【转】Fst指数
【转】Fst指数

群体遗传学--Fst指数,即群体间分化指数,用于群体间分化分析。


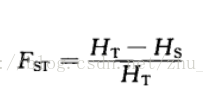

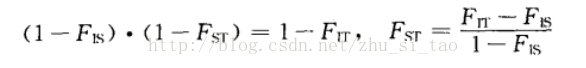

Pi主要用来衡量每个site的nucleotide divergency。
这几个参数同样可以通过vcftools来计算:
vcftools:
vcftools --vcf test.vcf --window-pi 3000 --out Tenera
vcftools --vcf test.vcf --TajimaD 3000 --out Tenera
vcftools --vcf test.vcf --weir-fst-pop A2.txt --weir-fst-pop A134567.txt --fst-window-size 3000 --out A2.all.Fst
【转】Fst指数的更多相关文章
- Fst指数说明
群体遗传学--Fst指数,即群体间分化指数,用于群体间分化分析. 群体遗传学中衡量群体间分化程度的指标有很多种,最常用的就是Fst指数.Fst指数,由F统计量演变而来.F统计量(FIS,FIT,FST ...
- 使用vcftools或者gcta计算群体间固定指数(Fixation index,FST)
下列所用到的数据均为千人基因组数据库 1.通过vcftools计算FST 命令行如下: ./vcftools --vcf input_data.vcf --weir-fst-pop populatio ...
- [LeetCode] H-Index 求H指数
Given an array of citations (each citation is a non-negative integer) of a researcher, write a funct ...
- UVA 10692 Huge Mods(指数循环节)
指数循环节,由于a ^x = a ^(x % m + phi(m)) (mod m)仅在x >= phi(m)时成立,故应注意要判断 //by:Gavin http://www.cnblogs. ...
- 股指的趋势持续研究(Hurst指数)
只贴基本的适合小白的Matlab实现代码,深入的研究除了需要改进算法,我建议好好研究一下混沌与分形,不说让你抓住趋势,至少不会大亏,这个资金盈亏回调我以前研究过. function [line_H,R ...
- 使用excel计算指数平滑和移动平均
指数平滑法 原数数据如下: 点击数据——数据分析 选择指数平滑 最一次平滑 由于我们选择的区域是B1:B22,第一个单元格“钢产量”,被当做标志,所以我们应该勾选标志.当我们勾选了标志后,列中的第 ...
- 快速得出e指数的算法
, b, c = , d, e = , f[]; int main() { for (;b - c;) f[b++] = gap; , c;c-=, printf("%.4d ", ...
- 决策树-预测隐形眼镜类型 (ID3算法,C4.5算法,CART算法,GINI指数,剪枝,随机森林)
1. 1.问题的引入 2.一个实例 3.基本概念 4.ID3 5.C4.5 6.CART 7.随机森林 2. 我们应该设计什么的算法,使得计算机对贷款申请人员的申请信息自动进行分类,以决定能否贷款? ...
- 关于jquery on方法进行事件绑定触发次数指数叠加的问题
发生环境: $modal.on('click', '#search',function(e){}); 上面代码的语法是这样的: .on( events [, selector ] [, data ], ...
随机推荐
- java课程课后作业190502之单词统计续集
第1步:输出单个文件中的前 N 个最常出现的英语单词. 功能1:输出文件中所有不重复的单词,按照出现次数由多到少排列,出现次数同样多的,以字典序排列. 功能2: 指定文件目录,对目录下每一个文件执行统 ...
- Abstract抽象类 && Interface接口
# 抽象类 ## 将相同的但是不确定的动作提取出来,抽象化,抽象类的意义在于,在子类中进行实现. ## 抽象类可以被继承,子类继承抽象类时,需要对抽象方法进行完全实现. ## 抽象方法不能有方法体. ...
- Spring Boot without the web server
https://stackoverflow.com/questions/26105061/spring-boot-without-the-web-server/28565277 1. spring.m ...
- python np array转json
np array转json import numpy as np import codecs, json a = np.arange().reshape(,) # a by array b = a.t ...
- Linux 目录变化监听 - python代码实现
在python中 文件监控主要有两个库, 一个是pyinotify ( https://github.com/seb-m/pyinotify/wiki ),pyinotify依赖于Linux平台的in ...
- [CISCN2019 总决赛 Day2 Web1]Easyweb
0x00 知识点 1:备份文件泄露 2:SQL注入 3:php短标签 短标签<? ?>需要php.ini开启short_open_tag = On,但<?= ?>不受该条控制. ...
- CMakeLists添加内部库
SET(RTABMap_LIBRARIES ${PROJECT_SOURCE_DIR}/bin/librtabmap_core.so ${PROJECT_SOURCE_DIR}/bin/librtab ...
- python进阶(三)~~~装饰器和闭包
一.闭包 满足条件: 1. 函数内嵌套一个函数: 2.外层函数的返回值是内层函数的函数名: 3.内层嵌套函数对外部作用域有一个非全局变量的引用: def func(): print("=== ...
- 吴裕雄--天生自然TensorFlow2教程:数学运算
import tensorflow as tf b = tf.fill([2, 2], 2.) a = tf.ones([2, 2]) a+b a-b a*b a/b b // a b % a tf. ...
- one_day_one_linuxCmd---光标快捷操作
<坚持每天学习一个 linux 命令,今天我们来学习 切换光标的常用命令> 摘要:最近经常使用 xshell 软件来远程连接各种机器,在 bin/bash 下输入各种命令,因为都是一些非常 ...