Kmeans应用
1、思路
应用Kmeans聚类时,需要首先确定k值,如果k是未知的,需要先确定簇的数量。其方法可以使用拐点法、轮廓系数法(k>=2)、间隔统计量法。若k是已知的,可以直接调用sklearn子模块cluster中Kmeans方法,对数据进行切割。
另外如若数据集不规则,存在量纲上的差异,也需要对其进行标准化处理。
2、数据的标准化处理

(minmax_scale为sklearn子模块processing 中 的函数),第一种方法为压缩变量为mean=0,std=1的无量纲数据,第二种方式会压缩变量为[0,1]之间无量纲数据 。
3、案例
1)对iris聚类(已知簇类的情况)
情况1,已知k值,k=3
调用KMeans模块
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from pylab import *
mpl.rcParams['font.sans-serif'] = ['SimHei'] iris = pd.read_csv(r'iris.csv') # 设置聚为3类,n_clusters =3
X = iris.drop(labels = 'Species',axis = 1)
kmeans = KMeans(n_clusters =3 )
kmeans.fit(X) X['cluster'] = kmeans.labels_
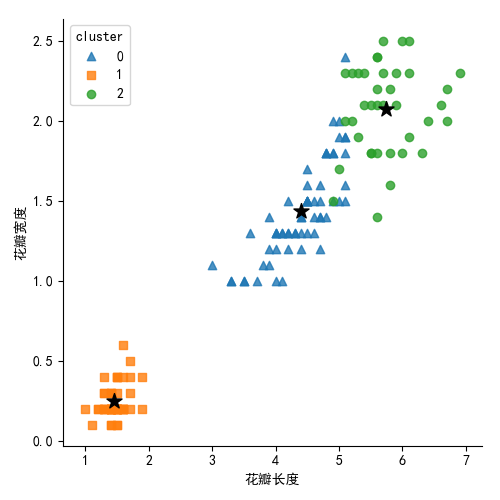
X.cluster.value_counts() # 绘制花瓣长度与宽度的散点图
import seaborn as sns centers = kmeans.cluster_centers_
print(centers)
sns.lmplot(x = 'Petal_Length',
y= 'Petal_Width',
hue = 'cluster',
markers = ['^','s','o'],
data = X,
fit_reg= False,
scatter_kws = {'alpha':0.8},
legend_out = False
)
plt.scatter(centers[:,2], centers[:,3], marker = '*',color = 'black', s =130) # 绘制簇中心点
plt.xlabel('花瓣长度')
plt.ylabel('花瓣宽度')
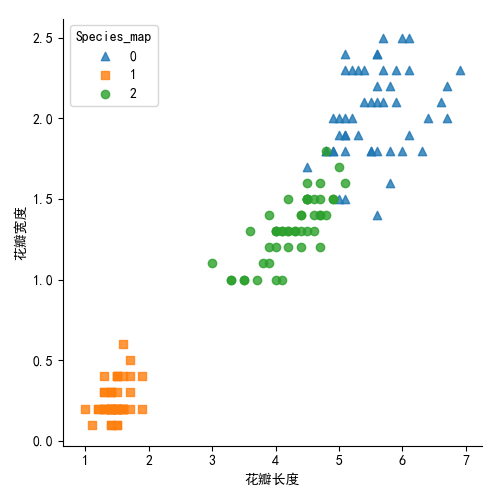
plt.show() iris['Species_map'] = iris.Species.map({'virginica':0,'setosa':1,"versicolor":2}) # 3种类型进行映射到0,1,2
sns.lmplot(x = 'Petal_Length',
y= 'Petal_Width',
