操作系统 I/O 全流程详解
我们之前的文章提到了操作系统的三个抽象,它们分别是进程、地址空间和文件,除此之外,操作系统还要控制所有的 I/O 设备。操作系统必须向设备发送命令,捕捉中断并处理错误。它还应该在设备和操作系统的其余部分之间提供一个简单易用的接口。操作系统如何管理 I/O 是我们接下来的重点。
不同的人对 I/O 硬件的理解也不同。对于电子工程师而言,I/O 硬件就是芯片、导线、电源和其他组成硬件的物理设备。而我们程序员眼中的 I/O 其实就是硬件提供给软件的接口,比如硬件接受到的命令、执行的操作以及反馈的错误。我们着重探讨的是如何对硬件进行编程,而不是其工作原理。
I/O 设备
什么是 I/O 设备?I/O 设备又叫做输入/输出设备,它是人类用来和计算机进行通信的外部硬件。输入/输出设备能够向计算机发送数据(输出)并从计算机接收数据(输入)。
I/O 设备(I/O devices)可以分成两种:块设备(block devices) 和 字符设备(character devices)。
块设备
块设备是一个能存储固定大小块信息的设备,它支持以固定大小的块,扇区或群集读取和(可选)写入数据。每个块都有自己的物理地址。通常块的大小在 512 - 65536 之间。所有传输的信息都会以连续的块为单位。块设备的基本特征是每个块都较为对立,能够独立的进行读写。常见的块设备有 硬盘、蓝光光盘、USB 盘
与字符设备相比,块设备通常需要较少的引脚。

块设备的缺点
基于给定固态存储器的块设备比基于相同类型的存储器的字节寻址要慢一些,因为必须在块的开头开始读取或写入。所以,要读取该块的任何部分,必须寻找到该块的开始,读取整个块,如果不使用该块,则将其丢弃。要写入块的一部分,必须寻找到块的开始,将整个块读入内存,修改数据,再次寻找到块的开头处,然后将整个块写回设备。
字符设备
另一类 I/O 设备是字符设备。字符设备以字符为单位发送或接收一个字符流,而不考虑任何块结构。字符设备是不可寻址的,也没有任何寻道操作。常见的字符设备有 打印机、网络设备、鼠标、以及大多数与磁盘不同的设备。

下面显示了一些常见设备的数据速率。

设备控制器
首先需要先了解一下设备控制器的概念。
设备控制器是处理 CPU 传入和传出信号的系统。设备通过插头和插座连接到计算机,并且插座连接到设备控制器。设备控制器从连接的设备处接收数据,并将其存储在控制器内部的一些特殊目的寄存器(special purpose registers) 也就是本地缓冲区中。
特殊用途寄存器,顾名思义是仅为一项任务而设计的寄存器。例如,cs,ds,gs 和其他段寄存器属于特殊目的寄存器,因为它们的存在是为了保存段号。 eax,ecx 等是一般用途的寄存器,因为你可以无限制地使用它们。 例如,你不能移动 ds,但是可以移动 eax,ebx。
通用目的寄存器比如有:eax、ecx、edx、ebx、esi、edi、ebp、esp
特殊目的寄存器比如有:cs、ds、ss、es、fs、gs、eip、flag
每个设备控制器都会有一个应用程序与之对应,设备控制器通过应用程序的接口通过中断与操作系统进行通信。设备控制器是硬件,而设备驱动程序是软件。
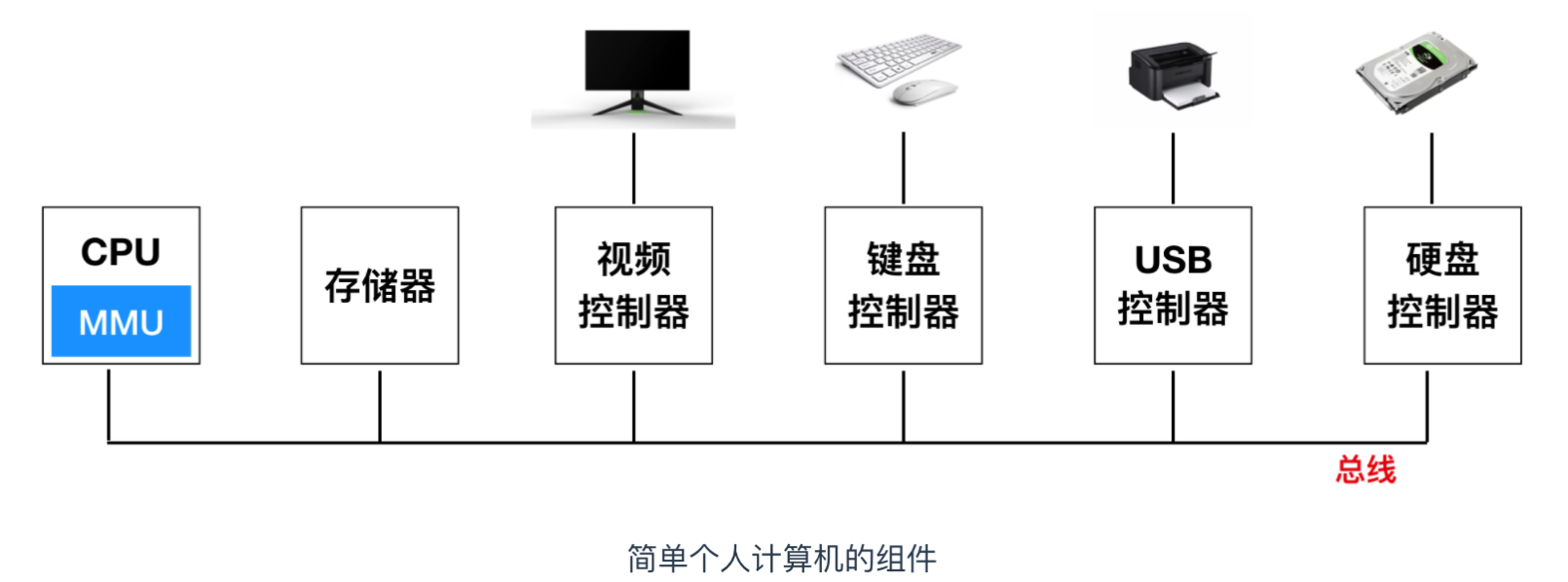
I/O 设备通常由机械组件(mechanical component)和电子组件(electronic component)构成。电子组件被称为 设备控制器(device controller)或者 适配器(adapter)。在个人计算机上,它通常采用可插入(PCIe)扩展插槽的主板上的芯片或印刷电路卡的形式。

机械设备就是它自己,它的组成如下
控制器卡上通常会有一个连接器,通向设备本身的电缆可以插入到这个连接器中,很多控制器可以操作 2 个、4 个设置 8 个相同的设备。
控制器与设备之间的接口通常是一个低层次的接口。例如,磁盘可能被格式化为 2,000,000 个扇区,每个磁道 512 字节。然而,实际从驱动出来的却是一个串行的比特流,从一个前导符(preamble)开始,然后是一个扇区中的 4096 位,最后是一个校验和 或 ECC(错误码,Error-Correcting Code)。前导符是在对磁盘进行格式化的时候写上去的,它包括柱面数和扇区号,扇区大小以及类似的数据,此外还包含同步信息。
控制器的任务是把串行的位流转换为字节块,并进行必要的错误校正工作。字节块通常会在控制器内部的一个缓冲区按位进行组装,然后再对校验和进行校验并证明字节块没有错误后,再将它复制到内存中。
内存映射 I/O
每个控制器都会有几个寄存器用来和 CPU 进行通信。通过写入这些寄存器,操作系统可以命令设备发送数据,接收数据、开启或者关闭设备等。通过从这些寄存器中读取信息,操作系统能够知道设备的状态,是否准备接受一个新命令等。
为了控制寄存器,许多设备都会有数据缓冲区(data buffer),来供系统进行读写。例如,在屏幕上显示一个像素的常规方法是使用一个视频 RAM,这一 RAM 基本上只是一个数据缓冲区,用来供程序和操作系统写入数据。
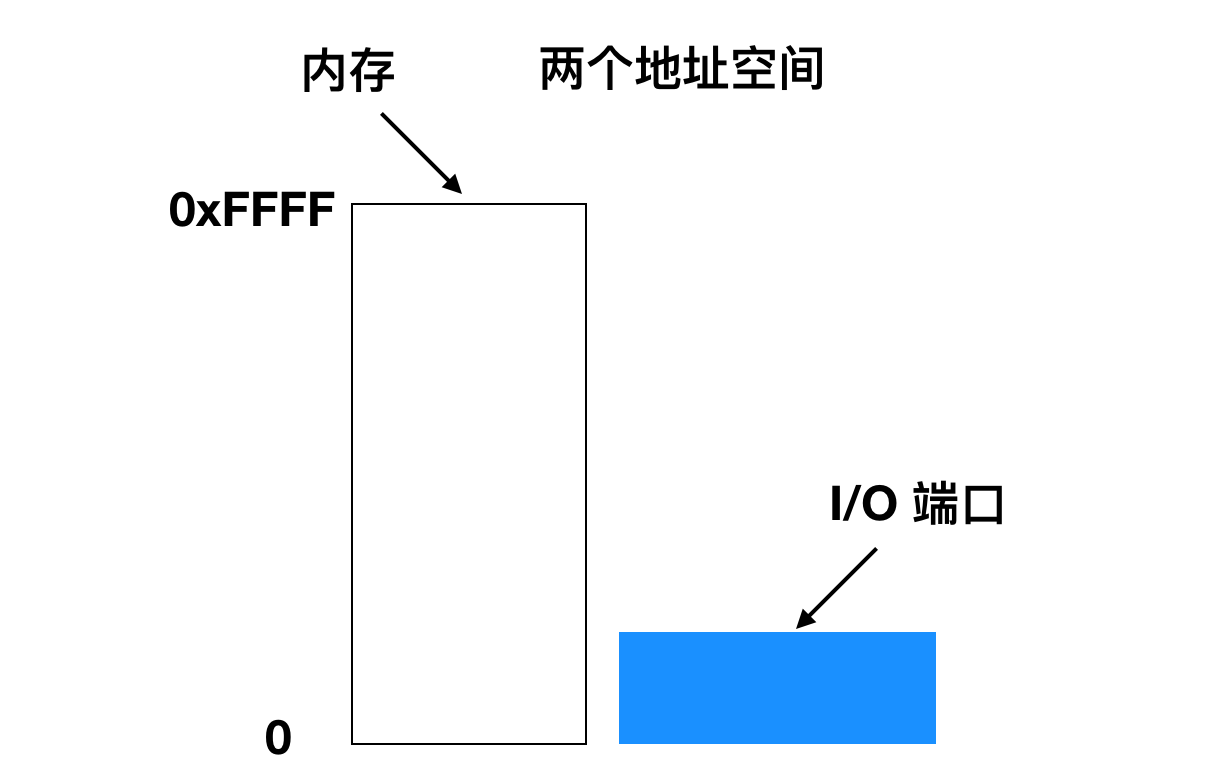
那么问题来了,CPU 如何与设备寄存器和设备数据缓冲区进行通信呢?存在两个可选的方式。第一种方法是,每个控制寄存器都被分配一个 I/O 端口(I/O port)号,这是一个 8 位或 16 位的整数。所有 I/O 端口的集合形成了受保护的 I/O 端口空间,以便普通用户程序无法访问它(只有操作系统可以访问)。使用特殊的 I/O 指令像是
IN REG,PORT
CPU 可以读取控制寄存器 PORT 的内容并将结果放在 CPU 寄存器 REG 中。类似的,使用
OUT PORT,REG
CPU 可以将 REG 的内容写到控制寄存器中。大多数早期计算机,包括几乎所有大型主机,如 IBM 360 及其所有后续机型,都是以这种方式工作的。
控制寄存器是一个处理器寄存器而改变或控制的一般行为 CPU 或其他数字设备。控制寄存器执行的常见任务包括中断控制,切换寻址模式,分页控制和协处理器控制。
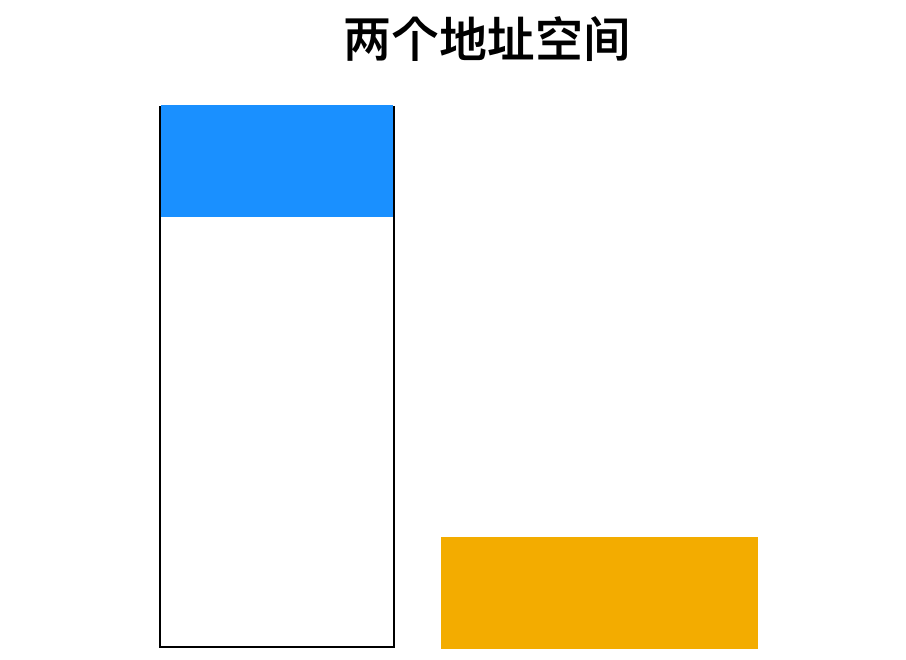
在这一方案中,内存地址空间和 I/O 地址空间是不相同的,如下图所示
指令
IN R0,4
和
MOV R0,4
这一设计中完全不同。前者读取 I/O端口 4 的内容并将其放入 R0,而后者读取存储器字 4 的内容并将其放入 R0。这些示例中的 4 代表不同且不相关的地址空间。
第二个方法是 PDP-11 引入的,
什么是 PDP-11?

它将所有控制寄存器映射到内存空间中,如下图所示
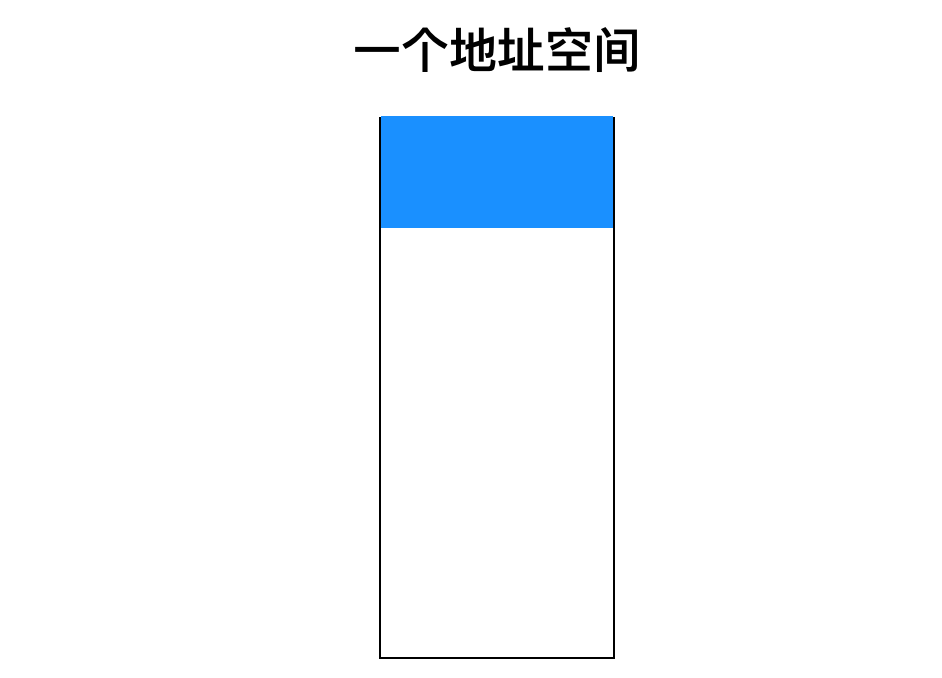
内存映射的 I/O 是在 CPU 与其连接的外围设备之间交换数据和指令的一种方式,这种方式是处理器和 IO 设备共享同一内存位置的内存,即处理器和 IO 设备使用内存地址进行映射。
在大多数系统中,分配给控制寄存器的地址位于或者靠近地址的顶部附近。
下面是采用的一种混合方式
这种方式具有与内存映射 I/O 的数据缓冲区,而控制寄存器则具有单独的 I/O 端口。x86 采用这一体系结构。在 IBM PC 兼容机中,除了 0 到 64K - 1 的 I/O 端口之外,640 K 到 1M - 1 的内存地址保留给设备的数据缓冲区。
这些方案是如何工作的呢?当 CPU 想要读入一个字的时候,无论是从内存中读入还是从 I/O 端口读入,它都要将需要的地址放到总线地址线上,然后在总线的一条控制线上调用一个 READ 信号。还有第二条信号线来表明需要的是 I/O 空间还是内存空间。如果是内存空间,内存将响应请求。如果是 I/O 空间,那么 I/O 设备将响应请求。如果只有内存空间,那么每个内存模块和每个 I/O 设备都会将地址线和它所服务的地址范围进行比较。如果地址落在这一范围之内,它就会响应请求。绝对不会出现地址既分配给内存又分配给 I/O 设备,所以不会存在歧义和冲突。
内存映射 I/O 的优点和缺点
这两种寻址控制器的方案具有不同的优缺点。先来看一下内存映射 I/O 的优点。
- 第一,如果需要特殊的 I/O 指令读写设备控制寄存器,那么访问这些寄存器需要使用汇编代码,因为在 C 或 C++ 中不存在执行
IN和OUT指令的方法。调用这样的过程增加了 I/O 的开销。在内存映射中,控制寄存器只是内存中的变量,在 C 语言中可以和其他变量一样进行寻址。 - 第二,对于内存映射 I/O ,不需要特殊的保护机制就能够阻止用户进程执行 I/O 操作。操作系统需要保证的是禁止把控制寄存器的地址空间放在用户的虚拟地址中就可以了。
- 第三,对于内存映射 I/O,可以引用内存的每一条指令也可以引用控制寄存器,便于引用。
在计算机设计中,几乎所有的事情都要权衡。内存映射 I/O 也是一样,它也有自己的缺点。首先,大部分计算机现在都会有一些对于内存字的缓存。缓存一个设备控制寄存器的代价是很大的。为了避免这种内存映射 I/O 的情况,硬件必须有选择性的禁用缓存,例如,在每个页面上禁用缓存,这个功能为硬件和操作系统增加了额外的复杂性,因此必须选择性的进行管理。
第二点,如果仅仅只有一个地址空间,那么所有的内存模块(memory modules)和所有的 I/O 设备都必须检查所有的内存引用来推断出谁来进行响应。
什么是内存模块?在计算中,存储器模块是其上安装有存储器集成电路的印刷电路板。

