给出两个单词(start和end)与一个字典,找出从start到end的最短转换序列
问题
给出两个单词(start和end)与一个字典,找出从start到end的最短转换序列。规则如下:
- 一次只能改变一个字母
- 中间单词必须在字典里存在
例如:
给出
start = "hit"
end = "cog"
dict = ["hot","dot","dog","lot","log"]
返回
[
["hit","hot","dot","dog","cog"],
["hit","hot","lot","log","cog"]
]
注意
- 所有单词的长度一样
- 所有单词中只有小写字母
初始思路
最直接的想法是从start开始,对每个字母位置从'a'到'z'尝试替换。如果替换字母后的单词在字典中,将其加入路径,然后以新单词为起点进行递归调用,否则继续循环。每层递归函数终止的条件是end出现或者单词长度*26次循环完毕。end出现时表示找到一个序列,对比当前最短序列做相应更新即可。
处理过程中需要注意的主要有几点:
- 不能相同字母替换,如hot第一个位置遍历到h时不应该处理。否则就会不断的在hot上死循环。因此在替换后前要做一次检查。
- 我们要找的是最短的转换方案,所以转换序列不应该出现重复的单词。否则组合将会有无数多种,如例子中的["hit","hot","dot","dog","dot","dog","dog",....."cog"]。这里我们可以使用一个unordered_set容器来保存某次一次替换序列中已出现过的单词,也可以每次使用std:find去搜索当前替换序列。如果使用unordered_set,在递归处理时,和单词序列一样,要在递归后做相应的出栈操作。
- 处理过程中如果发现当前处理序列长度已经超过当前最短序列长度,可以中止对该序列的处理,因为我们要找的是最短的序列。
class Solution {
public:
std::vector<std::vector<std::string>> findLadders(std::string start, std::string end, std::unordered_set<std::string> &dict)
{
std::vector<std::vector<std::string>> result;
std::vector<std::string> entry;
entry.push_back(start);
Find(start, end, dict, , result, entry);
return result;
}
private:
void Find(std::string& start, const std::string& end, const std::unordered_set<std::string> &dict
, size_t positionToChange, std::vector<std::vector<std::string>>& result, std::vector<std::string>& entry)
{
//如果长度已经等于当前结果中的长度,再找出来肯定就
//超过了,终止处理
if(!result.empty() && entry.size() == result[].size())
{
return;
}
for(size_t pos = positionToChange; pos < start.size(); ++pos)
{
char beforeChange = ' ';
for(int i = 'a'; i <= 'z'; ++i)
{
//防止同字母替换
if(start[pos] == i)
{
continue;
}
beforeChange = start[pos];
start[pos] = i;
//用std::find的话
/*
if(std::find(entry.begin(), entry.end(), start) != entry.end())
{
start[pos] = beforeChange;
continue;
}
*/
//如果单词已经用过的情况
if(!used_.empty() && used_.count(start)!= )
{
start[pos] = beforeChange;
continue;
}
if(start == end)
{
entry.push_back(start);
//只需要保存最短的序列
if(!result.empty())
{
if(entry.size() < result[].size())
{
result.clear();
result.push_back(entry);
}
else if(entry.size() == result[].size())
{
result.push_back(entry);
}
}
else
{
result.push_back(entry);
}
//完成一个序列,把前面加入的end弹出
entry.pop_back();
return;
}
if(dict.find(start) != dict.end())
{
entry.push_back(start);
used_.insert(start);
Find(start, end, dict, , result, entry);
used_.erase(*entry.rbegin());
entry.pop_back();
if(!entry.empty())
{
start = *entry.rbegin();
}
else
{
start[pos] = beforeChange;
}
}
else
{
start[pos] = beforeChange;
}
}
}
return;
}
std::unordered_set<std::string> used_;
};
递归实现
提交测试,Judge Small没有问题。Judge Large不幸超时。
优化
观察我们的处理方法,找到可变换后的单词后,我们会马上基于它继续查找。这是一种深度优先的查找方法,即英文的DFS(Depth-first search)。这对找出答案很可能是不利的,如果一开始进入了一条很长的序列,就会浪费了时间。而广度优先BFS(Breadth-first search)的方法似乎更合适,当找到一个序列时,这个序列肯定是最短的之一。
要进行广度优先遍历,我们可以在发现替换字母后的单词在字典中时,不马上继续处理它,而是将其放入一个队列中。通过队列先进先出的性质,就可以实现广度优先的处理了。由于最后要输出的是整个转换序列,为了简单起见,我们可以将当前已转换出的序列放入队列中,即队列形式为std::vector<std::vector<std::string>>,序列的最后一个元素就是下次处理时要继续转换的单词。
