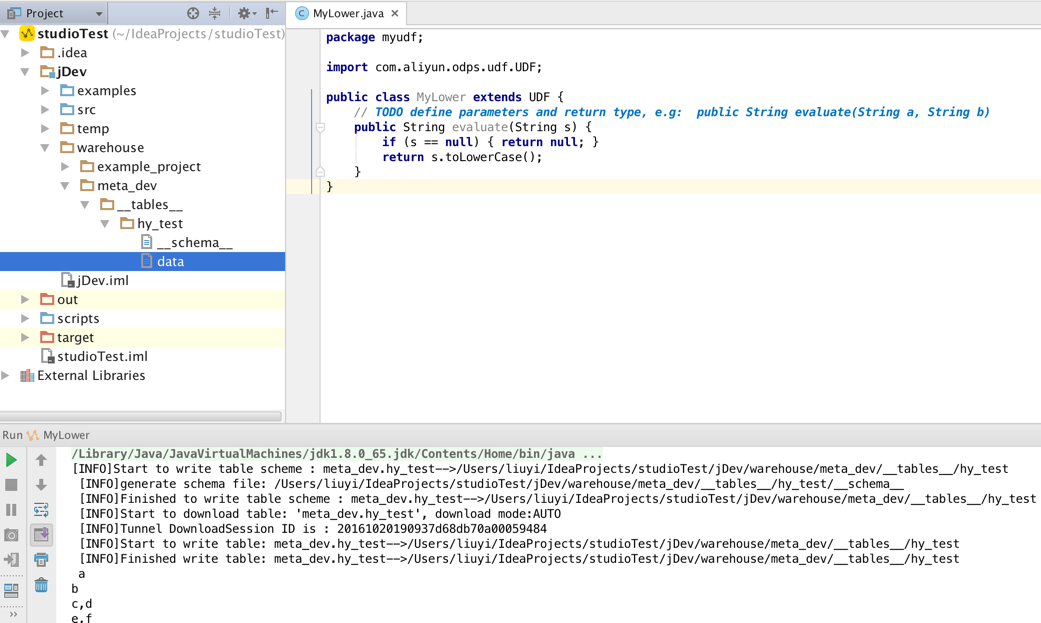
发布UDF
好了,我们的MyLower.java测试通过了,接下来我们要将其打包成jar资源(这一步可以通过IDE打包,参考用户手册)上传到MaxComptute服务端上:
1. 在MaxCompute菜单选择Add Resource菜单项:

2. 选择要上传到哪个MaxCompute project上,jar包路径,要注册的资源名,以及当资源或函数已存在时是否强制更新,然后点击OK。

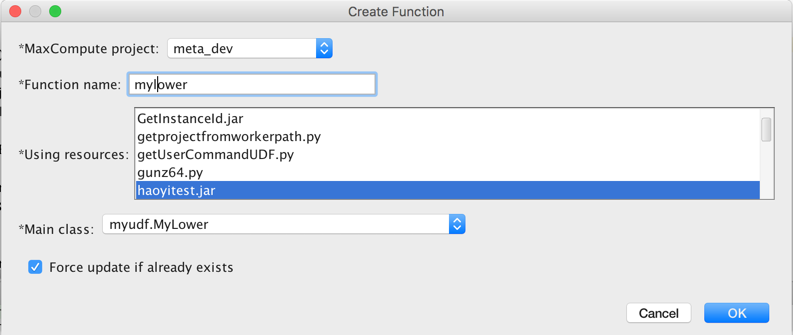
3. jar包上传成功后,接下来就可以注册UDF了,在MaxCompute菜单选择Create Function菜单项。

