Redis(三):多机数据库的实现
复制
在Redis中,用户可以通过SLAVEOF命令或是slaveof选项设置服务器的主从关系,从(SLAVE)服务器会复制主(Master)服务器。
旧版复制功能实现(2.8以前)
旧版复制功能主要分为两个过程: 同步(SYNC)和命令传播(COMMAND PROPGATE)。
同步过程:
- 当从服务器执行
SLAVEOF命令时,从服务器会向主服务器发送SYNC命令 - 主服务器收到
SYNC命令后,开始BGSAVE,生成RDB文件,同时使用一个缓冲区记录从同步开始时执行的所有写命令 - 主服务器执行完
BGSAVE命令,将生成的RDB文件发送给从服务器,从服务器载入这个RDB文件,将数据库状态同步到主服务器开始同步时的状态 - 主服务器将缓冲区内的数据发送给从服务器,从服务器执行这些命令,达到与从服务器同步的状态。
命令传播:
经过同步过程,主从服务器第一次达到了同步的状态。但是这状态并非一成不变的,主服务器执行的写命令,仍然会导致主从服务器状态不一致。因此就需要命令传播维持主从一致。
命令传播就是主服务器将自己执行的写命令发送给从服务器执行,保持主从服务器在同步后执行的写命令一致。

旧版本复制过程的缺陷
对于非初次复制的从服务器而言(从服务器断线后重连),仍然需要再次进行一次同步的过程。由于同步过程涉及RDB文件的生成,RDB文件的发送,在SYNC时需要使用CPU和带宽,代价较大。而对于断线后重连的情况,由于主从服务器在断线前都是一致的状态,因此只需要考虑同步断线到重连这段时间内的数据即可。
新版本复制过程
新版本采用PSYNC命令代替SYNC命令。PSYNC命令有完整重同步和部分重同步两种模式:
- 完整重同步:用于初次复制的情况,执行过程和
SYNC一致 - 部分重同步:用于断线后重连的情况,尽量避免再次执行
SYNC的过程。
部分重同步的实现
部分重同步设计三个内容:
- 主服务器的复制偏移量和从服务器的偏移量
- 主服务器的复制积压缓冲区
- 服务器的运行ID
复制偏移量long long master_repl_offset:
主从服务器会维持一个自己的复制偏移量,主服务器每次向从服务器传播N个字节时,就将自己的复制偏移量增加N。从服务器每次收到主服务器传来的N个字节的数据时,就将自己的复制偏移量增加N。
通过比对主从服务器的复制偏移量,可以判断主从服务器是否一致。
复制积压缓冲区char* repl_backlog:
复制积压缓冲区是由主服务器维护的一个固定长度long long repl_backlog_size的先进先出的队列(缓冲区满时,后进的字符将挤出先进的字符)。并且维护了一个缓冲区中的首字符的复制偏移量long long repl_backlog_off。
当从服务器重连后,通过PSYNC命令发送自己的复制偏移量,主服务器校验该偏移量后一位(offset + 1)是否仍在复制积压缓冲区中,如果存在,说明可以通过部分重同步,如果不存在,只能通过完全重同步。
服务器运行IDchar master_replid[CONFIG_RUN_ID_SIZE+1]:
服务器运行ID是从服务器初次向主服务器复制时,所保存主服务器的运行ID。当从服务器重连时,会向主服务器发送运行时ID,主服务器根据是否是自己的运行时ID,决定执行部分重同步还是完全重同步。
PSYNC命令的实现
PSYNC命令格式如下:
PSYNC <runid> <offset>
当从服务器初次复制时,runid为?,offset为-1。非初次复制时,runid为上次PSYNC时传递的运行时ID,offset为从服务器断线前维护的复制偏移量。

复制功能的流程
复制的流程主要分为以下步骤:
- 客户端发送
SLAVEOF命令:
SLAVEOF <master_ip> <master_port>
- 设置相关属性:
服务器接收到客户发送的SLAVEOF命令后,将命令指定的IP和端口保存到char *masterhost和int masterport中。SLAVEOF命令是一个异步命令,设置完成后便向客户端返回OK。 - 服务器根据
IP和端口,向主服务器创建套接字的链接:
如果链接成功,则关联一个负责处理复制工作的文件事件处理器,用来执行复制工作(如接受RDB文件及接受主服务器传播的命令),主服务器在接受从服务器的链接后,为套接字创建一个客户端,将从服务器当作一个客户端对待。 - 从服务器发送
PING命令:
用来测试网络情况和测试主服务器命令处理能力。当从服务器超时未收到回复及收到错误回复时,从服务器将断开重连。只用在从服务器收到PONG时,才可以继续执行复制工作的下个步骤。 - 身份验证:
如果从服务器设置了masterauth选项,从服务器会发送AUTH命令,命令的参数为masterauth的值,该值将会于主服务器的requirepass选项比较,校验通过时才可以进行下一步复制。当校验失败,或者是仅有一方设置了相关选项,主服务器都会返回错误。 - 发送端口信息:
从服务器发送命令REPLCONF listening-port <port-number>告诉主服务器监听的端口号,该信息将被保存在redisClient的int slave_listening_port中,用来在主服务器执行INFO replication命令时打印从服务器的端口。 - 同步:
从服务器发送PSYNC命令,执行同步操作,将数据库状态和主服务器保持一致。在这一步,主服务器也会成为从服务器的客户端。因为从服务器需要执行主服务器发送的缓冲区或是挤压缓冲区中的命令。 - 命令传播:
主从服务器在第一次状态达到一致后,需要通过命令传播的方式继续维持一致的状态。
复制过程流程图如下:

心跳检测
在命令传播阶段,从服务器会默认以美妙一次的频率向主服务器发送命令:
REPLCONF ACK <replication_offset>
其中replication_offset是从服务器维护的复制偏移量。
REPLCONF ACK命令主要用三个目的:
- 检测主从服务器之间的网络连接状态:
如果主服务器超过一秒的时间没收到从服务器发的REPLCONF ACK命令,那么说明主从服务器间的连接出现问题了。我们可以通过向主服务器发送INFO replication命令,在列出从服务器列表的lag一栏中,看到相应从服务器最后一次向主服务器fasongREPLCONF ACK距现在过了多少秒。 - 辅助实现
min-slaves选项
主服务器的min-slaves-max-lag比较的对象就是从客户端的lag值。 - 检测命令丢失
如果出现主从服务器由于网络问题,传播的命令在半路丢失的情况,当从服务器通过RELPCONF ACK向主服务器发送复制偏移量,那么主服务可以比较二者的偏移量,实现命令补发,达到校准从服务器的目的。
Sentinel
概念
Sentinel (哨兵模式)是Redis高可用性的方案, 一个或多个Sentinel实例组成Sentinel系统,负责监视任意多个主服务器及其从服务器,当一个主服务器进入下线状态时,将主服务器的某个从服务器提升为主服务器。
启动并初始化
可以通过redis-sentinel /configpath/sentinel.conf或是redis-server /configpath/sentinel.conf --sentinel命令来启动。当Sentinel启动时需要经历以下步骤:
- 初始化服务器
- 将普通Redis服务器的代码替换成
Sentinel的代码 - 初始化
Sentinel状态 - 根据配置文件,监视主服务器列表
- 创建连向主服务器的网络连接
初始化服务器
Sentinel实例本质上是一个特殊的Redis服务器,所以初始化Sentinel的初始化过程和Redis服务器的初始化过程很多步骤都是相同的,比如都在main方法中启动,且会对启动参数进行解析等。Redis会根据启动命令判断是运行Redis服务器还是Sentinel服务器。
使用Sentinel的专用代码
启动Sentinel服务器时,Redis会执行一些不同于Redis服务器的特殊步骤:
if (server.sentinel_mode) {
initSentinelConfig();
initSentinel();
}
initSentinelConfig会根据Sentinel的配置设置监听的端口。
initSentinel中的过程可以分成两部,第一步用Sentinel专用的命令表替换一般Redis服务器的命令表。第二步是初始化sentinelState结构。
初始化Sentinel状态
初始化Sentinel状态就是初始化sentienlState这个结构体:
/* Main state. */
struct sentinelState {
//用来记录当前纪元
uint64_t current_epoch; /* Current epoch. */
//记录mater服务器的字段表,其中键是master的名字,value是master对应的sentinelRedisInstance实例
dict *masters; /* Dictionary of master sentinelRedisInstances.