如果计算机是一种单总线体系结构的话,如下图所示
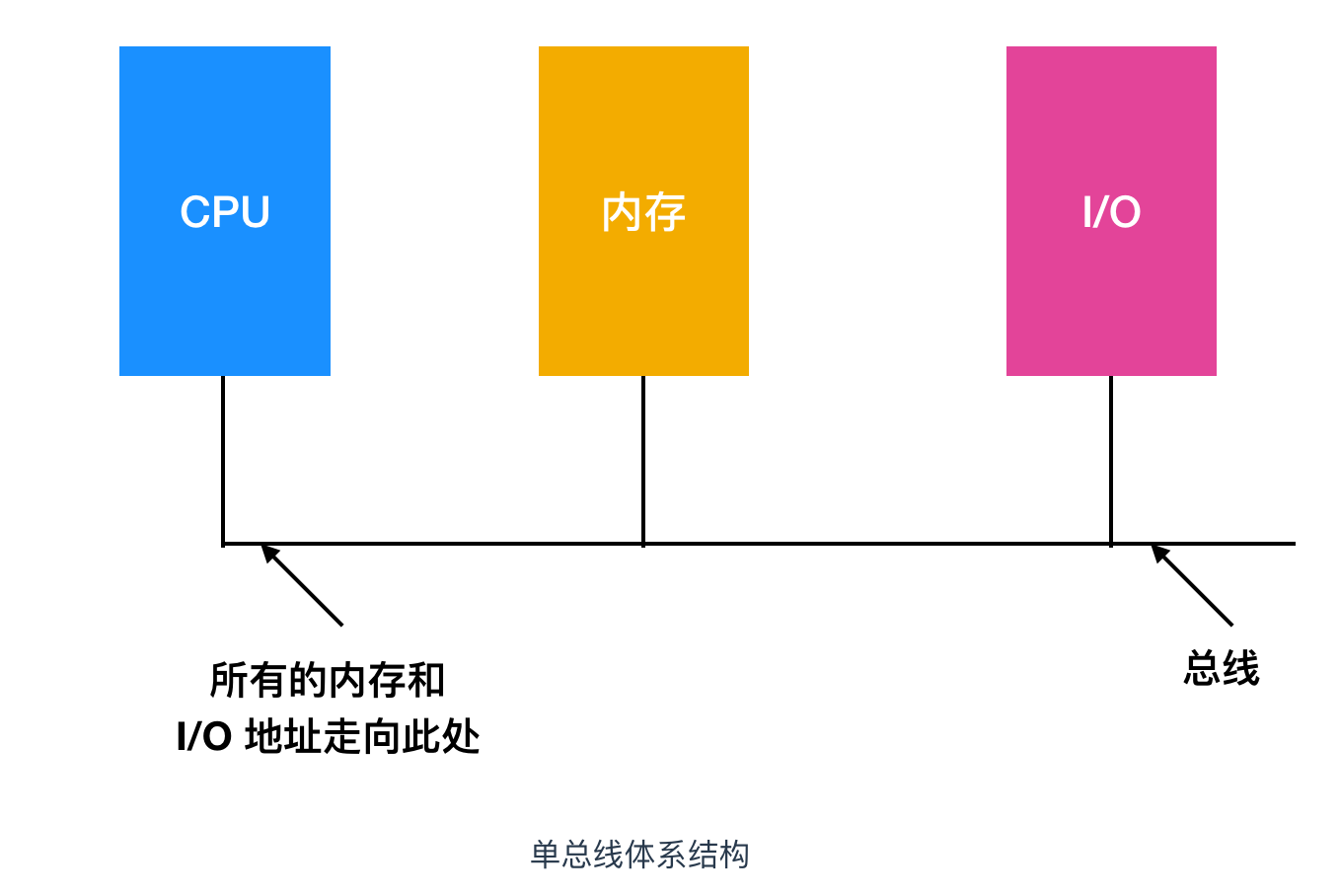
让每个内存模块和 I/O 设备查看每个地址是简单易行的。
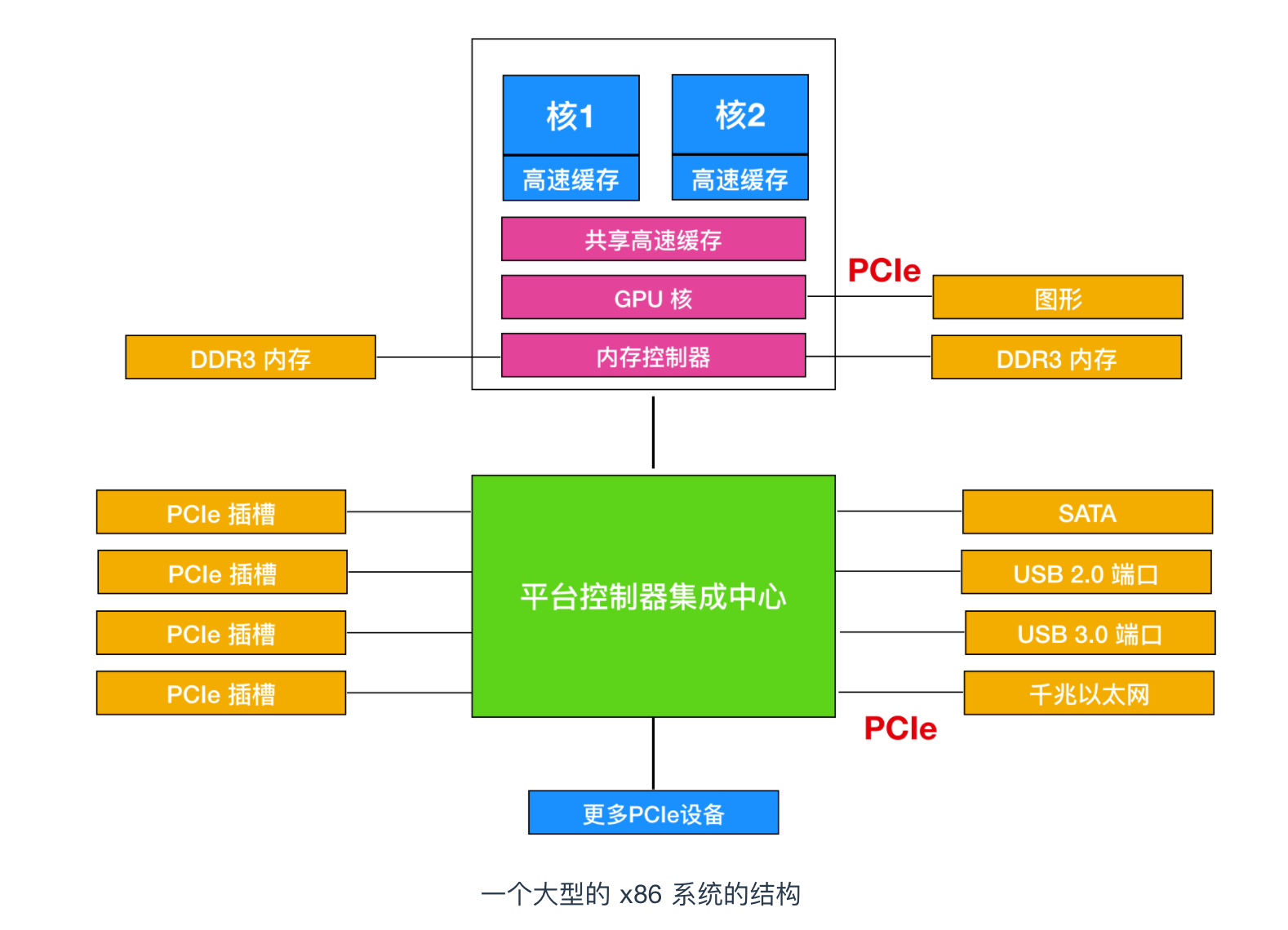
然而,现代个人计算机的趋势是专用的高速内存总线,如下图所示

装备这一总线是为了优化内存访问速度,x86 系统还可以有多种总线(内存、PCIe、SCSI 和 USB)。如下图所示
在内存映射机器上使用单独的内存总线的麻烦之处在于,I/O 设备无法通过内存总线查看内存地址,因此它们无法对其进行响应。此外,必须采取特殊的措施使内存映射 I/O 工作在具有多总线的系统上。一种可能的方法是首先将全部内存引用发送到内存,如果内存响应失败,CPU 再尝试其他总线。
第二种设计是在内存总线上放一个探查设备,放过所有潜在指向所关注的 I/O 设备的地址。此处的问题是,I/O 设备可能无法以内存所能达到的速度处理请求。
第三种可能的设计是在内存控制器中对地址进行过滤,这种设计与上图所描述的设计相匹配。这种情况下,内存控制器芯片中包含在引导时预装载的范围寄存器。这一设计的缺点是需要在引导时判定哪些内存地址而不是真正的内存地址。因而,每一设计都有支持它和反对它的论据,所以折中和权衡是不可避免的。
直接内存访问
无论一个 CPU 是否具有内存映射 I/O,它都需要寻址设备控制器以便与它们交换数据。CPU 可以从 I/O 控制器每次请求一个字节的数据,但是这么做会浪费 CPU 时间,所以经常会用到一种称为直接内存访问(Direct Memory Access) 的方案。为了简化,我们假设 CPU 通过单一的系统总线访问所有的设备和内存,该总线连接 CPU 、内存和 I/O 设备,如下图所示
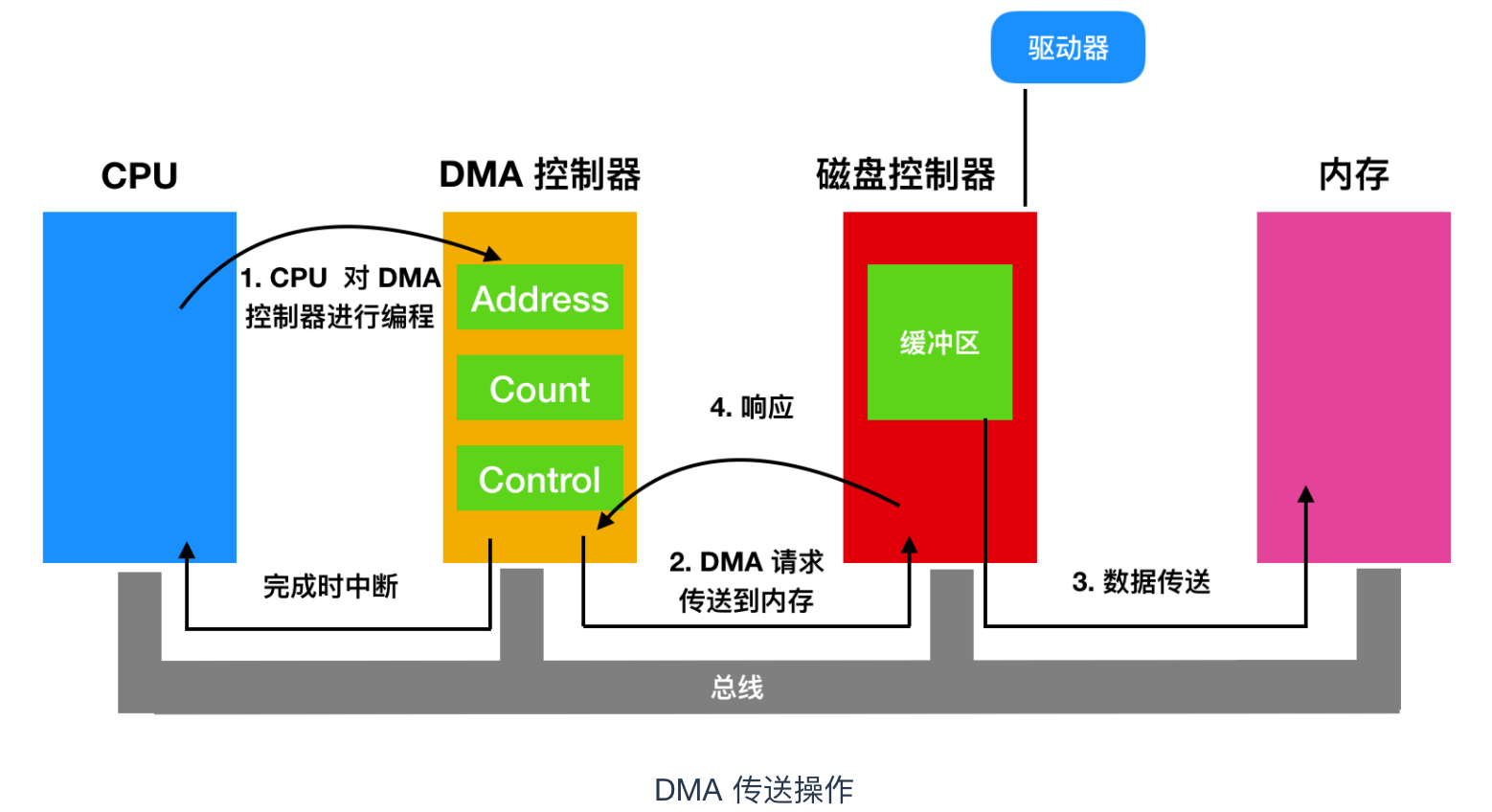
现代操作系统实际更为复杂,但是原理是相同的。如果硬件有 DMA 控制器,那么操作系统只能使用 DMA。有时这个控制器会集成到磁盘控制器和其他控制器中,但这种设计需要在每个设备上都装有一个分离的 DMA 控制器。单个的 DMA 控制器可用于向多个设备传输,这种传输往往同时进行。
不管 DMA 控制器的物理地址在哪,它都能够独立于 CPU 从而访问系统总线,如上图所示。它包含几个可由 CPU 读写的寄存器,其中包括一个内存地址寄存器,字节计数寄存器和一个或多个控制寄存器。控制寄存器指定要使用的 I/O 端口、传送方向(从 I/O 设备读或写到 I/O 设备)、传送单位(每次一个字节或者每次一个字)以及在一次突发传送中要传送的字节数。
为了解释 DMA 的工作原理,我们首先看一下不使用 DMA 该如何进行磁盘读取。
- 首先,控制器从
磁盘驱动器串行地、一位一位的读一个块(一个或多个扇区),直到将整块信息放入控制器的内部缓冲区。 - 读取
校验和以保证没有发生读错误。然后控制器会产生一个中断,当操作系统开始运行时,它会重复的从控制器的缓冲区中一次一个字节或者一个字地读取该块的信息,并将其存入内存中。
DMA 工作原理
当使用 DMA 后,这个过程就会变得不一样了。首先 CPU 通过设置 DMA 控制器的寄存器对它进行编程,所以 DMA 控制器知道将什么数据传送到什么地方。DMA 控制器还要向磁盘控制器发出一个命令,通知它从磁盘读数据到其内部的缓冲区并检验校验和。当有效数据位于磁盘控制器的缓冲区中时,DMA 就可以开始了。
DMA 控制器通过在总线上发出一个读请求到磁盘控制器而发起 DMA 传送,这是第二步。这个读请求就像其他读请求一样,磁盘控制器并不知道或者并不关心它是来自 CPU 还是来自 DMA 控制器。通常情况下,要写的内存地址在总线的地址线上,所以当磁盘控制器去匹配下一个字时,它知道将该字写到什么地方。写到内存就是另外一个总线循环了,这是第三步。当写操作完成时,磁盘控制器在总线上发出一个应答信号到 DMA 控制器,这是第四步。
然后,DMA 控制器会增加内存地址并减少字节数量。如果字节数量仍然大于 0 ,就会循环步骤 2 - 步骤 4 ,直到字节计数变为 0 。此时,DMA 控制器会打断 CPU 并告诉它传输已经完成了。操作系统开始运行时,它不会把磁盘块拷贝到内存中,因为它已经在内存中了。
不同 DMA 控制器的复杂程度差别很大。最简单的 DMA 控制器每次处理一次传输,就像上面描述的那样。更为复杂的情况是一次同时处理很多次传输,这样的控制器内部具有多组寄存器,每个通道一组寄存器。在传输每一个字之后,DMA 控制器就决定下一次要为哪个设备提供服务。DMA 控制器可能被设置为使用 轮询算法,或者它也有可能具有一个优先级规划设计,以便让某些设备受到比其他设备更多的照顾。假如存在一个明确的方法分辨应答信号,那么在同一时间就可以挂起对不同设备控制器的多个请求。
许多总线能够以两种模式操作:每次一字模式和块模式。一些 DMA 控制器也能够使用这两种方式进行操作。在前一个模式中,DMA 控制器请求传送一个字并得到这个字。如果 CPU 想要使用总线,它必须进行等待。设备可能会偷偷进入并且从 CPU 偷走一个总线周期,从而轻微的延迟 CPU。这种机制称为 周期窃取(cycle stealing)。
在块模式中,DMA 控制器告诉设备获取总线,然后进行一系列的传输操作,然后释放总线。这一操作的形式称为 突发模式(burst mode)。这种模式要比周期窃取更有效因为获取总线占用了时间,并且一次总线获得的代价是可以同时传输多个字。缺点是如果此时进行的是长时间的突发传送,有可能将 CPU 和其他设备阻塞很长的时间。
在我们讨论的这种模型中,有时被称为 飞越模式(fly-by mode),DMA 控制器会告诉设备控制器把数据直接传递到内存。一些 DMA 控制器使用的另一种模式是让设备控制器将字发送给 DMA 控制器,然后 DMA 控制器发出第二条总线请求,将字写到任何可以写入的地方。采用这种方案,每个传输的字都需要一个额外的总线周期,但是更加灵活,因为它还可以执行设备到设备的复制,甚至是内存到内存的复制(通过事先对内存进行读取,然后对内存进行写入)。
大部分的 DMA 控制器使用物理地址进行传输。使用物理地址需要操作系统将目标内存缓冲区的虚拟地址转换为物理地址,并将该物理地址写入 DMA 控制器的地址寄存器中。另一种方案是一些 DMA 控制器将虚拟地址写入 DMA 控制器中。然后,DMA 控制器必须使用 MMU 才能完成虚拟到物理的转换。仅当 MMU 是内存的一部分而不是 CPU 的一部分时,才可以将虚拟地址放在总线上。
重温中断
在一台个人计算机体系结构中,中断结构会如下所示