4. 选择需要使用的资源jar,选择主类(studio会自动解析资源jar中包含的主类供用户选择),输入函数名,然后点击OK。
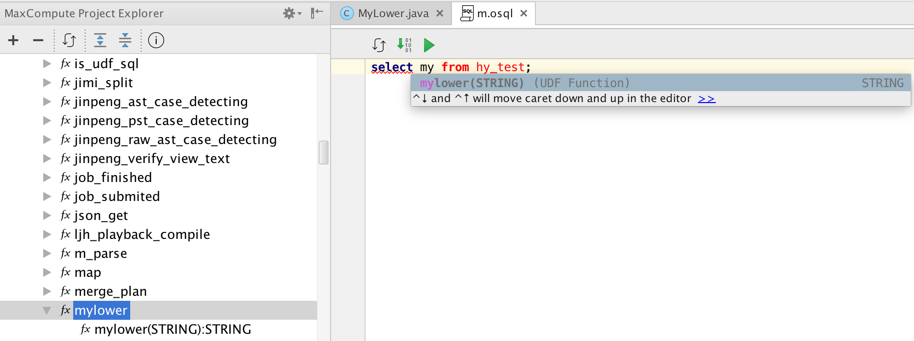
生产使用
上传成功的jar资源和注册成功的function(在Project Explorer相应project下的Resources和Functions节点中就能及时看到,双击也能显示反编译的源码)就能够实际生产使用了。我们打开studio的sql editor,就能愉快的使用我们刚写好的mylower函数,语法高亮,函数签名显示都不在话下:
MapReduce
studio对MapReduce的开发流程支持与开发UDF基本类似,主要区别有:
MapReduce程序是作用于整张表的,而且输入输出表在Driver中已指定,因此如果使用sample数据测试的话在run configuration里只需要指定project即可。
MapReduce开发好后,只需要打包成jar上传资源即可,没有注册这一步。
对于MapReduce,如果想在生产实际运行,可以通过studio无缝集成的console来完成。具体的,在Project Explorer Window的project上右键,选择Open in Console,然后在console命令行中输入类似如下的命令:
jar -libjars wordcount.jar -classpath D:\odps\clt\wordcount.jar com.aliyun.odps.examples.mr.WordCount wc_in wc_out;
转载于:https://blog.51cto.com/11778640/1906626
MaxCompute Studio提升UDF和MapReduce开发体验的更多相关文章
- 使用 typescript ,提升 vue 项目的开发体验(2)
此文已由作者张汉锐授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. vuex-class 提供了和 vuex 相关的全部装饰器,从而解决了上面 Vue.extend + vue ...
- 使用 typescript ,提升 vue 项目的开发体验(1)
此文已由作者张汉锐授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. 前言:对于我们而言,typescript 更像一个工具 官方指南 从 vue2.5 之后,vue 对 ts ...
- 使用新一代js模板引擎NornJ提升React.js开发体验
当前的前端世界中有很多著名的开源javascript模板引擎如Handlebars.Nunjucks.EJS等等,相信很多人对它们都并不陌生. js模板引擎的现状 通常来讲,这些js模板引擎项目都有一 ...
- 如何结合整洁架构和MVP模式提升前端开发体验(二) - 代码实现篇
上一篇文章介绍了整体架构,接下来说说怎么按照上图的分层结构实现下面的增删改查的功能. 代码结构 vue userManage └── List ├── api.ts ├── EditModal │ ├ ...
- 如何结合整洁架构和MVP模式提升前端开发体验(三) - 项目工程化配置、规范篇
工程化配置 还是开发体验的问题,跟开发体验有关的项目配置无非就是使用 eslint.prettier.stylelint 统一代码风格. formatting and lint eslint.pret ...
- Hadoop MapReduce开发最佳实践(上篇)
body{ font-family: "Microsoft YaHei UI","Microsoft YaHei",SimSun,"Segoe UI& ...
- [转] Hadoop MapReduce开发最佳实践(上篇)
前言 本文是Hadoop最佳实践系列第二篇,上一篇为<Hadoop管理员的十个最佳实践>. MapRuduce开发对于大多数程序员都会觉得略显复杂,运行一个WordCount(Hadoop ...
- MaxCompute Studio 使用入门
MaxCompute Studio 是MaxCompute 平台提供的安装在开发者客户端的大数据集成开发环境工具,是一套基于流行的集成开发平台 IntelliJ IDEA 的开发插件,可以帮助您方便地 ...
- 在Visual Studio 2012中使用VMSDK开发领域特定语言(二)
本文为<在Visual Studio 2012中使用VMSDK开发领域特定语言>专题文章的第二部分,在这部分内容中,将以实际应用为例,介绍开发DSL的主要步骤,包括设计.定制.调试.发布以 ...
随机推荐
- 数据库学习 day1 认识数据库
从SQL的角度而言,数据库是一个以某种有组织的方式储存的数据集合. 我们可以把它比作一个“文件柜”,这个“文件柜”是一个存放数据的物理位置,不管数据是什么,也不管数据是如何组织的. 下面介绍几个术语 ...
- Jmeter 压力测试笔记(2)--问题定位
事情已经出了,是该想办法解决的时候了. 经过运维和DBA定位: 数据库读写分离中,读库延时超过了30秒,导致所有请求都压在主库.另外所有数据库都连接数都被占满,但活跃请求数量缺不多. 数据库16K的连 ...
- 尝试用tornado部署django
import os from tornado.options import options, define from tornado import httpserver from tornado.io ...
- python3(十八)decorator
# -----------------------1-------------------------------------------- # 由于函数也是一个对象,而且函数对象可以被赋值给变量,所 ...
- vue(element)中使用codemirror实现代码高亮,代码补全,版本差异对比
vue(element)中使用codemirror实现代码高亮,代码补全,版本差异对比 使用的是vue语言,用element的组件,要做一个在线编辑代码,要求输入代码内容,可以进行高亮展示,可以切换各 ...
- [算法]素数筛法(埃氏筛法&线性筛法)
目录 一.素数筛的定义 二.埃氏筛法(Eratosthenes筛法) 三.线性筛法 四.一个性质 一.素数筛的定义 给定一个整数n,求出[1,n]之间的所有质数(素数),这样的问题为素数筛(素数的筛选 ...
- 别再问我 new 字符串创建了几个对象了!我来证明给你看!
我想所有 Java 程序员都曾被这个 new String 的问题困扰过,这是一道高频的 Java 面试题,但可惜的是网上众说纷纭,竟然找不到标准的答案.有人说创建了 1 个对象,也有人说创建了 2 ...
- 负载均衡服务之HAProxy基础入门
首先我们来了解下haproxy是干嘛的?haproxy是一个法国人名叫Willy Tarreau开发的一个开源软件:这款软件主要用于解决客户端10000以上的同时连接的高性能的TCP和HTTP负载均衡 ...
- 中国剩余定理(CRT)
只看懂了CRT,EXCRT待补.... 心得:记不得这是第几次翻CRT了,每次都有迷迷糊糊的.. 中国剩余定理用来求解类似这样的方程组: 求解的过程中用到了同余方程. x=a1( mod x1) x= ...
- I. 蚂蚁上树
蚂蚁上树(Sauteed Vermicelli with minced Pork),又名肉末粉条,是四川省及重庆市的特色传统名菜之一.因肉末贴在粉丝上,形似蚂蚁爬在树枝上而得名.这道菜具体的历史,已不 ...