Key is the instance name, value is the
sentinelRedisInstance structure pointer. */
int tilt; /* Are we in TILT mode? */
int running_scripts; /* Number of scripts in execution right now. */
mstime_t tilt_start_time; /* When TITL started. */
mstime_t previous_time; /* Last time we ran the time handler. */
list *scripts_queue; /* Queue of user scripts to execute. */
char *announce_ip; /* IP addr that is gossiped to other sentinels if
not NULL. */
int announce_port; /* Port that is gossiped to other sentinels if
non zero. */
} sentinel;
其中sentinelRedisInstance是sentienl为服务器创建的实例,其可以表示主服务器,从服务器和其他sentinel服务器。
typedef struct sentinelRedisInstance {
//标志位,可以代码不同的实例状态
int flags; /* See SRI_... defines */
//主服务器的名字
char *name; /* Master name from the point of view of this sentinel. */
//该实例对应服务器的运行ID
char *runid; /* run ID of this instance. */
//纪元
uint64_t config_epoch; /* Configuration epoch. */
//主服务器地址
sentinelAddr *addr; /* Master host. */
redisAsyncContext *cc; /* Hiredis context for commands. */
redisAsyncContext *pc; /* Hiredis context for Pub / Sub. */
int pending_commands; /* Number of commands sent waiting for a reply. */
mstime_t cc_conn_time; /* cc connection time. */
mstime_t pc_conn_time; /* pc connection time. */
mstime_t pc_last_activity; /* Last time we received any message. */
mstime_t last_avail_time; /* Last time the instance replied to ping with
a reply we consider valid. */
mstime_t last_ping_time; /* Last time a pending ping was sent in the
context of the current command connection
with the instance. 0 if still not sent or
if pong already received. */
mstime_t last_pong_time; /* Last time the instance replied to ping,
whatever the reply was. That's used to check
if the link is idle and must be reconnected. */
mstime_t last_pub_time; /* Last time we sent hello via Pub/Sub. */
mstime_t last_hello_time; /* Only used if SRI_SENTINEL is set. Last time
we received a hello from this Sentinel
via Pub/Sub. */
mstime_t last_master_down_reply_time; /* Time of last reply to
SENTINEL is-master-down command. */
mstime_t s_down_since_time; /* Subjectively down since time. */
mstime_t o_down_since_time; /* Objectively down since time. */
mstime_t down_after_period; /* Consider it down after that period. */
mstime_t info_refresh; /* Time at which we received INFO output from it. */
/* Role and the first time we observed it.
* This is useful in order to delay replacing what the instance reports
* with our own configuration. We need to always wait some time in order
* to give a chance to the leader to report the new configuration before
* we do silly things. */
int role_reported;
mstime_t role_reported_time;
mstime_t slave_conf_change_time; /* Last time slave master addr changed. */
/* Master服务器指定字段 */
//sentinel字典,存放其他监视该主服务器的sentinel实例,其中key是ip:port,value是sentinelRedisInstance实例
dict *sentinels; /* Other sentinels monitoring the same master. */
//从服务器字典,存放该主服务器的从服务器实例,其中key是ip:port,value是sentinelRedisInstance实例
dict *slaves; /* Slaves for this master instance. */
//配置的quorum数
unsigned int quorum;/* Number of sentinels that need to agree on failure. */
int parallel_syncs; /* How many slaves to reconfigure at same time. */
char *auth_pass; /* Password to use for AUTH against master & slaves. */
/* Slave服务器指定字段 */
mstime_t master_link_down_time; /* Slave replication link down time. */
//优先级 用于failover时排序
int slave_priority; /* Slave priority according to its INFO output. */
//从INFO命令中解析得到的信息
mstime_t slave_reconf_sent_time; /* Time at which we sent SLAVE OF <new> */
//对应主服务的sentinelRedisInstance实例
struct sentinelRedisInstance *master; /* Master instance if it's slave. */
char *slave_master_host; /* Master host as reported by INFO */
int slave_master_port; /* Master port as reported by INFO */
int slave_master_link_status; /* Master link status as reported by INFO */
//从服务器的复制偏移量
unsigned long long slave_repl_offset; /* Slave replication offset. */
/* Failover */
char *leader; /* If this is a master instance, this is the runid of
the Sentinel that should perform the failover. If
this is a Sentinel, this is the runid of the Sentinel
that this Sentinel voted as leader. */
uint64_t leader_epoch; /* Epoch of the 'leader' field. */
uint64_t failover_epoch; /* Epoch of the currently started failover. */
int failover_state; /* See SENTINEL_FAILOVER_STATE_* defines. */
mstime_t failover_state_change_time;
