【Hadoop离线基础总结】Hadoop的架构模型
Hadoop的架构模型
1.x的版本架构模型介绍
架构图
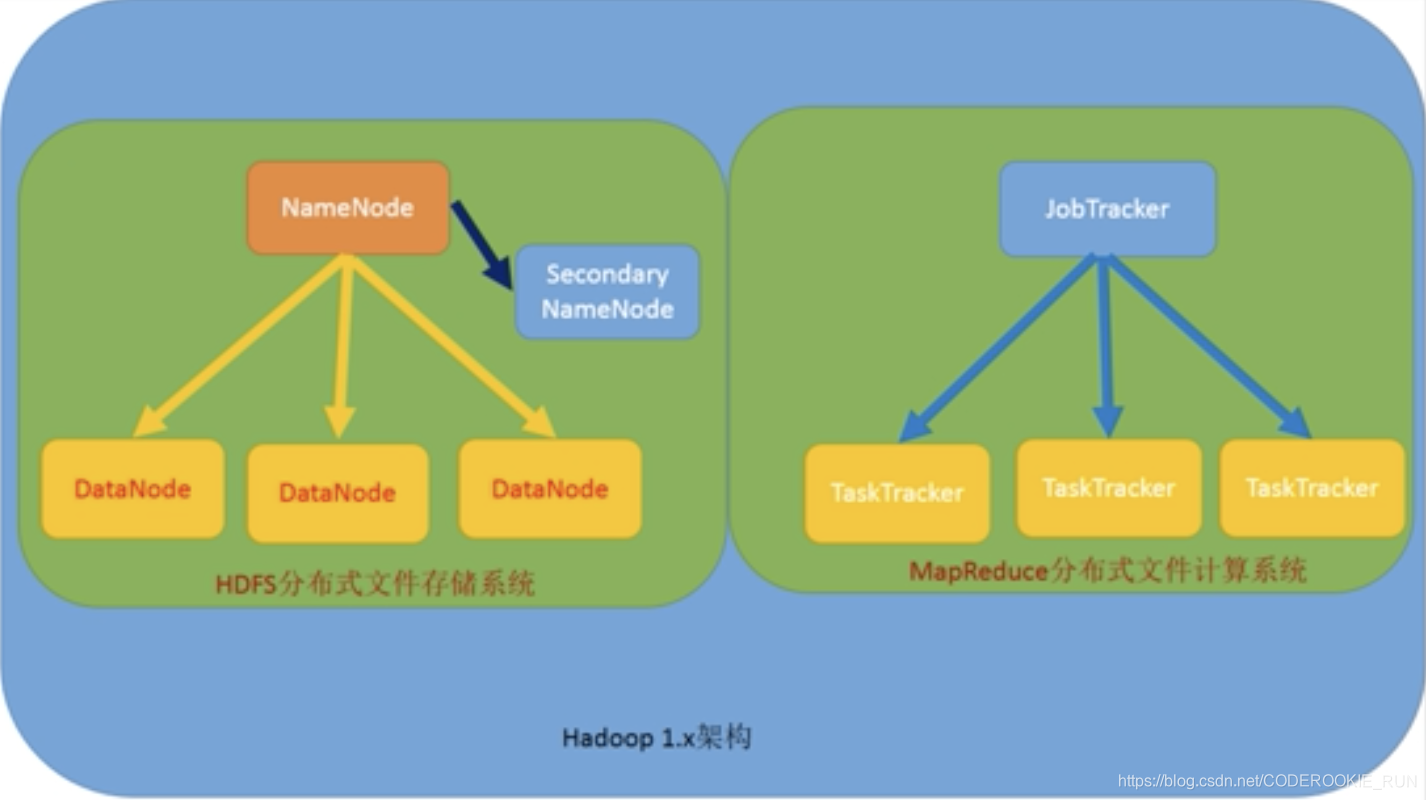
HDFS分布式文件存储系统(典型的主从架构)
NameNode:集群当中的主节点,主要用于维护集群当中的元数据信息,以及接受用户的请求,处理用户的请求
SecondaryNameNode:主要是辅助NameNode管理元数据信息
DataNode:集群当中的从节点,主要用于存储数据
什么是元数据?
