写代码?程序猿?你不能不懂的八大排序算法的Python实现
信息获取后通常需要进行处理,处理后的信息其目的是便于人们的应用。信息处理方法有多种,通常由数据的排序,查找,插入,删除等操作。本章介绍几种简单的数据排序算法和高效的排序算法.
本章主要涉及到的知识点有:
简单排序算法: 学会选择排序、冒泡排序、桶排序、插入排序的原理以及代码编写
高效排序算法: 理解希尔排序,基数排序,快速排序和归并排序的原理

1. 简单排序算法
简单排序算法包括选择排序、冒泡排序、桶排序和插入排序,本节重点介绍以上四种简单排序算法。
1.1 选择排序
基本思想:
每一趟从待排序的数据元素中选出最小(或最大)的一个元素,顺序放在待排序的数列的最前,知道全部待排序的数据元素排完。
排序过程:
例如:
初始:[5 4 6 8 7 1 2 3]
第一趟排序后 1 [4 6 8 7 5 2 3]
第二趟排序后 1 2 [6 8 7 5 4 3]
第三趟排序后 1 2 3 [8 7 5 4 6]
第四趟排序后 1 2 3 4 [7 5 8 6]
第五趟排序后 1 2 3 4 5 [7 8 6]
第六趟排序后 1 2 3 4 5 6 [8 7]
第七趟排序后 1 2 3 4 5 6 7 [8]
最后排序结果 1 2 3 4 5 6 7 8
对应代码:
a = [5, 4, 6, 8, 7, 1, 2, 3]
n = len(a)
for i in range(n - 1):
k = i
for j in range(i + 1, n):
if a[j] < a[k]:
k = j
if k != i:
temp = a[i]
a[i] = a[k]
a[k] = temp
print(a)
1.2 冒泡排序
基本思想:
所谓冒泡排序就是依次将两个相邻的数进行比较,大的在前面,小的在后面。即先比较第一个数和第二个数,大数在前,小数在后,然后比较第2个数和第3个数,直到比较最后两个数。第一趟结束后,最小数的数一定在最后。第二趟在第一趟的基础上重复上述操作。
由于排序过程中总是大数在前,小数在后, 相当于气泡上升,所以叫冒泡排序。
大数在前,小数在后排序后得到的是降序,小数在前,大数在后排序后得到的是升序结果。
排序过程(降序)
初始数据:4 5 6 1 2 3
第一趟:
比较前两个数,4比5小,交换位置 5 4 6 1 2 3
比较第2第3个数,4比6小,交换位置 5 6 4 1 2 3
比较第3第4个数,5比1大,位置不变 5 6 4 1 2 3
比较第4第5个数,1比2小,交换位置 5 6 4 2 1 3
比较最后两个数 ,1比3小,交换位置 5 6 4 2 3 1
第一趟结束
第二趟重复第一趟过程得到 6 5 4 3 2 1
排序完毕。
可以发现,第二趟结束已经排好序了,实际上对于一组数据排n-1趟一定能排好序。因为第i趟都会有前i小的数排序好,n-1趟前n-1小的数已排好序,最后一个数自然也排好序了。
对应代码:
a = [4, 5, 6, 1, 2, 3]
n = len(a)
for i in range(n - 1):
for j in range(n - i - 1):
if a[j] < a[j + 1]:
temp = a[j]
a[j] = a[j + 1]
a[j + 1] = temp
print(a)
1.3 桶排序
基本思想:
桶排序的思想是若待排序的记录的关键字在一个明显有限范围内(整型)时,可设计有限个有序桶,每个桶只能装与之对应的值,顺序输出各桶的值,将得到有序的序列。
例如,输入n个0~9之间的整数,由小到大排序输出
我们可以准备10个桶依次编号为0~9。输入的数0入0号桶,1入1号桶,依次类推。
如图所示:

先准备好10个空桶并编号。
依次输入8个整数:2,5,6,8,5,2,9,6
每输入一次就将数放入对应的桶。
输入完毕后桶内数据如图所示:

