恶劣的网络环境下,Netty是如何处理写事件的?

更多技术分享可关注我
前言
前面,在Netty在接收完新连接后,默认为何要为其注册读事件,其处理I/O事件的优先级是什么?这篇文章,分析到了Netty处理I/O事件的优先级——读事件优先,写事件仅仅是需要写的时候才注册,为什么要这样设计呢?下面抛出两个问题,可以带着这两个问题阅读本篇文章:恶劣的网络环境下,Netty是如何处理写事件的?。
1、假设服务器在成功接收到一个客户端新连接后,就给它注册了OP_WRITE事件,此时可能会发生什么问题?
2、有人说,JDK不是已经提供了一个往Socket写数据的方法么,在客户端直接调用它,给服务器发送数据不就OK了么,还注册什么事件,费这个劲呢,对此你怎么理解?
另外本文后续引起的几篇文章可以参考:
Netty在接收完新连接后,默认为何要为其注册读事件,其处理I/O事件的优先级是什么?
Netty在接收完新连接后,默认为何要为其注册读事件,其处理I/O事件的优先级是什么?
NIO的I/O事件都有哪些,它们的本质是什么,处理它们有哪些坑需要注意?
NIO的I/O事件都有哪些,它们的本质是什么,处理它们有哪些坑需要注意?
Netty为何在Channel里设计Unsafe,且针对不同类型的Channel设计了两大类实现?
Netty为何在Channel里设计Unsafe,且针对不同类型的Channel设计了两大类实现?
NIO的connect方法有什么坑,Netty是如何解决的?
NIO的connect方法有什么坑,Netty是如何解决的?
Reactor主从模型你理解对了么?
总结Netty的新连接接入和数据读写相关的面试题
NIO处理写事件的坑和正确做法
先抛出结论:
1、JDK NIO的OP_WRITE事件处理不对,很容易发生“无限”循环的问题!
2、在网络不给力的情况下,往处于非阻塞模式下的连接上调用写方法容易导致CPU被浪费,服务器性能会陡然下降!
首先,知道JDK NIO的OP_WRITE事件何时会被触发,前提是必须在注册了Channel的I/O多路复用器上注册了OP_WRITE事件,之后该连接上:
1、Socket的缓冲区有空闲位置
2、对端关闭了该连接
3、该连接自己内部出现了错误
发生以上三个场景,都可以触发I/O多路复用器上注册的写事件。
带着上述结论,回答开头提到的第一个问题:
1、假设一个服务器在成功接收到一个客户端新连接后,就给它注册了OP_WRITE事件,此时可能会发生什么问题呢?
答案是可能导致“死”循环发生,最终结果就是CPU利用率达到100%,服务被拖垮!因为一个Channel上写事件的就绪条件为TCP写缓冲区有空闲位置,根据常识我们也知道TCP写缓冲区在大多场景下,都是有空闲位置的,所以直接给新连接注册写事件,那么这个写事件在大多数时间下会一直被触发,处理这个过程的I/O线程就会被长时间拖累,直到占用整个CPU资源。这样干说可能不太好理解,看一个demo,这是早些年我写的一个NIO框架里面的一段I/O事件循环处理的代码,当然很挫,和Netty的run方法没得比,但是大概思路是通的:
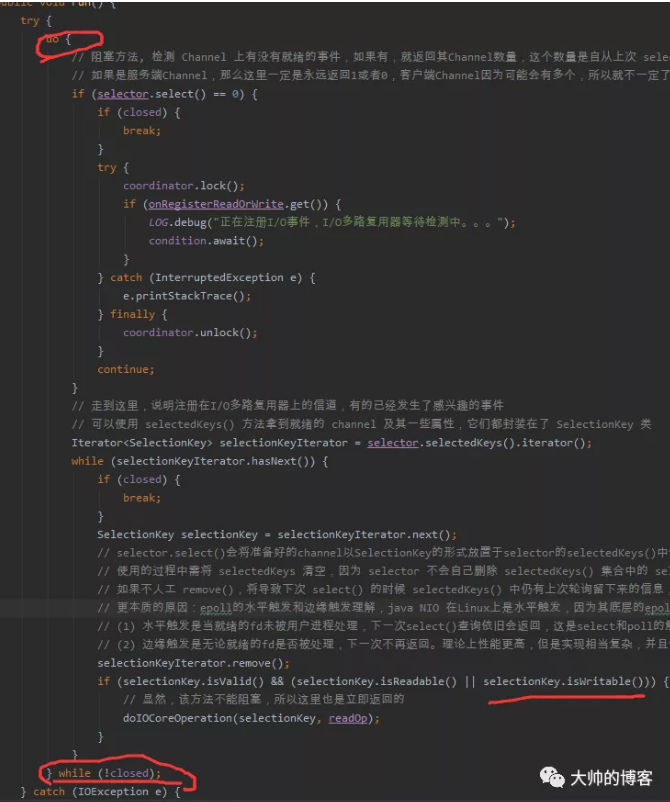