当一个 I/O 设备完成它的工作后,它就会产生一个中断(默认操作系统已经开启中断),它通过在总线上声明已分配的信号来实现此目的。主板上的中断控制器芯片会检测到这个信号,然后执行中断操作。
如果在中断前没有其他中断操作阻塞的话,中断控制器将立刻对中断进行处理,如果在中断前还有其他中断操作正在执行,或者有其他设备发出级别更高的中断信号的话,那么这个设备将暂时不会处理。在这种情况下,该设备会继续在总线上置起中断信号,直到得到 CPU 服务。
为了处理中断,中断控制器在地址线上放置一个数字,指定要关注的设备是哪个,并声明一个信号以中断 CPU。中断信号导致 CPU 停止当前正在做的工作并且开始做其他事情。地址线上会有一个指向中断向量表 的索引,用来获取下一个程序计数器。这个新获取的程序计数器也就表示着程序将要开始,它会指向程序的开始处。一般情况下,陷阱和中断从这一点上看使用相同的机制,并且常常共享相同的中断向量。中断向量的位置可以硬连线到机器中,也可以位于内存中的任何位置,由 CPU 寄存器指向其起点。
中断服务程序开始运行后,中断服务程序通过将某个值写入中断控制器的 I/O 端口来确认中断。告诉它中断控制器可以自由地发出另一个中断。通过让 CPU 延迟响应来达到多个中断同时到达 CPU 涉及到竞争的情况发生。一些老的计算机没有集中的中断控制器,通常每个设备请求自己的中断。
硬件通常在服务程序开始前保存当前信息。对于不同的 CPU 来说,哪些信息需要保存以及保存在哪里差别很大。不管其他的信息是否保存,程序计数器必须要被保存,这对所有的 CPU 来说都是相同的,以此来恢复中断的进程。所有可见寄存器和大量内部寄存器也应该被保存。
上面说到硬件应该保存当前信息,那么保存在哪里是个问题,一种选择是将其放入到内部寄存器中,在需要时操作系统可以读出这些内部寄存器。这种方法会造成的问题是:一段时间内设备无法响应,直到所有的内部寄存器中存储的信息被读出后,才能恢复运行,以免第二个内部寄存器重写内部寄存器的状态。
第二种方式是在堆栈中保存信息,这也是大部分 CPU 所使用的方式。但是,这种方法也存在问题,因为使用的堆栈不确定,如果使用的是当前堆栈,则它很可能是用户进程的堆栈。堆栈指针甚至不合法,这样当硬件试图在它所指的地址处写入时,将会导致致命错误。如果使用的是内核堆栈,堆栈指针是合法的并且指向一个固定的页面,这样的机会可能会更大。然而,切换到内核态需要切换 MMU 上下文,并且可能使高速缓存或者 TLB 失效。静态或动态重新装载这些东西将增加中断处理的时间,浪费 CPU 时间。
精确中断和不精确中断
另一个问题是:现代 CPU 大量的采用流水线并且有时还采用超标量(内部并行)。在一些老的系统中,每条指令执行完毕后,微程序或硬件将检查是否存在未完成的中断。如果存在,那么程序计数器和 PSW 将被压入堆栈中开始中断序列。在中断程序运行之后,旧的 PSW 和程序计数器将从堆栈中弹出恢复先前的进程。
下面是一个流水线模型
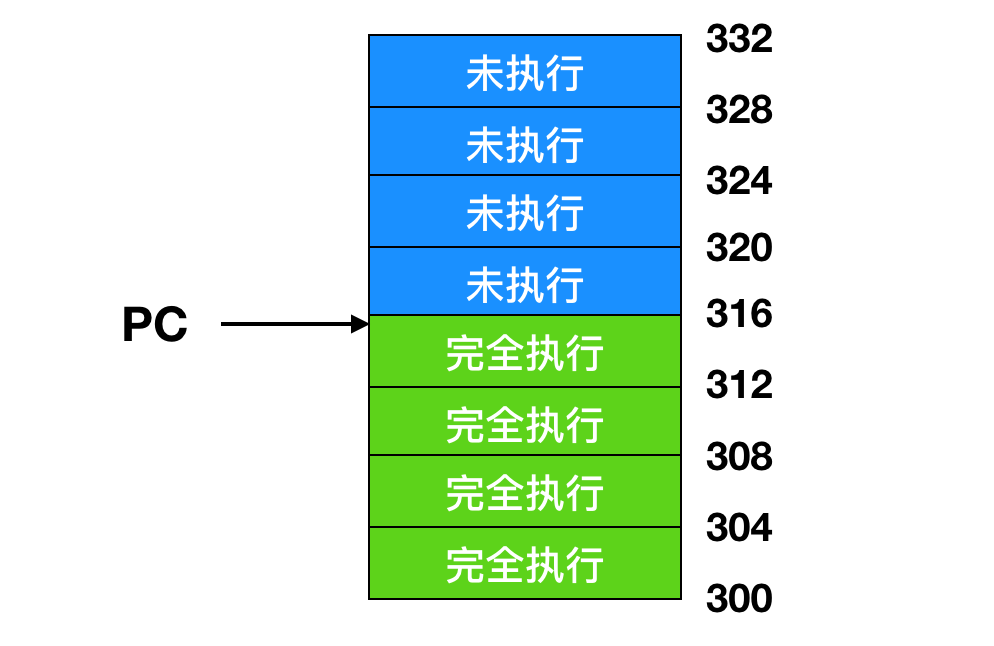
在流水线满的时候出现一个中断会发生什么情况?许多指令正处于不同的执行阶段,中断出现时,程序计数器的值可能无法正确地反应已经执行过的指令和尚未执行的指令的边界。事实上,许多指令可能部分执行力,不同的指令完成的程度或多或少。在这种情况下,a程序计数器更有可能反应的是将要被取出并压入流水线的下一条指令的地址,而不是刚刚被执行单元处理过的指令的地址。
在超标量的设计中,可能更加糟糕

每个指令都可以分解成为微操作,微操作有可能乱序执行,这取决于内部资源(如功能单元和寄存器)的可用性。当中断发生时,某些很久以前启动的指令可能还没开始执行,而最近执行的指令可能将要马上完成。在中断信号出现时,可能存在许多指令处于不同的完成状态,它们与程序计数器之间没有什么关系。
使机器处于良好状态的中断称为精确中断(precise interrupt)。这样的中断具有四个属性:
- PC (程序计数器)保存在一个已知的地方
- PC 所指向的指令之前所有的指令已经完全执行
- PC 所指向的指令之后所有的指令都没有执行
- PC 所指向的指令的执行状态是已知的
不满足以上要求的中断称为 不精确中断(imprecise interrupt),不精确中断让人很头疼。上图描述了不精确中断的现象。指令的执行时序和完成度具有不确定性,而且恢复起来也非常麻烦。
IO 软件原理
I/O 软件目标
设备独立性
现在让我们转向对 I/O 软件的研究,I/O 软件设计一个很重要的目标就是设备独立性(device independence)。啥意思呢?这意味着我们能够编写访问任何设备的应用程序,而不用事先指定特定的设备。比如你编写了一个能够从设备读入文件的应用程序,那么这个应用程序可以从硬盘、DVD 或者 USB 进行读入,不必再为每个设备定制应用程序。这其实就体现了设备独立性的概念。

再比如说你可以输入一条下面的指令
sort 输入 输出
那么上面这个 输入 就可以接收来自任意类型的磁盘或者键盘,并且 输出 可以写入到任意类型的磁盘或者屏幕。

计算机操作系统是这些硬件的媒介,因为不同硬件它们的指令序列不同,所以需要操作系统来做指令间的转换。
与设备独立性密切相关的一个指标就是统一命名(uniform naming)。设备的代号应该是一个整数或者是字符串,它们不应该依赖于具体的设备。在 UNIX 中,所有的磁盘都能够被集成到文件系统中,所以用户不用记住每个设备的具体名称,直接记住对应的路径即可,如果路径记不住,也可以通过 ls 等指令找到具体的集成位置。举个例子来说,比如一个 USB 磁盘被挂载到了 /usr/cxuan/backup 下,那么你把文件复制到 /usr/cxuan/backup/device 下,就相当于是把文件复制到了磁盘中,通过这种方式,实现了向任何磁盘写入文件都相当于是向指定的路径输出文件。
错误处理
除了设备独立性外,I/O 软件实现的第二个重要的目标就是错误处理(error handling)。通常情况下来说,错误应该交给硬件层面去处理。如果设备控制器发现了读错误的话,它会尽可能的去修复这个错误。如果设备控制器处理不了这个问题,那么设备驱动程序应该进行处理,设备驱动程序会再次尝试读取操作,很多错误都是偶然性的,如果设备驱动程序无法处理这个错误,才会把错误向上抛到硬件层面(上层)进行处理,很多时候,上层并不需要知道下层是如何解决错误的。这就很像项目经理不用把每个决定都告诉老板;程序员不用把每行代码如何写告诉项目经理。这种处理方式不够透明。
同步和异步传输
I/O 软件实现的第三个目标就是 同步(synchronous) 和 异步(asynchronous,即中断驱动)传输。这里先说一下同步和异步是怎么回事吧。
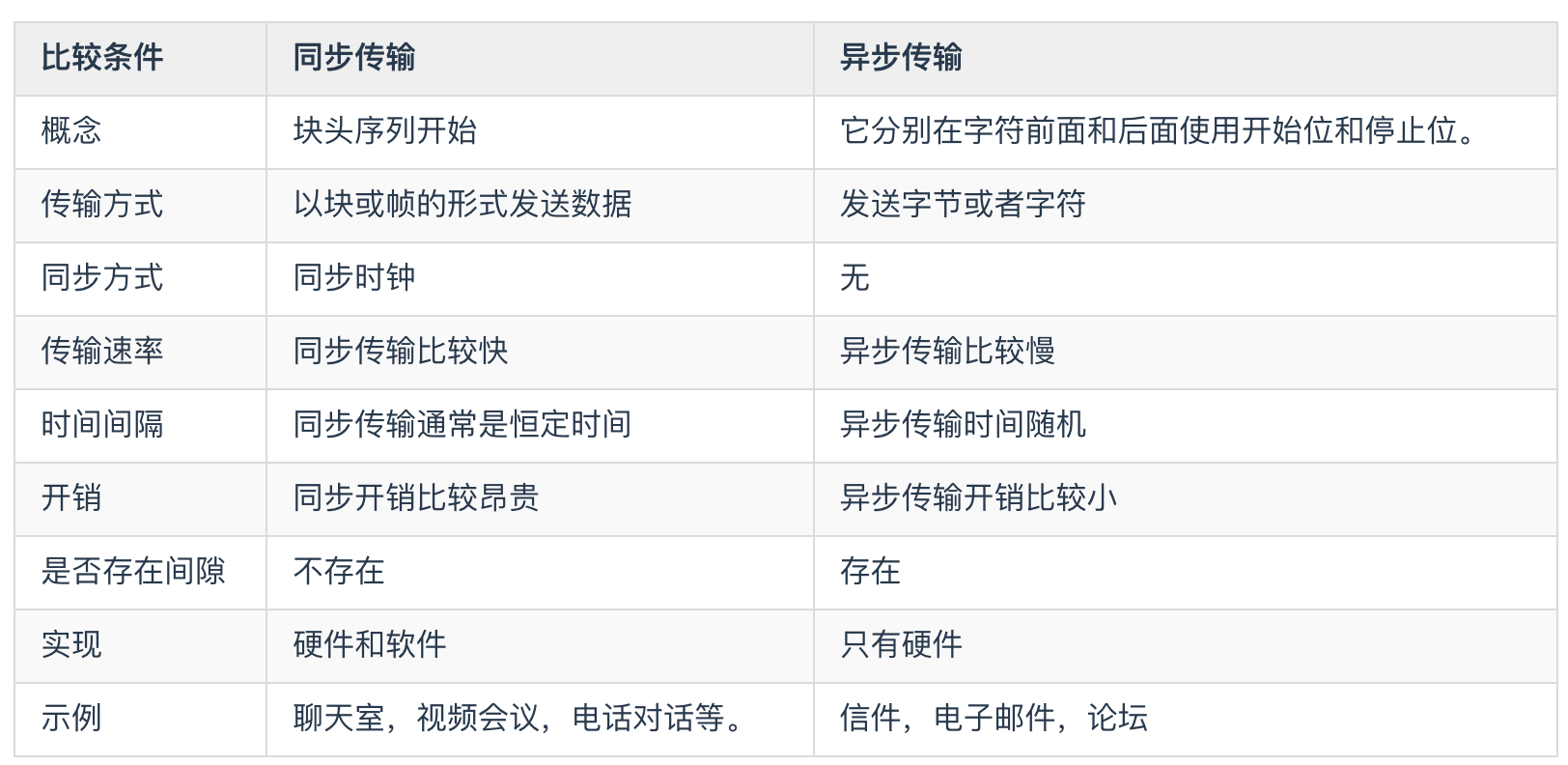
同步传输中数据通常以块或帧的形式发送。发送方和接收方在数据传输之前应该具有同步时钟。而在异步传输中,数据通常以字节或者字符的形式发送,异步传输则不需要同步时钟,但是会在传输之前向数据添加奇偶校验位。下面是同步和异步的主要区别
回到正题。大部分物理IO(physical I/O) 是异步的。物理 I/O 中的 CPU 是很聪明的,CPU 传输完成后会转而做其他事情,它和中断心灵相通,等到中断发生后,CPU 才会回到传输这件事情上来。
I/O 分为两种:物理I/O 和
逻辑I/O(Logical I/O)。物理 I/O 通常是从磁盘等存储设备实际获取数据。逻辑 I/O 是对存储器(块,缓冲区)获取数据。
缓冲
I/O 软件的最后一个问题是缓冲(buffering)。通常情况下,从一个设备发出的数据不会直接到达最后的设备。其间会经过一系列的校验、检查、缓冲等操作才能到达。举个例子来说,从网络上发送一个数据包,会经过一系列检查之后首先到达缓冲区,从而消除缓冲区填满速率和缓冲区过载。
共享和独占
I/O 软件引起的最后一个问题就是共享设备和独占设备的问题。有些 I/O 设备能够被许多用户共同使用。一些设备比如磁盘,让多个用户使用一般不会产生什么问题,但是某些设备必须具有独占性,即只允许单个用户使用完成后才能让其他用户使用。
下面,我们来探讨一下如何使用程序来控制 I/O 设备。一共有三种控制 I/O 设备的方法
- 使用程序控制 I/O
- 使用中断驱动 I/O
- 使用 DMA 驱动 I/O
使用程序控制 I/O
使用程序控制 I/O 又被称为 可编程I/O,它是指由 CPU 在驱动程序软件控制下启动的数据传输,来访问设备上的寄存器或者其他存储器。CPU 会发出命令,然后等待 I/O 操作的完成。由于 CPU 的速度比 I/O 模块的速度快很多,因此可编程 I/O 的问题在于,CPU 必须等待很长时间才能等到处理结果。CPU 在等待时会采用轮询(polling)或者 忙等(busy waiting) 的方式,结果,整个系统的性能被严重拉低。可编程 I/O 十分简单,如果需要等待的时间非常短的话,可编程 I/O 倒是一个很好的方式。一个可编程的 I/O 会经历如下操作
- CPU 请求 I/O 操作
- I/O 模块执行响应
- I/O 模块设置状态位
- CPU 会定期检查状态位
- I/O 不会直接通知 CPU 操作完成
- I/O 也不会中断 CPU
- CPU 可能会等待或在随后的过程中返回