mstime_t failover_start_time; /* Last failover attempt start time. */
mstime_t failover_timeout; /* Max time to refresh failover state. */
mstime_t failover_delay_logged; /* For what failover_start_time value we
logged the failover delay. */
struct sentinelRedisInstance *promoted_slave; /* Promoted slave instance. */
/* Scripts executed to notify admin or reconfigure clients: when they
* are set to NULL no script is executed. */
char *notification_script;
char *client_reconfig_script;
} sentinelRedisInstance;
sentinelRedisInstance结构较为复杂,上文只针对较为重要的属性添加了中文注释,其余一些记录时间的信息基本上是用来判断服务器是否健康,以及在FailOver时,筛选从服务器用的信息。
根据配置文件,监视主服务器列表
在main函数中的loadConfig中,会根据sentinel的配置文件所中声明的需要监视的主服务器的列表创建对应的sentinelRedisInstance实例,并添加至sentinelState的maters字典中。
创建连向主服务器的连接
在main的initServer中,会注册serverCron作为时间事件的回调,而serverCron在sentinel模式下,会调用sentinel.c/sentinelTimer,然后调用sentinel.c/sentinelHandleDictOfRedisInstances:
void sentinelHandleDictOfRedisInstances(dict *instances) {
dictIterator *di;
dictEntry *de;
sentinelRedisInstance *switch_to_promoted = NULL;
//遍历masters字典上所有的主服务器实例
di = dictGetIterator(instances);
while((de = dictNext(di)) != NULL) {
sentinelRedisInstance *ri = dictGetVal(de);
//处理本实例的事情
sentinelHandleRedisInstance(ri);
//如果该实例是主服务器,则递归调用该方法,同样处理主服务器下的从服务器和sentinel
if (ri->flags & SRI_MASTER) {
sentinelHandleDictOfRedisInstances(ri->slaves);
sentinelHandleDictOfRedisInstances(ri->sentinels);
//主服务器是否在failOver
if (ri->failover_state == SENTINEL_FAILOVER_STATE_UPDATE_CONFIG) {
switch_to_promoted = ri;
}
}
}
//进行failOver
if (switch_to_promoted)
sentinelFailoverSwitchToPromotedSlave(switch_to_promoted);
dictReleaseIterator(di);
}
其中sentinelHandleRedisInstance是对实例进行的一些定时操作:
void sentinelHandleRedisInstance(sentinelRedisInstance *ri) {
/* ========== MONITORING HALF ============ */
/* Every kind of instance */
//负责处理针对实例的连接
sentinelReconnectInstance(ri);
//周期性发送命令
sentinelSendPeriodicCommands(ri);
/* ============== ACTING HALF ============= */
/* We don't proceed with the acting half if we are in TILT mode.
* TILT happens when we find something odd with the time, like a
* sudden change in the clock. */
if (sentinel.tilt) {
if (mstime()-sentinel.tilt_start_time < SENTINEL_TILT_PERIOD) return;
sentinel.tilt = 0;
sentinelEvent(REDIS_WARNING,"-tilt",NULL,"#tilt mode exited");
}
/* Every kind of instance */
//检测实例是否客观下线
sentinelCheckSubjectivelyDown(ri);
/* Masters and slaves */
if (ri->flags & (SRI_MASTER|SRI_SLAVE)) {
/* Nothing so far. */
}
/* Only masters */
//确认是否主观下线,并开始FailOver
if (ri->flags & SRI_MASTER) {
sentinelCheckObjectivelyDown(ri);
if (sentinelStartFailoverIfNeeded(ri))
sentinelAskMasterStateToOtherSentinels(ri,SENTINEL_ASK_FORCED);
sentinelFailoverStateMachine(ri);
sentinelAskMasterStateToOtherSentinels(ri,SENTINEL_NO_FLAGS);
}
}
在sentinelReconnectInstance函数中,我们可以看到连接建立的过程:
void sentinelReconnectInstance(sentinelRedisInstance *ri) {
//如果已经建立连接,则直接返回
if (!(ri->flags & SRI_DISCONNECTED)) return;
/* Commands connection. */
//建立命令连接(所有的实例都需要进行命令连接)
if (ri->cc == NULL) {
ri->cc = redisAsyncConnectBind(ri->addr->ip,ri->addr->port,REDIS_BIND_ADDR);
if (ri->cc->err) {
sentinelEvent(REDIS_DEBUG,"-cmd-link-reconnection",ri,"%@ #%s",
ri->cc->errstr);
sentinelKillLink(ri,ri->cc);
} else {
//连接建立成功,并设置响应回调函数
ri->cc_conn_time = mstime();
ri->cc->data = ri;
redisAeAttach(server.el,ri->cc);
redisAsyncSetConnectCallback(ri->cc,
sentinelLinkEstablishedCallback);
redisAsyncSetDisconnectCallback(ri->cc,
sentinelDisconnectCallback);
sentinelSendAuthIfNeeded(ri,ri->cc);
sentinelSetClientName(ri,ri->cc,"cmd");
/* Send a PING ASAP when reconnecting. */
sentinelSendPing(ri);
}
}
/* Pub / Sub */
//建立负责Pub/sub的连接(只针对主从服务器)
if ((ri->flags & (SRI_MASTER|SRI_SLAVE)) && ri->pc == NULL) {
ri->pc = redisAsyncConnectBind(ri->addr->ip,ri->addr->port,REDIS_BIND_ADDR);
if (ri->pc->err) {
sentinelEvent(REDIS_DEBUG,"-pubsub-link-reconnection",ri,"%@ #%s",
ri->pc->errstr);
sentinelKillLink(ri,ri->pc);
} else {
//建立成功,设置响应的回调
int retval;
ri->pc_conn_time = mstime();
ri->pc->data = ri;
redisAeAttach(server.el,ri->pc);
redisAsyncSetConnectCallback(ri->pc,
sentinelLinkEstablishedCallback);
redisAsyncSetDisconnectCallback(ri->pc,
sentinelDisconnectCallback);
sentinelSendAuthIfNeeded(ri,ri->pc);
sentinelSetClientName(ri,ri->pc,"pubsub");
/* Now we subscribe to the Sentinels "Hello" channel. */
retval = redisAsyncCommand(ri->pc,
sentinelReceiveHelloMessages, NULL, "SUBSCRIBE %s",
SENTINEL_HELLO_CHANNEL);