看最外层do-while循环里的while子循环代码,红线处有一个当前轮询出的Channel是否可写的判断,如果上来就给该Channel注册写事件,那么此时该判断在大多数时间下都是ture,接着反复执行doIOCoreOperation这个非阻塞的方法,此时并没有数据要写出,所以一直在做无用功,更根本的原因在于最开始的selector.select()大多数时间都不会阻塞,一直能让do-while循环跑起来。。。
为此,一种合理的做法是:
1、JDK NIO的OP_WRITE事件只有在有数据需要写出的场景,才注册到对应Channel上
2、大前提是这个Channel必须活跃
3、在触发OP_WRITE事件后,业务层应该及时处理这个事件,一般交给I/O线程处理,并且处理完立即取消OP_WRITE事件的注册,然后做判断:
当前需要写出的数据,一次发送不完,那么需要重新注册OP_WRITE事件,即循环的注册-写-取消-判断-。。。
当前需要写出的数据,已经发送完,那么就无需再次注册写事件
注册、触发写事件和什么时候写出没有直接关系
可能一些人初学NIO编程都会有这样一个认识误区:想当然的认为NIO的WRITE事件是调用了channel.write后发生的,因为调用Channel的write方法会执行把缓冲区里的数据真正写出去的操作。其实这是完全两个不同的东西,没有必然联系。
要知道,给组件注册XXX事件,仅仅是事件驱动模型的一种编程思想,不代表xxx事件一定会发生。比如写事件,写事件被触发,不代表有数据在此时此刻已经写出,它仅仅是告诉I/O多路复用器,此时某些连接上的缓冲区有空闲位置可放(写)数据。即这个注册写事件的过程是I/O多路复用器需要的,当某个Channel上注册了相关的I/O事件,就可以通过Selector的select(xxx)方法轮询出发生该事件的那些Channel,之后业务上做相应判断和处理即可。
还有一个可能的疑问,也就是开头提到的第二个问题:
有人说,JDK不是已经提供了一个往Socket连接写数据的方法么,在客户端直接调用它,给服务器发送数据不就OK了么,还注册什么写事件,还得检测,异步处理,各种坑。。。费这个劲呢!对此你怎么理解?
首先,理解为什么需要注册写事件,其它I/O事件同理。以写事件为例,给某个Channel注册写事件的目的是为了查看当前Channel的缓冲区是否可以写数据,这个触发时机前面说了就是底层缓冲区有空闲位置。如果写的数据非常非常少,那么完全可以不搞注册监听这一套逻辑,直接调用write方法也行,也能正常通信,但如果数据稍微多一些,那么就需要用户自己判断好连接底层的可读、可写、以及是否关闭等状态。即单纯的通信跟是否注册I/O事件没有直接关系。
其次,Channel的write方法并不可靠,即不一定真的会写出数据,比如在非阻塞模式下,该方法不会阻塞。假设网络环境很差,业务层一直在发数据,TCP的发送缓冲区很快会满,这一般是由滑动窗口等流量控制机制决定的,缓冲区满就会拒绝新数据写入。此时调用Channel的write方法就会立即返回0,口说无凭,咱们看JDK的注释:
/**
* Writes a sequence of bytes to this channel from the given buffer.