hue = 'Species_map',
markers = ['^','s','o'],
data = iris,
fit_reg= False,
scatter_kws = {'alpha':0.8},
legend_out = False )
plt.xlabel('花瓣长度')
plt.ylabel('花瓣宽度')
plt.show()
生成图形如下:
对簇中心做雷达图
import pygal radar_chart = pygal.Radar(fill = True)
radar_chart.x_labels = ['花萼长度','花萼宽度', '花瓣长度','花瓣宽度'] # 雷达图区域绘制
radar_chart.add('C1',centers[0])
radar_chart.add('C2',centers[1])
radar_chart.add('C3',centers[2])
radar_chart.render_to_file('radar_chart.svg')
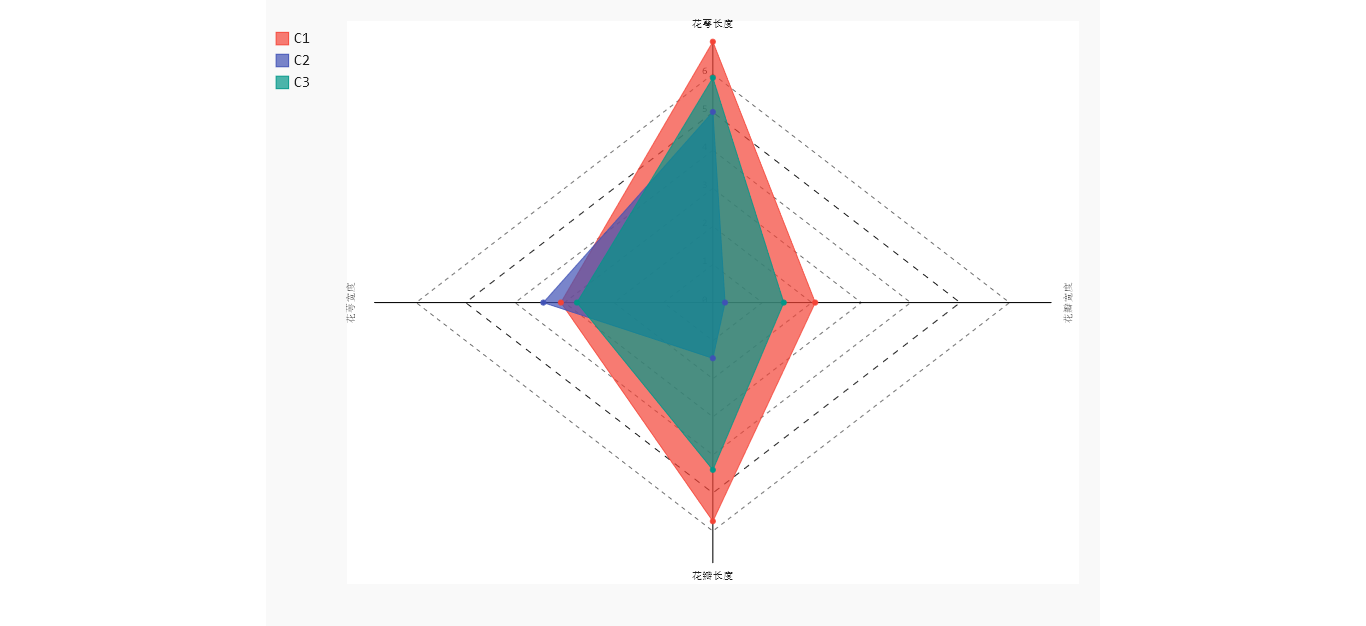
生成如下图形,C1类型的花,花萼长和花瓣长都是最大的。C2类型的花,对应的3个指标值都比较小,C3类型的花,3个指标的平均值,恰好落在C1和C2之间。
2)NBA球员数据集聚类(未知k值)
数据集

选定得分、命中率,三分命中率,罚球命中率四个维度进行分析,观察数据情况,需进行标准化。
- 先对得分和命中率作散点图,进行观察
sns.lmplot(x = '得分',
y = '命中率',
data = players,
fit_reg = False,
scatter_kws = {'alpha': 0.8,'color': 'steelblue'}
) plt.show()
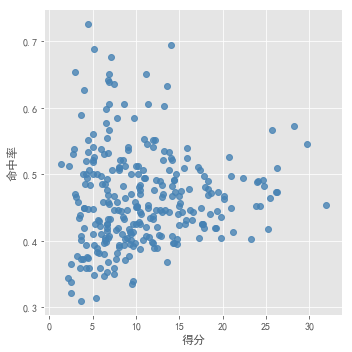
肉眼无法进行观察数据集适合分为几个簇。分别采用 以上确定k值的3种方法进行测试。
拐点法:
from sklearn import preprocessing X = preprocessing.minmax_scale(players[['得分','罚球命中率','命中率','三分命中率']]) # 数据集的标准化
X = pd.DataFrame(X, columns=['得分','罚球命中率','命中率','三分命中率'])
k_SSE(X,15)
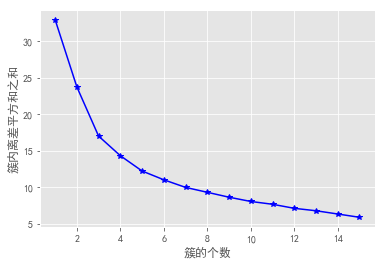
结果看出,k值在3、4斜率变化比较明显,在5以后斜率保持一定的水平。所以k取3,4,5均有可能。在比较其他方法。
轮廓系数法及Gap statistic法可视化效果如下:
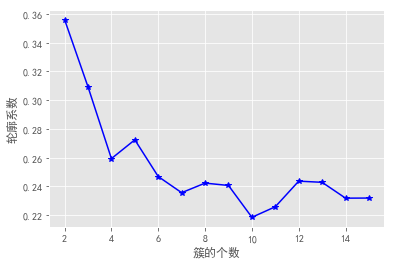