元数据就是描述数据的数据。简单的来说,一个文件的存放位置、文件名称、打开方式、创建人、修改时间、文件大小、文件权限等这些都是描述性的数据,都可以称为元数据。拿到现实生活中来说,判断一个人是否是我们想要找到的人,他的样貌、身高、体型、穿着这些都是描述性的信息,也就是元数据。mapReduce分布式计算系统
JobTracker:主节点,接受用户请求,分配任务给taskTracker去执行
TaskTracker:从节点,主要用于接受jobTracker分配的任务
2.x的版本架构模型介绍
- 第一种:NameNode和ResourceManager单节点架构模型
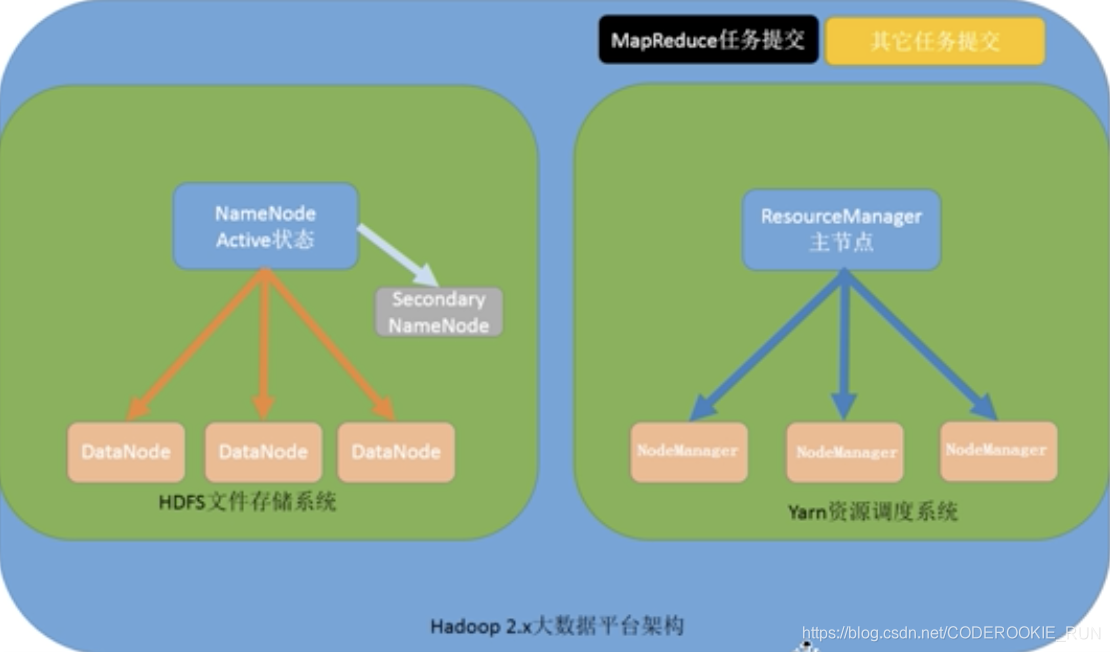
HDFS文件存储系统(典型的主从架构)
NameNode:集群当中的主节点,主要用于维护集群当中的元数据信息,以及接受用户的请求,处理用户的请求
SecondaryNameNode:主要是辅助NameNode管理元数据信息