使用广度优先遍历后,还有一个特性使得我们可以更方便的处理深度优先中重复单词的问题。当一个单词在某一层(一层即从第一个单词到当前单词的长度一样的序列)出现后,后面再出现的情况肯定不会是最短序列(相当于走了回头路),因此我们可以在处理完一层后直接将已用过的单词从字典中去除。需要注意的是,同一层是不能去除的,如例子中的hot在两个序列的第二层中都出现了。这样我们就需要一个容器把当前层用过的单词保存起来,等处理的层数发生变化时再将它们从字典里移除。
最后要注意的是查找结束的条件。由于找到了一个序列后该序列只是最短的之一,我们还要继续进行处理,直到队列中当前层都处理完毕。所以我们要在找到一个序列后将它的长度记录下来,当要处理的序列长度已经大于该值时,就可以结束查找了。
class Solution {
public:
std::vector<std::vector<std::string> > findLadders(std::string start, std::string end, std::unordered_set<std::string> &dict)
{
std::queue<std::vector<std::string>> candidate;
std::vector<std::vector<std::string>> result;
std::unordered_set<std::string> usedWord;
std::string currentString;
bool foundShortest = false;
size_t shortest = ;
size_t previousPathLen = ;
candidate.push({start});
while(!candidate.empty())
{
currentString = *candidate.front().rbegin();
if(candidate.front().size() != previousPathLen)
{
for(auto iter = usedWord.begin(); iter != usedWord.end(); ++iter)
{
dict.erase(*iter);
}
}
if(foundShortest && candidate.front().size() >= shortest)
{
break;
}
for(size_t pos = ; pos < start.size(); ++pos)
{
char beforeChange = ' ';
for(int i = 'a'; i <= 'z'; ++i)
{
beforeChange = currentString[pos];
if(beforeChange == i)
{
continue;
}
currentString[pos] = i;
if(dict.count(currentString) > )
{
usedWord.insert(currentString);
if(currentString == end)
{
result.push_back(candidate.front());
result.rbegin()->push_back(end);
foundShortest = true;
shortest = result.rbegin()->size();
}
else
{
std::vector<std::string> newPath(candidate.front());
newPath.push_back(currentString);
candidate.push(newPath);
}
}
currentString[pos] = beforeChange;
}
}
if(!candidate.empty())
{
previousPathLen = candidate.front().size();
candidate.pop();
}
}
return result;
}
};
BFS实现1
提交后Judge Large多处理了几条用例,但是最后还是超时了。
再次优化
一个比较明显的优化点是我们把存储序列的vector放到了队列中,每次都要拷贝旧队列然后产生新队列。回想一下我们使用vector的原因,主要是为了能保存序列,同时还能获得当前序列的长度。为了实现这两个目的,我们可以定义如下结构体:

1 struct PathTag
2 {
3 PathTag* parent_;
4 std::string value_;
5 int length_;
6
7 PathTag(PathTag* parent, const std::string& value, int length) : parent_(parent), value_(value), length_(length)
8 {
9 }
10 };
结构体记录了当前单词的前一个单词以及当前的序列长度。有了这个结构体,我们在最后找到end后就可以通过不断往前回溯得出整个路径。而这个路径是反向的,最后还需要做一次倒置操作。改进前面的BFS代码如下(需要注意的是,由于LeetCode里不能使用智能指针,我们通过辅助函数来申请和释放裸指针而不是直接new。如果不关心内存问题的话直接new了不管也可。):
class Solution{
public:
~Solution()
{
for(auto iter = pool_.begin(); iter != pool_.end(); ++iter)
{
delete *iter;
}
}
std::vector<std::vector<std::string> > findLadders(std::string start, std::string end, std::unordered_set<std::string> &dict)
{
std::queue<PathTag*> candidate;
std::vector<std::vector<std::string>> result;
std::unordered_set<std::string> usedWord;
std::string currentString;
bool foundShortest = false;
size_t shortest = ;
size_t previousPathLen = ;
candidate.push(AllocatePathTag(nullptr, start, ));
while(!candidate.empty())
{
PathTag* current = candidate.front();
currentString = current->value_;
if(current->length_ != previousPathLen)