结合上图,轮廓系数在大于0的情况下,最大值对应的k值为2,统计量法首次出现正值的k值为3,综合考虑以上三种方法取k值为3,即将数据集分为3个簇最理想。
- 对得分和命中率进行聚类
kmeans = KMeans(n_clusters = 3)
kmeans.fit(X)
players['cluster'] = kmeans.labels_
centers = [] for i in players.cluster.unique():
centers.append(players.ix[players.cluster == i, ['得分','罚球命中率','命中率','三分命中率']].mean()) centers = np.array(centers) sns.lmplot(x = '得分',
y = '命中率',
hue = 'cluster',
data = players,
markers = ['^','s','o'],
fit_reg = False,
scatter_kws = {'alpha': 0.8},
legend = False
)
plt.scatter(centers[:,0],centers[:,2],c = 'k',marker = '*',s =180)
plt.xlabel('得分')
plt.ylabel('命中率')
plt.show() # 雷达图绘制
centers_std = kmeans.cluster_centers_
radar_chart = pygal.Radar(fill = True) # 设置填充型雷达图
radar_chart.x_labels = ['得分','罚球命中率','命中率','三分命中率']
radar_chart.add('C1', centers_std[0])
radar_chart.add('C2', centers_std[1])
radar_chart.add('C3', centers_std[2]) radar_chart.render_to_file('radar_charts.svg')
结果如下图:

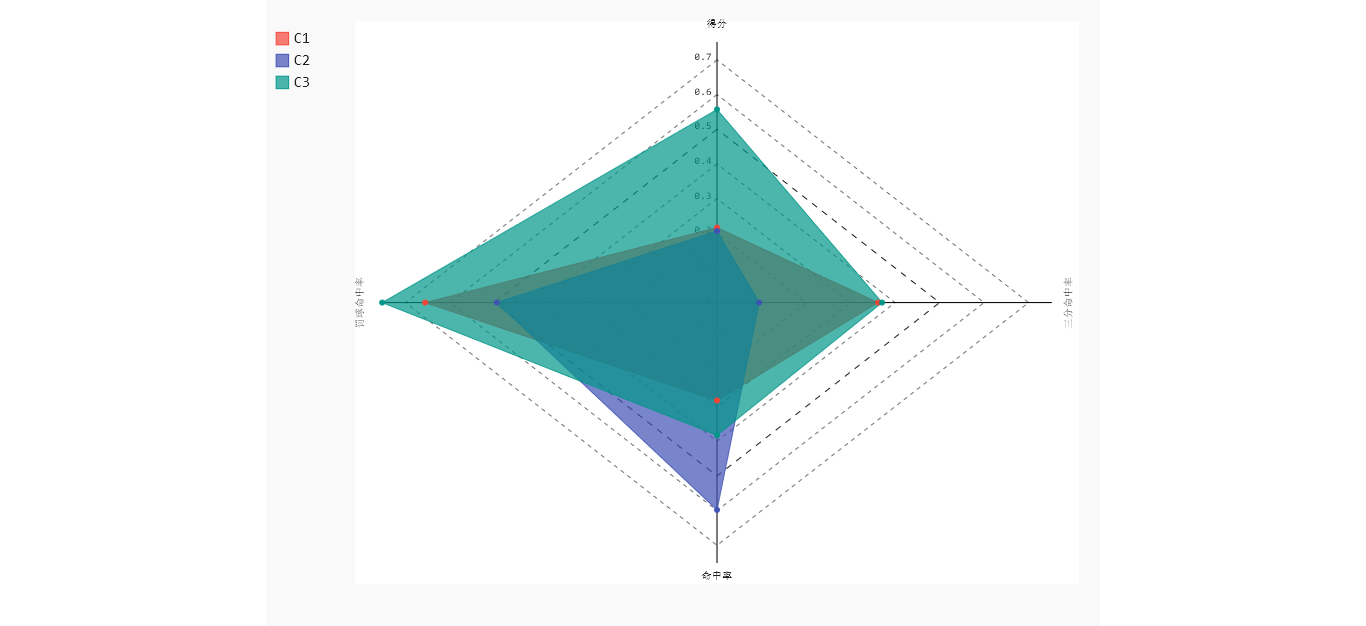
由聚类结果可以发现,三角形区域代表的球员属于低得分低命中率类型,命中率普遍低于50%,方形区域代表低得分高命中率的球员,圆形区域球员与三角形区域球员具有类似的命中率,单圆形区域球员具有高得分。且该区域存在部分球员具有高得分且高命中率。通过对比雷达图,C1、C2类球员平均得分差不多,但C2具有更高的命中率。平均罚球命中率和三分球命中率上来看,C1球员也要明显高于C2.
Kmeans应用的更多相关文章
- 当我们在谈论kmeans(1)
本稿为初稿,后续可能还会修改:如果转载,请务必保留源地址,非常感谢! 博客园:http://www.cnblogs.com/data-miner/ 简书:建设中... 知乎:建设中... 当我们在谈论 ...