*
* <p> An attempt is made to write up to <i>r</i> bytes to the channel,
* where <i>r</i> is the number of bytes remaining in the buffer, that is,
* <tt>src.remaining()</tt>, at the moment this method is invoked.
*
* <p> Suppose that a byte sequence of length <i>n</i> is written, where
* <tt>0</tt> <tt><=</tt> <i>n</i> <tt><=</tt> <i>r</i>.
* This byte sequence will be transferred from the buffer starting at index
* <i>p</i>, where <i>p</i> is the buffer's position at the moment this
* method is invoked; the index of the last byte written will be
* <i>p</i> <tt>+</tt> <i>n</i> <tt>-</tt> <tt>1</tt>.
* Upon return the buffer's position will be equal to
* <i>p</i> <tt>+</tt> <i>n</i>; its limit will not have changed.
*
* <p> Unless otherwise specified, a write operation will return only after
* writing all of the <i>r</i> requested bytes. Some types of channels,
* depending upon their state, may write only some of the bytes or possibly
* none at all. A socket channel in non-blocking mode, for example, cannot
* write any more bytes than are free in the socket's output buffer.
*
* <p> This method may be invoked at any time. If another thread has
* already initiated a write operation upon this channel, however, then an
* invocation of this method will block until the first operation is
* complete. </p>
*
* @param src
* The buffer from which bytes are to be retrieved
*
* @return The number of bytes written, possibly zero
*
* @throws NonWritableChannelException
* If this channel was not opened for writing
*
* @throws ClosedChannelException
* If this channel is closed
*
* @throws AsynchronousCloseException
* If another thread closes this channel
* while the write operation is in progress
*
* @throws ClosedByInterruptException
* If another thread interrupts the current thread
* while the write operation is in progress, thereby
* closing the channel and setting the current thread's
* interrupt status
*
* @throws IOException
* If some other I/O error occurs
*/
public int write(ByteBuffer src) throws IOException;
大概意思是:尝试向该Channel中写入最多r个字节,r是调用此方法时缓冲区中剩余的字节数,即src.remaining()返回值,假设写入了长度为n的字节序列,其中0<=n<=r。从缓冲区的索引p处开始传输该字节,其中p是调用此方法时该缓冲区的位置;最后写入的字节索引是p+n-1。返回时该缓冲区的位置将等于p+n;限制不会更改。除非另行指定,否则仅在写入所有请求的r个字节后write操作才会返回。有些类型的Channel(取决于它们的状态)可能仅写入某些字节或者可能根本不写入。例如处于非阻塞模式的SocketChannel只能写入该套接字输出缓冲区中的字节。可在任意时间调用此方法。但是如果另一个线程已经在此Channel上发起了一个写操作,则在该操作完成前此方法的调用被阻塞。