{
for(auto iter = usedWord.begin(); iter != usedWord.end(); ++iter)
{
dict.erase(*iter);
}
}
if(foundShortest && current->length_ >= shortest)
{
break;
}
for(size_t pos = ; pos < start.size(); ++pos)
{
char beforeChange = ' ';
for(int i = 'a'; i <= 'z'; ++i)
{
beforeChange = currentString[pos];
if(beforeChange == i)
{
continue;
}
currentString[pos] = i;
if(dict.count(currentString) > )
{
usedWord.insert(currentString);
if(currentString == end)
{
GeneratePath(result, current, currentString);
foundShortest = true;
shortest = result.rbegin()->size();
continue;
}
else
{
candidate.push(AllocatePathTag(current, currentString, current->length_ + ));
}
}
currentString[pos] = beforeChange;
}
}
if(!candidate.empty())
{
previousPathLen = current->length_;
candidate.pop();
}
}
return result;
}
private:
struct PathTag
{
PathTag* parent_;
std::string value_;
int length_;
PathTag(PathTag* parent, const std::string& value, int length) : parent_(parent), value_(value), length_(length)
{
}
};
PathTag* AllocatePathTag(PathTag* parent, const std::string& value, int length)
{
if(nextPoolPos_ >= pool_.size())
{
for(int i = ; i < ; ++i)
{
PathTag* newTag = new PathTag(nullptr, " ", );
pool_.push_back(newTag);
}
}
PathTag* toReturn = pool_[nextPoolPos_];
toReturn->parent_ = parent;
toReturn->value_ = value;
toReturn->length_ = length;
++nextPoolPos_;
return toReturn;
}
int nextPoolPos_;
std::vector<PathTag*> pool_;
void GeneratePath(std::vector<std::vector<std::string>>& result, PathTag* pathTag, const std::string& end)
{
std::vector<std::string> path;
path.push_back(end);
while(pathTag != nullptr)
{
path.push_back(pathTag->value_);
pathTag = pathTag->parent_;
}
size_t left = ;
size_t right = path.size() - ;
while(left < right)
{
std::swap(path[left], path[right]);
++left;
--right;
}
result.push_back(path);
}
};
BFS2
提交后Judge Large又多处理了几条用例,但是还是没能通过。
使用邻接列表
在继续优化之前,我们先来学习一个图论中的概念 - 邻接列表(Adjacency List)。具体细节可以参见这篇wiki:http://en.wikipedia.org/wiki/Adjacency_list 。简单来说,这是一个存储图中每个顶点的所有邻接顶点的数据结构。如无向图:
a
/ \
b --- c
它的邻接列表为:
a => b, c
b => a, c
c => a, b
具体到本问题,我们可以发现,start到end的所有序列,就是一个这些序列中所有单词为点组成的图。如果我们生成了该图的邻接列表,就可以不断的在每个单词的邻接列表里找到转换的下一个单词,从而最终找到end。那么,我们首先要对字典里的单词生成邻接列表:遍历字典里的单词,针对每个单词用前面逐字母替换的方法找出邻接单词,并保存起来。这里使用一个std::unordered_map<std::string, std::unordered_set<std::string>>来保存邻接列表。
有了邻接列表,寻找序列的方法就发生变化了。我们不再逐个替换字母,而是从start出发,遍历start的邻接顶点,将邻接顶点放入队列中。并重复操作直到队列为空。还有一个发生变化的地方是去重操作。由于不再遍历字典,现在我们发现非同层出现重复的单词就跳过它而不是从字典里删去。
剩下的生成路径的方法仍然和BFS2类似,全部代码如下:
class Solution {
public:
~Solution()
{
for(auto iter = pool_.begin(); iter != pool_.end(); ++iter)
{
delete *iter;
}
}
std::vector<std::vector<std::string> > findLadders(std::string start, std::string end, std::unordered_set<std::string> &dict)
{
nextPoolPos_ = ;
std::unordered_map<std::string, std::unordered_set<std::string>> adjacencyList;
std::string word;
for (auto iter = dict.begin(); iter != dict.end(); ++iter)
{
word = *iter;
BuildAdjacencyList(word, adjacencyList, dict);