桶排序过程
2号桶内有两个数字2,5号桶内有两个数字5,6号桶内有两个数字6,8号桶内有一个数字8,9号桶内有一个数字9.
然后按桶编号从小到大的顺序将桶内数字输出,得到 2,2,5,5,6,6,8,9
此时就排好续了。
实现代码:
b={0:0,1:0,2:0,3:0,4:0,5:0,6:0,7:0,8:0,9:0}
n=eval(input("输入整数n"))
for i in range(n):
x=eval(input("输入0~9之间的整数"))
b[x]+=1
for key in range(10):
while b[key]>0:
print(key,end=' ')
b[key]-=1
1.4插入排序
基本思想:
插入排序是一种简单的排序方法,其算法的基本思想是:
假设待排序的数据存放在数组a[1…n]中,增加一个哨兵节点x.
a[1]自成一个有序区,无序区为a[2…n];
从i=2起直至i=n为止,将a[i]放在恰当的位置,使a[1…i]数据序列有序;
x=a[i]
将x与前i-1个数比较,j=i-1;while(x<a[j]) j-=1
将a数组的元素从j位置开始向后移动:for k in range(j,i+1,-1): a[k]=a[k-1]
a[j]=x
生成包含n个数据的有序区。
例如 a=[3 2 4 1 6 5 2 7]
排序过程:
第0步:[3] 2 4 1 6 5 2 7
第1步:[2 3] 4 1 6 5 2 7
第2步:[2 3 4] 1 6 5 2 7
第3步:[1 2 3 4] 6 5 2 7
第4步:[1 2 3 4 6] 5 2 7
第5步:[1 2 3 4 5 6] 2 7
第6步:[1 2 2 3 4 5 6] 7
第7步:[1 2 2 3 4 5 6 7]
插入排序的时间复杂度为O(n*n)。插入排序适用于数据已经排好序,插入一个新数据的情况
实现代码:
a = [0, 3, 2, 4, 1, 6, 5, 2, 7]
n = len(a)
for i in range(2, n):
x = a[i]
j = i - 1
while x < a[j]:
a[j + 1] = a[j]
j -= 1
a[j + 1] = x
print(a)
**注意:**此数组有效数据从i=1开始,a[0]=0,是为了运算方便补上的。
2. 高效排序算法
第一节介绍了简单的排序算法,但在实际应用中,简单的排序算法很难达到效率的要求,所以本节介绍了两种高效的排序算法,使排序时间复杂度大大减少。
2.1 快速排序
基本思想:
快速排序是一种采用分治法解决问题的一个典型应用,也是冒泡排序的一种改进。它的基本思想是,通过一趟排序将待排记录分割成独立的两部分,其中一部分均比另一部分小,则可分别对这两部分继续进行排序,已达到整个序列有序。排序的时间复杂度为O(nlogn),相比于简单排序算法,运算效率大大提高。
算法步骤:
① 从序列中取出一个数作为中轴数
② 将比这个数大的数放到它的右边,小于或等于他的数放到它的左边。
③ 再对左右区间重复第二步,知道各区间只有一个数
例如:对以下10个数进行快速排序:
6 1 2 7 9 3 4 5 10 8
以第一个数为基准数
在初始状态下,数字6在序列的第1位。我们的目标是将6挪到序列中间的某个位置,假设这个位置是k。现在就需要寻找这个k,并且以第k位为分界点,左边的数都≤6,右边的数都≥6。那么如何找到这个位置k呢?
我们要知道,快速排序其实是冒泡排序的一种改进,冒泡排序每次对相邻的两个数进行比较,这显然是一种比较浪费时间的。
而快速排序是分别从两端开始”探测”的,先从右往左找一个小于6的数,再从左往右找一个大于6的数,然后交换他们。这里可以用两个变量i和j,分别指向序列最左边和最右边。我们为这两个变量起个好听的名字“哨兵i”和“哨兵j”。刚开始的时候让哨兵i指向序列的最左边,指向数字6。让哨兵j指向序列的最右边,指向数字8。

首先哨兵j开始出动。因为此处设置的基准数是最左边的数,所以需要让哨兵j先出动,这一点非常重要。哨兵j一步一步地向左挪动,直到找到一个小于6的数停下来。接下来哨兵i再一步一步向右挪动),直到找到一个数大于6的数停下来。最后哨兵j停在了数字5面前,哨兵 i停在了数字7面前
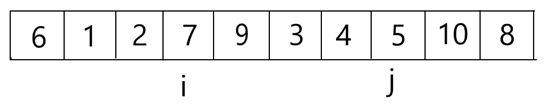
现在交换哨兵i和哨兵j所指向元素的值。交换之后的序列如下。