注释说的非常细致了,需要正确理解这个过程。简单说,在发送缓冲区空间不够时,write方法返回的字节数可能只是需要写出数据的一部分,比如写缓冲区只剩100字节空间,写入200字节,write返回100,如果缓冲区满,那么write返回0。在正常情况下不太可能发生上述问题,就怕网络不好的时候,此时数据包重传率非常高,发送数据的I/O线程会一直被拖累在这里,这样干说可能不太形象,下面看一个demo,这是我之前自己写的一个NIO框架里,服务器发送消息的方法,当初就没有考虑这种情况:
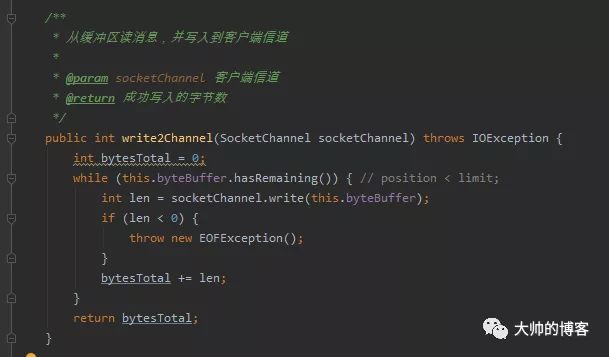
假设此时网络较差,调用socketChannel.write方法可能会返回0,而且是在非阻塞模型下编程,故socketChannel.write会立刻返回,且while判断条件会一直为true,在网络较差的这一段时间内,while循环快速转动。。。消耗大量CPU,且什么也没做,导致服务器性能会马上下降。
这时候注册OP_WRITE事件就有用了!NIO编程中比较常用的套路如下:
1、在socketChannel.write返回0时,给此Channel注册OP_WRITE事件,然后马上退出循环,让I/O线程去做别的事情
2、当网络恢复正常后,该Channel的底层写缓冲区会变为非满,此时触发Channel上的写事件,通知Selector,业务上就可以让I/O线程来处理写数据的操作,这样就能节约大量CPU资源,服务器也能适应恶劣的网络环境,非常健壮了。
说了很多理论,看看Netty是怎么做的。由此也感慨,有时候你觉得简单,是因为你不知道你不懂的东西还很多,共勉。
Netty处理写事件的过程分析
1、首先知道,Netty优先处理读事件,不会主动注册写事件,参考:
Netty在接收完新连接后,默认为何要为其注册读事件,其处理I/O事件的优先级是什么?如下是Netty的事件循环机制里,轮询到写事件后的处理逻辑,注释写到必须在处理完OP_WRITE事件后,在forceFlush方法里取消(clear)注册。
2、下面看Netty如何取消注册的I/O事件:
跟进forceFlush方法,中间的过程省略,会在写到Netty编解码的时候详细拆解,最终会调用到doWrite方法:
在for(;;)循环里,判断是否已经写完全部的消息,如果是,那么就调用clearOpWrite方法,清理注册的写事件:
如果以后有自己写NIO代码的时候,那么学会这种用法——使用位与运算判断并清理注册的I/O事件。
3、在看一下Netty的发消息的方法,还是只看本文相关的代码,其余过程省略,在写到编解码的时候在详细拆解。
在使用Netty时,往对端发消息,往往都是调用pipeline的writeAndFlush方法,如下:
最终调用到invokeFlush0方法是真正刷新消息到Channel里:
重点看这个方法,它最终调用到该客户端Channel的pipeline的头结点的flush方法,前面也提到过flsuh,write等都属于出站方法,而pipeline的头结点本身就是出站处理器,如下:
最终调用到内部类——unsafe的flush方法,内部最终会调用到doWrite方法,前面说取消注册的写事件时,简单提到过,看里面一段核心代码:
首先调用客户端Channel——ch的write方法,往Channel里写出数据,如果返回为0,说明可能遇到了网络较差的情况,此时Netty会立即break出循环写数据的逻辑,设置标记位setOpWrite为true,后面会进入如下方法:
此时setOpWrite为true,故会进入if条件,执行setOpWrite方法,顾名思义就是给当前Channel注册写事件:
注册完毕后,会退出整个writeAndFlush方法,等该NIO线程的事件循环处理器——run方法里再次轮询到写事件时,说明网络OK了,NIO线程再回头执行写操作。
总结
1、NIO的写事件不能随便注册,必须在写数据时才注册
2、写完数据,需要及时取消写事件的注册
3、知道为什么会有写事件,以及它在何时使用
4,学习Netty是如何适用恶劣的网络环境的
欢迎关注
dashuai的博客是终身学习践行者,大厂程序员,且专注于工作经验、学习笔记的分享和日常吐槽,包括但不限于互联网行业,附带分享一些PDF电子书,资料,帮忙内推,欢迎拍砖!

恶劣的网络环境下,Netty是如何处理写事件的?的更多相关文章
- 主机WIFI网络环境下,Linux虚拟机网络设置
在主机使用WIFI网络环境下,怎么样进行虚拟机静态ip设置和连接互联网呢,原理什么太麻烦,另类的网络共享而已: 1.其实简单将网络连接模式设置成NAT模式即可. 2.虚拟网络编辑器依旧是桥接模式,选择 ...
- linux网络环境下socket套接字编程(UDP文件传输)
今天我们来介绍一下在linux网络环境下使用socket套接字实现两个进程下文件的上传,下载,和退出操作! 在socket套接字编程中,我们当然可以基于TCP的传输协议来进行传输,但是在文件的传输中, ...
