centos搭建单节点hadoop
由于本地机器资源有限,搭建单节点hadoop供开发、测试。
1、安装java
mkdir /usr/local/java
cd /usr/local/java
tar zxvf jdk-8u181-linux-x64.tar.gz
rm -f jdk-8u181-linux-x64.tar.gz
---设置jdk环境变量
vi /etc/profile
JAVA_HOME=/usr/local/java/jdk1.8.0_181
JRE_HOME=/usr/local/java/jdk1.8.0_181/jre
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
PATH=$JAVA_HOME/bin:$PATH
export PATH JAVA_HOME CLASSPATH
source /etc/profile
java -version
2、增加用户
useradd hadoop
配置免密登陆(需开启ssh服务)
yum install -y openssh-server
yum install -y openssh-clients
systemctl start sshd.service
su - hadoop
ssh-keygen -t rsa -P ''
cat id_rsa.pub > ~/.ssh/authorized_keys
chmod 700 ~/.ssh
chmod 600 ~/.ssh/authorized_keys
3、创建目录和解压缩
mkdir -p /opt/hadoop
上传hadoop-2.8.5.tar.gz 至/opt/hadoop
chown -R hadoop:hadoop /opt/hadoop
mkdir -p /u01/hadoop
mkdir /u01/hadoop/tmp
mkdir /u01/hadoop/var
mkdir /u01/hadoop/dfs
mkdir /u01/hadoop/dfs/name
mkdir /u01/hadoop/dfs/data
chown -R hadoop.hadoop /u01/hadoop
su - hadoop
cd /opt/hadoop
tar -xzvf hadoop-2.8.5.tar.gz