使用中断驱动 I/O
鉴于上面可编程 I/O 的缺陷,我们提出一种改良方案,我们想要在 CPU 等待 I/O 设备的同时,能够做其他事情,等到 I/O 设备完成后,它就会产生一个中断,这个中断会停止当前进程并保存当前的状态。一个可能的示意图如下
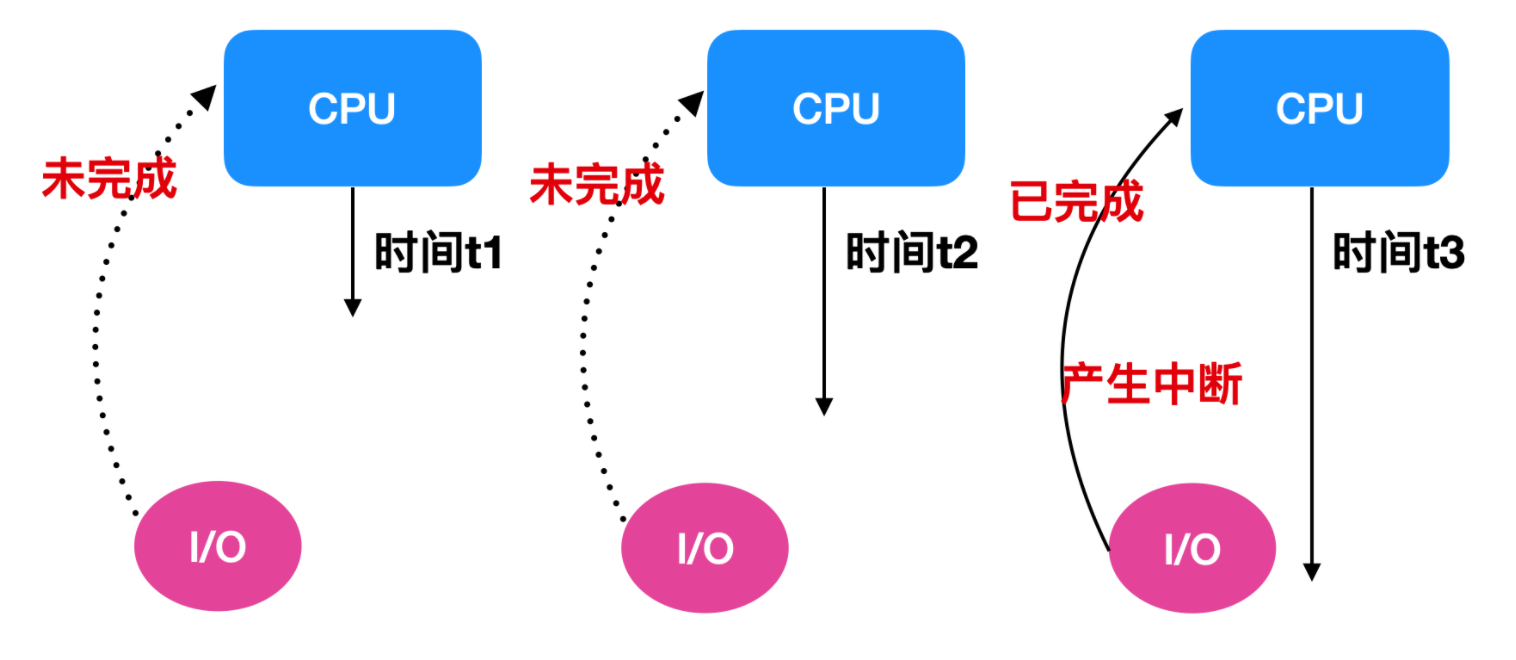
尽管中断减轻了 CPU 和 I/O 设备的等待时间的负担,但是由于还需要在 CPU 和 I/O 模块之前进行大量的逐字传输,因此在大量数据传输中效率仍然很低。下面是中断的基本操作
- CPU 进行读取操作
- I/O 设备从外围设备获取数据,同时 CPU 执行其他操作
- I/O 设备中断通知 CPU
- CPU 请求数据
- I/O 模块传输数据
所以我们现在着手需要解决的就是 CPU 和 I/O 模块间数据传输的效率问题。
使用 DMA 的 I/O
DMA 的中文名称是直接内存访问,它意味着 CPU 授予 I/O 模块权限在不涉及 CPU 的情况下读取或写入内存。也就是 DMA 可以不需要 CPU 的参与。这个过程由称为 DMA 控制器(DMAC)的芯片管理。由于 DMA 设备可以直接在内存之间传输数据,而不是使用 CPU 作为中介,因此可以缓解总线上的拥塞。DMA 通过允许 CPU 执行任务,同时 DMA 系统通过系统和内存总线传输数据来提高系统并发性。
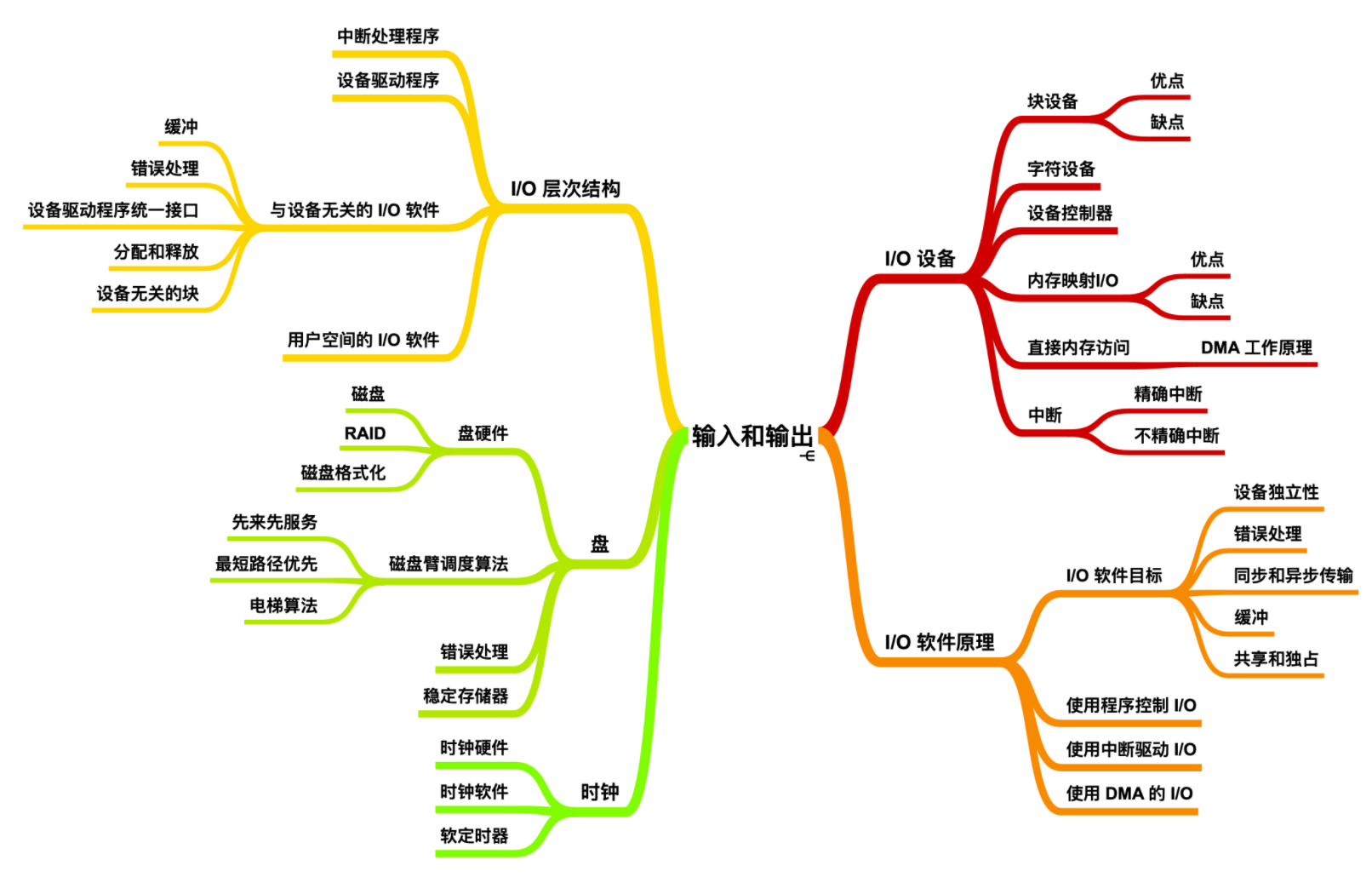
I/O 层次结构
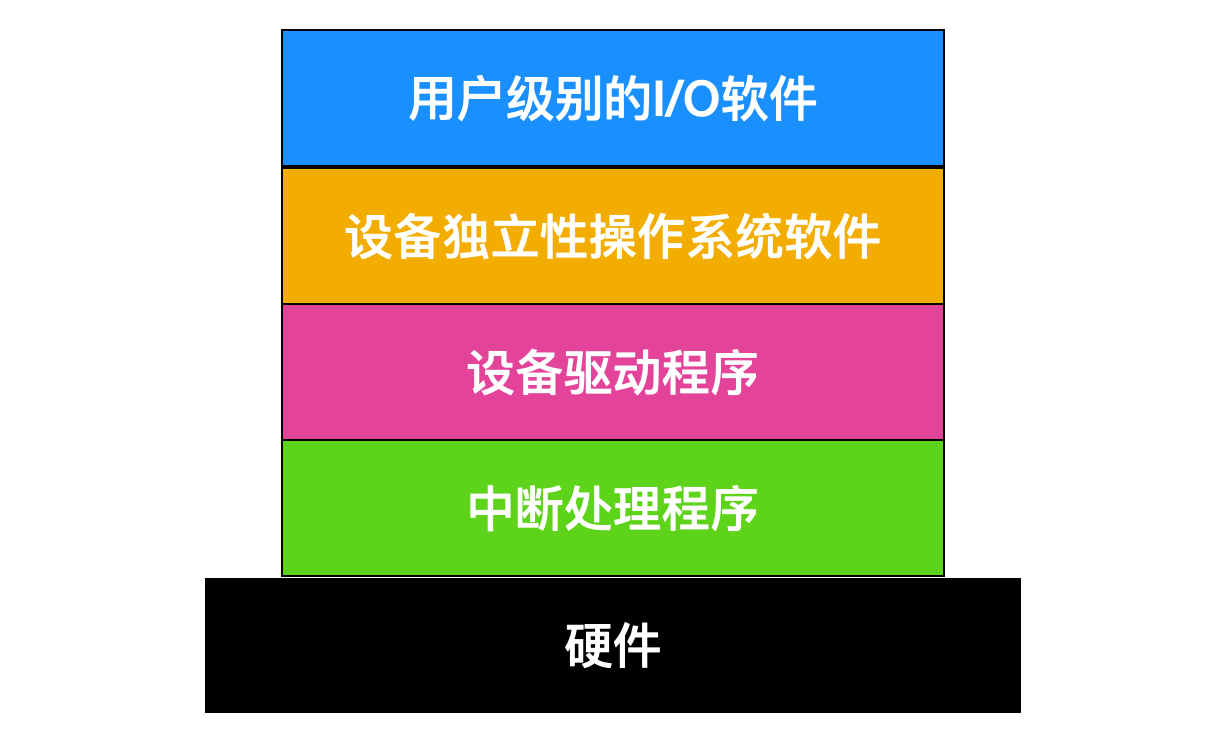
I/O 软件通常组织成四个层次,它们的大致结构如下图所示
每一层和其上下层都有明确的功能和接口。下面我们采用和计算机网络相反的套路,即自下而上的了解一下这些程序。
下面是另一幅图,这幅图显示了输入/输出软件系统所有层及其主要功能。

下面我们具体的来探讨一下上面的层次结构
中断处理程序
在计算机系统中,中断就像女人的脾气一样无时无刻都在产生,中断的出现往往是让人很不爽的。中断处理程序又被称为中断服务程序 或者是 ISR(Interrupt Service Routines),它是最靠近硬件的一层。中断处理程序由硬件中断、软件中断或者是软件异常启动产生的中断,用于实现设备驱动程序或受保护的操作模式(例如系统调用)之间的转换。
中断处理程序负责处理中断发生时的所有操作,操作完成后阻塞,然后启动中断驱动程序来解决阻塞。通常会有三种通知方式,依赖于不同的具体实现
- 信号量实现中:在信号量上使用
up进行通知; - 管程实现:对管程中的条件变量执行
signal操作 - 还有一些情况是发送一些消息
不管哪种方式都是为了让阻塞的中断处理程序恢复运行。
中断处理方案有很多种,下面是 《ARM System Developer’s Guide
Designing and Optimizing System Software》列出来的一些方案
非嵌套的中断处理程序按照顺序处理各个中断,非嵌套的中断处理程序也是最简单的中断处理嵌套的中断处理程序会处理多个中断而无需分配优先级可重入的中断处理程序可使用优先级处理多个中断简单优先级中断处理程序可处理简单的中断标准优先级中断处理程序比低优先级的中断处理程序在更短的时间能够处理优先级更高的中断高优先级中断处理程序在短时间能够处理优先级更高的任务,并直接进入特定的服务例程。优先级分组中断处理程序能够处理不同优先级的中断任务
下面是一些通用的中断处理程序的步骤,不同的操作系统实现细节不一样
- 保存所有没有被中断硬件保存的寄存器
- 为中断服务程序设置上下文环境,可能包括设置
TLB、MMU和页表,如果不太了解这三个概念,请参考另外一篇文章 - 为中断服务程序设置栈
- 对中断控制器作出响应,如果不存在集中的中断控制器,则继续响应中断
- 把寄存器从保存它的地方拷贝到进程表中
- 运行中断服务程序,它会从发出中断的设备控制器的寄存器中提取信息
- 操作系统会选择一个合适的进程来运行。如果中断造成了一些优先级更高的进程变为就绪态,则选择运行这些优先级高的进程
- 为进程设置 MMU 上下文,可能也会需要 TLB,根据实际情况决定
- 加载进程的寄存器,包括 PSW 寄存器
- 开始运行新的进程
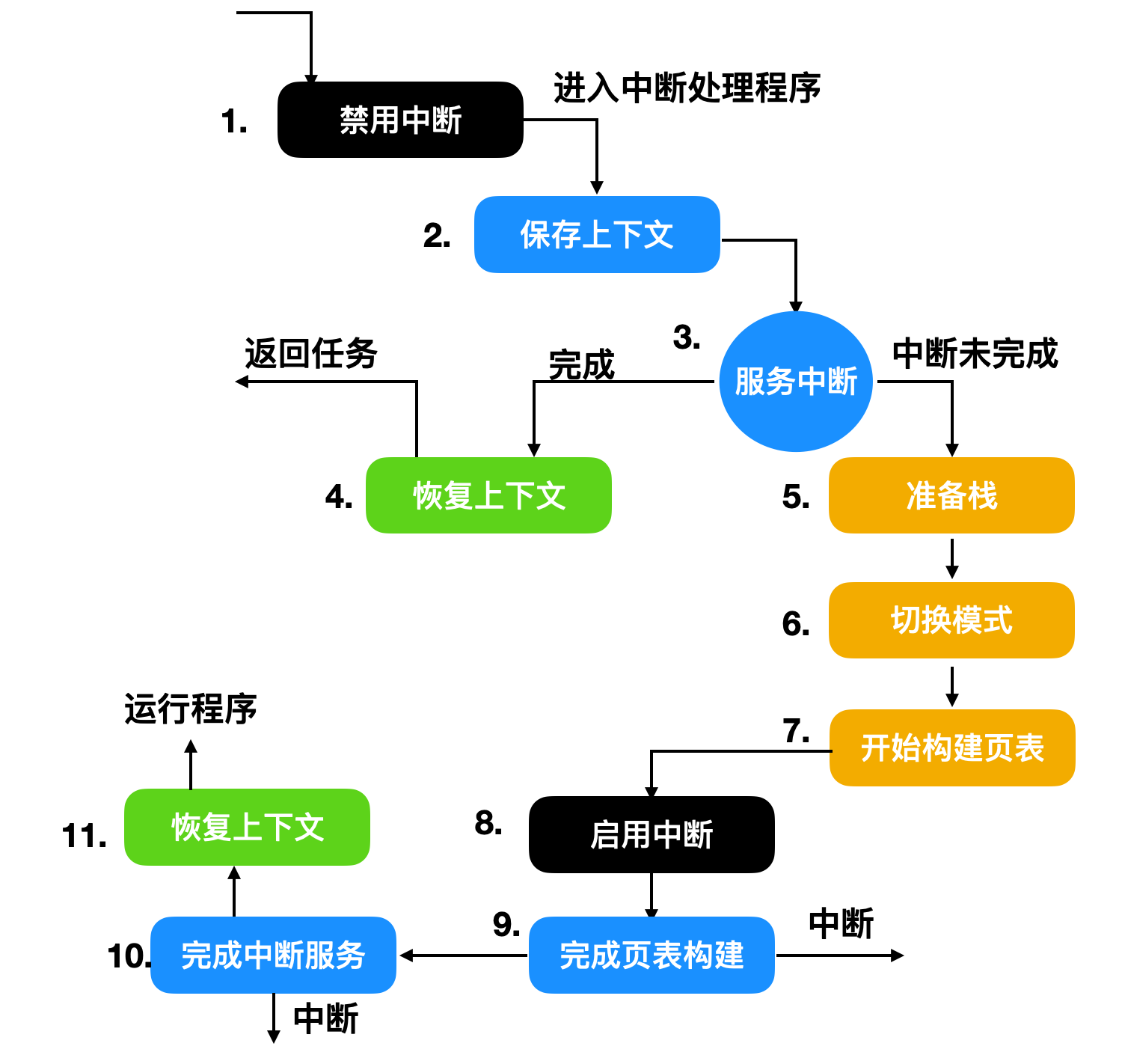
上面我们罗列了一些大致的中断步骤,不同性质的操作系统和中断处理程序能够处理的中断步骤和细节也不尽相同,下面是一个嵌套中断的具体运行步骤
设备驱动程序
在上面的文章中我们知道了设备控制器所做的工作。我们知道每个控制器其内部都会有寄存器用来和设备进行沟通,发送指令,读取设备的状态等。
因此,每个连接到计算机的 I/O 设备都需要有某些特定设备的代码对其进行控制,例如鼠标控制器需要从鼠标接受指令,告诉下一步应该移动到哪里,键盘控制器需要知道哪个按键被按下等。这些提供 I/O 设备到设备控制器转换的过程的代码称为 设备驱动程序(Device driver)。
为了能够访问设备的硬件,实际上也就意味着,设备驱动程序通常是操作系统内核的一部分,至少现在的体系结构是这样的。但是也可以构造用户空间的设备驱动程序,通过系统调用来完成读写操作。这样就避免了一个问题,有问题的驱动程序会干扰内核,从而造成崩溃。所以,在用户控件实现设备驱动程序是构造系统稳定性一个非常有用的措施。MINIX 3 就是这么做的。下面是 MINI 3 的调用过程
然而,大多数桌面操作系统要求驱动程序必须运行在内核中。
操作系统通常会将驱动程序归为 字符设备 和 块设备,我们上面也介绍过了