if (retval != REDIS_OK) {
/* If we can't subscribe, the Pub/Sub connection is useless
* and we can simply disconnect it and try again. */
sentinelKillLink(ri,ri->pc);
return;
}
}
}
/* Clear the DISCONNECTED flags only if we have both the connections
* (or just the commands connection if this is a sentinel instance). */
//更新实例的标识位
if (ri->cc && (ri->flags & SRI_SENTINEL || ri->pc))
ri->flags &= ~SRI_DISCONNECTED;
}
获取主服务器信息
当sentinel建立了向主服务器的连接后,sentinel会调用sentinelSendPeriodicCommands周期性的发送一些命令:
void sentinelSendPeriodicCommands(sentinelRedisInstance *ri) {
mstime_t now = mstime();
mstime_t info_period, ping_period;
int retval;
//如果未连接,则直接返回
if (ri->flags & SRI_DISCONNECTED) return;
//如果堆积的任务过多,则直接返回
if (ri->pending_commands >= SENTINEL_MAX_PENDING_COMMANDS) return;
//根据实例的标志位确定INFO发送的周期,sentinel向主从服务器发送的周期为10秒,当主服务器客观下线后,对从服务器发送INFO的周期缩短为1秒
if ((ri->flags & SRI_SLAVE) &&
(ri->master->flags & (SRI_O_DOWN|SRI_FAILOVER_IN_PROGRESS))) {
info_period = 1000;
} else {
info_period = SENTINEL_INFO_PERIOD;
}
/* We ping instances every time the last received pong is older than
* the configured 'down-after-milliseconds' time, but every second
* anyway if 'down-after-milliseconds' is greater than 1 second. */
ping_period = ri->down_after_period;
if (ping_period > SENTINEL_PING_PERIOD) ping_period = SENTINEL_PING_PERIOD;
//如果超过INFO发送周期,则发送INFO命令
if ((ri->flags & SRI_SENTINEL) == 0 &&
(ri->info_refresh == 0 ||
(now - ri->info_refresh) > info_period))
{
/* Send INFO to masters and slaves, not sentinels. */
//异步发送,并设置收到响应的回调
retval = redisAsyncCommand(ri->cc,
sentinelInfoReplyCallback, NULL, "INFO");
if (retval == REDIS_OK) ri->pending_commands++;
} else if ((now - ri->last_pong_time) > ping_period) {
//如果超过PING发送周期,则发送PING命令
/* Send PING to all the three kinds of instances. */
sentinelSendPing(ri);
} else if ((now - ri->last_pub_time) > SENTINEL_PUBLISH_PERIOD) {
//如果超过PUB/SUB发送周期,则发布消息
sentinelSendHello(ri);
}
}
获取从服务器
在sentinel会根据主服务器发送回来的INFO命令响应,解析得到该主服务器的从服务器,该过程由回调函数sentinelInfoReplyCallback触发,并调用sentinelRefreshInstanceInfo解析INFO的响应,如果解析得到的从服务器在主服务器实例的slaves字典中找不到,那么将为其创建对应实例,并建立网络连接。如果该从服务器已存在,那么更新master实例中slaves的信息。
发现其它Sentinel
Sentinel会与所有服务器(不论主从)都建立两个网络连接,一个用来发送命令(INFO,PING和PUB),另一个连接则用来SUB命令。PUB命令会向监视的主服务器的__sentinel__:hello频道,发送如下格式的消息:
sentinel_ip,sentinel_port,sentinel_runid,current_epoch,master_name,master_ip,master_port,master_config_epoch
这条信息包含sentinel和master服务器的IP,端口,runid 和 epoch(纪元)。
该消息会被所有监视这个服务器的Sentinel发现,当sentinel收到这条消息,会比较是否是自己发的消息,如果不是,则会提取其中sentinel的信息,比较是否为新发现的sentinel,如果不是,则更新旧sentinel对应的实例,如果是,则创建新实例,并建立命令连接,用于之后发送PING消息。
在Sentinel模式下,各服务器的关系如下:

检测主观下线状态
当Sentinel在连续时间内(由配置文件中的down-after-millisends指定)发送的PING命令所得到的响应均为无效回复(超时或是其他错误回复),那么Sentinel就会在该实例的flags中将SRI_S_DOWN的标识位打开。
检查客观下线
当Sentienl认为一个主服务器主观下线后,会向同样监视该主服务器的Sentienl发送is-mater-down-by-addr命令询问:
SENTIENL is-master-down-by-addr <ip> <port> <current_epoch> <runid>
其中前两项参数为master的ip和port。第三项为sentinel当前的纪元,第四项在询问主观下线时,为*,而在选举领头Sentinel时,为sentinel的runid。
当其他sentinel收到命令后会回复如下格式的请求:
<down_state>
<leader_runid>
<leader_epoch>
其中第一行别是其认为服务器的状态(1表示下线),第二行和第三行在选举领头Sentinel时分别表示该sentiel的runid和纪元。在非选举时,为*和0。
当sentinel询问其他sentinel,且超过quorum的票都是下线时,sentinel就会将对应master的flags的客观下线标记打开(主观下线的标记仍然存在)。
Sentinel的启动过程和各服务器之间的发现过程如下图:

选举领头Sentinel
发现主服务器主观下线的Sentinel会向其他同样监视该主服务器的Sentinel发起一次领头Sentinel选举。
选举主要有以下规则:
- 每个
Sentinel在每个纪元内可以选一次领头Sentinel(相当于每一轮都有一次投票权),一轮选举结束,无论成功失败,Sentinel的纪元都将加1。 - 判定服务器主观下线的
Sentinel会通过is-master-down-by-addr向其他Sentinel发起领头Sentinel选举,并推荐自己成为领头Sentinel。 - 其他
Sentinel会根据先到先得的原则设置它认为的领头Sentinel(即如果这一轮中它已经设置其他Sentinel为leader,那么它无法将这次向它推荐的Sentinel设置leader)。 - 当一个
Sentinel得到超过半数的支持时,它就成为领头Sentienl,并负责之后的failOver工作。 - 如果一轮选举没能选出领头
Sentinel,那么将进行下一轮的选举。
故障转移
当选领头的Sentinel将负责故障转移操作,该操作主要包含三个步骤:
- 在从服务器中选举出一个服务器,成为新的主服务器
- 让其他从服务器成为新主服务器的从服务器
- 让已下线的主服务器成为新主服务器的从服务器
选举新服务器
故障转移操作的第一步是在已下线的主服务器的所有从服务器中,挑选出一个状态良好,数据完成的从服务器,并向这个从服务器发送SLAVEOF on one命令,从而将其转换为主服务器。
挑选的规则是选择在线的,健康的,优先级高的,且复制偏移量最大的从服务器,这样可以保证从服务器的数据最全。
当向从服务器发送的INFO命令解析得到服务器的role变为master时,说明从服务器已经升级为主服务器了。
修改从服务器的复制目标
当选举出新主服务器后,领头Sentinel下一步要做的是让已下线主服务器的从服务器复制新的主服务器。这一步可以通过Sentinel发送SLAVEOF命令实现。
将旧的主服务器变为从服务器
最后一步需要做的是将已下线的主服务器成为新主服务器的从服务器。由于旧的主服务器已经下线,因此会在对应的sentinelRedisInstance保存退化的操作,等到该服务器再次上线时,Sentinel就会向它发送SLAVEOF命令,让它成为新主服务器的从服务器。
集群
Redis 集群是 Redis 提供的分布式数据库方案,集群通过分片来进行数据共享,并提供复制和故障转移功能。
节点
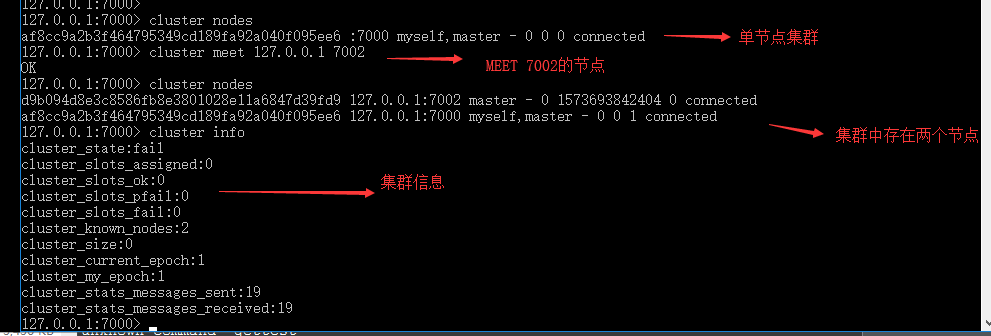
一个 Redis 集群通常由多个节点( node )组成。开始时,每个节点互相独立,处于在只包含自己的集群中。我们可以通过以下命令让独立的节点连接,构成一个包含多节点的集群:
CLUSTER MEET <ip> <port>
向某个节点发送CLUSTER MEET命令,会让该节点向 ip 和 port 指定的节点发送握手。当握手成功时,node节点会将 ip 和 port 所指定的节点添加到当前所在集群中。
集群中添加节点的过程:
节点的启动
集群模式下的节点本质上还是一个 Redis 服务器,因此启动过程和普通 Redis 服务器一致,都是由main方法启动,并开始加载,但是一个特殊的操作会在initServer()中的clusterInit()中做初始化。
void clusterInit(void) {
int saveconf = 0;
//初始化ClusterState
server.cluster = zmalloc(sizeof(clusterState));
server.cluster->myself = NULL;
server.cluster->currentEpoch = 0;
server.cluster->state = REDIS_CLUSTER_FAIL;
server.cluster->size = 1;
server.cluster->todo_before_sleep = 0;
server.cluster->nodes = dictCreate(&clusterNodesDictType,NULL);
server.cluster->nodes_black_list =
dictCreate(&clusterNodesBlackListDictType,NULL);
server.cluster->failover_auth_time = 0;
server.cluster->failover_auth_count = 0;
server.cluster->failover_auth_rank = 0;
server.cluster->failover_auth_epoch = 0;
server.cluster->cant_failover_reason = REDIS_CLUSTER_CANT_FAILOVER_NONE;
server.cluster->lastVoteEpoch = 0;
server.cluster->stats_bus_messages_sent = 0;
server.cluster->stats_bus_messages_received = 0;
memset(server.cluster->slots,0, sizeof(server.cluster->slots));
clusterCloseAllSlots();
/* Lock the cluster config file to make sure every node uses
* its own nodes.conf. */
if (clusterLockConfig(server.cluster_configfile) == REDIS_ERR)
exit(1);
/* Load or create a new nodes configuration. */
if (clusterLoadConfig(server.cluster_configfile) == REDIS_ERR) {
/* No configuration found. We will just use the random name provided
* by the createClusterNode() function. */
myself = server.cluster->myself =
createClusterNode(NULL,REDIS_NODE_MYSELF|REDIS_NODE_MASTER);
redisLog(REDIS_NOTICE,"No cluster configuration found, I'm %.40s",
myself->name);
clusterAddNode(myself);
saveconf = 1;
}
if (saveconf) clusterSaveConfigOrDie(1);
/* We need a listening TCP port for our cluster messaging needs. */
server.cfd_count = 0;
/* Port sanity check II
* The other handshake port check is triggered too late to stop
* us from trying to use a too-high cluster port number. */
if (server.port > (65535-REDIS_CLUSTER_PORT_INCR)) {
redisLog(REDIS_WARNING, "Redis port number too high. "
"Cluster communication port is 10,000 port "
"numbers higher than your Redis port. "
"Your Redis port number must be "
"lower than 55535.");
exit(1);
}
if (listenToPort(server.port+REDIS_CLUSTER_PORT_INCR,
server.cfd,&server.cfd_count) == REDIS_ERR)
{
exit(1);
} else {
int j;
for (j = 0; j < server.cfd_count; j++) {
if (aeCreateFileEvent(server.el, server.cfd[j], AE_READABLE,
clusterAcceptHandler, NULL) == AE_ERR)
redisPanic("Unrecoverable error creating Redis Cluster "
"file event.");
}
}
/* The slots -> keys map is a sorted set. Init it. */
server.cluster->slots_to_keys = zslCreate();
/* Set myself->port to my listening port, we'll just need to discover
* the IP address via MEET messages. */
myself->port = server.port;
server.cluster->mf_end = 0;
resetManualFailover();
}
该主要作用是初始ClusterState结构体并创建表示自身节点的ClsuterNode。
除此之外,在serverCron()中,集群模式下的 Redis 服务器还有特定周期处理事件clusterCron()函数。
集群特有的数据结构
ClusterState
redisServer结构中会有一个指向ClusterState的指针,而ClusterState结构就是用来记录集群状态的:
typedef struct clusterState {
//指向自身节点
clusterNode *myself; /* This node */
//当前纪元
uint64_t currentEpoch;
//集群状态
int state; /* REDIS_CLUSTER_OK, REDIS_CLUSTER_FAIL, ... */
//集群规模,只统计主节点数
int size;
/* Num of master nodes with at least one slot */
//集群中的节点
dict *nodes; /* Hash table of name -> clusterNode structures */
dict *nodes_black_list; /* Nodes we don't re-add for a few seconds. */
//准备迁移的SLOTS
clusterNode *migrating_slots_to[REDIS_CLUSTER_SLOTS];
//准备导入的SLOTS
clusterNode *importing_slots_from[REDIS_CLUSTER_SLOTS];
//记录每个SLOT对应哪个节点
clusterNode *slots[REDIS_CLUSTER_SLOTS];
//借助跳表组织数据库键(分值为键的槽位),可以快速确定某个槽对应哪些键
zskiplist *slots_to_keys;
/* The following fields are used to take the slave state on elections. */
mstime_t failover_auth_time; /* Time of previous or next election. */
int failover_auth_count; /* Number of votes received so far. */
int failover_auth_sent; /* True if we already asked for votes. */
int failover_auth_rank; /* This slave rank for current auth request. */
uint64_t failover_auth_epoch; /* Epoch of the current election. */
int cant_failover_reason; /* Why a slave is currently not able to
failover. See the CANT_FAILOVER_* macros. */
/* Manual failover state in common. */
mstime_t mf_end; /* Manual failover time limit (ms unixtime).
