第二章 表与指针Pro SQL Server Internal (Dmitri Korotkev)
聚集索引
聚集索引就是表中数据的物理顺序,它是按照聚集索引分类的。表只能定义一个聚集索引。
如果你要在一个有数据的堆表中创建一个聚集索引,如2-5所示,第一步要做的就是SQL服务器创建另一个根据聚集索引键分类的数据副本。数据页连接到双向链表,双向链表的每一页都包含指向下一页或前一页的指针。这个表就称为索引的叶级,它包括实际的数据表。
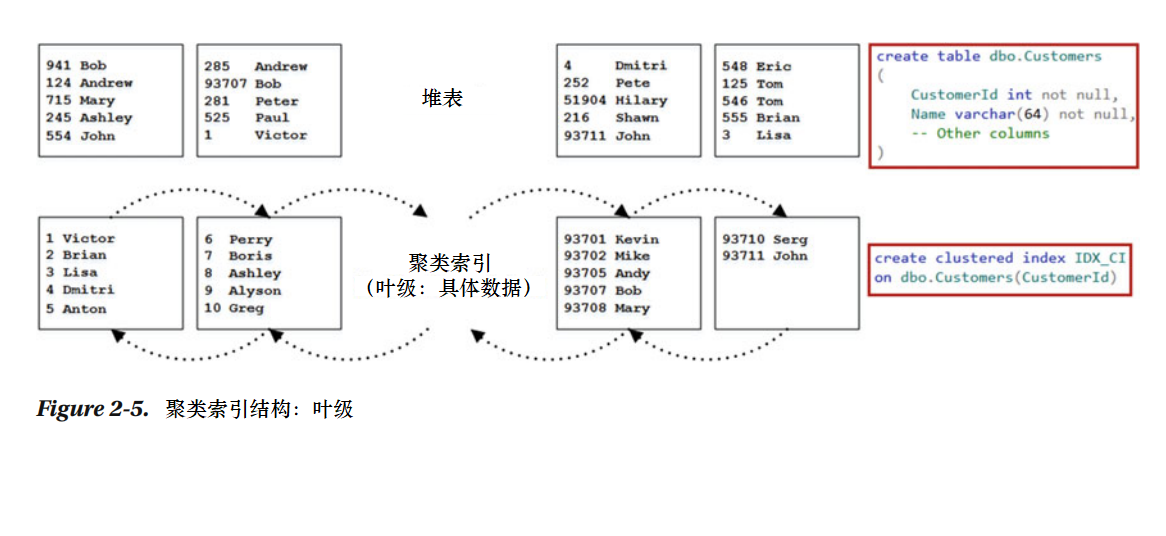
笔记:页面排序是由缝隙阵控制的,页中的实际数据没有排序。
当叶级别由多个页构成,SQL服务器会创建一个索引的中级维护,如表2-6所示。
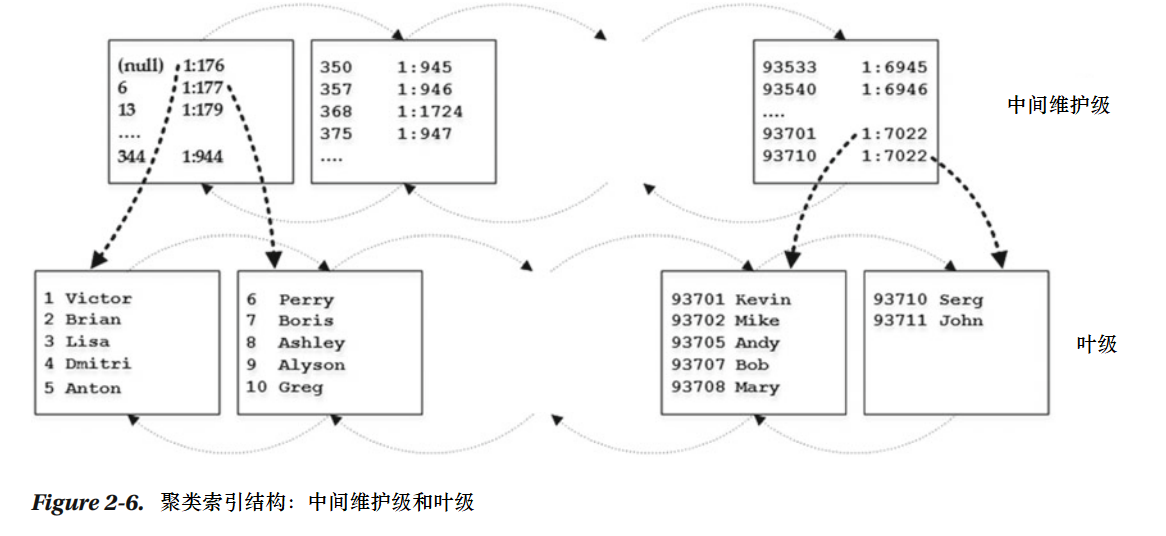
中间维护级每叶级的页面存一行数据,包含两条信息:物理地址和从页中获得的索引键最小值。唯一例外的只有最先前的第一页的第一行,这个位置SQL服务器存空值,不是最小索引键值。优化过后,当你要用最小键值插入新的行时,SQL服务器不需要更新非叶级的行。
中间维护级也连接到双向链表,SQL服务器天可以一直添加中间维护级的页面直到它只包含单独页面的级别,这个级别称为根级。它也是索引的添加点,如图2-7所示。

可以发现,索引总是只有一个叶级,一个根级,无或多个中间维护级。唯一例外的是当索引数据纳入单独的页面。这时候SQL服务器不会创建一个单独的根页面,而且索引只有单独的叶级页面。
索引页面的数量很大程度依赖于行和索引键的大小。例如4字节整数列的键在叶中间维护级和根级需要每行13字节的大小,这13字节有2字节缝隙阵入口,4字节索引键的值和6字节的页指针,还有1字节行开销,它用来确保空间充足,因为索引键不包括可变长度列和空列。