DataNode:集群当中的从节点,主要用于存储数据
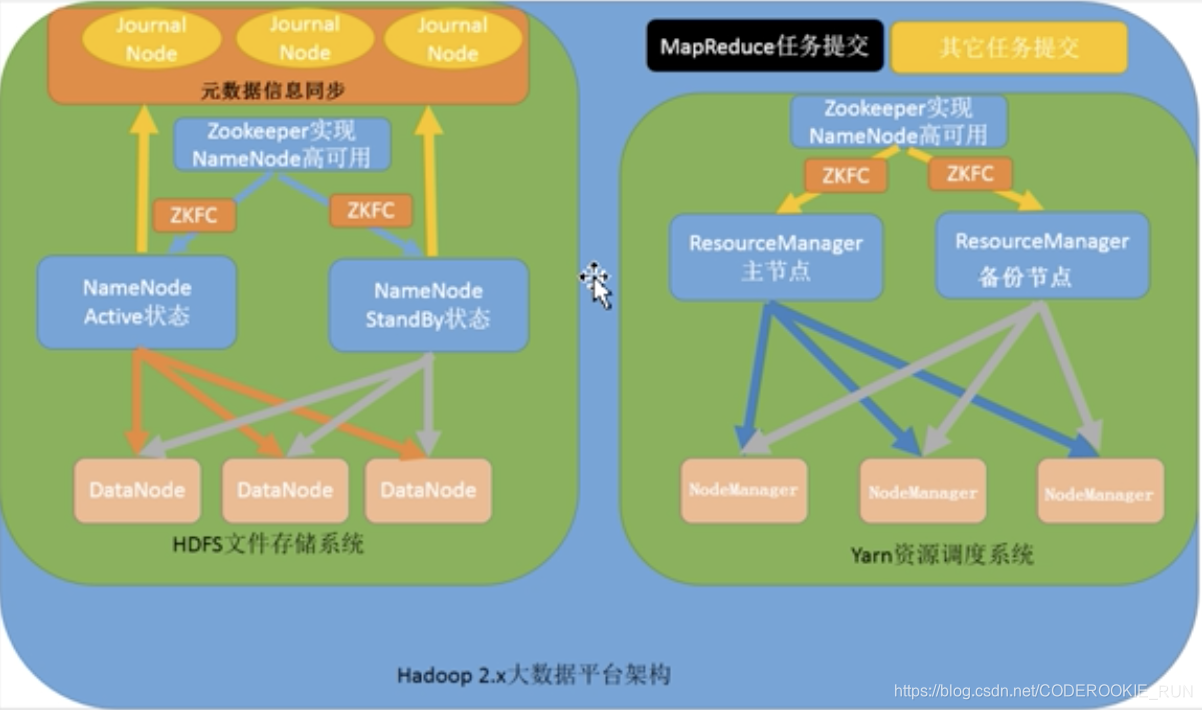
Yarn资源调度系统
ResourceManager:主节点,接受用户请求,分配资源(分配CPU、分配内存等)
NodeManager:从节点,主要用于处理计算任务
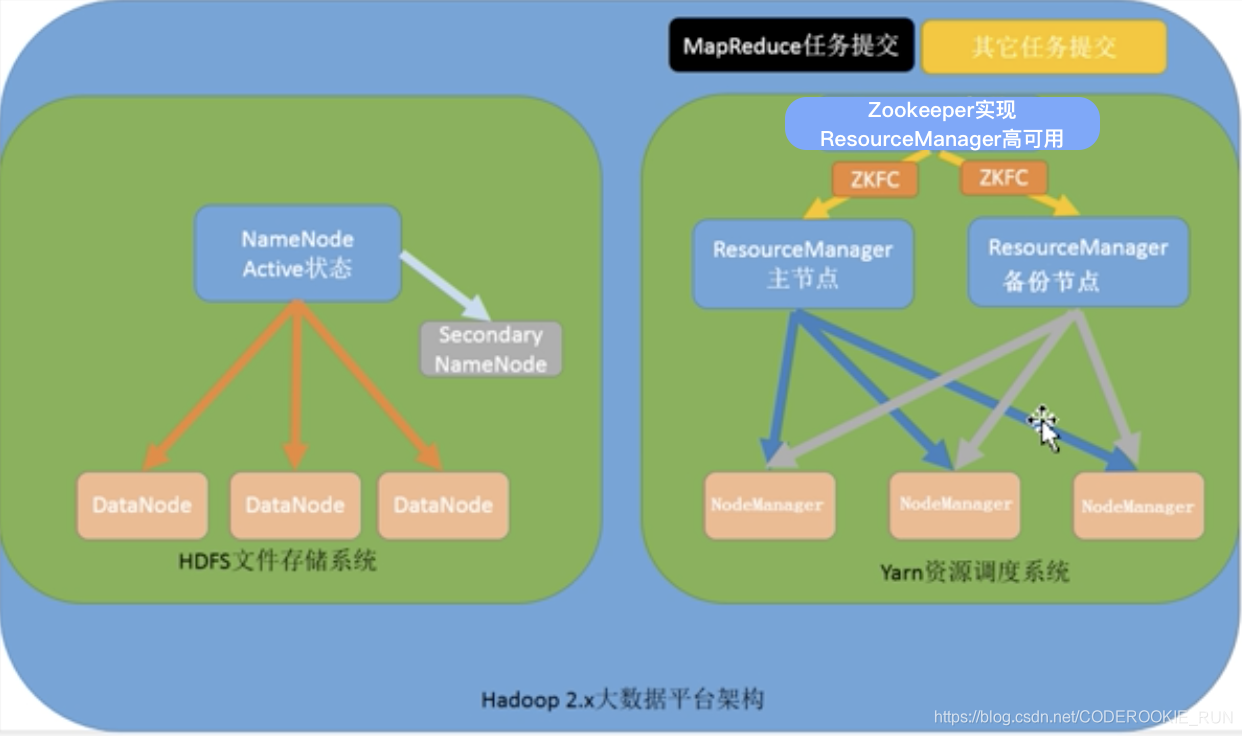
- 第二种:NameNode单节点和ResourceManager高可用架构模型
- 第三种:NameNode高可用和ResourceManager单节点架构模型
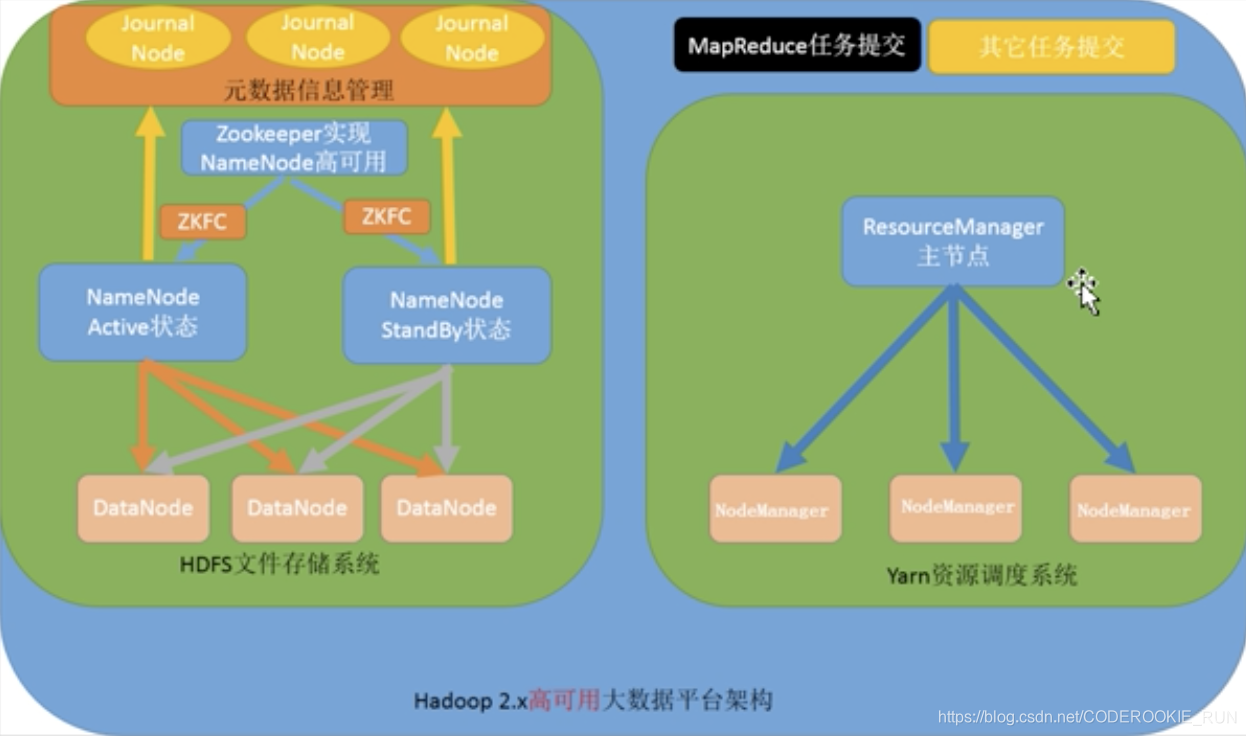
NameNode高可用
NameNode Active:处于活跃的主节点,处理用户请求,维护元数据信息
NameNode StandBy:处于待命的节点,当活跃的主节点出故障停止工作后,切换为活跃的主节点,对外提供服务
JournalNode:专门用于同步元数据信息(因为,如果NameNode高可用,就一定要保证两个NameNode的元数据信息一致,否则就会出现脑裂的问题。JournalNode机制就是用来解决这个问题的)
zkfc ( ZooKeeper FailLover Controller ):NameNode的守护进程,用于监听NameNode的状态,当NameNode Active出故障停机时,会立刻通知NameNode StandBy切换为活跃的主节点
- 第四种:NameNode高可用和ResourceManager高可用架构模型
【Hadoop离线基础总结】Hadoop的架构模型的更多相关文章
- 【Hadoop离线基础总结】流量日志分析网站整体架构模块开发
目录 数据仓库设计 维度建模概述 维度建模的三种模式 本项目中数据仓库的设计 ETL开发 创建ODS层数据表 导入ODS层数据 生成ODS层明细宽表 统计分析开发 流量分析 受访分析 访客visit分 ...