- 无网络环境下使用docker加载镜像
无网络环境下使用docker加载镜像 你需要做的主要有3步骤: 先从一个有网络的电脑下载docker镜像 [root@localhost ~]# docker pull hub.c.163.com ...
- virtual Box centos7 公司网络环境下不能联网的解决方案
首先感谢@采蘑菇的东峰的博客 的分享 原文:http://blog.sina.com.cn/s/blog_8d92d7580102vhky.html ------------------------- ...
- 在 win10 环境下,设置自己写的 程序 开机自动 启动的方法
原文:在 win10 环境下,设置自己写的 程序 开机自动 启动的方法 1.是登录自己用户时才能开机启 C:\Users\username\AppData\Roaming\Microsoft\Wind ...
- UNIX环境下用C语言写静态库与动态库
静态库,动态库用UNIX 的术语来说,或者叫做归档文件(archive 常以.a 结尾)和共享对象(share object 常以lib 开头.so 结尾)更为准确.静态库,动态库可能是WINDOWS ...
- 解决Chrome Safari Opera环境下 动态创建iframe onload事件同步执行
我们先看下面的代码: setTimeout(function(){ alert(count); },2000); var count = []; document.body.appendChild(c ...
- centos7无网络环境下创建基于scratch镜像的Linux镜像,并带有Java运行环境
一.准备 将下载好的jdk以及scratch镜像放在同一文件夹下:这里放在linux:2.0 二.导入scratch镜像 #docker load -i scratch.tar 三.创建dockerf ...
- ipv4-only网络环境下访问ipv6站点
使用6plat.org+openVPN(无需资金投入)进入ipv6网络 这里我们主要使用的是6plat.org提供的“46模块——IPv4到IPv6”功能,需要配合openVPN这个软件,支持wind ...
随机推荐
- Linux vi编辑的常用的操作备忘
1 复制 1) 单行复制 在命令模式下,将光标移动到将要复制的行处,按"yy"进行复制: 2) 多行复制 在命令模式下,将光标移动到将要复制的首行处,按"nyy" ...
- 贵州省网络安全知识竞赛个人赛Writeup
首先拖到D盾扫描 可以很明显的看出来确实就是两个后门 0x01 Index.php#一句话木马后门 0x02 About.php#文件包含漏洞 都可以很直观的看出来非常明显的漏洞,第一个直接就是eva ...
- hdu1015+hdu1016 都是十分钟以内的深搜题
hdu1015:给定一串可用序列值,每个字符映射到一个1-26之间的整数,选择五个有序数使得满足 a-b2+c3-d4+e5=target. #include<iostream> #inc ...
- python环境变量忘记配置
Python安装没有勾选配置环境变量安装 解决方法一: 于是,便用安装包卸载后重新安装. 重新安装勾选 安装成功 方法二: 配置环境变量 A.右键点击“我的电脑”,点击“属性”: B.在弹出的界面中点 ...
- 题解 P2642 【双子序列最大和】
前言 其实这道题的关键就是在于预处理,其方法类似于 合唱队形 正文 求最大子段和 要想求出双子序列最大和,首先我们要会求出最大子段和 最大子段和的求值方法很简单 定义 \(f_i\) 为以第 \(i\ ...
- Oracle数据库的创建表全
CREATE TABLE "库名"."表名" ( "FEE_ID" VARCHAR2(10 BYTE) constraint ABS_FEE ...
- 微信公众平台 分享 关注 js功能代码
转上一篇文章 微信很火,微信推出的公众平台也吸引了一部分市场宣传推广团队,像冷笑话大全这种微博养粉大户在微信的公众平台也是异常火爆. 因工作需求,最近为我们的市场部做了几个微信公共平台下的页面,其中涉 ...
- tf.contrib.legacy_seq2seq.basic_rnn_seq2seq 函数 example 最简单实现
tf.contrib.legacy_seq2seq.basic_rnn_seq2seq 函数 example 最简单实现 函数文档:https://www.tensorflow.org/api_doc ...
- Vue2.0 -- 钩子函数/ 过度属性/常用指令/以及Vue-resoure发送请求
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 关于getchar的疑惑
最近做了一道题,我的代码有片段是这样的 while(scanf("%d",&n)) { if(n==0&&getchar()=='\n') break; . ...