}
std::vector<std::vector<std::string>> result;
std::queue<PathTag*> candidate;
std::unordered_map<std::string, int> usedWord;
std::string currentString;
bool foundShortest = false;
size_t shortest = ;
candidate.push(AllocatePathTag(nullptr, start, ));
while(!candidate.empty())
{
PathTag* current = candidate.front();
if(foundShortest && current->length_ >= shortest)
{
break;
}
candidate.pop();
auto adjacentIter = adjacencyList.find(current->value_);
if(adjacentIter != adjacencyList.end())
{
for(auto iter = adjacentIter->second.begin(); iter != adjacentIter->second.end(); ++iter)
{
if(*iter == end)
{
GeneratePath(result, current, *iter);
foundShortest = true;
shortest = result.rbegin()->size();
continue;
}
auto usedIter = usedWord.find(*iter);
if(usedIter != usedWord.end() && usedIter->second != current->length_ + )
{
continue;
}
usedWord[*iter] = current->length_ + ;
candidate.push(AllocatePathTag(current, *iter, current->length_ + ));
}
}
else
{
continue;
}
}
return result;
}
private:
struct PathTag
{
PathTag* parent_;
std::string value_;
int length_;
PathTag(PathTag* parent, const std::string& value, int length) : parent_(parent), value_(value), length_(length)
{
}
};
PathTag* AllocatePathTag(PathTag* parent, const std::string& value, int length)
{
if(nextPoolPos_ >= pool_.size())
{
for(int i = ; i < ; ++i)
{
PathTag* newTag = new PathTag(nullptr, " ", );
pool_.push_back(newTag);
}
}
PathTag* toReturn = pool_[nextPoolPos_];
toReturn->parent_ = parent;
toReturn->value_ = value;
toReturn->length_ = length;
++nextPoolPos_;
return toReturn;
}
int nextPoolPos_;
std::vector<PathTag*> pool_;
void GeneratePath(std::vector<std::vector<std::string>>& result, PathTag* pathTag, const std::string& end)
{
std::vector<std::string> path;
path.push_back(end);
while(pathTag != nullptr)
{
path.push_back(pathTag->value_);
pathTag = pathTag->parent_;
}
size_t left = ;
size_t right = path.size() - ;
while(left < right)
{
std::swap(path[left], path[right]);
++left;
--right;
}
result.push_back(path);
}
void BuildAdjacencyList(std::string& word, std::unordered_map<std::string, std::unordered_set<std::string>>& adjacencyList, const std::unordered_set<std::string>& dict)
{
std::string original = word;
for(size_t pos = ; pos < word.size(); ++pos)
{
char beforeChange = ' ';
for(int i = 'a'; i <= 'z'; ++i)
{
beforeChange = word[pos];
if(beforeChange == i)
{
continue;
}
word[pos] = i;
if(dict.count(word) > )
{
auto iter = adjacencyList.find(original);
if(iter != adjacencyList.end())
{
iter->second.insert(word);
}
else
{
adjacencyList.insert(std::pair<std::string, std::unordered_set<std::string>>(original, std::unordered_set<std::string>()));
adjacencyList[original].insert(word);
}
}
word[pos] = beforeChange;
}
}
}
};
邻接列表BFS
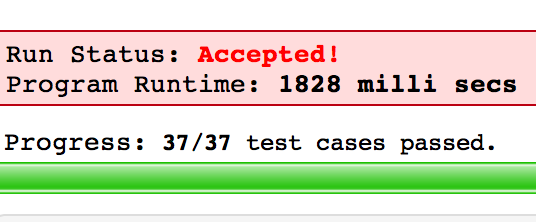
这回终于通过Judge Large了。
一种更快的解决方案
下面再介绍一种更快的解决方案,思路及代码来自niaokedaoren的博客。
前一个解决方案虽然能通过大数据集测试,但是为了保存路径信息我们额外引入了一个结构体而且因为需要用到指针使用了大量的new操作。还有什么不用保存所有路径信息的办法?