到此,第一次交换结束。接下来开始哨兵j继续向左挪动(再友情提醒,每次必须是哨兵j先出发)。他发现了4<6,停下来。哨兵i也继续向右挪动的,他发现了9>6,停下来。此时再次进行交换,交换之后的序列如下

第二次交换结束。哨兵j继续向左挪动,他发现了3<6,又停下来。哨兵i继续向右移动,此时哨兵i和哨兵j相遇了,哨兵i和哨兵j都走到3面前。说明此时“探测”结束。我们将基准数6和3进行交换。交换之后的序列如下。

到此第一轮“探测”真正结束。现在基准数6已经归为,此时以基准数6为分界点,6左边的数都小于等于6,6右边的数都大于等于6。
现在我们将第一轮“探测”结束后的序列,以6为分界点拆分成两个序列,左边的序列是“3 1 2 5 4”,右边的序列是“9 7 10 8”。接下来还需要分别处理这两个序列,因为6左边和右边的序列目前都还是混乱的。不过不要紧 ,我们已经掌握了方法,接下来只要模拟刚才的方法分别处理6左边和右边的序列即可。
实际上快速排序的每一轮处理其实就是将这一轮的基准数归为,直到所有的数都归为为止,排序就结束了。
实现代码:
def qsort(l,r):
if(l>r):
return None
tmp=a[l]
i=l
j=r
while i!=j:
while(a[j]>=tmp and j>i):
j-=1
while(a[i]<=tmp and j>i):
i+=1
if(j>i):
t=a[i]
a[i]=a[j]
a[j]=t
a[l]=a[i]
a[i]=tmp
qsort(l,i-1)
qsort(i+1,r)
2.2归并排序
基本思想:
归并排序是由递归实现的,主要是分而治之的思想,也就是通过将问题分解成多个容易求解的局部性小问题来解开原本的问题的技巧。
另外,归并排序在合并两个已排序数组时,如果遇到了相同的元素,只要保证前半部分数组优先于后半部分数组, 相同元素的顺序就不会颠倒。所以归并排序属于稳定的排序算法。
每次分别排左半边和右半边,不断递归调用自己,直到只有一个元素递归结束,开始回溯,调用merge函数,合并两个有序序列,再合并的时候每次给末尾追上一个最大int这样就不怕最后一位的数字不会被排序。
排序过程:

代码实现:
def MergeSort(lists):
if len(lists) <= 1:
return lists
num = int( len(lists) / 2 )
left = MergeSort(lists[:num])
right = MergeSort(lists[num:])
return Merge(left, right)
def Merge(left,right):
r, l=0, 0
result=[]
while l<len(left) and r<len(right):
if left[l] <= right[r]:
result.append(left[l])
l += 1
else:
result.append(right[r])
r += 1
result += list(left[l:])
result += list(right[r:])
return result
print MergeSort([1, 2, 3, 4, 5, 6, 7, 90, 21, 23, 45])
2.3基数排序:
基本思想:
基数排序(radix sort)属于“分配式排序”(distribution sort),又称“桶子法”(bucket sort)或bin sort,顾名思义,它是透过键值的部份资讯,将要排序的元素分配至某些“桶”中,藉以达到排序的作用。参考桶排序。
基数排序算法不依靠直接比较元素排序。而是采用分配式排序,单独处理元素的每一位。从最高位向最低位处理称为:最高位优先(MSD)反之称为:最低位优先(LSD)。
下面以最低位优先为例:
(1)准备10个容器,编号0-9,对应数字0-9。 容器是有序的(按添加顺序)
(2)然后按待排序元素的某一位上的数字(比如:个位/十位/百位)将其存放到对应容器中(数字相同,如: 个位是数字1时, 就把这个元素放在1号桶),所有元素这样处理完后,再从0号容器开始依次到9号容器, 将其中的元素顺序取出放回原数组,然后再从下一位开始…(比如个位处理完后, 再处理十位/百位…最高位)
基数排序,可以称之为,进阶版的桶排序。
排序过程:
这个图片的来源
代码实现:
import math
def sort(a, radix=10):
"""a为整数列表, radix为基数"""
K = int(math.ceil(math.log(max(a), radix))) # 用K位数可表示任意整数
bucket = [[] for i in range(radix)] # 不能用 [[]]*radix
for i in range(1, K+1): # K次循环
for val in a:
bucket[val%(radix**i)/(radix**(i-1))].append(val) # 析取整数第K位数字 (从低到高)
del a[:]
for each in bucket:
a.extend(each) # 桶合并
bucket = [[] for i in range(radix)]
2.4 希尔排序
基本思想:
希尔排序,也称递减增量排序算法,是插入排序的一种更高效的改进版本。希尔排序是非稳定排序算法。同时也突破了之前内排序算法复杂度为O(n2)的限制。
希尔排序是基于插入排序的以下两点性质而提出改进方法的:
插入排序在对几乎已经排好序的数据操作时,效率高,即可以达到线性排序的效率
插入排序一般来说是低效的,因为插入排序每次只能将数据移动一位
该方法的基本思想是:先将整个待排元素序列分割成若干个子序列(由相隔某个“增量”的元素组成的)分别进行直接插入排序,然后依次缩减增量再进行排序,待整个序列中的元素基本有序(增量足够小)时,再对全体元素进行一次直接插入排序。因为直接插入排序在元素基本有序的情况下(接近最好情况),效率是很高的,因此希尔排序在时间效率上比前两种方法有较大提高。
其中增量序列的选择是非常关键的,但通常我们取步长为n/2(数组长度的一般)然后一直取半直到1。
算法过程:

图片是之前看到的,如果有人知道出处,希望可以在评论区中指出,感谢。
实现代码:
a = [56,52,-96,-53,23,-789,520] #测试案例
b = len(a) #列表长度
gap = b // 2 #初始步长设置为总长度的一半
while gap >= 1:
for i in range (b):
j = i
while j>=gap and a[j-gap] > a[j]: #在每一组里面进行直接插入排序
a[j],a[j-gap] = a[j-gap],a[j]
j-= gap
gap=gap//2 #更新步长
print(a)
写代码?程序猿?你不能不懂的八大排序算法的Python实现的更多相关文章
- Java常用排序算法+程序员必须掌握的8大排序算法+二分法查找法
Java 常用排序算法/程序员必须掌握的 8大排序算法 本文由网络资料整理转载而来,如有问题,欢迎指正! 分类: 1)插入排序(直接插入排序.希尔排序) 2)交换排序(冒泡排序.快速排序) 3)选择排 ...
- Java 常用排序算法/程序员必须掌握的 8大排序算法
Java 常用排序算法/程序员必须掌握的 8大排序算法 分类: 1)插入排序(直接插入排序.希尔排序) 2)交换排序(冒泡排序.快速排序) 3)选择排序(直接选择排序.堆排序) 4)归并排序 5)分配 ...
- 八大排序算法详解(动图演示 思路分析 实例代码java 复杂度分析 适用场景)
一.分类 1.内部排序和外部排序 内部排序:待排序记录存放在计算机随机存储器中(说简单点,就是内存)进行的排序过程. 外部排序:待排序记录的数量很大,以致于内存不能一次容纳全部记录,所以在排序过程中需 ...
- 写在程序猿的困惑(特别Java程序猿)入行一年,感觉我不知道接下来该怎么办才能不断进步的,寻求翼
入行了一年.感觉不知道接下来该怎么做才干继续进步了,求不吝赐教(V2EX) @kafka0102 :做技术能够学的东西太多了.仅仅是在不同的阶段做好不同的规划.要结合当前所做的事情去做更深入或广度的学 ...
- 八大排序算法JS及PHP代码实现
从学习数据结构开始就接触各种算法基础,但是自从应付完考试之后就再也没有练习过,当在开发的时候也是什么时候使用什么时候去查一下,现在在学习JavaScript,趁这个时间再把各种基础算法整理一遍,分别以 ...
- [转]Java 常用排序算法/程序员必须掌握的 8大排序算法
本文转自:http://www.cnblogs.com/qqzy168/archive/2013/08/03/3219201.html 本文由网络资料整理转载而来,如有问题,欢迎指正! 分类: 1)插 ...
- 八大排序算法——堆排序(动图演示 思路分析 实例代码java 复杂度分析)
一.动图演示 二.思路分析 先来了解下堆的相关概念:堆是具有以下性质的完全二叉树:每个结点的值都大于或等于其左右孩子结点的值,称为大顶堆:或者每个结点的值都小于或等于其左右孩子结点的值,称为小顶堆.如 ...
- 八大排序算法——希尔(shell)排序(动图演示 思路分析 实例代码java 复杂度分析)
一.动图演示 二.思路分析 希尔排序是把记录按下标的一定增量分组,对每组使用直接插入排序算法排序:随着增量逐渐减少,每组包含的关键词越来越多,当增量减至1时,整个文件恰被分成一组,算法便终止. 简单插 ...
- 八大排序算法——基数排序(动图演示 思路分析 实例代码java 复杂度分析)