结果表明,它能适应8060字节除以13字节每行,等于620行每页。它说明用一个中间维护级页能存储620*620=384,400叶级页面的信息。如果数据行是200字节,你能每叶级页面存40行,而且仅用3级索引可高达15,376,000行。添加另一个中间维护级到索引中,能基本覆盖所有的整数值。
笔记:在现实中,索引碎片会减少这些数量。我们在第六章会提到索引碎片。
SQL服务器有三种不同的从索引中读取数据。第一种是通过排序扫描。我们假设我们要执行这段代码: SELECT Name FROM dbo.Customers ORDER BY CustomerId query. 索引的页级数据已经按Customer Id列的值排序好了。结果就是SQL服务器能从第一页到最后一页扫描索引的页级页面,并按原来存储的顺序返回行。、
SQL服务器从索引的根级页面开始读取第一行,行用键最小值参照中间维护级页面。SQL服务器读取页面并重复步骤知道它找到页级第一页。然后SQL服务器开始一行接着一行读取行,按照页面连接表移动知道所有的行都读取了。图2-8阐述了这一过程。
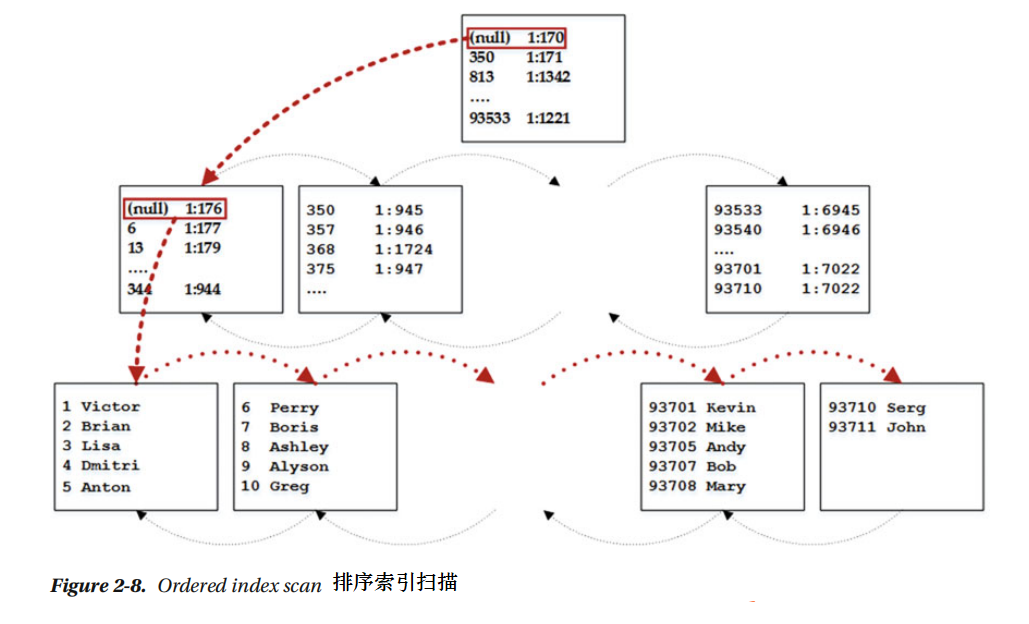
前置查询的查询计划显示聚类索引扫描操作员设置排序属性集为true,如图2-9

值得一提的是条款的顺序不是要引发扫描排序。扫描排序只是把SQL服务器基于索引键的顺序读取数据。SQL服务器能够从向前或向后两个方向同时索引导航,然而一定要记住SQL服务器在向后索引扫描时不能并行使用。
提示:可以通过查询计划测试索引扫描属性或索引查找属性来检查扫描的方向。记住,Management Stdio不会通过图表显示这些属性。你要打开属性窗口,选中操作窗体的执行计划并且选中View属性窗体菜单项目,或者F4按钮才能看到。