It is zero if there is no MF in progress. */
/* Manual failover state of master. */
clusterNode *mf_slave; /* Slave performing the manual failover. */
/* Manual failover state of slave. */
long long mf_master_offset; /* Master offset the slave needs to start MF
or zero if stil not received. */
int mf_can_start; /* If non-zero signal that the manual failover
can start requesting masters vote. */
/* The followign fields are used by masters to take state on elections. */
uint64_t lastVoteEpoch; /* Epoch of the last vote granted. */
int todo_before_sleep; /* Things to do in clusterBeforeSleep(). */
long long stats_bus_messages_sent; /* Num of msg sent via cluster bus. */
long long stats_bus_messages_received; /* Num of msg rcvd via cluster bus.*/
} clusterState;
clusterNode
clusterNode表示集群中的一个节点
typedef struct clusterNode {
//创建时间
mstime_t ctime; /* Node object creation time. */
//节点名称
char name[REDIS_CLUSTER_NAMELEN]; /* Node name, hex string, sha1-size */
//节点标志
int flags; /* REDIS_NODE_... */
uint64_t configEpoch; /* Last configEpoch observed for this node */
//记录该节点分配到的SLOT
unsigned char slots[REDIS_CLUSTER_SLOTS/8]; /* slots handled by this node */
//该节点负责的槽
int numslots; /* Number of slots handled by this node */
//该节点的从节点数
int numslaves; /* Number of slave nodes, if this is a master */
//从节点的指针
struct clusterNode **slaves; /* pointers to slave nodes */
//指向主节点
struct clusterNode *slaveof; /* pointer to the master node */
mstime_t ping_sent; /* Unix time we sent latest ping */
mstime_t pong_received; /* Unix time we received the pong */
mstime_t fail_time; /* Unix time when FAIL flag was set */
mstime_t voted_time; /* Last time we voted for a slave of this master */
mstime_t repl_offset_time; /* Unix time we received offset for this node */
long long repl_offset; /* Last known repl offset for this node. */
char ip[REDIS_IP_STR_LEN]; /* Latest known IP address of this node */
int port; /* Latest known port of this node */
//节点的连接
clusterLink *link; /* TCP/IP link with this node */
list *fail_reports; /* List of nodes signaling this as failing */
} clusterNode;
clusterLink
clusterNode结构中会有一个指向clusterLink的指针,代表当前节点与该节点间的连接。
typedef struct clusterLink {
mstime_t ctime; /* Link creation time */
//TCP Socket的文件描述符
int fd; /* TCP socket file descriptor */
//输入输出缓冲区
sds sndbuf; /* Packet send buffer */
sds rcvbuf; /* Packet reception buffer */
//对应的节点
struct clusterNode *node; /* Node related to this link if any, or NULL */
} clusterLink;
-CLUSTER MEET的流程
- 客户端向
A发送CLUSTER MEET消息,A收到消息后,为新节点B创建clusterNode结构,并根据命令指示的ip和port向节点B发送MEET消息 B收到A发送的消息后,为A创建一个clusterNode的结构,并回复一个PONG消息作为收到MEET命令的响应A收到PONG消息后,再向B节点发送PING消息作为收到PONG的响应,当B收到PING后,确认A已经收到之前发送的PONG。
整个握手过程,其实和TCP的三次握手过程很相似。
TCP握手过程和CLUSTER MEET过程对比

让集群删除节点可以通过
CLUSTER FORGET <node_name>来实现,其中的node_name可以通过CLUSTER NODES命令去查询,CLUSTER FORGET的作用是让执行命令的节点的nodes中移除对应name的节点,由于集群中的节点间存在GOSSIP协议,如果一段周期内,集群中才存在节点没FORGET掉节点,那么被删除的节点仍然会被加入到集群中。除此之外,当被删除的节点重启后,由于该节点的配置中记录了集群的信息,它仍会接入集群,因此需要在再次启动前删除对应的节点配置文件nodes.conf文件。
槽
Redis 集群通过分片的方式保存数据库中的键值对:整个集群被划分为16384个槽,集群中的每个节点可以负责处理部分或全部的槽。 当16384个槽全被节点认领后,集群才处于上线状态(OK),否则集群处于离线状态(FAIL)。
我们可以通过CLUSTER INFO命令,查询集群状态,确认下槽分配完前后的区别:

为节点分配槽可以通过CLUSTER ADDSLOTS <slot> [slot ...]命令。
记录节点的槽指派信息
上文已经介绍过clusterNode中会用unsigned char slot[16384/8]来表示某个节点负责哪些操。虽然该字段为一个字节数组,但是其用每一位表示一个槽,0表示不负责该槽,1表示负责该槽。
而numslots表示该节点负责的槽数量。
节点会通过消息将自己负责的槽信息发送给集群中其他节点。当其它节点收到该消息后,会更新clusterState.nodes中对应clusterNode的结构。
记录集群所有槽的指派信息
clusterState结构中的slots数组会记录某个槽负责的节点。
clusterState用clusterNode slots数组记录每个槽负责的节点(slot -> node),又会在clusterNode中用unsigned char slots数组记录每个节点负责的槽(node -> slot)。这样无论是想确认某个槽对应的节点,还是想确认某个节点处理的槽,时间复杂度都很小。
除此之外,clusterState还会通过跳表记录键和槽的对应关系。方便快速查询某个槽包含哪些键。
以下图片展示了三主三从情况下,某个主节点clusterNode和clusterState的结构:

在集群中执行命令
当集群中的槽都被分配完后,集群就会进入上线状态。此时,客户端就可以向集群发送数据命令了。
- 当节点收到客户端发送查询和存储有关的命令时,首先会计算键属于哪个槽(我们可以通过
CLUSTER KEYSLOT命令查询)。 - 确认这个槽由哪个节点处理。
- 如果是槽指派给当前节点,那么节点可以直接执行命令。
- 如果槽不由当前节点负责,那么节点返回一个
MOVED错误,其中MOVE错误的格式为MOVED <slot> <ip> <port>。 - 客户端会根据MOVED错误自动重定向到正确的节点,并再次发送命令。
重新分片
Redis集群的重新分片操作可以将任意数量已分配的给某个节点(源节点)的槽指派给新的节点(目标节点),并且槽中的键值对也会转移的目标节点。重新分片的流程如下:
- 客户端对目标节点发送
CLUSTER SETSLOT <slot> IMPORTING <source_id>,告知目标节点准备导入槽(目标节点的clusterNode的importing_slots_from[16384]数组相应槽的位置会指向源节点) - 客户端对源节点发送
CLUSTER SETSLOT <slot> MIGRATING <target_id>,告知源节点准备迁移槽(源节点的clusterNode的migrating_slots_to[16384]数组相应槽的位置会指向目标节点) - 客户端向源节点发送
CLUSTER GETKEYINSLOT <slot> <count>,逐步获取源节点中该槽存放的键 - 客户端根据获得的键名,再向源节点发送
MIGRATE <taget_ip> <target_port> <key_name> 0 <timeout>,将该键值对迁移至目标节点 - 当这个槽中所有的键都迁移完成后,客户端再向集群中任意一个节点发送
CLUSTER SETSLOT <slot> NODE <target_id>命令,说明该槽已经被指派给目标节点
重新分片的流程如下:

ASK错误
考虑一种情况,在槽迁移过程中,一部份键仍在源节点,而另一部分键已经在目标节点。那么此时,客户端所要查询的键正好位于这个槽,那么客户端会如何处理?