- K-Means 聚类算法
K-Means 概念定义: K-Means 是一种基于距离的排他的聚类划分方法. 上面的 K-Means 描述中包含了几个概念: 聚类(Clustering):K-Means 是一种聚类分析(Clus ...
- 用scikit-learn学习K-Means聚类
在K-Means聚类算法原理中,我们对K-Means的原理做了总结,本文我们就来讨论用scikit-learn来学习K-Means聚类.重点讲述如何选择合适的k值. 1. K-Means类概述 在sc ...
- K-Means聚类算法原理
K-Means算法是无监督的聚类算法,它实现起来比较简单,聚类效果也不错,因此应用很广泛.K-Means算法有大量的变体,本文就从最传统的K-Means算法讲起,在其基础上讲述K-Means的优化变体 ...
- kmeans算法并行化的mpi程序
用c语言写了kmeans算法的串行程序,再用mpi来写并行版的,貌似参照着串行版来写并行版,效果不是很赏心悦目~ 并行化思路: 使用主从模式.由一个节点充当主节点负责数据的划分与分配,其他节点完成本地 ...
- 当我们在谈论kmeans(2)
本稿为初稿,后续可能还会修改:如果转载,请务必保留源地址,非常感谢! 博客园:http://www.cnblogs.com/data-miner/ 其他:建设中- 当我们在谈论kmeans(2 ...
- K-Means clusternig example with Python and Scikit-learn(推荐)
https://www.pythonprogramming.net/flat-clustering-machine-learning-python-scikit-learn/ Unsupervised ...
- K-Means聚类和EM算法复习总结
摘要: 1.算法概述 2.算法推导 3.算法特性及优缺点 4.注意事项 5.实现和具体例子 6.适用场合 内容: 1.算法概述 k-means算法是一种得到最广泛使用的聚类算法. 它是将各个聚类子集内 ...
- 【原创】数据挖掘案例——ReliefF和K-means算法的医学应用
数据挖掘方法的提出,让人们有能力最终认识数据的真正价值,即蕴藏在数据中的信息和知识.数据挖掘 (DataMiriing),指的是从大型数据库或数据仓库中提取人们感兴趣的知识,这些知识是隐含的.事先未知 ...
- 【十大经典数据挖掘算法】k-means
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 引言 k-means与kNN虽 ...
随机推荐
- PHP 获取header 的自定义参数值
$.ajax({ type: "GET", url: "default.aspx", beforeSend: function(request) { reque ...
- vue 使用 element-ui 时报错ERROR in ./node_modules/element-ui/lib/theme-chalk/fonts/element-icons.ttf
在vue项目中引用 element-ui 时,虽然按照 element-ui 的官方文档一步步操作,还是产生了下面的错误 解决这个问题的方法,就是在 web pack.config.js 文件中进 ...
- gpg加密和解密
linux:gpg加密和解密 1 创建密钥 2 查看私钥 3 导出公钥 4 导出私钥 5 导入秘钥 5.1 公钥 6 公钥加密 7 私钥解密 创建密钥 gpg --gen-key 你要求输入一下内容, ...
- Windows 10工程版本泄露全新设计的操作中心圆角样式
早些时候微软错误地向Windows 10所有测试通道推送内部工程版本,该版本构建后尚未经过微软内部测试. 当然本身微软也没准备推送所以该版本里很多新功能未被关闭,而成功升级的用户则可以立即查看这些功能 ...
- 第1节 IMPALA:8、shell交互窗口使用;9、外部和内部shell参数
impala当中的元数据的同步的问题impala当中创建的数据库表,直接就可以看得到,不用刷新hive当中创建的数据库表,需要刷新元数据才能够看得到 因为impala的catalog的服务,我们需要通 ...
- day04-Python运维开发基础(位运算、代码块、流程控制)
# (7)位运算符: & | ^ << >> ~ var1 = 19 var2 = 15 # & 按位与 res = var1 & var2 " ...
- lsof(查看端口)
简介 简介 lsof(list open files)是一个列出当前系统打开文件的工具.在linux环境下,任何事物都以文件的形式存在,通过文件不仅仅可以访问常规数据,还可以访问网络连接和硬件.所以如 ...
- Django(十一)视图详解:基本使用、登录实例、HttpReqeust对象、HttpResponse对象
一.视图(基于类的视图) [参考]https://docs.djangoproject.com/zh-hans/3.0/topics/class-based-views/intro/ 1)视图的功能 ...
- Golang函数-匿名函数与闭包函数
Golang函数-匿名函数与闭包函数 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任.
- Golang函数-函数的基本概念
Golang函数-函数的基本概念 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.函数的概述 1>.函数定义语法格式 Go语言函数定义格式如下: func 函数名( 函数参 ...