在 UNIX 系统中,操作系统是一个二进制程序,包含需要编译到其内部的所有驱动程序,如果你要对 UNIX 添加一个新设备,需要重新编译内核,将新的驱动程序装到二进制程序中。
然而随着大多数个人计算机的出现,由于 I/O 设备的广泛应用,上面这种静态编译的方式不再有效,因此,从 MS-DOS 开始,操作系统转向驱动程序在执行期间动态的装载到系统中。
设备驱动程序具有很多功能,比如接受读写请求,对设备进行初始化、管理电源和日志、对输入参数进行有效性检查等。
设备驱动程序接受到读写请求后,会检查当前设备是否在使用,如果设备在使用,请求被排入队列中,等待后续的处理。如果此时设备是空闲的,驱动程序会检查硬件以了解请求是否能够被处理。在传输开始前,会启动设备或者马达。等待设备就绪完成,再进行实际的控制。控制设备就是对设备发出指令。
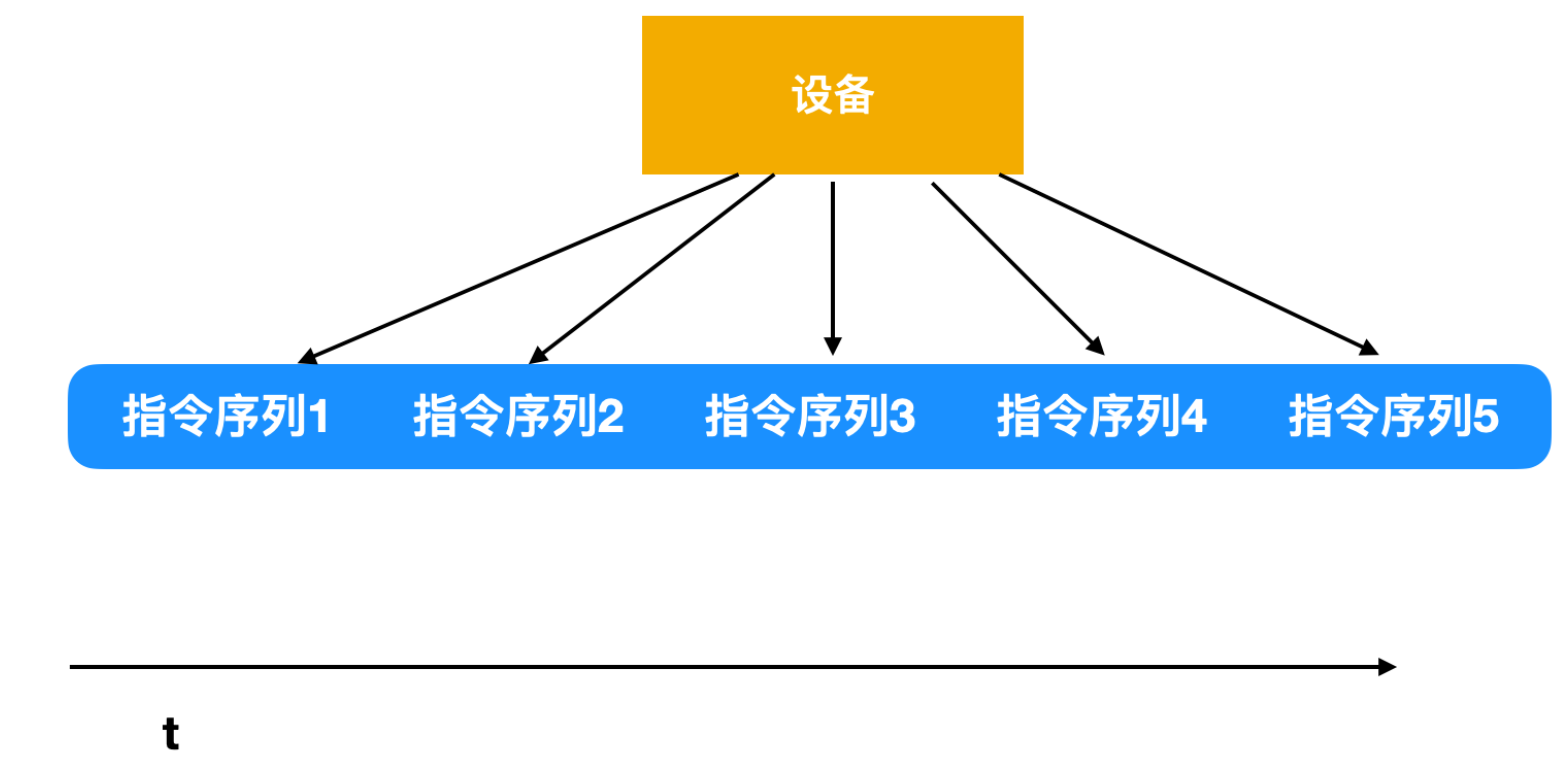
发出命令后,设备控制器便开始将它们写入控制器的设备寄存器。在将每个命令写入控制器后,会检查控制器是否接受了这条命令并准备接受下一个命令。一般控制设备会发出一系列的指令,这称为指令序列,设备控制器会依次检查每个命令是否被接受,下一条指令是否能够被接收,直到所有的序列发出为止。
发出指令后,一般会有两种可能出现的情况。在大多数情况下,设备驱动程序会进行等待直到控制器完成它的事情。这里需要了解一下设备控制器的概念
设备控制器的主要主责是控制一个或多个 I/O 设备,以实现 I/O 设备和计算机之间的数据交换。
设备控制器接收从 CPU 发送过来的指令,继而达到控制硬件的目的
设备控制器是一个可编址的设备,当它仅控制一个设备时,它只有一个唯一的设备地址;如果设备控制器控制多个可连接设备时,则应含有多个设备地址,并使每一个设备地址对应一个设备。
设备控制器主要分为两种:字符设备和块设备
设备控制器的主要功能有下面这些
接收和识别命令:设备控制器可以接受来自 CPU 的指令,并进行识别。设备控制器内部也会有寄存器,用来存放指令和参数
进行数据交换:CPU、控制器和设备之间会进行数据的交换,CPU 通过总线把指令发送给控制器,或从控制器中并行地读出数据;控制器将数据写入指定设备。
地址识别:每个硬件设备都有自己的地址,设备控制器能够识别这些不同的地址,来达到控制硬件的目的,此外,为使 CPU 能向寄存器中写入或者读取数据,这些寄存器都应具有唯一的地址。
差错检测:设备控制器还具有对设备传递过来的数据进行检测的功能。
在这种情况下,设备控制器会阻塞,直到中断来解除阻塞状态。还有一种情况是操作是可以无延迟的完成,所以驱动程序不需要阻塞。在第一种情况下,操作系统可能被中断唤醒;第二种情况下操作系统不会被休眠。
设备驱动程序必须是可重入的,因为设备驱动程序会阻塞和唤醒然后再次阻塞。驱动程序不允许进行系统调用,但是它们通常需要与内核的其余部分进行交互。
与设备无关的 I/O 软件
I/O 软件有两种,一种是我们上面介绍过的基于特定设备的,还有一种是设备无关性的,设备无关性也就是不需要特定的设备。设备驱动程序与设备无关的软件之间的界限取决于具体的系统。下面显示的功能由设备无关的软件实现

与设备无关的软件的基本功能是对所有设备执行公共的 I/O 功能,并且向用户层软件提供一个统一的接口。
缓冲
无论是对于块设备还是字符设备来说,缓冲都是一个非常重要的考量标准。下面是从 ADSL(调制解调器) 读取数据的过程,调制解调器是我们用来联网的设备。
用户程序调用 read 系统调用阻塞用户进程,等待字符的到来,这是对到来的字符进行处理的一种方式。每一个到来的字符都会造成中断。中断服务程序会给用户进程提供字符,并解除阻塞。将字符提供给用户程序后,进程会去读取其他字符并继续阻塞,这种模型如下
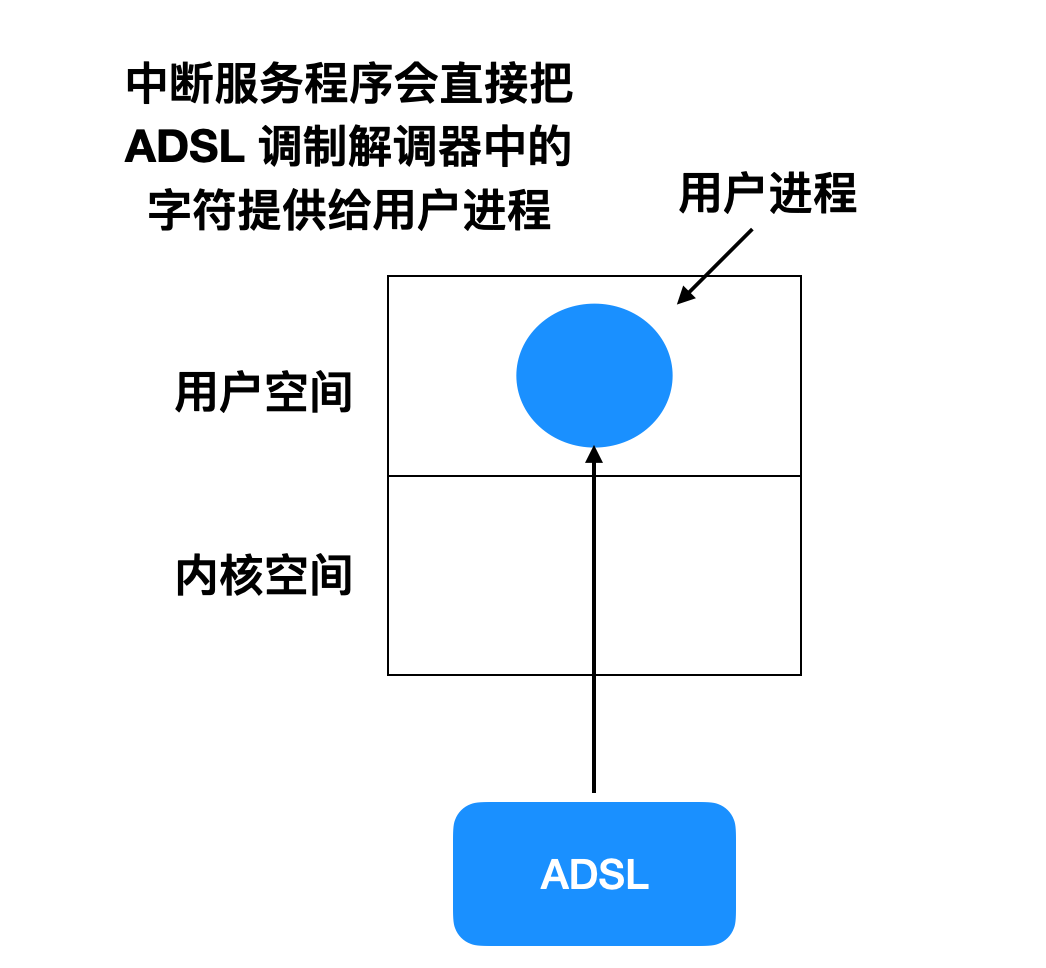
这一种方案是没有缓冲区的存在,因为用户进程如果读不到数据会阻塞,直到读到数据为止,这种情况效率比较低,而且阻塞式的方式,会直接阻止用户进程做其他事情,这对用户来说是不能接受的。还有一种情况就是每次用户进程都会重启,对于每个字符的到来都会重启用户进程,这种效率会严重降低,所以无缓冲区的软件不是一个很好的设计。
作为一个改良点,我们可以尝试在用户空间中使用一个能读取 n 个字节缓冲区来读取 n 个字符。这样的话,中断服务程序会把字符放到缓冲区中直到缓冲区变满为止,然后再去唤醒用户进程。这种方案要比上面的方案改良很多。
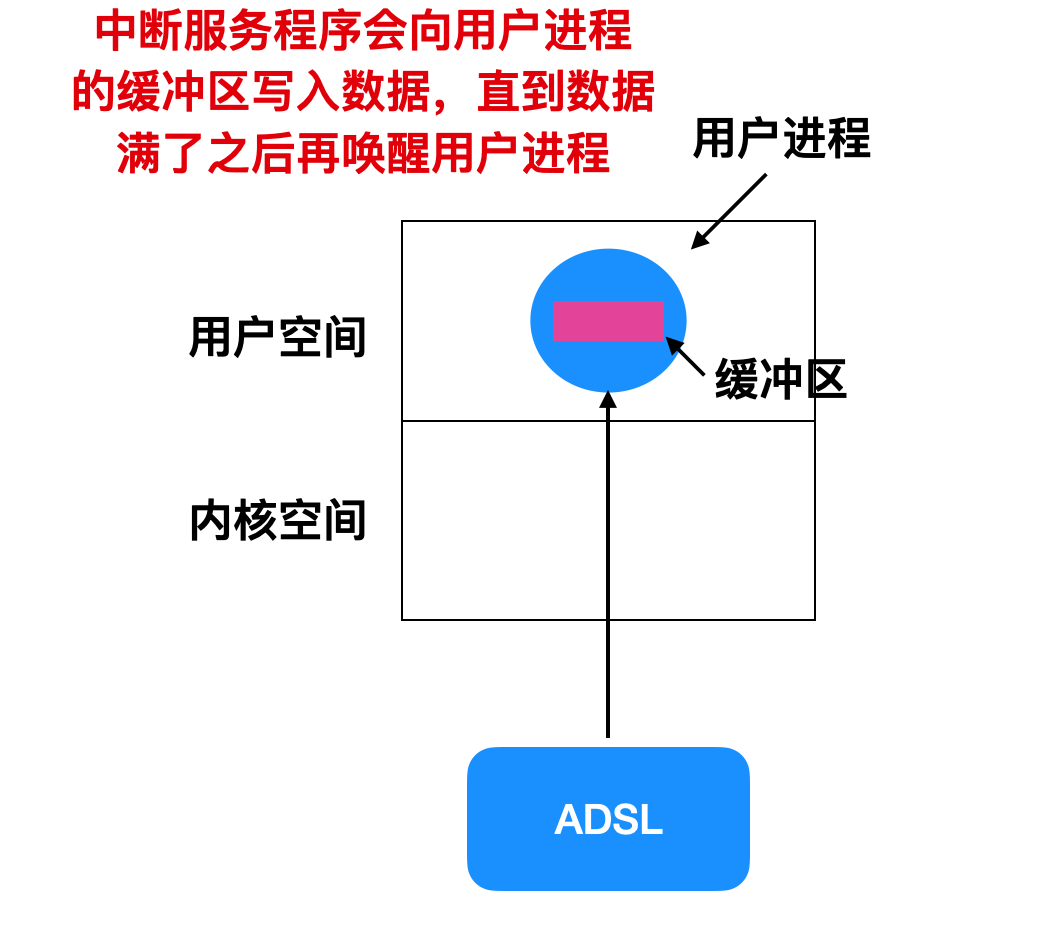
但是这种方案也存在问题,当字符到来时,如果缓冲区被调出内存会出现什么问题?解决方案是把缓冲区锁定在内存中,但是这种方案也会出现问题,如果少量的缓冲区被锁定还好,如果大量的缓冲区被锁定在内存中,那么可以换进换出的页面就会收缩,造成系统性能的下降。
一种解决方案是在内核中内部创建一块缓冲区,让中断服务程序将字符放在内核内部的缓冲区中。
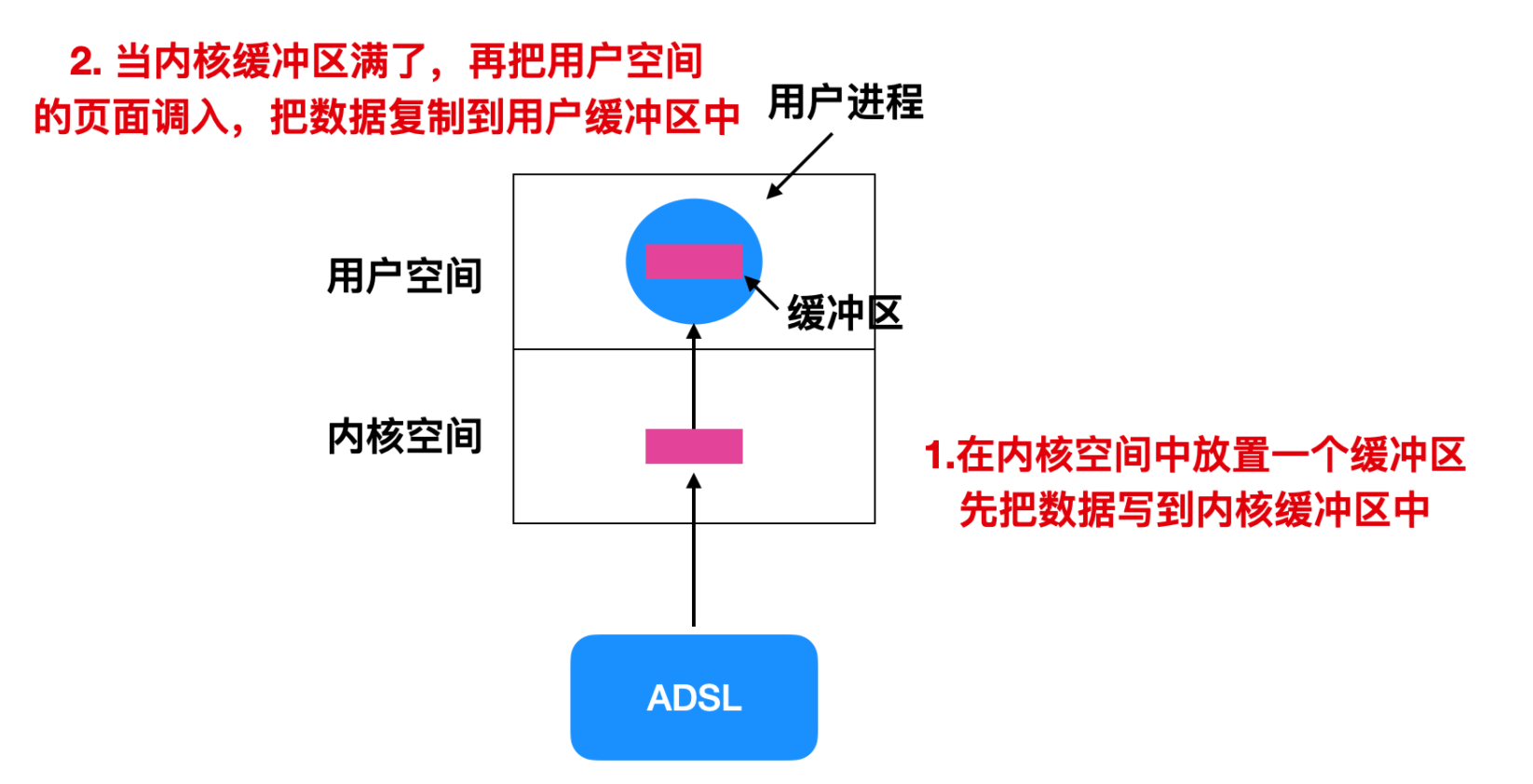
当内核中的缓冲区要满的时候,会将用户空间中的页面调入内存,然后将内核空间的缓冲区复制到用户空间的缓冲区中,这种方案也面临一个问题就是假如用户空间的页面被换入内存,此时内核空间的缓冲区已满,这时候仍有新的字符到来,这个时候会怎么办?因为缓冲区满了,没有空间来存储新的字符了。
一种非常简单的方式就是再设置一个缓冲区就行了,在第一个缓冲区填满后,在缓冲区清空前,使用第二个缓冲区,这种解决方式如下