rm -f hadoop-2.8.5.tar.gz
4、配置环境变量
vi ~/.bashrc
export HADOOP_HOME=/opt/hadoop/hadoop-2.8.5
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_COMMON_LIB_NATIVE_DIR"
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
source ~/.bashrc
5、修改配置文件
路径:/opt/hadoop/hadoop-2.8.5/etc/hadoop
- hadoop-env.sh
JAVA_HOME=/usr/local/java/jdk1.8.0_181
- core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/u01/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
</configuration>
- hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/u01/hadoop/dfs/name</value>
<description>Path on the local filesystem where theNameNode stores the namespace and transactions logs persistently.</description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/u01/hadoop/dfs/data</value>
<description>Comma separated list of paths on the localfilesystem of a DataNode where it should store its blocks.</description>
</property>
<property>
<name>dfs.permissions</name>
<value>true</value>
<description>need not permissions</description>
</property>
</configuration>
- mapred-site.xml
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>hadoop01:49001</value>
</property>
<property>
<name>mapred.local.dir</name>
<value>/u01/hadoop/var</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
- yarn-site.xml
- slaves
hadoop01
6、启动服务
---初始化HDFS文件系统
hdfs namenode -format
---启动Hadoop服务
start-dfs.sh #启动Hadoop
start-yarn.sh #启动yarn
jps #查看服务状态
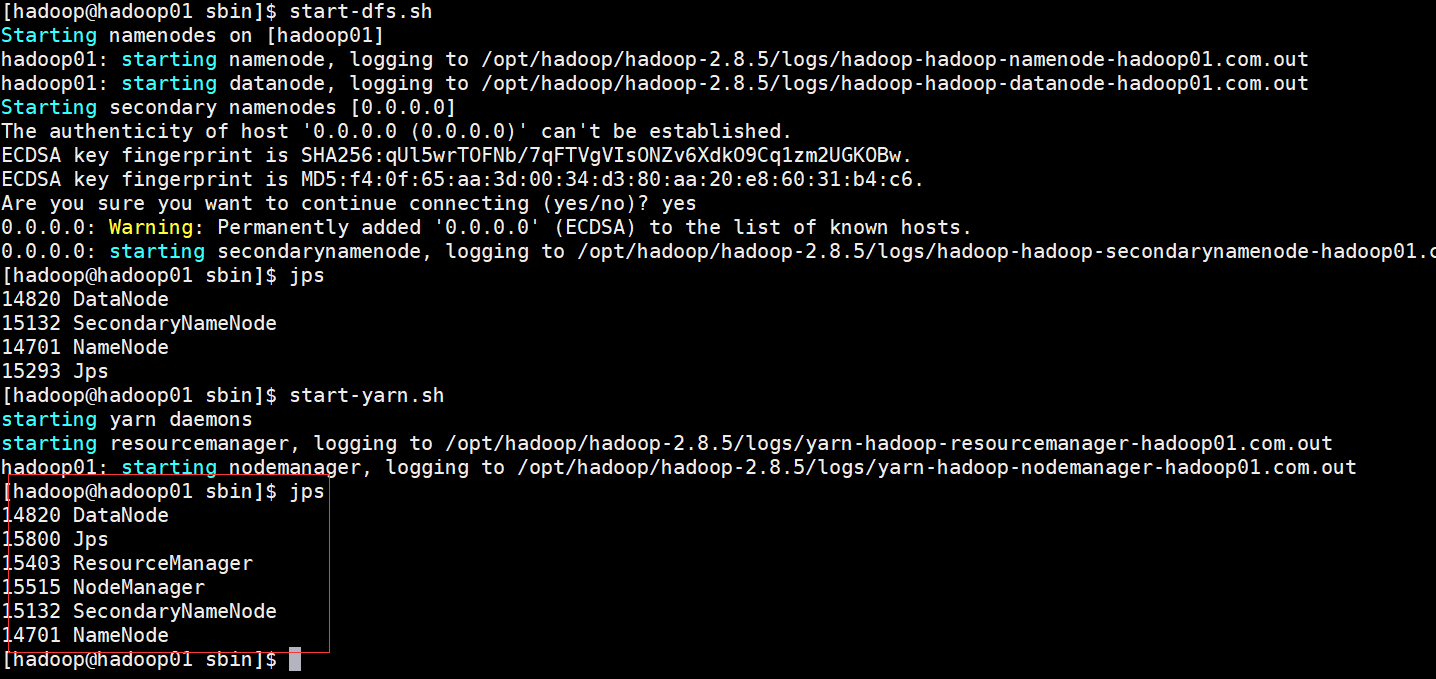
如图有5个服务起来
如果启动报错可以通过以下单独启动
hadoop-daemon.sh start namenode
hadoop-daemon.sh start datanode
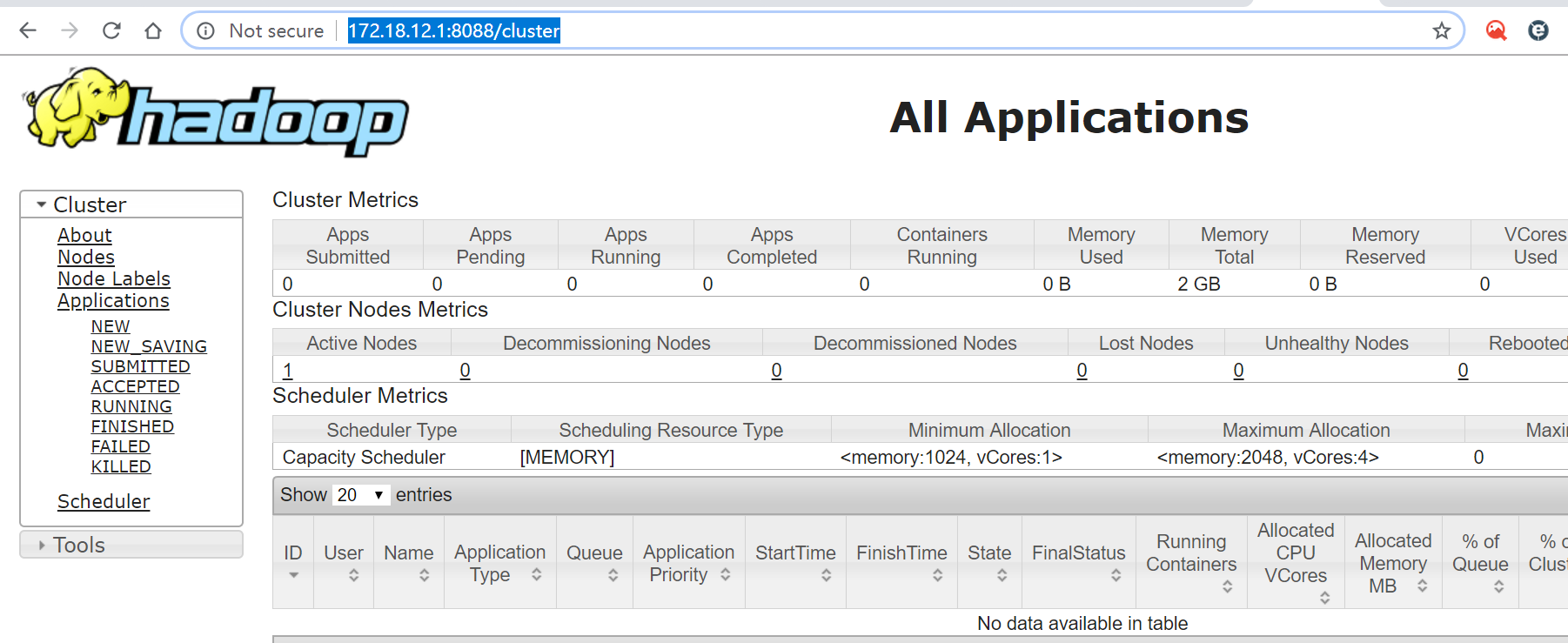
登录验证:
http://172.18.12.1:8088/cluster
尝试创建文件
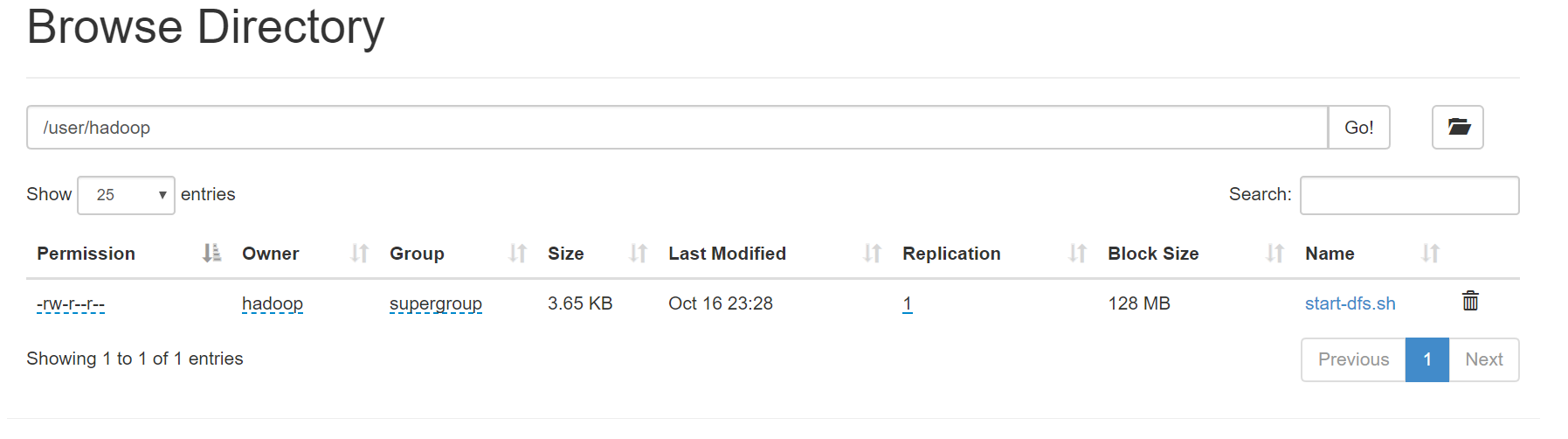
hdfs dfs -mkdir /user
hdfs dfs -mkdir /user/hadoop
hdfs dfs -put start-dfs.sh /user/hadoop
centos搭建单节点hadoop的更多相关文章
- 搭建单节点Hadoop应用环境
虚拟机: VirtualBox 5 Server操作系统: Ubuntu Server 14.04.3 LTS 如果对虚拟机空间和性能不做考虑, 且不习惯用Linux命令, 你也可以使用Ubuntu ...
- 基于Docker快速搭建多节点Hadoop集群--已验证
Docker最核心的特性之一,就是能够将任何应用包括Hadoop打包到Docker镜像中.这篇教程介绍了利用Docker在单机上快速搭建多节点 Hadoop集群的详细步骤.作者在发现目前的Hadoop ...