niaokedaoren的方案中使用了一个前驱单词表,即记录每一个单词的前驱单词是哪些。这样在遍历完毕后,我们从end出发递归就能把所有路径生成出来。但是由于前驱单词表不能记录当前的层次信息,似乎我们没法完成去重的工作。这个方案的巧妙之处就在于它没有使用我们通常的队列保存待处理的单词,一个单词一个单词先进先出处理的方法,而是使用两个vector来模拟队列的操作。我们从vector 1中遍历单词进行转换尝试,发现能转换的单词后将其放入vector 2中。当vector 1中的单词处理完毕后即为一层处理完毕,它里面的单词就可以从字典里删去了。接着我们对vector 2进行同样处理,如此反复直到当前处理的vector中不再有单词。我们发现vector 1和vector 2在不断地交换正处理容器和待处理容器的身份,因此可以通过将其放入一个数组中,每次循环对数组下标值取反实现身份的交替:
int current = 0;
int previous = 1;
循环
current = !current;
previous = !previous;
......
循环结束
完全代码如下:
class Solution {
public:
std::vector<std::vector<std::string> > findLadders(std::string start, std::string end, std::unordered_set<std::string> &dict)
{
result_.clear();
std::unordered_map<std::string, std::vector<std::string>> prevMap;
for(auto iter = dict.begin(); iter != dict.end(); ++iter)
{
prevMap[*iter] = std::vector<std::string>();
}
std::vector<std::unordered_set<std::string>> candidates();
int current = ;
int previous = ;
candidates[current].insert(start);
while(true)
{
current = !current;
previous = !previous;
for (auto iter = candidates[previous].begin(); iter != candidates[previous].end(); ++iter)
{
dict.erase(*iter);
}
candidates[current].clear();
for(auto iter = candidates[previous].begin(); iter != candidates[previous].end(); ++iter)
{
for(size_t pos = ; pos < iter->size(); ++pos)
{
std::string word = *iter;
for(int i = 'a'; i <= 'z'; ++i)
{
if(word[pos] == i)
{
continue;
}
word[pos] = i;
if(dict.count(word) > )
{
prevMap[word].push_back(*iter);
candidates[current].insert(word);
}
}
}
}
if (candidates[current].size() == )
{
return result_;
}
if (candidates[current].count(end))
{
break;
}
}
std::vector<std::string> path;
GeneratePath(prevMap, path, end);
return result_;
}
private:
void GeneratePath(std::unordered_map<std::string, std::vector<std::string>> &prevMap, std::vector<std::string>& path,
const std::string& word)
{
if (prevMap[word].size() == )
{
path.push_back(word);
std::vector<std::string> curPath = path;
reverse(curPath.begin(), curPath.end());
result_.push_back(curPath);
path.pop_back();
return;
}
path.push_back(word);
for (auto iter = prevMap[word].begin(); iter != prevMap[word].end(); ++iter)
{
GeneratePath(prevMap, path, *iter);
}
path.pop_back();
}
std::vector<std::vector<std::string>> result_;
};
niaokedaoren的方案
可以看到处理速度快了不少:
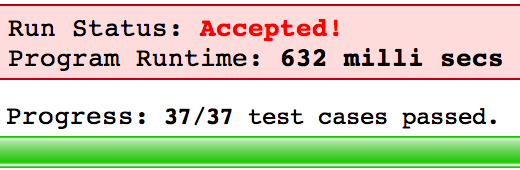
给出两个单词(start和end)与一个字典,找出从start到end的最短转换序列的更多相关文章
- 给出两个单词word1和word2,写一个函数计算出将word1 转换为word2的最少操作次数。
问题: 给出两个单词word1和word2,写一个函数计算出将word1 转换为word2的最少操作次数. 你总共三种操作方法: 1.插入一个字符 2.删除一个字符 3.替换一个字符 格式: 输入行输 ...
- 使用 JavaScript 中的变量、数据类型和运算符,计算出两个 number 类型的变量与一个 string 类型的变量的和,根据 string 类型处于运算符的不同位置得到不同的结果
查看本章节 查看作业目录 需求说明: 使用 JavaScript 中的变量.数据类型和运算符,计算出两个 number 类型的变量与一个 string 类型的变量的和,根据 string 类型处于运算 ...
- 给出2n+1个数,其中有2n个数出现过两次,如何用最简便的方法找出里面只出现了一次的那个数(转载)
有2n+1个数,其中有2n个数出现过两次,找出其中只出现一次的数 例如这样一组数3,3,1,2,4,2,5,5,4,其中只有1出现了1次,其他都是出现了2次,如何找出其中的1? 最简便的方法是使用异或 ...