当第二个缓冲区也满了的时候,它也会把数据复制到用户空间中,然后第一个缓冲区用于接受新的字符。这种具有两个缓冲区的设计被称为 双缓冲(double buffering)。
还有一种缓冲形式是 循环缓冲(circular buffer)。它由一个内存区域和两个指针组成。一个指针指向下一个空闲字,新的数据可以放在此处。另外一个指针指向缓冲区中尚未删除数据的第一个字。在许多情况下,硬件会在添加新的数据时,移动第一个指针;而操作系统会在删除和处理无用数据时会移动第二个指针。两个指针到达顶部时就回到底部重新开始。
缓冲区对输出来说也很重要。对输出的描述和输入相似
缓冲技术应用广泛,但它也有缺点。如果数据被缓冲次数太多,会影响性能。考虑例如如下这种情况,
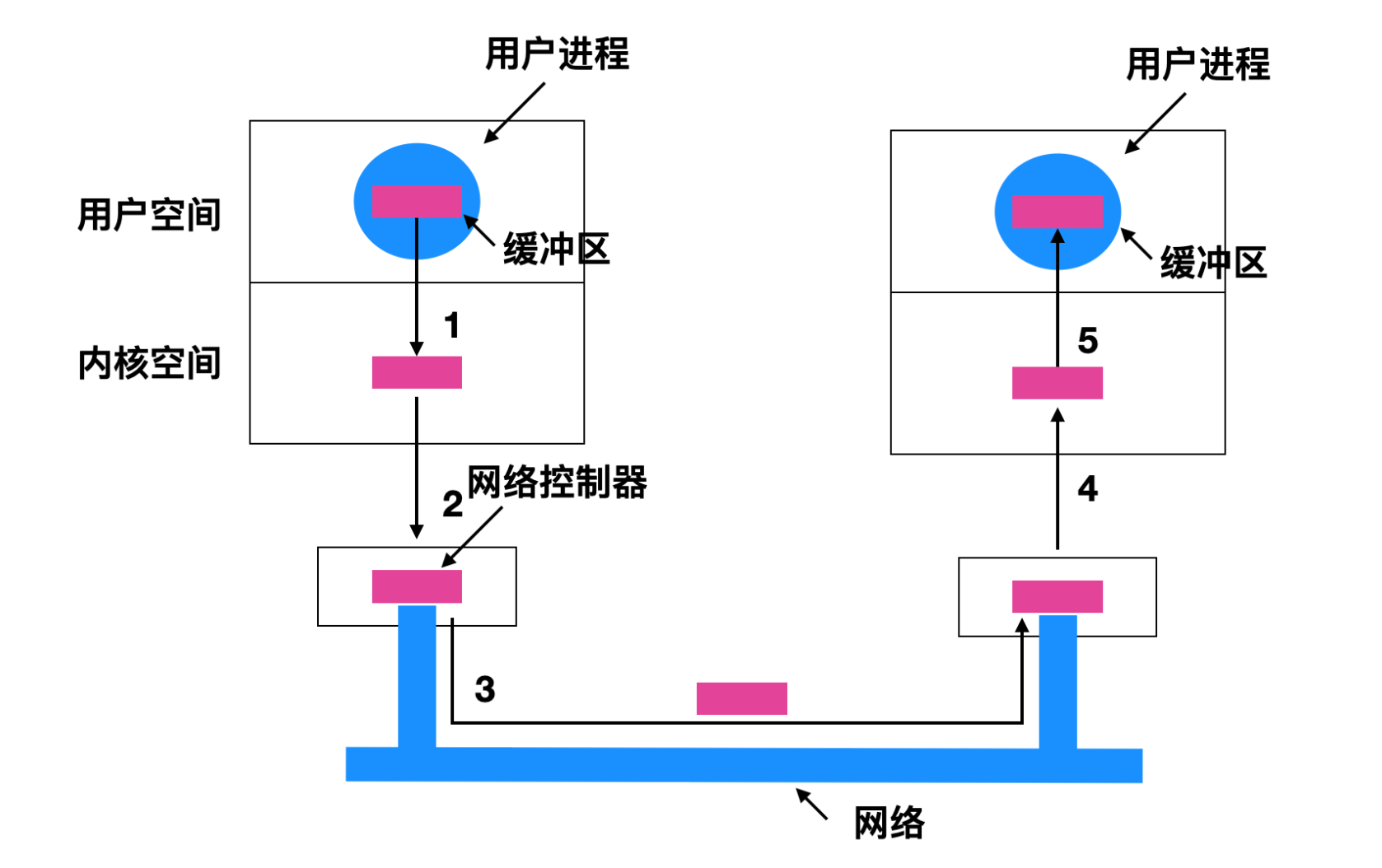
数据经过用户进程 -> 内核空间 -> 网络控制器,这里的网络控制器应该就相当于是 socket 缓冲区,然后发送到网络上,再到接收方的网络控制器 -> 接收方的内核缓冲 -> 接收方的用户缓冲,一条数据包被缓存了太多次,很容易降低性能。
错误处理
在 I/O 中,出错是一种再正常不过的情况了。当出错发生时,操作系统必须尽可能处理这些错误。有一些错误是只有特定的设备才能处理,有一些是由框架进行处理,这些错误和特定的设备无关。
I/O 错误的一类是程序员编程错误,比如还没有打开文件前就读流,或者不关闭流导致内存溢出等等。这类问题由程序员处理;另外一类是实际的 I/O 错误,例如向一个磁盘坏块写入数据,无论怎么写都写入不了。这类问题由驱动程序处理,驱动程序处理不了交给硬件处理,这个我们上面也说过。
设备驱动程序统一接口
我们在操作系统概述中说到,操作系统一个非常重要的功能就是屏蔽了硬件和软件的差异性,为硬件和软件提供了统一的标准,这个标准还体现在为设备驱动程序提供统一的接口,因为不同的硬件和厂商编写的设备驱动程序不同,所以如果为每个驱动程序都单独提供接口的话,这样没法搞,所以必须统一。
分配和释放
一些设备例如打印机,它只能由一个进程来使用,这就需要操作系统根据实际情况判断是否能够对设备的请求进行检查,判断是否能够接受其他请求,一种比较简单直接的方式是在特殊文件上执行 open操作。如果设备不可用,那么直接 open 会导致失败。还有一种方式是不直接导致失败,而是让其阻塞,等到另外一个进程释放资源后,在进行 open 打开操作。这种方式就把选择权交给了用户,由用户判断是否应该等待。
注意:阻塞的实现有多种方式,有阻塞队列等
设备无关的块
不同的磁盘会具有不同的扇区大小,但是软件不会关心扇区大小,只管存储就是了。一些字符设备可以一次一个字节的交付数据,而其他的设备则以较大的单位交付数据,这些差异也可以隐藏起来。
用户空间的 I/O 软件
虽然大部分 I/O 软件都在内核结构中,但是还有一些在用户空间实现的 I/O 软件,凡事没有绝对。一些 I/O 软件和库过程在用户空间存在,然后以提供系统调用的方式实现。
盘
盘可以说是硬件里面比较简单的构造了,同时也是最重要的。下面我们从盘谈起,聊聊它的物理构造
盘硬件
盘会有很多种类型。其中最简单的构造就是磁盘(magnetic hard disks), 也被称为 hard disk,HDD等。磁盘通常与安装在磁臂上的磁头配对,磁头可将数据读取或者将数据写入磁盘,因此磁盘的读写速度都同样快。在磁盘中,数据是随机访问的,这也就说明可以通过任意的顺序来存储和检索单个数据块,所以你可以在任意位置放置磁盘来让磁头读取,磁盘是一种非易失性的设备,即使断电也能永久保留。
在计算机发展早期一般是用光盘来存储数据的,然而随着固态硬盘的流行,固态硬盘不包含运动部件的特点,成为现在计算机的首选存储方式。
磁盘
为了组织和检索数据,会将磁盘组织成特定的结构,这些特定的结构就是磁道、扇区和柱面

每一个磁盘都是由无数个同心圆组成,这些同心圆就好像树的年轮一样
部分树的年轮照片都要付费下载了,不敢直接白嫖,阔怕阔怕。
磁盘被组织成柱面形式,每个盘用轴相连,每一个柱面包含若干磁道,每个磁道由若干扇区组成。软盘上大约每个磁道有 8 - 32 个扇区,硬盘上每条磁道上扇区的数量可达几百个,磁头大约是 1 - 16 个。
对于磁盘驱动程序来说,一个非常重要的特性就是控制器是否能够同时控制两个或者多个驱动器进行磁道寻址,这就是重叠寻道(overlapped seek)。对于控制器来说,它能够控制一个磁盘驱动程序完成寻道操作,同时让其他驱动程序等待寻道结束。控制器也可以在一个驱动程序上进行读写草哦做,与此同时让另外的驱动器进行寻道操作,但是软盘控制器不能在两个驱动器上进行读写操作。
RAID
RAID 称为 磁盘冗余阵列,简称 磁盘阵列。利用虚拟化技术把多个硬盘结合在一起,成为一个或多个磁盘阵列组,目的是提升性能或数据冗余。
RAID 有不同的级别
- RAID 0 - 无容错的条带化磁盘阵列
- RAID 1 - 镜像和双工
- RAID 2 - 内存式纠错码
- RAID 3 - 比特交错奇偶校验
- RAID 4 - 块交错奇偶校验
- RAID 5 - 块交错分布式奇偶校验
- RAID 6 - P + Q冗余
磁盘格式化
磁盘由一堆铝的、合金或玻璃的盘片组成,磁盘刚被创建出来后,没有任何信息。磁盘在使用前必须经过低级格式化(low-levvel format),下面是一个扇区的格式