- 首先,由于迁移未完成,因此该槽还是分配在源节点下。
- 当源节点收到命令时,会先在自身的数据库中查找是否存在该键,如果存在则直接返回。
- 如果不存在,则向客户端返回
ASK错误,将客户端指向目标节点。 - 收到客户端
ASK错误的客户端先会向目标节点发送ASKING命令,目标节点就知道客户端是由于ASK错误而再次发起的查询(因为此时目标节点还不负责该槽,为了避免向目标节点发送MOVED错误),之后再次向目标节点发送要执行的命令。
集群中消息处理的总流程图如下:

复制与故障转移
复制过程
集群中一个节点成为另一个节点的从节点可以通过命令CLUSTER REPLICATION <node_id>实现。
- 客户端向节点
A发送CLUSTER REPLICATION <node_id>命令后(其中node_id为节点B的ID) A首先会根据node_id找出节点B对应的clusterState,并将自己节点的slaveof指向节点B- 之后
A节点会将自己的flags变成REDIS_NODE_SLAVE - 然后
A节点会根据B的clusterNode结构中记录的IP和端口向B发起复制过程 - 复制结束后,
A就成为了B的从节点,并通知集群中的其他节点
故障检测
集群中的节点会定期向其他节点发送PING命令,如果在规定时期内没有收到PONG响应,那么节点就会将接受消息的节点标为疑似下线,同时更新接受节点的flags字段,打开PFAIL标志。
在之后集群的消息互发过程中,会向其它节点报告疑似下线的消息,当其他节点收到疑似下线的消息时,会将疑似下线节点的clusterNode中fail_reports的链表中添加一个clusterNodeFailReport节点:
typedef struct clusterNodeFailReport {
//发出疑似下线报告的节点
struct clusterNode *node; /* Node reporting the failure condition. */
//创建时间
mstime_t time; /* Time of the last report from this node. */
} clusterNodeFailReport;
当集群中半数以上负责处理槽的主节点都报告某个节点意思下线(clusterLink *link的size > clusterState.size / 2 ),那么该节点就成为已下线状态(FAIL)。发现某个节点下线的节点会向集群中广播一条节点下线的消息。
故障转移
集群下的故障转移过程和Sentinel下的故障转移过程相似:
- 在下线主节点的从节点中选出一个作为新的主节点(发现自己复制的主节点下线的从节点会向集群广播消息像其他主节点要票,主节点每一轮有一次投票权,会将票投给最先向自己要票的节点,得到半数票的从节点当选成功,如果没有当选,则进入下一轮)
- 选中的节点执行
SLAVEOF no one,成为主节点 - 选中的节点会将已下线主节点负责的槽指派给自己
- 向集群广播消息,表示故障转移结束
消息
上面介绍的集群中的节点会通过各种消息交换信息(比如PING,PONG等),这里说的PING和PONG并非客户端发送的PING命令。
消息的定义
消息结构的定义如下:
typedef struct {
char sig[4]; /* Siganture "RCmb" (Redis Cluster message bus). */
//消息总长度
uint32_t totlen; /* Total length of this message */
//协议版本
uint16_t ver; /* Protocol version, currently set to 0. */
uint16_t notused0; /* 2 bytes not used. */
//消息类型
uint16_t type; /* Message type */
uint16_t count; /* Only used for some kind of messages. */
//当前纪元
uint64_t currentEpoch; /* The epoch accordingly to the sending node. */
uint64_t configEpoch; /* The config epoch if it's a master, or the last
epoch advertised by its master if it is a
slave. */
//复制偏移量
uint64_t offset; /* Master replication offset if node is a master or
processed replication offset if node is a slave. */
//集群的名字
char sender[REDIS_CLUSTER_NAMELEN]; /* Name of the sender node */
//节点负责的槽
unsigned char myslots[REDIS_CLUSTER_SLOTS/8];
char slaveof[REDIS_CLUSTER_NAMELEN];
char notused1[32]; /* 32 bytes reserved for future usage. */
//TCP的端口
uint16_t port; /* Sender TCP base port */
//节点的标志
uint16_t flags; /* Sender node flags */
unsigned char state; /* Cluster state from the POV of the sender */
unsigned char mflags[3]; /* Message flags: CLUSTERMSG_FLAG[012]_... */
//消息体
union clusterMsgData data;
} clusterMsg;
我们可以看到上述结构中包含了节点的许多信息,比如负责处理的槽,节点复制偏移量,节点的标识位等等。因此集群中的节点能互相交换信息。而clusterMsgData表示某个具体类型的消息。
union clusterMsgData {
/* PING, MEET and PONG */
struct {
/* Array of N clusterMsgDataGossip structures */
clusterMsgDataGossip gossip[1];
} ping;
/* FAIL */
struct {
clusterMsgDataFail about;
} fail;
/* PUBLISH */
struct {
clusterMsgDataPublish msg;
} publish;
/* UPDATE */
struct {
clusterMsgDataUpdate nodecfg;
} update;
};
消息主要分为五种类型:
MEET消息:节点收到CLUSTER MEET消息后,会向指定的消息发送MEET命令,请求接收者加入集群PING消息:节点随机选择五个节点并挑选出一个最长时间未发送节点发送PING消息,除此之外,如果最后一次收到节点的PONG消息超过了cluster-node-timeout的一半,也会发送PING消息PONG消息:当节点收到PING或是MEET时,会发送PONG消息作为响应。或是某个从节点成为了主节点后,会发送一次PONG消息FAIL消息:一个节点判断另一个节点已下线时,会向集群广播一个FAIL消息PUBLISH消息:一个节点收到PUBLISH命令后,会向集群广播PUBLISH消息,让集群中的其它节点同样执行一次PUBLISH命令。
MEET,PING和PONG消息的实现
MEET,PING和PONG都通过gossip协议来交换信息。gossip协议通过点对点的信息交互实现集群中的信息同步。
MEET,PING和PONG消息体都带有一个长度为 2 的clusterMsgDataGossip的数组。
其中clusterMsgDataGossip结构的定义如下:
typedef struct {
//节点名称