- Word Ladder II——找出两词之间最短路径的所有可能
Given two words (start and end), and a dictionary, find all shortest transformation sequence(s) from ...
- pta 习题集 5-2 找出不是两个数组共有的元素 (5分)
给定两个整型数组,本题要求找出不是两者共有的元素. 输入格式: 输入分别在两行中给出两个整型数组,每行先给出正整数NN(≤20≤20),随后是NN个整数,其间以空格分隔. 输出格式: 在一行中按照数字 ...
- pta 7-1 找出不是两个数组共有的元素
给定两个整型数组,本题要求找出不是两者共有的元素. 输入格式: 输入分别在两行中给出两个整型数组,每行先给出正整数N(≤20),随后是N个整数,其间以空格分隔. 输出格式: 在一行中按照数字给出的顺序 ...
- PTA 找出不是两个数组共有的元素
7-2 找出不是两个数组共有的元素 (20 分) 给定两个整型数组,本题要求找出不是两者共有的元素. 输入格式: 输入分别在两行中给出两个整型数组,每行先给出正整数N(≤),随后是N个整数,其间以 ...
- 使用 Visual Studio 分析器找出应用程序瓶颈
VS的性能分析工具 性能分析工具的选择 打开一个“性能分析”的会话:Debug->Start Diagnotic Tools Without Debugging(或按Alt+F2),VS2013 ...
- 一起来刷《剑指Offer》——不修改数组找出重复的数字(思路及Python实现)
数组中重复的数字 在上一篇博客中<剑指Offer>-- 题目一:找出数组中重复的数字(Python多种方法实现)中,其实能发现这类题目的关键就是一边遍历数组一边查满足条件的元素. 然后我们 ...
随机推荐
- 详解 stream流
在本人之前的博文中,我们学习了 I/O流.NIO流的相关概念. 那么,在JDK8的更新内容中,提出了一个新的流 -- stream流 那么,现在,本人就来讲解下这个流: 目录 stream流 常用AP ...
- Charles抓包——弱网测试(客户端)
基础知识 网络延迟:网络延时指一个数据包从用户的计算机发送到网站服务器,然后再立即从网站服务器返回用户计算机的来回时间.通常使用网络管理工具PING(Packet Internet Grope)来测量 ...
- v&n赛 内存取证题解(已更新)
题目是一个raw的镜像文件 用volatility搜索一下进程 有正常的notepad,msprint,还有dumpit和truecrypt volatility -f mem.raw --profi ...
- SpringCloud(七)超时、重试
一.Ribbon(单独配置) 可以通过ribbon.xx来进行全局配置.也可以通过服务名.ribbon.xx来对指定服务配置 全局配置: ribbon: ConnectTimeout: 3000 #连 ...
- 牛顿迭代法的理解与应用( x 的平方根)
题目来源与LeetCode算法题中的第69题,具体内容如下(点击查看原题): 实现 int sqrt(int x) 函数. 计算并返回 x 的平方根,其中 x 是非负整数. 由于返回类型是整数,结果只 ...
- 解决cvc-complex-type.2.4.a: Invalid content was found starting with element
今天用myeclipse导入 一个项目出现后出现cvc-complex-type.2.4.a: Invalid content was found starting with element 'inf ...
- python os模块获取指定目录下的文件列表
bath_path = r"I:\ner_results\ner_results" dir_list1 = os.listdir(bath_path) for dir1 in di ...
- 天大福利!世界第一科技出版公司 Springer 免费开放 400 多本电子书!
前几天,世界著名的科技期刊/图书出版公司施普林格(Springer)宣布:免费向公众开放 400 多本正版的电子书!! Springer 即施普林格出版社,于1842 年在德国柏林创立,20 世纪60 ...
- CentOS配置Tomcat监听80端口,虚拟主机
2019独角兽企业重金招聘Python工程师标准>>> Tomcat更改默认端口为80 更改的配置文件是: /usr/local/tomcat/conf/server.xml [ro ...
- 限流 - Guava RateLimiter
2019独角兽企业重金招聘Python工程师标准>>> 限流 限流的目的是通过对并发访问/请求进行限速或者一个时间窗口内的的请求进行限速来保护系统,一旦并发访问/请求达到限制速率或者 ...