前导码相当于是标示扇区的开始位置,通常以位模式开始,前导码还包括柱面号、扇区号等一些其他信息。紧随前导码后面的是数据区,数据部分的大小由低级格式化程序来确定。大部分磁盘使用 512 字节的扇区。数据区后面是 ECC,ECC 的全称是 error correction code ,数据纠错码,它与普通的错误检测不同,ECC 还可以用于恢复读错误。ECC 阶段的大小由不同的磁盘制造商实现。ECC 大小的设计标准取决于设计者愿意牺牲多少磁盘空间来提高可靠性,以及程序可以处理的 ECC 的复杂程度。通常情况下 ECC 是 16 位,除此之外,硬盘一般具有一定数量的备用扇区,用于替换制造缺陷的扇区。
低级格式化后的每个 0 扇区的位置都和前一个磁道存在偏移,如下图所示
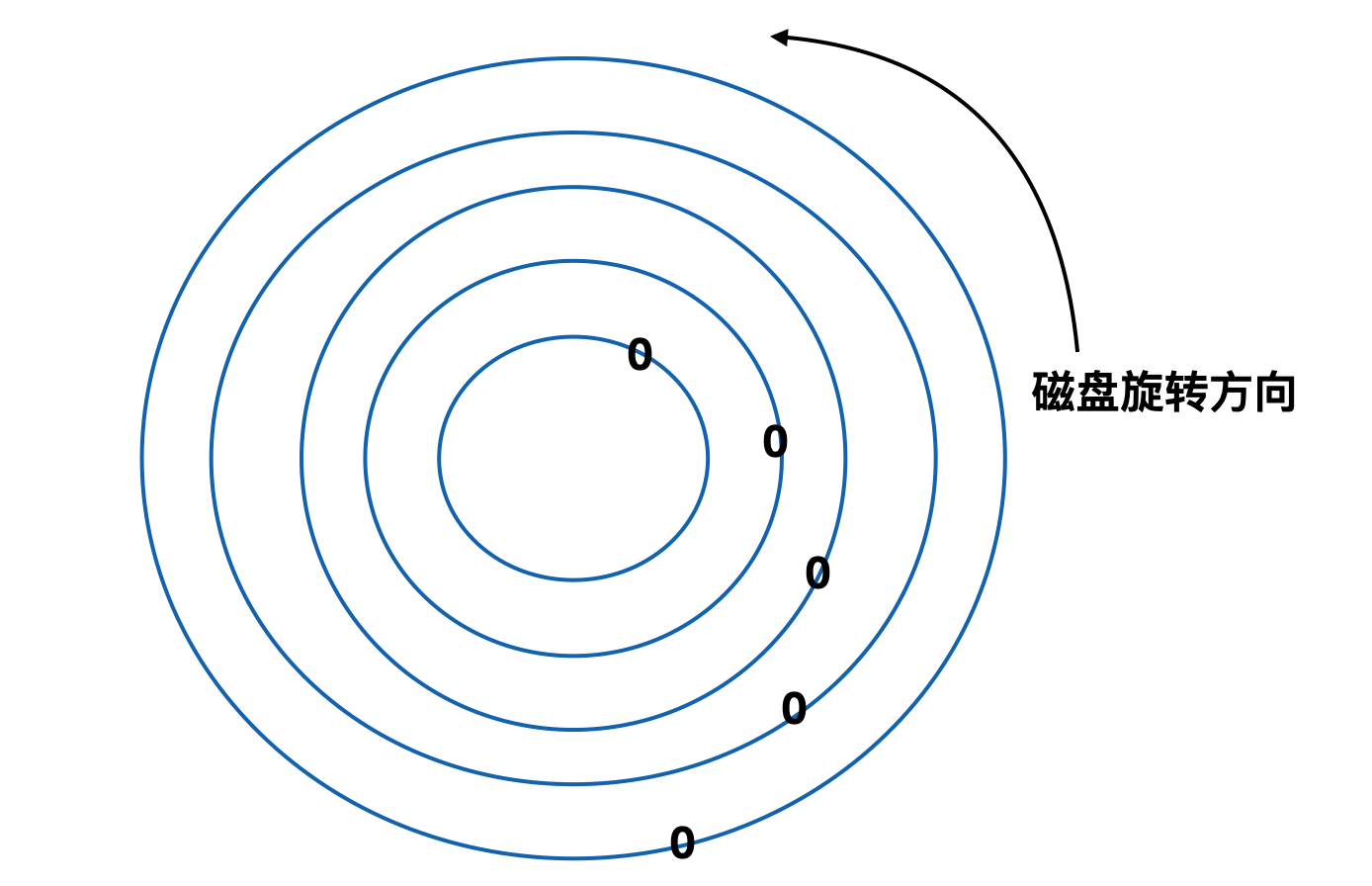
这种方式又被称为 柱面斜进(cylinder skew),之所以采用这种方式是为了提高程序的运行性能。可以这样想,磁盘在转动的过程中会经由磁头来读取扇区信息,在读取内侧一圈扇区数据后,磁头会进行向外侧磁道的寻址操作,寻址操作的同时磁盘在继续转动,如果不采用这种方式,可能刚好磁头寻址到外侧,0 号扇区已经转过了磁头,所以需要旋转一圈才能等到它继续读取,通过柱面斜进的方式可以消除这一问题。
柱面斜进量取决于驱动器的几何规格。柱面斜进量就是两个相邻同心圆 0 号扇区的差异量。如下图所示
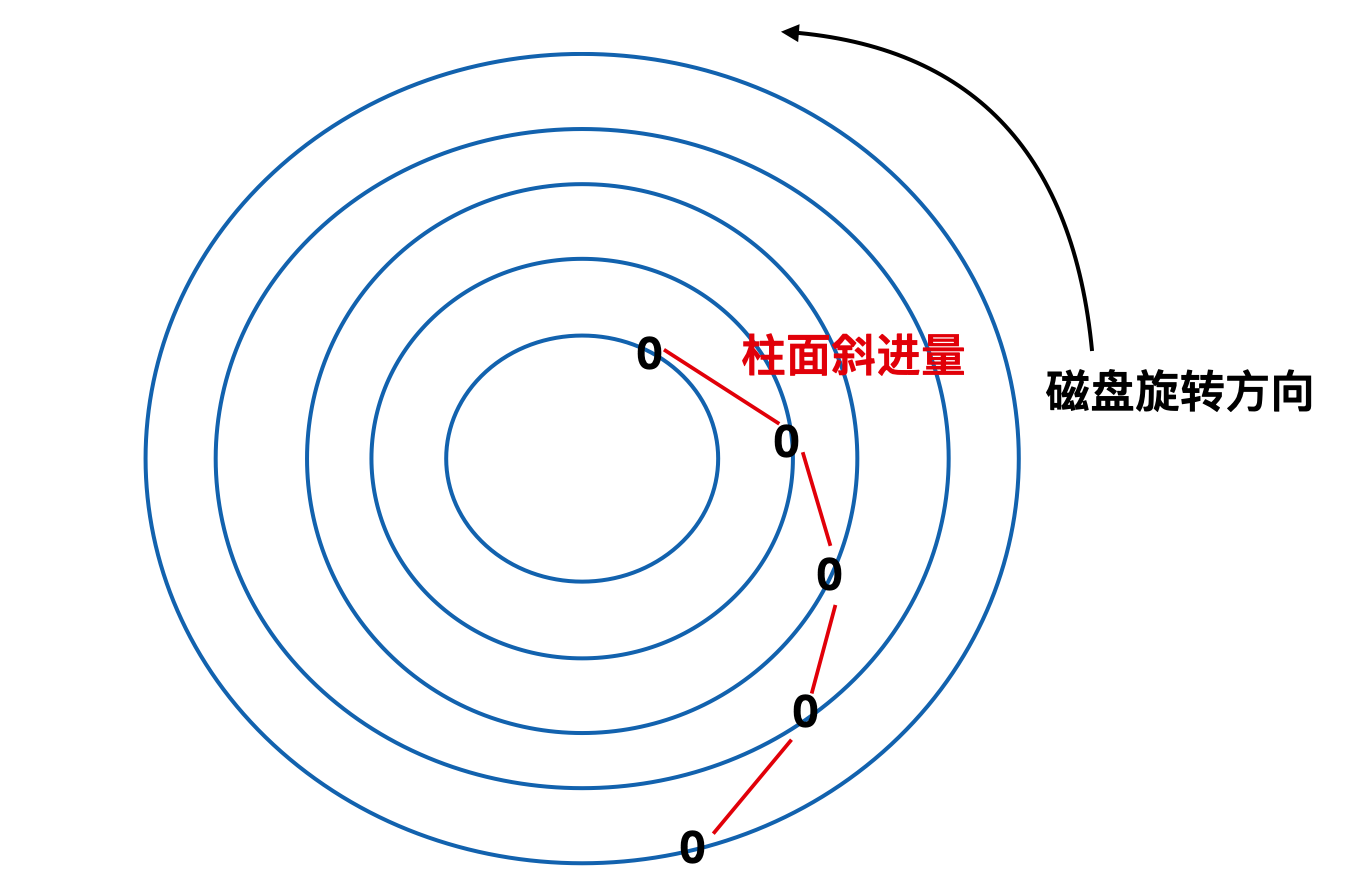
这里需要注意一点,不只有柱面存在斜进,磁头也会存在斜进(head skew),但是磁头斜进比较小。
磁盘格式化会减少磁盘容量,减少的磁盘容量都会由前导码、扇区间间隙和 ECC 的大小以及保留的备用扇区数量。
在磁盘使用前,还需要经过最后一道工序,那就是对每个分区分别执行一次高级格式化(high-level format),这一操作要设置一个引导块、空闲存储管理(采用位图或者是空闲列表)、根目录和空文件系统。这一步操作会把码放在分区表项中,告诉分区使用的是哪种文件系统,因为许多操作系统支持多个兼容的文件系统。在这一步之后,系统就可以进行引导过程。
当电源通电后,BIOS 首先运行,它会读取主引导记录并跳转到主引导记录中。然后引导程序会检查以了解哪个分区是处于活动的。然后,它从该分区读取启动扇区(boot sector)并运行它。启动扇区包含一个小程序来加载一个更大一点的引导器来搜索文件系统以找到系统内核(system kernel),然后程序被转载进入内存并执行。
这里说下什么是引导扇区:引导扇区是磁盘或者存储设备的保留扇区,其中包含用于完成计算机或磁盘引导过程所必要的数据或者代码。
引导扇区存储引导记录数据,这些数据用于在计算机启动时提供指令。有两种不同类型的引导扇区
- Master boot record 称为主引导扇区
- Volume boot record 卷启动记录
对于分区磁盘,引导扇区由主引导记录组成;
非分区磁盘由卷启动记录组成。
磁盘臂调度算法
下面我们来探讨一下关于影响磁盘读写的算法,一般情况下,影响磁盘快读写的时间由下面几个因素决定
- 寻道时间 - 寻道时间指的就是将磁盘臂移动到需要读取磁盘块上的时间
- 旋转延迟 - 等待合适的扇区旋转到磁头下所需的时间
- 实际数据的读取或者写入时间
这三种时间参数也是磁盘寻道的过程。一般情况下,寻道时间对总时间的影响最大,所以,有效的降低寻道时间能够提高磁盘的读取速度。
如果磁盘驱动程序每次接收一个请求并按照接收顺序完成请求,这种处理方式也就是 先来先服务(First-Come, First-served, FCFS) ,这种方式很难优化寻道时间。因为每次都会按照顺序处理,不管顺序如何,有可能这次读完后需要等待一个磁盘旋转一周才能继续读取,而其他柱面能够马上进行读取,这种情况下每次请求也会排队。
通常情况下,磁盘在进行寻道时,其他进程会产生其他的磁盘请求。磁盘驱动程序会维护一张表,表中会记录着柱面号当作索引,每个柱面未完成的请求会形成链表,链表头存放在表的相应表项中。
一种对先来先服务的算法改良的方案是使用 最短路径优先(SSF) 算法,下面描述了这个算法。
假如我们在对磁道 6 号进行寻址时,同时发生了对 11 , 2 , 4, 14, 8, 15, 3 的请求,如果采用先来先服务的原则,如下图所示
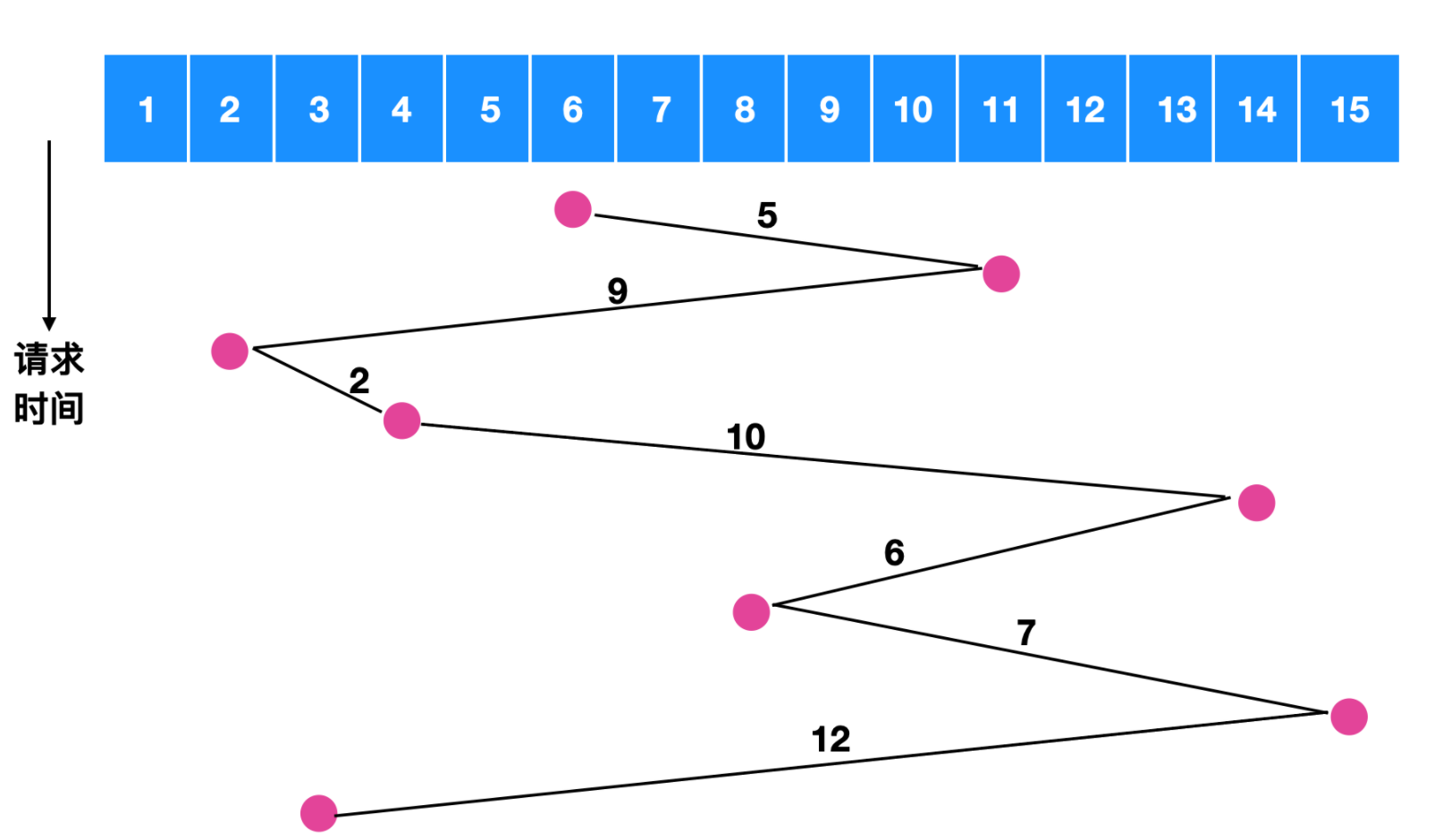
我们可以计算一下磁盘臂所跨越的磁盘数量为 5 + 9 + 2 + 10 + 6 + 7 + 12 = 51,相当于是跨越了 51 次盘面,如果使用最短路径优先,我们来计算一下跨越的盘面

跨越的磁盘数量为 4 + 1 + 1 + 4 + 3 + 3 + 1 = 17 ,相比 51 足足省了两倍的时间。
但是,最短路径优先的算法也不是完美无缺的,这种算法照样存在问题,那就是优先级 问题,
这里有一个原型可以参考就是我们日常生活中的电梯,电梯使用一种电梯算法(elevator algorithm) 来进行调度,从而满足协调效率和公平性这两个相互冲突的目标。电梯一般会保持向一个方向移动,直到在那个方向上没有请求为止,然后改变方向。
电梯算法需要维护一个二进制位,也就是当前的方向位:UP(向上)或者是 DOWN(向下)。当一个请求处理完成后,磁盘或电梯的驱动程序会检查该位,如果此位是 UP 位,磁盘臂或者电梯仓移到下一个更高跌未完成的请求。如果高位没有未完成的请求,则取相反方向。当方向位是 DOWN 时,同时存在一个低位的请求,磁盘臂会转向该点。如果不存在的话,那么它只是停止并等待。
我们举个例子来描述一下电梯算法,比如各个柱面得到服务的顺序是 4,7,10,14,9,6,3,1 ,那么它的流程图如下
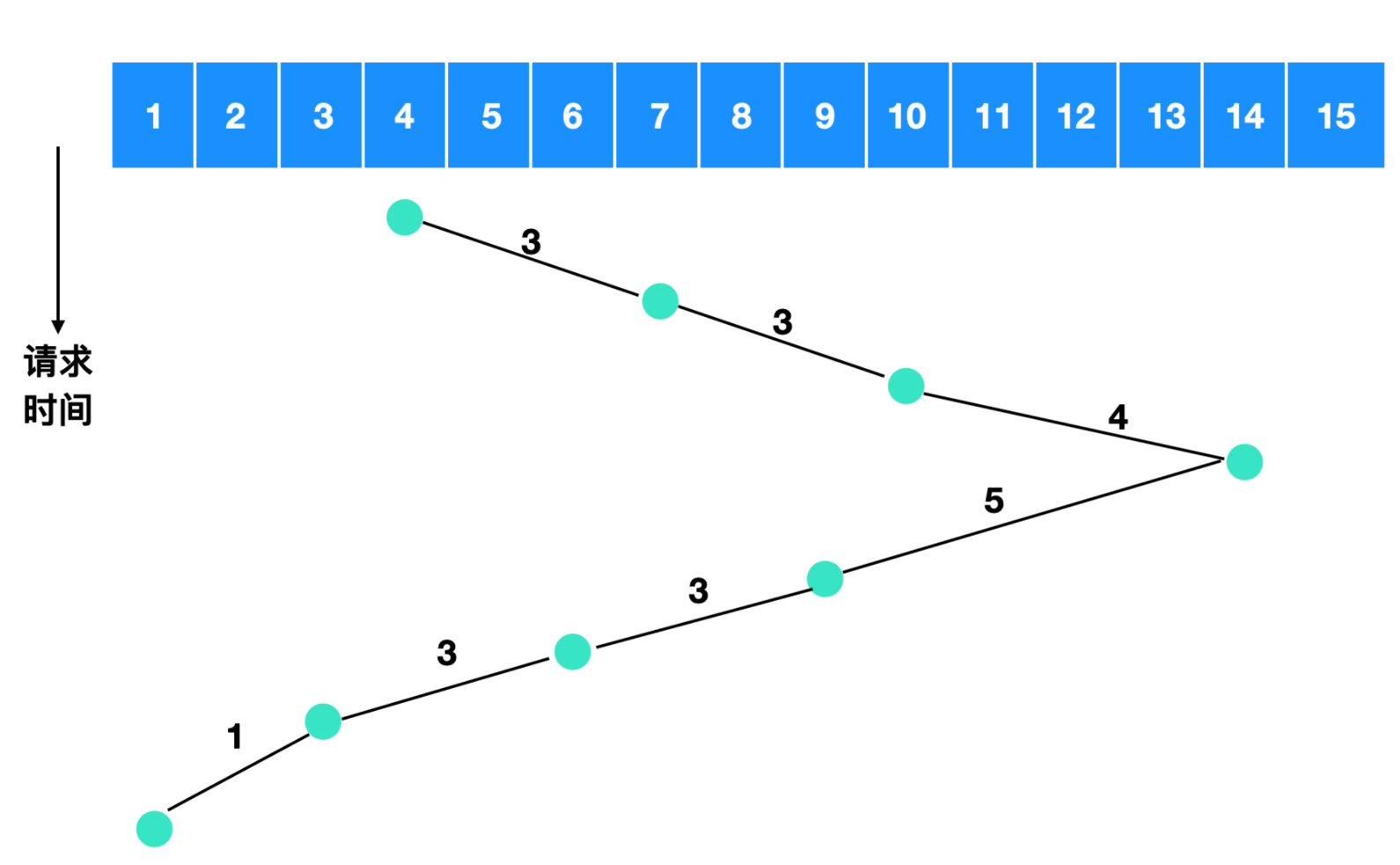
所以电梯算法需要跨越的盘面数量是 3 + 3 + 4 + 5 + 3 + 3 + 1 = 22
电梯算法通常情况下不如 SSF 算法。
一些磁盘控制器为软件提供了一种检查磁头下方当前扇区号的方法,使用这样的控制器,能够进行另一种优化。如果对一个相同的柱面有两个或者多个请求正等待处理,驱动程序可以发出请求读写下一次要通过磁头的扇区。
这里需要注意一点,当一个柱面有多条磁道时,相继的请求可能针对不同的磁道,这种选择没有代价,因为选择磁头不需要移动磁盘臂也没有旋转延迟。
对于磁盘来说,最影响性能的就是寻道时间和旋转延迟,所以一次只读取一个或两个扇区的效率是非常低的。出于这个原因,许多磁盘控制器总是读出多个扇区并进行高速缓存,即使只请求一个扇区时也是这样。一般情况下读取一个扇区的同时会读取该扇区所在的磁道或者是所有剩余的扇区被读出,读出扇区的数量取决于控制器的高速缓存中有多少可用的空间。
磁盘控制器的高速缓存和操作系统的高速缓存有一些不同,磁盘控制器的高速缓存用于缓存没有实际被请求的块,而操作系统维护的高速缓存由显示地读出的块组成,并且操作系统会认为这些块在近期仍然会频繁使用。
当同一个控制器上有多个驱动器时,操作系统应该为每个驱动器都单独的维护一个未完成的请求表。一旦有某个驱动器闲置时,就应该发出一个寻道请求来将磁盘臂移到下一个被请求的柱面。如果下一个寻道请求到来时恰好没有磁盘臂处于正确的位置,那么驱动程序会在刚刚完成传输的驱动器上发出一个新的寻道命令并等待,等待下一次中断到来时检查哪个驱动器处于闲置状态。
错误处理
磁盘在制造的过程中可能会有瑕疵,如果瑕疵比较小,比如只有几位,那么使用坏扇区并且每次只是让 ECC 纠正错误是可行的,如果瑕疵较大,那么错误就不可能被掩盖。
一般坏块有两种处理办法,一种是在控制器中进行处理;一种是在操作系统层面进行处理。
这两种方法经常替换使用,比如一个具有 30 个数据扇区和两个备用扇区的磁盘,其中扇区 4 是有瑕疵的。