char nodename[REDIS_CLUSTER_NAMELEN];
//发送PING命令的时间
uint32_t ping_sent;
//收到PONG命令的时间
uint32_t pong_received;
//IP地址
char ip[REDIS_IP_STR_LEN]; /* IP address last time it was seen */
//端口
uint16_t port; /* port last time it was seen */
//标志位
uint16_t flags; /* node->flags copy */
uint16_t notused1; /* Some room for future improvements. */
uint32_t notused2;
} clusterMsgDataGossip;
当集群发送PING,PONG和MEET消息时,会从clusterNode的字典中随机挑选两个节点,并将其信息保存到clusterMsgDataGossip中。这样就能通过消息交换节点信息。
接收到消息的节点会解析clusterMsgDataGossip中的节点信息,如果是未发现的节点则建立连接,如果是已发送的节点,则同步信息。
FAIL消息的实现
FAIL消息通过clusterMsgDataFail结构记录消息节点的名字。
typedef struct {
//下线节点的name
char nodename[REDIS_CLUSTER_NAMELEN];
} clusterMsgDataFail;
PUBLISH消息的实现
PUBLISH消息通过clusterMsgDataPublish来记录一个PUBLISH命令的channel和message。
typedef struct {
//channel字符串的长度
uint32_t channel_len;
//message字符串的长度
uint32_t message_len;
/* We can't reclare bulk_data as bulk_data[] since this structure is
* nested. The 8 bytes are removed from the count during the message
* length computation. */
//字符串数组,保存了channel和message
unsigned char bulk_data[8];
} clusterMsgDataPublish;
Redis(三):多机数据库的实现的更多相关文章
- Redis 设计与实现 (五)--多机数据库的实现
多机数据库的实现 一.复制 slaveof 主服务器ip地址.形成主从关系. 1.同步 从向主服务器发送sync命令. 主服务器收到sync命令执行bgsave,生成rdb文件,缓冲区同时记录从 ...
- Redis多机数据库
复制 PSYNC命令具有完整重同步(full resynchronization)和部分重同步(partial resynchronization)两种模式: ·其中完整重同步用于处理初次复制情况:完 ...
- 分布式锁的几种使用方式(redis、zookeeper、数据库)
Q:一个业务服务器,一个数据库,操作:查询用户当前余额,扣除当前余额的3%作为手续费 synchronized lock db lock Q:两个业务服务器,一个数据库,操作:查询用户当前余额,扣除当 ...
- redis/分布式文件存储系统/数据库 存储session,解决负载均衡集群中session不一致问题
先来说下session和cookie的异同 session和cookie不仅仅是一个存放在服务器端,一个存放在客户端那么笼统 session虽然存放在服务器端,但是也需要和客户端相互匹配,试想一个浏览 ...
- Redis笔记(3)多数据库实现
1.前言 本章介绍redis的三种多服务实现方式,尽可能简单明了总结一下. 2.复制 复制也可以称为主从模式.假设有两个redis服务,一个在127.0.0.1:6379,一个在127.0.0.1:1 ...
- Redis(1.8)Redis与mysql的数据库同步(缓存穿透与缓存雪崩)
[1]缓存穿透与缓存雪崩 [1.1]缓存和数据库间数据一致性问题 分布式环境下(单机就不用说了)非常容易出现缓存和数据库间的数据一致性问题,针对这一点的话,只能说,如果你的项目对缓存的要求是强一致性的 ...
- Redis 01: 非关系型数据库 + 配置Redis
数据库应用的发展历程 单机数据库时代:一个应用,一个数据库实例 缓存时代:对某些表中的数据访问频繁,则对这些数据设置缓存(此时数据库中总的数据量不是很大) 水平切分时代:将数据库中的表存放到不同数据库 ...
- 基于RMAN的异机数据库克隆(rman duplicate)
对于基于生产环境下的数据库的版本升级或者测试新的应用程序的性能及其影响,备份恢复等等,我们可以采取从生产环境以克隆的方式将其克隆到本地而不影响生产数据库的正常使用.实现这个功能我们可以借助rman d ...
- zTree市县实现三个梯级数据库映射
zTree市县实现三个梯级数据库映射 Province.hbm.xml: <?xml version="1.0" encoding="UTF-8"? &g ...
随机推荐
- Hadoop(学习·2)
Hadoop 操作步骤: 192.168.1.110-113 ...
- 原生js,jquery通过ajax获得后台json数据动态新增页面元素
一.原生js通过ajax获取json数据 因为IE浏览器对ajax对象的创建和其他浏览器不同,为了兼容全部浏览器,我用下面的代码: function createXMLHttpRequest(){ t ...
- spring使用jdbc
对于其中的一些内容 @Repository(value="userDao") 该注解是告诉Spring,让Spring创建一个名字叫“userDao”的UserDaoImpl实例. ...
- gdb调试工具常用命令 && kdb
编译程序时需要加上-g,之后才能用gdb进行调试:gcc -g main.c -o main gdb中命令: 回车键:重复上一命令 (gdb)help:查看命令帮助,具体命令查询在gdb中输入help ...
- C语言 生日快乐
#include <stdio.h> #include <math.h> #include <stdlib.h> #define I 20 #define R 34 ...
- python填写问卷星,疫情上报
#!!!注意:修改main里的url为真实的url,按需修改 50行 set_data中的submitdata # 61行 ip 修改为 真ip # submittype可能有错误,在151行 # 提 ...
- 08-less预处理器
一.less预处理器 Less(LeanerStyle Sheets 的缩写)是一门 CSS扩展语言,也成为CSS预处理器. 1.插件安装 安装Easy LESS插件就能使写入的.less文件保存时自 ...
- Linux/UNIX 下 “command not found” 原因分析及解决
在使用 Linux/UNIX 时,会经常遇到 "command not found" 的错误,就如提示的信息,Linux /UNIX 没有找到该命令.原因无外乎你命令拼写错误或 L ...
- 在svg文间画图过程中放大缩小图片后,坐标偏移问题
//鼠标坐标:在SVG经过缩放.偏移.ViewBox转换后,鼠标坐标值 var mouseCoord = { x : ., y : . }; //用户坐标:相对于原始SVG,坐标位置 var user ...
- PHP出现SSL certificate:unable to get local issuer certificate的解决办法
当本地curl需要访问https时,如果没有配置证书,会出现SSL certificate: unable to get local issuer certificate错误信息. 解决办法: 1.下 ...