- 【Hadoop离线基础总结】oozie的安装部署与使用
目录 简单介绍 概述 架构 安装部署 1.修改core-site.xml 2.上传oozie的安装包并解压 3.解压hadooplibs到与oozie平行的目录 4.创建libext目录,并拷贝依赖包 ...
- 【Hadoop离线基础总结】impala简单介绍及安装部署
目录 impala的简单介绍 概述 优点 缺点 impala和Hive的关系 impala如何和CDH一起工作 impala的架构及查询计划 impala/hive/spark 对比 impala的安 ...
- 【Hadoop离线基础总结】Hue的简单介绍和安装部署
目录 Hue的简单介绍 概述 核心功能 安装部署 下载Hue的压缩包并上传到linux解压 编译安装启动 启动Hue进程 hue与其他框架的集成 Hue与Hadoop集成 Hue与Hive集成 Hue ...
- 【Hadoop离线基础总结】Sqoop常用命令及参数
目录 常用命令 常用公用参数 公用参数:数据库连接 公用参数:import 公用参数:export 公用参数:hive 常用命令&参数 从关系表导入--import 导出到关系表--expor ...
- 【Hadoop离线基础总结】Hive调优手段
Hive调优手段 最常用的调优手段 Fetch抓取 MapJoin 分区裁剪 列裁剪 控制map个数以及reduce个数 JVM重用 数据压缩 Fetch的抓取 出现原因 Hive中对某些情况的查询不 ...
- 【Hadoop离线基础总结】Hadoop High Availability\Hadoop基础环境增强
目录 简单介绍 Hadoop HA 概述 集群搭建规划 集群搭建 第一步:停止服务 第二步:启动所有节点的ZooKeeper 第三步:更改配置文件 第四步:启动服务 简单介绍 Hadoop HA 概述 ...
- 【Hadoop离线基础总结】关键路径转化率分析(漏斗模型)
关键路径转化 需求 在一条指定的业务流程中,各个步骤的完成人数及相对上一个步骤的百分比 模型设计 定义好业务流程中的页面标识 Step1. /item Step2. /category Step3. ...
- 【Hadoop离线基础总结】网站流量日志数据分析系统
目录 点击流数据模型 概述 点击流模型 网站流量分析 网站流量模型分析 网站流量来源 网站流量多维度细分 网站内容及导航分析 网站转化及漏斗分析 流量常见分析角度和指标分类 指标概述 指标分类 分析角 ...
随机推荐
- 资料整理:python自动化测试——操作测试对象
文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:爱吃米饭的猪 PS:如有需要Python学习资料的小伙伴可以加点击下方链接自 ...
- Sprint 3 : oxford project API 尝试
本次Sprint我们大家主要在调研和尝试阶段,主要是对photo experience 中的语音接口部分进行相应的调研和分析. 工作进度: 1. 图像界面设计兆阳和敏龙的工作进一步推进,除去之前介绍的 ...
- B - Fadi and LCM CodeForces - 1285C 质因子
题目大意很简单,给你一个整数X,让你求a和b,使得max(a,b)尽可能的小,然后打印a,b 题解:想到了质因子分解,也考虑到了暴力,但是觉得暴力的话会TLE,所以打算用贪心做,然后就一直Wa.... ...
- C - Ekka Dokka
Ekka and his friend Dokka decided to buy a cake. They both love cakes and that's why they want to sh ...
- 对短路变形POJ3615
Farmer John wants the cows to prepare for the county jumping competition, so Bessie and the gang are ...
- [安全] Kali Linux安装TheFatRat
一.解决访问国外网络的问题 由于字符敏感,以下所有vray的第二位都需要加上"2". 1.使用vray客户端 前提条件:拥有一个海外vray服务器提供socks5代理. 1)下载v ...
- BUUOJ [极客大挑战 2019]Secret File
[极客大挑战 2019]Secret File 0X01考点 php的file伪协议读取文件 ?file=php://filter/convert.base64-encode/resource= 0X ...
- Linux常见提权
常见的linux提权 内核漏洞提权 查看发行版 cat /etc/issue cat /etc/*-release 查看内核版本 uname -a 查看已经安装的程序 dpkg -l rpm -qa ...
- python调用word2vec工具包安装和使用指南
python调用word2vec工具包安装和使用指南 word2vec python-toolkit installation and use tutorial 本文选译自英文版,代码注释均摘自本文, ...
- Springboot:第一个Springboot程序(一)
1.创建Springboot项目 选择创建Springboot项目: 填写项目基本信息: 选择Springboot版本以及web依赖(内嵌tomcat): 创建完成: 创建完成后 等待构建maven项 ...