一.动图演 二.思路分析 基数排序第i趟将待排数组里的每个数的i位数放到tempj(j=1-10)队列中,然后再从这十个队列中取出数据,重新放到原数组里,直到i大于待排数的最大位数. 1.数组里的数最 ...
随机推荐
- pip 命令参数以及如何配置国内镜像源
文章更新于:2020-04-05 注:如果 pip 命令不可以用,参见:python pip命令不能用 文章目录 一.参数详解 1.命令列表 2.通用参数列表 二.实际应用 1.常用命令 2.`pip ...
- Linux 磁盘管理篇,开机挂载
设置开机挂载需要到 /etc/fstab 里设置 第一列:磁盘设备文件名或该设备的label 第二列:挂载点 第三列:磁盘分区文件系统 第四列:文件系统参数 第五列:能否被dump备份命令作用 第六列 ...
- 数据结构和算法(Golang实现)(11)常见数据结构-前言
常见数据结构及算法 数据结构主要用来组织数据,也作为数据的容器,载体. 各种各样的算法,都需要使用一定的数据结构来组织数据. 常见的典型数据结构有: 链表 栈和队列 树 图 上述可以延伸出各种各样的术 ...
- 子域名爆破工具:OneForALL
0x00 简介 OneForAll是一款功能强大的子域收集工具 0x01 下载地址 码云: https://gitee.com/shmilylty/OneForAll.git Github: http ...
- 如何改变Xcode字体大小?
运行Xcode后依次点击左上角Xcode/Preferences/Fonts & Colors里就可以调整,在右边随便点中一个字体就可以调整这个字体的大小和颜色了,按command+a可以将所 ...
- AJ学IOS 之微博项目实战(8)用AFNetworking和SDWebImage简单加载微博数据
AJ分享,必须精品 一:效果 没有图文混排,也没有复杂的UI,仅仅是简单的显示出微博数据,主要介绍AFNetworking和SDWebImage的简单用法 二:加载数据AFNetworking AFN ...
- 对于不平凡的我来说,从小我就在想为啥别人就什么都能拥有,而看看自己却什么都没有,对于原来的我就会抱怨爸妈怎么没有别人父母都能给自己想要的,可我从未想过父母的文化只有小学,其实父母内心也有太多的辛酸,所以我不甘愿如此,从此让我在大学里面直接选择一个让我巨大的转折————IT。
对于不平凡的我来说,从小我就在想为啥别人就什么都能拥有,而看看自己却什么都没有,对于原来的我就会抱怨爸妈怎么没有别人父母都能给自己想要的,可我从未想过父母的文化只有小学,其实父母内心也有太多的辛酸,所 ...
- 从3dMax导出供threeJS使用的带动作模型与加载
评论区发现的建议,最近没空测试,先贴这 还有好多人说找不到插件的 https://pan.baidu.com/s/1Q5g0... 密码:b43e . 应该是他们现在只是维护blender,只有这个的 ...
- 068.Python框架Django之DRF视图集使用
一 视图集与路由的使用 使用视图集ViewSet,可以将一系列逻辑相关的动作放到一个类中: list() 提供一组数据 retrieve() 提供单个数据 create() 创建数据 update() ...
- windows批处理protoc生成C++代码
1 首先需要生成protoc的可执行文件,具体可以参考 https://www.cnblogs.com/cnxkey/articles/10152646.html 2 将单个protoc文件生成.h ...