- hadoop集群搭建——单节点(伪分布式)
1. 准备工作: 前提:需要电脑安装VM,且VM上安装一个Linux系统 注意:本人是在学习完尚学堂视频后,结合自己的理解,在这里做的总结.学习的视频是:大数据. 为了区分是在哪一台机器做的操作,eg ...
- Zookeeper在Centos7上搭建单节点应用
(默认机器上已经安装并配置好了jdk) 1.下载zookeeper并解压 $ tar -zxvf zookeeper-3.4.6.tar.gz 2.将解压后的文件夹移动到 /usr/local/ 目录 ...
- dcoker 搭建单节点redis
1.安装docker 1.检查内核版本,必须是3.10及以上 [root@localhost ~]# uname -r 2.安装docker [root@localhost ~]# yum insta ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:单节点伪分布式安装
实验目的 了解java的安装配置 学习配置对自己节点的免密码登陆 了解hdfs的配置和相关命令 了解yarn的配置 实验原理 1.Hadoop安装 Hadoop的安装对一个初学者来说是一个很头疼的事情 ...
- kafka系列一:单节点伪分布式集群搭建
Kafka集群搭建分为单节点的伪分布式集群和多节点的分布式集群两种,首先来看一下单节点伪分布式集群安装.单节点伪分布式集群是指集群由一台ZooKeeper服务器和一台Kafka broker服务器组成 ...
- ASP.NET Core on K8S学习初探(1)K8S单节点环境搭建
当近期的一个App上线后,发现目前的docker实例(应用服务BFF+中台服务+工具服务)已经很多了,而我司目前没有专业的运维人员,发现运维的成本逐渐开始上来,所以容器编排也就需要提上议程.因此我决定 ...
- Hadoop的单节点集群详细启动步骤
见,如下博客 hadoop-2.2.0.tar.gz的伪分布集群环境搭建(单节点) 很简单,不多赘述.
随机推荐
- Jmeter在linux下的安装
Apache Jmeter简介 Apache JMeter 是Apache组织的开放源代码项目,是一个100%纯Java桌面应用,用于压力测试和性能测量.它最初被设计用于Web应用测试但后来扩展到 ...
- python splash scrapy
python splash scrapy 1. 前言 slpash是一个渲染引擎,它有自己的api,可以直接访问splash服务的http接口,但也有对应的包python-splash方便调 ...
- mybatis源码探索笔记-4(缓存原理)
前言 mybatis的缓存大家都知道分为一级和二级缓存,一级缓存系统默认使用,二级缓存默认开启,但具体用的时候需要我们自己手动配置.我们依旧还是先看一个demo.这儿只贴出关键代码 public in ...
- Idea 隐藏不必要的文件或文件夹 eg:(.idea,.gitignore,*.iml)
在使用Idea的时候,有一些文件是不必要的,可以将他们隐藏起来 方法:打开File–>Settings–>Editor如图,在File Types 中的 Ignore files and ...
- jmeter download historyList
https://archive.apache.org/dist/jmeter/binaries/ 反馈,问题和评论应发送到Apache JMeter Users 邮件列表. 有关更多信息, 请访问Ap ...
- Day11 - B - Dice (III) LightOJ - 1248
设dp_i为已经出现了i面,需要的期望次数,dp_n=0 那么dp_i= i/n*dp_i + (n-i)/n*dp_(i+1) + 1 现在已经i面了,i/n的概率再选择一次i面,(n-i)/n的概 ...
- JavaScript学习笔记----- 继承的实现及其原理
按照自己在极客上学习的顺序整理了一下,参考了几位前辈的随笔,十分感谢: 参见http://blog.yemou.net/article/query/info ...
- ubuntu16.04下安装docker和docker-compose
开始安装 由于apt官方库里的docker版本可能比较旧,所以先卸载可能存在的旧版本:$ sudo apt-get remove docker docker-engine docker-ce dock ...
- Java基础 -1.4
标识符与关键字 对于标识符的组成在Java之中的定义如下:由字母.数字._.$ 组成 其中不能使用Java的保留字(关键字) 其中 $ 一般都有特殊的含义 不建议出现在自己所编写的代码上 关键字 是系 ...
- java记录5--线程
------------恢复内容开始------------ 1.什么叫程序:是一个严格有序的指令集合.程序规定了完成某一任务时,计算机所需做的各种操作,已经执行顺序. 特点:资源的独占性 执 ...