推荐系统之矩阵分解(MF)
一、矩阵分解
1.案例
我们都熟知在一些软件中常常有评分系统,但并不是所有的用户user人都会对项目item进行评分,因此评分系统所收集到的用户评分信息必然是不完整的矩阵。那如何跟据这个不完整矩阵中已有的评分来预测未知评分呢。使用矩阵分解的思想很好地解决了这一问题。
假如我们现在有一个用户-项目的评分矩阵R(n,m)是n行m列的矩阵,n表示user个数,m行表示item的个数

那么,如何根据目前的矩阵R(5,4)如何对未打分的商品进行评分的预测(如何得到分值为0的用户的打分值)?
——矩阵分解的思想可以解决这个问题,其实这种思想可以看作是有监督的机器学习问题(回归问题)。
矩阵分解的过程中,,矩阵R可以近似表示为矩阵P与矩阵Q的乘积:
矩阵P(n,k)表示n个user和k个特征之间的关系矩阵,这k个特征是一个中间变量,矩阵Q(k,m)的转置是矩阵Q(m,k),矩阵Q(m,k)表示m个item和K个特征之间的关系矩阵,这里的k值是自己控制的,可以使用交叉验证的方法获得最佳的k值。为了得到近似的R(n,m),必须求出矩阵P和Q,如何求它们呢?
2.推导步骤
1.首先令:
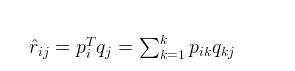
2。对于式子1的左边项,表示的是r^ 第i行,第j列的元素值,对于如何衡量,我们分解的好坏呢,式子2,给出了衡量标准,也就是损失函数,平方项损失,最后的目标,就是每一个元素(非缺失值)的e(i,j)的总和最小值
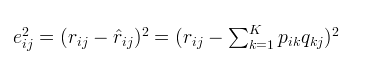
3.使用梯度下降法获得修正的p和q分量:
- 求解损失函数的负梯度
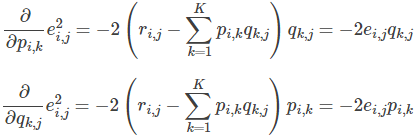
- 根据负梯度的方向更新变量:
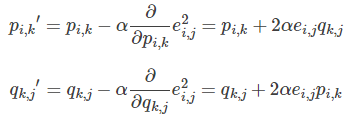
4.不停迭代直到算法最终收敛(直到sum(e^2) <=阈值,即梯度下降结束条件:f(x)的真实值和预测值小于自己设定的阈值)
5.为了防止过拟合,增加正则化项
3.加入正则项的损失函数求解
1.通常在求解的过程中,为了能够有较好的泛化能力,会在损失函数中加入正则项,以对参数进行约束,加入正则L2范数的损失函数为:

对正则化不清楚的,公式可化为:
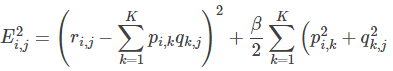
2.使用梯度下降法获得修正的p和q分量:
- 求解损失函数的负梯度:
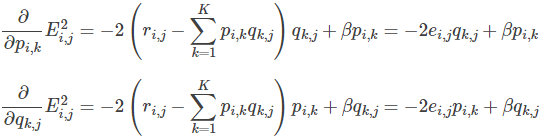
- 根据负梯度的方向更新变量:
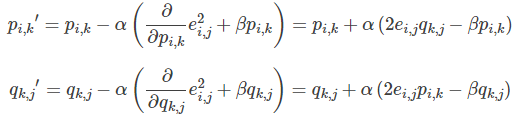
4.预测
预测利用上述的过程,我们可以得到矩阵和,这样便可以为用户 i 对商品 j 进行打分:

二、代码实现
import numpy as np
import matplotlib.pyplot as plt
def matrix(R, P, Q, K, alpha, beta):
result=[]
steps = 1
while 1 :
#使用梯度下降的一步步的更新P,Q矩阵直至得到最终收敛值
steps = steps + 1
eR = np.dot(P,Q)
e=0
for i in range(len(R)):
for j in range(len(R[i])):
if R[i][j]>0:
# .dot(P,Q) 表示矩阵内积,即Pik和Qkj k由1到k的和eij为真实值和预测值的之间的误差,
eij=R[i][j]-np.dot(P[i,:],Q[:,j])
#求误差函数值,我们在下面更新p和q矩阵的时候我们使用的是化简得到的最简式,较为简便,
#但下面我们仍久求误差函数值这里e求的是每次迭代的误差函数值,用于绘制误差函数变化图
e=e+pow(R[i][j] - np.dot(P[i,:],Q[:,j]),2)
for k in range(K):
#在上面的误差函数中加入正则化项防止过拟合
e=e+(beta/2)*(pow(P[i][k],2)+pow(Q[k][j],2))
for k in range(K):
#在更新p,q时我们使用化简得到了最简公式
P[i][k]=P[i][k]+alpha*(2*eij*Q[k][j]-beta*P[i][k])
Q[k][j]=Q[k][j]+alpha*(2*eij*P[i][k]-beta*Q[k][j])
print('迭代轮次:', steps, ' e:', e)
result.append(e)#将每一轮更新的损失函数值添加到数组result末尾
#当损失函数小于一定值时,迭代结束
if eij<0.00001:
break
return P,Q,result
R=[
[5,3,1,1,4],
[4,0,0,1,4],
[1,0,0,5,5],
[1,3,0,5,0],
[0,1,5,4,1],
[1,2,3,5,4]
]
R=np.array(R)
alpha = 0.0001 #学习率
beta = 0.002
N = len(R) #表示行数
M = len(R[0]) #表示列数
K = 3 #3个因子
p = np.random.rand(N, K) #随机生成一个 N行 K列的矩阵
q = np.random.rand(K, M) #随机生成一个 M行 K列的矩阵
P, Q, result=matrix(R, p, q, K, alpha, beta)
print("矩阵Q为:\n",Q)
print("矩阵P为:\n",P)
print("矩阵R为:\n",R)
MF = np.dot(P,Q)
print("预测矩阵:\n",MF)
#下面代码可以绘制损失函数的收敛曲线图
n=len(result)
x=range(n)
plt.plot(x, result,color='b',linewidth=3)
plt.xlabel("generation")
plt.ylabel("loss")
plt.show()
推荐系统之矩阵分解(MF)的更多相关文章
- 推荐系统之矩阵分解及C++实现
1.引言 矩阵分解(Matrix Factorization, MF)是传统推荐系统最为经典的算法,思想来源于数学中的奇异值分解(SVD), 但是与SVD 还是有些不同,形式就可以看出SVD将原始的评 ...
- 推荐系统之矩阵分解及其Python代码实现
有如下R(5,4)的打分矩阵:(“-”表示用户没有打分) 其中打分矩阵R(n,m)是n行和m列,n表示user个数,m行表示item个数 那么,如何根据目前的矩阵R(5,4)如何对未打分的商品进行评分 ...
- 【RS】Matrix Factorization Techniques for Recommender Systems - 推荐系统的矩阵分解技术
[论文标题]Matrix Factorization Techniques for Recommender Systems(2009,Published by the IEEE Computer So ...
- 【RS】List-wise learning to rank with matrix factorization for collaborative filtering - 结合列表启发排序和矩阵分解的协同过滤
[论文标题]List-wise learning to rank with matrix factorization for collaborative filtering (RecSys '10 ...
- SVD++:推荐系统的基于矩阵分解的协同过滤算法的提高
1.背景知识 在讲SVD++之前,我还是想先回到基于物品相似的协同过滤算法.这个算法基本思想是找出一个用户有过正反馈的物品的相似的物品来给其作为推荐.其公式为:
- 推荐系统实践 0x0b 矩阵分解
前言 推荐系统实践那本书基本上就更新到上一篇了,之后的内容会把各个算法拿来当专题进行讲解.在这一篇,我们将会介绍矩阵分解这一方法.一般来说,协同过滤算法(基于用户.基于物品)会有一个比较严重的问题,那 ...
- 矩阵分解(Matrix Factorization)与推荐系统
转自:http://www.tuicool.com/articles/RV3m6n 对于矩阵分解的梯度下降推导参考如下:
- 推荐系统(recommender systems):预测电影评分--构造推荐系统的一种方法:低秩矩阵分解(low rank matrix factorization)
如上图中的predicted ratings矩阵可以分解成X与ΘT的乘积,这个叫做低秩矩阵分解. 我们先学习出product的特征参数向量,在实际应用中这些学习出来的参数向量可能比较难以理解,也很难可 ...
- 【RS】Sparse Probabilistic Matrix Factorization by Laplace Distribution for Collaborative Filtering - 基于拉普拉斯分布的稀疏概率矩阵分解协同过滤
[论文标题]Sparse Probabilistic Matrix Factorization by Laplace Distribution for Collaborative Filtering ...
随机推荐
- CentOS 7.3 安装redis 4.0.2服务
CentOS 7.3 安装redis 4.0.2服务 1.下载解压 下载地址:/home/xiaoming/ wget http://download.redis.io/releases/redis- ...
- 纯CSS导航栏下划线跟随效果
参考文章 <ul> <li>111</li> <li>2222</li> <li>3333333</li> < ...
- JAVA 算法练习(二)
和上次一样,虽说用 java 语言,但有 c 的基础一样可以看懂哦. 机器人走方格问题Ⅰ 题目概述 有一个XxY的网格,一个机器人只能走格点且只能向右或向下走,要从左上角走到右下角.请设计一个算法,计 ...
- 动态类型识别&动态创建
以下大部分内容摘自<windows程序设计 第2版> 王艳平 张铮 编著 动态类型识别:在程序运行过程中,辨别对象是否属于特定类的技术. 应用举例:函数辨别参数类型.需要针对对象的类编写特 ...
- go语言实现leetcode-242
package main import ( "fmt" "reflect" ) func isAnagram(s string, t string) bool ...
- eclipse配置tomcat详细步骤
1.下载tomcat9并解压到D盘根目录下 2.Windows——>Preferences——>Server——>Runtime Environments——>Add 3.选择 ...
- 【转载】Github上优秀的.NET Core项目
Github上优秀的.NET Core项目 Github上优秀的.NET Core开源项目的集合.内容包括:库.工具.框架.模板引擎.身份认证.数据库.ORM框架.图片处理.文本处理.机器学习.日志. ...
- 14)载入png图片
1)之前在窗口中载入图片 一般都是bmp的 但是 我想从网上下一些图片,这些图片可能是png的 2)那么就有了下面的操作 3)png图片可以直接做成透明的. 4)首先是创建窗口的基本代码: #i ...
- 66)vector基础总结
基本知识: 1)vector 样子 其实就是一个动态数组: 2)vector的基本操作: 3)vector对象的默认构造 对于类 添加到 容器中 要有 拷贝构造函数---> 这个注意 ...
- redis的过期策略
1.了解redis 什么是Redis,为啥用缓存? Redis是用内存当缓存的.Redis主要是基于内存来进行高性能.高并发的读写操作的. 内存是有限的,比如Redis就只能用10个G,你一直往里面写 ...