Mapreduce实例——WordCount
实验步骤
- 切换目录到/apps/hadoop/sbin下,启动hadoop。
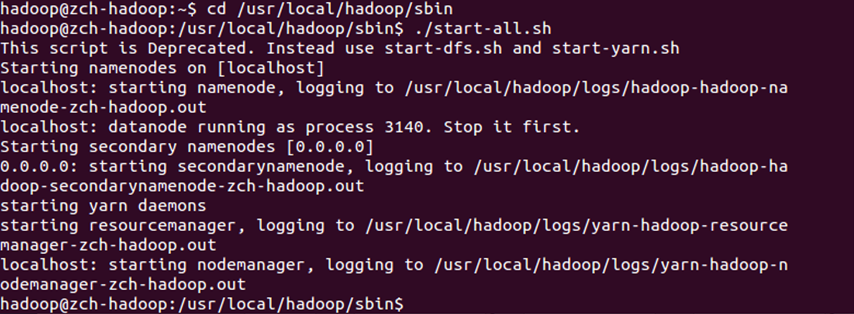
cd /apps/hadoop/sbin
./start-all.sh
2.在linux上,创建一个目录/data/mapreduce1。

mkdir -p /data/mapreduce1
3.切换到/data/mapreduce1目录下,自行建立文本文件buyer_favorite1。
依然在/data/mapreduce1目录下,使用wget命令,从
网络下载hadoop2lib.tar.gz,下载项目用到的依赖包。
将hadoop2lib.tar.gz解压到当前目录下。
tar -xzvf hadoop2lib.tar.gz
4.将linux本地/data/mapreduce1/buyer_favorite1,上传到HDFS上的/mymapreduce1/in目录下。若HDFS目录不存在,需提前创建。
- hadoop fs -mkdir -p /mymapreduce1/in
- hadoop fs -put /data/mapreduce1/buyer_favorite1 /mymapreduce1/in
5.打开Eclipse,新建Java Project项目。并将项目名设置为mapreduce1。
6.在项目名mapreduce1下,新建package包。并将包命名为mapreduce 。
7.在创建的包mapreduce下,新建类。并将类命名为WordCount。
8.添加项目所需依赖的jar包,右键单击项目名,新建一个目录hadoop2lib,用于存放项目所需的jar包。
9.添加代码
10.打开终端或使用hadoop eclipse插件,查看hdfs上,程序输出的实验结果。


hadoop fs -ls /mymapreduce1/out
hadoop fs -cat /mymapreduce1/out/part-r-00000
Mapreduce实例——WordCount的更多相关文章
- 实验6:Mapreduce实例——WordCount
实验目的1.准确理解Mapreduce的设计原理2.熟练掌握WordCount程序代码编写3.学会自己编写WordCount程序进行词频统计实验原理MapReduce采用的是“分而治之”的 ...
- 大型数据库技术实验六 实验6:Mapreduce实例——WordCount
现有某电商网站用户对商品的收藏数据,记录了用户收藏的商品id以及收藏日期,名为buyer_favorite1. buyer_favorite1包含:买家id,商品id,收藏日期这三个字段,数据以“\t ...
- MapReduce实例2(自定义compare、partition)& shuffle机制
MapReduce实例2(自定义compare.partition)& shuffle机制 实例:统计流量 有一份流量数据,结构是:时间戳.手机号.....上行流量.下行流量,需求是统计每个用 ...
- MapReduce实例&YARN框架
MapReduce实例&YARN框架 一个wordcount程序 统计一个相当大的数据文件中,每个单词出现的个数. 一.分析map和reduce的工作 map: 切分单词 遍历单词数据输出 r ...
- 利用python操作mrjob实例---wordcount
网上利用java实现mr操作实例相对较多,现将python实现mr操作实例---Wordcount分享如下: 在操作前,需要作如下准备: 1.确保linux系统里安装有python3.5,pyt ...
- Java编程MapReduce实现WordCount
Java编程MapReduce实现WordCount 1.编写Mapper package net.toocruel.yarn.mapreduce.wordcount; import org.apac ...
- eclipse运行mapreduce的wordcount
1,eclipse安装hadoop插件 插件下载地址:链接: https://pan.baidu.com/s/1U4_6kLFNiKeLsGfO7ahXew 提取码: as9e 下载hadoop-ec ...
- Mapreduce 测试自带实例 wordcount
2.7.3版本的hadoop: jar程序所在目录:$HADOOP_HOME/shar/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar 1.本 ...
- Hadoop实战2:MapReduce编程-WordCount实例-streaming-python环境
这是搭建hadoop环境后的第一个MapReduce程序: 基于hadoop streaming的python的脚本: 1 map.py文件,把文本的内容划分成单词: #!/usr/bin/pytho ...
随机推荐
- day03-MyBatis的动态SQL语句查询
场景一: 例如当我们想实现这样的查询的时候之前的操作貌似满足不了我们. 场景二: 还有些时候我们如果输入的信息越多满足要求的就越多,所查找出来的用户就越少 当我们之输入姓名的时候可能查找出10个人, ...
- SpringBoot 集成Log4j、集成AOP
集成Log4j (1)在pom.xml中添加依赖 <!--去掉springboot默认的日志--> <dependency> <groupId>org.spring ...
- Python 正则表达式之 sub 和 subn函数的使用
re.sub() 函数的功能 re是reguler expressioin的缩写,表示正则表达式 sub 是 substitute 的缩写,表示替换: re.sub是个正则表达式方面的函数,用来实现通 ...
- 十二 Spring的AOP开发入门,整合Junit单元测试(AspectJ的XML方式)
创建web项目,引入jar包 引入Spring配置文件
- jquery $.ajax status为200 却调用了error方法
参考: https://blog.csdn.net/shuifa2008/article/details/41121269 https://blog.csdn.net/shuifa2008/artic ...
- Django问题 Did you rename .....a ForeignKey
给新加入的字段添加一个default默认值即可,让字段非空.然后在进行makemigrations,完成操作后删除相关默认值即可.
- kafka的搭建,命令
a)kafka搭建 1.解压 2.修改配置/software/kafka_2.11-0.11.0.3/config/server.properties broker.id=0 log.dirs=/va ...
- AtCoder agc007_d Shik and Game
洛谷题目页面传送门 & AtCoder题目页面传送门 有\(1\)根数轴,Shik初始在位置\(0\).数轴上有\(n\)只小熊,第\(i\)只在位置\(a_i\).Shik每秒可以向左移动\ ...
- 算法设计与分析 - AC 题目 - 第 5 弹(重复第 2 弹)
PTA-算法设计与分析-AC原题 - 最大子列和问题 (20分) 给定K个整数组成的序列{ N1, N2, ..., NK },“连续子列”被定义为{ Ni, Ni+, ..., Nj },其中 ≤i ...
- docker源码安装
概述:Docker目前分为两个版本:EE版本(企业版本).CE版本(社区版本).推荐的内核版本是3.8或者更高.必须是64位的操作系统. 安装Docker的先决条件: 运行64位CPU架构的计算机(x ...