控制器能做的事情就是将备用扇区之一重新映射。

还有一种处理方式是将所有的扇区都向上移动一个扇区
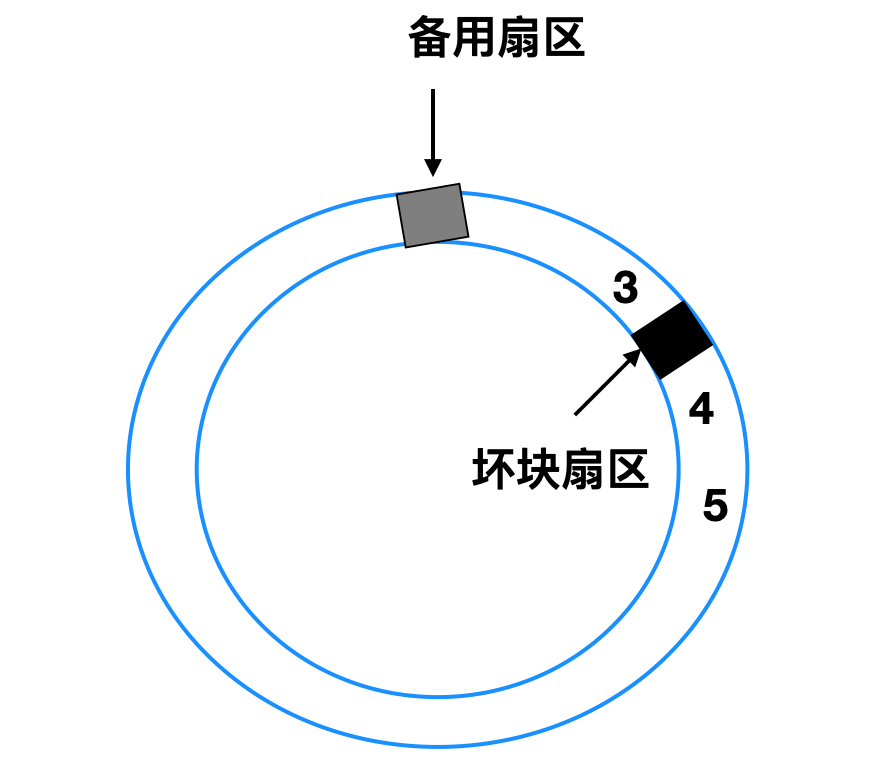
上面这这两种情况下控制器都必须知道哪个扇区,可以通过内部的表来跟踪这一信息,或者通过重写前导码来给出重新映射的扇区号。如果是重写前导码,那么涉及移动的方式必须重写后面所有的前导码,但是最终会提供良好的性能。
稳定存储器
磁盘经常会出现错误,导致好的扇区会变成坏扇区,驱动程序也有可能挂掉。RAID 可以对扇区出错或者是驱动器崩溃提出保护,然而 RAID 却不能对坏数据中的写错误提供保护,也不能对写操作期间的崩溃提供保护,这样就会破坏原始数据。
我们期望磁盘能够准确无误的工作,但是事实情况是不可能的,但是我们能够知道的是,一个磁盘子系统具有如下特性:当一个写命令发给它时,磁盘要么正确地写数据,要么什么也不做,让现有的数据完整无误的保留。这样的系统称为 稳定存储器(stable storage)。 稳定存储器的目标就是不惜一切代价保证磁盘的一致性。
稳定存储器使用两个一对相同的磁盘,对应的块一同工作形成一个无差别的块。稳定存储器为了实现这个目的,定义了下面三种操作:
稳定写(stable write)稳定读(stable read)崩溃恢复(crash recovery)
稳定写指的就是首先将块写到比如驱动器 1 上,然后将其读回来验证写入的是否正确,如果不正确,那么就会再次尝试写入和读取,一直到能够验证写入正确为止。如果块都写完了也没有验证正确,就会换块继续写入和读取,直到正确为止。无论尝试使用多少个备用块,都是在对你驱动器 1 写入成功之后,才会对驱动器 2 进行写入和读取。这样我们相当于是对两个驱动器进行写入。
稳定读指的就是首先从驱动器 1 上进行读取,如果读取操作会产生错误的 ECC,则再次尝试读取,如果所有的读取操作都会给出错误的 ECC,那么会从驱动器 2 上进行读取。这样我们相当于是对两个驱动器进行读取。
崩溃恢复指的是崩溃之后,恢复程序扫描两个磁盘,比较对应的块。如果一对块都是好的并且是相同的,就不会触发任何机制;如果其中一个块触发了 ECC 错误,这时候就需要使用好块来覆盖坏块。
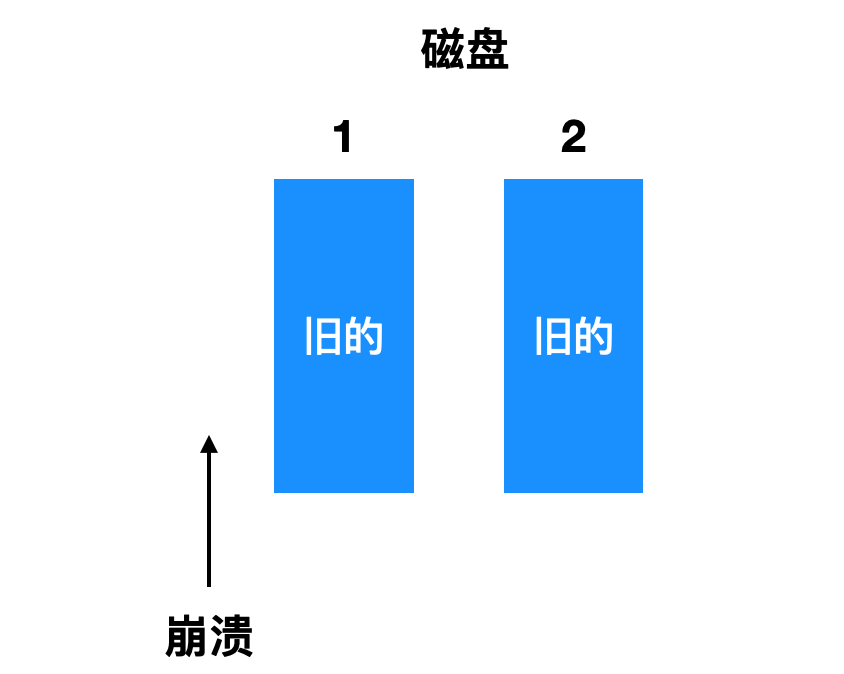
如果 CPU 没有崩溃的话,那么这种方式是可行的,因为稳定写总是对每个块写下两个有效的副本,并且假设自发的错误不会再相同的时刻发生在两个对应的块上。如果在稳定写期间出现 CPU 崩溃会怎么样?这就取决于崩溃发生的精确时间,有五种情况,下面来说一下
- 第一种情况是崩溃发生在写入之前,在恢复的时候就什么都不需要修改,旧的值也会继续存在。
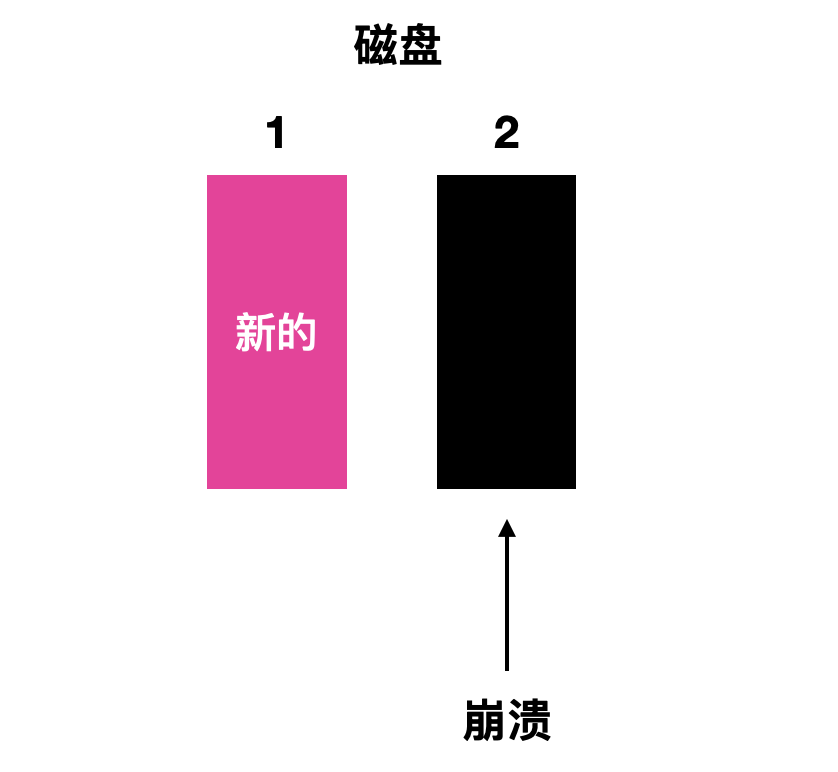
- 第二种情况是 CPU 崩溃发生在写入驱动器 1 的时候,崩溃导致块内容被破坏,然而恢复程序能够检测出这一种错误,并且从驱动器 2 恢复驱动器 1 上的块。

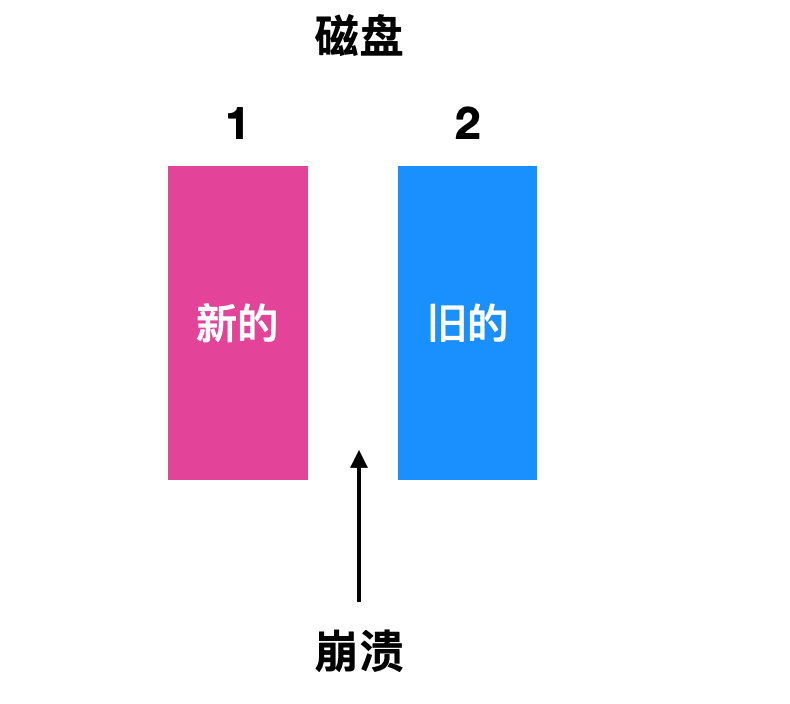
- 第三种情况是崩溃发生在磁盘驱动器 1 之后但是还没有写驱动器 2 之前,这种情况下由于磁盘 1 已经写入成功
- 第四种情况是崩溃发生在磁盘驱动 1 写入后在磁盘驱动 2 写入时,恢复期间会用好的块替换坏的块,两个块的最终值都是最新的
- 最后一种情况就是崩溃发生在两个磁盘驱动写入后,这种情况下不会发生任何问题
这种模式下进行任何优化和改进都是可行的,但是代价高昂,一种改进是在稳定写期间监控被写入的块,这样在崩溃后进行检验的块只有一个。有一种 非易失性 RAM 能够在崩溃之后保留数据,但是这种方式并不推荐使用。
时钟
时钟(Clocks) 也被称为定时器(timers),时钟/定时器对任何程序系统来说都是必不可少的。时钟负责维护时间、防止一个进程长期占用 CPU 时间等其他功能。时钟软件(clock software) 也是一种设备驱动的方式。下面我们就来对时钟进行介绍,一般都是先讨论硬件再介绍软件,采用由下到上的方式,也是告诉你,底层是最重要的。
时钟硬件
在计算机中有两种类型的时钟,这些时钟与现实生活中使用的时钟完全不一样。
- 比较简单的一种时钟被连接到 110 V 或 220 V 的电源线上,这样每个
电压周期会产生一个中断,大概是 50 - 60 HZ。这些时钟过去一直占据支配地位。 - 另外的一种时钟由晶体振荡器、计数器和寄存器组成,示意图如下所示

这种时钟称为可编程时钟 ,可编程时钟有两种模式,一种是 一键式(one-shot mode),当时钟启动时,会把存储器中的值复制到计数器中,然后,每次晶体的振荡器的脉冲都会使计数器 -1。当计数器变为 0 时,会产生一个中断,并停止工作,直到软件再一次显示启动。还有一种模式时 方波(square-wave mode) 模式,在这种模式下,当计数器变为 0 并产生中断后,存储寄存器的值会自动复制到计数器中,这种周期性的中断称为一个时钟周期。
时钟软件
时钟硬件所做的工作只是根据已知的时间间隔产生中断,而其他的工作都是由时钟软件来完成,一般操作系统的不同,时钟软件的具体实现也不同,但是一般都会包括以下这几点
- 维护一天的时间
- 阻止进程运行的时间超过其指定时间
- 统计 CPU 的使用情况
- 处理用户进程的警告系统调用
- 为系统各个部分提供看门狗定时器
- 完成概要剖析,监视和信息收集
软定时器
时钟软件也被称为可编程时钟,可以设置它以程序需要的任何速率引发中断。时钟软件触发的中断是一种硬中断,但是某些应用程序对于硬中断来说是不可接受的。
这时候就需要一种软定时器(soft timer) 避免了中断,无论何时当内核因为某种原因呢在运行时,它返回用户态之前都会检查时钟来了解软定时器是否到期。如果软定时器到期,则执行被调度的事件也无需切换到内核态,因为本身已经处于内核态中。这种方式避免了频繁的内核态和用户态之前的切换,提高了程序运行效率。
软定时器因为不同的原因切换进入内核态的速率不同,原因主要有
- 系统调用
- TLB 未命中
- 缺页异常
- I/O 中断
- CPU 变得空闲
我发起了一个成为最好的 bestJavaer 开源项目,地址是 https://github.com/crisxuan/bestJavaer,欢迎各位 star。

操作系统 I/O 全流程详解的更多相关文章
- 拥有 GitHub 开源项目的小伙伴,免费申请 JetBrains 全家桶的全流程详解
工欲善其事,必先利其器.如果您想要学习 Java.PHP.Ruby.Python.JavaScript.Objective-C..NET 中的任何一种开发技术,国际知名且屡获殊荣的 JetBrains ...
- Linux启动流程详解【转载】
在BIOS阶段,计算机的行为基本上被写死了,可以做的事情并不多:一般就是通电.BIOS.主引导记录.操作系统这四步.所以我们一般认为加载内核是linux启动流程的第一步. 第一步.加载内核 操作系统接 ...
- Sqlmap全参数详解
sqlmap全参数详解 sqlmap是在sql注入中非常常用的一款工具,由于其开源性,适合从个人到企业,从学习到实战,各领域各阶段的应用,我们还可以将它改造成我们自己独有的渗透利器.这款工具中,大大小 ...
- C++的性能C#的产能?! - .Net Native 系列《二》:.NET Native开发流程详解
之前一文<c++的性能, c#的产能?!鱼和熊掌可以兼得,.NET NATIVE初窥> 获得很多朋友支持和鼓励,也更让我坚定做这项技术的推广者,希望能让更多的朋友了解这项技术,于是先从官方 ...
- [nRF51822] 5、 霸屏了——详解nRF51 SDK中的GPIOTE(从GPIO电平变化到产生中断事件的流程详解)
:由于在大多数情况下GPIO的状态变化都会触发应用程序执行一些动作.为了方便nRF51官方把该流程封装成了GPIOTE,全称:The GPIO Tasks and Events (GPIOTE) . ...
- HTML video 视频标签全属性详解
HTML 5 video 视频标签全属性详解 现在如果要在页面中使用video标签,需要考虑三种情况,支持Ogg Theora或者VP8(如果这玩意儿没出事的话)的(Opera.Mozilla.C ...
- 迅为4412开发板Linux驱动教程——总线_设备_驱动注册流程详解
本文转自:http://www.topeetboard.com 视频下载地址: 驱动注册:http://pan.baidu.com/s/1i34HcDB 设备注册:http://pan.baidu.c ...
- iOS 组件化流程详解(git创建流程)
[链接]组件化流程详解(一)https://www.jianshu.com/p/2deca619ff7e
- git概念及工作流程详解
git概念及工作流程详解 既然我们已经把gitlab安装完毕[当然这是非必要条件],我们就可以使用git来管理自己的项目了,前文也多多少少提及到git的基本命令,本文就先简单对比下SVN与git的区别 ...
随机推荐
- os.walk()的实际应用
背景: 通过Mobaxterm从本地上传虹膜数据,一共79个类,每类里包含左右眼各400张数据,总共63200张,上传期间断网不确定是否传完. 思路: 1.首先遍历总类别数是否正确,若不足79,返回“ ...
- 使用websocket开发智能聊天机器人
前面我们学习了异步web框架(sanic)和http异步调用库httpx,今天我们学习websocket技术. websocket简介 我们知道HTTP协议是:请求->响应,如果没有响应就一直等 ...
- Rocket - tilelink - RegisterRouter
https://mp.weixin.qq.com/s/DaJhf7hEoWsEi_AjwSrOfA 简单介绍RegisterRouter的实现. 1. 基本介绍 实现挂在Tile ...
- Rocket - 断句 - Diplomacy and TileLink from the Rocket Chip
https://mp.weixin.qq.com/s/rfgptF9YxDpzDoespYtQvA 整理Diplomacy and TileLink from the Rocket Chip这篇文 ...
- java方法句柄-----1.方法句柄类型、调用
目录 方法句柄 1.方法句柄的类型 1.1MethodType类的对象实例的创建 1.1.1 通过指定参数和返回值的类型来创建MethodType.[显式地指定返回值和参数的类型] 1.1.2 通过静 ...
- Java实现 LeetCode 819 最常见的单词(暴力)
819. 最常见的单词 给定一个段落 (paragraph) 和一个禁用单词列表 (banned).返回出现次数最多,同时不在禁用列表中的单词. 题目保证至少有一个词不在禁用列表中,而且答案唯一. 禁 ...
- Java实现 LeetCode 378 有序矩阵中第K小的元素
378. 有序矩阵中第K小的元素 给定一个 n x n 矩阵,其中每行和每列元素均按升序排序,找到矩阵中第k小的元素. 请注意,它是排序后的第k小元素,而不是第k个元素. 示例: matrix = [ ...
- Java实现 LeetCode 49 字母异位词分组
49. 字母异位词分组 给定一个字符串数组,将字母异位词组合在一起.字母异位词指字母相同,但排列不同的字符串. 示例: 输入: ["eat", "tea", & ...
- 数据的存储结构浅析LSM-Tree和B-tree
目录 顺序存储与哈希索引 SSTable和LSM tree B-Tree 存储结构的比对 小结 本篇主要讨论的是不同存储结构(主要是LSM-tree和B-tree),它们应对的不同场景,所采用的底层存 ...
- Java培训Day01——制作疫情地图(一)
一.前言 此次培训,是为期三天的网上培训.最终的目的是制作出疫情地图.首先我们来看看主要的讲课内容大纲. Day1 |-Java语法学习(个人感觉讲得还可以,主要围绕本次培训作出的讲解,没有像网上的基 ...