企业版的SQL服务器有一个叫做 merry-go-roundscan的优化属性呢能过允许多个任务共享同一个索引扫描。假设S1会话在扫描索引,有时候在扫描中,另一个S2会话执行查询需要扫描同一个索引,通过 merry-go-roundscan会话S2在S1现有的位置加入S1扫描中。SQL服务器每页只读取一次扫描,同时进行两个会话。
当S1扫描到了索引末端,S2开始从索引首段开始扫描数据,直到指针指向它开始的位置。 merry-go-roundscan是另一个为什么不能依靠索引键顺序的例子,也是为什么要特定ORDER BY条款。下一个存取方式在排序扫描被叫做分配顺序扫描之后,SQL服务器通过IAM页面来存取表格数据,它类似堆表的方式。e SELECT Name FROM dbo.Customers WITH (NOLOCK)查询语句和表2-10说明了这个方法。表2-11是这个语句的执行计划。
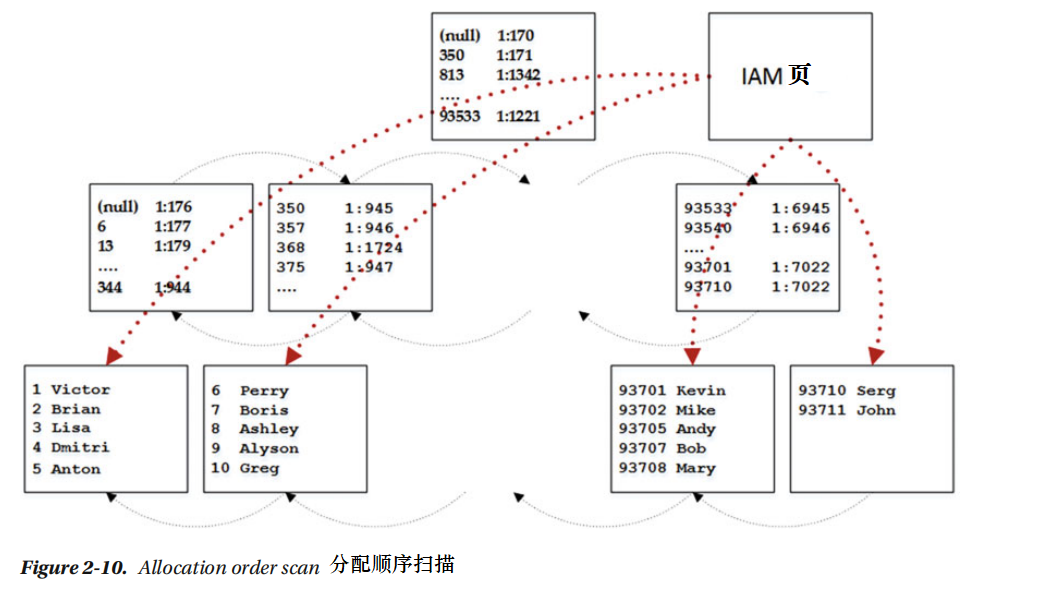

不巧的是,当SQL服务器在使用分配顺序扫描的时候不容易察觉,尽管Ordered 属性在执行计划的时候显示失败,它还是表明SQL服务器不管是不是按索引键顺序读取行,还是按分配顺序扫描。
另一个分配顺序扫描在扫描大量的表格的时候会更快,尽管启动的时候会有更大的开销,在表单不多的时候SQL服务器不用这种存取方式。另一个重要的考虑因素就是数据连贯性,SQL服务器在表单有聚类索引的时候不使用前向指针,分配顺序扫描会导致不连贯,因为页面切割后可能会跳过行或重复读取行。结果就是SQL服务器一般避免使用分配顺序扫描,除非需要读取的数据是读未提交或者可序列化的事务隔离级别。
笔记:我们会在第六章的“指针碎片”一节谈到页面切割和碎片,还会在第三节“锁定、封锁、并发”提到锁定和数据连贯性。
最后的索引存储方法叫做索引查找,“ SELECT Name FROM dbo.Customers WHERE CustomerId BETWEEN 4 AND 7”查询语句和图2-12说明了操作。
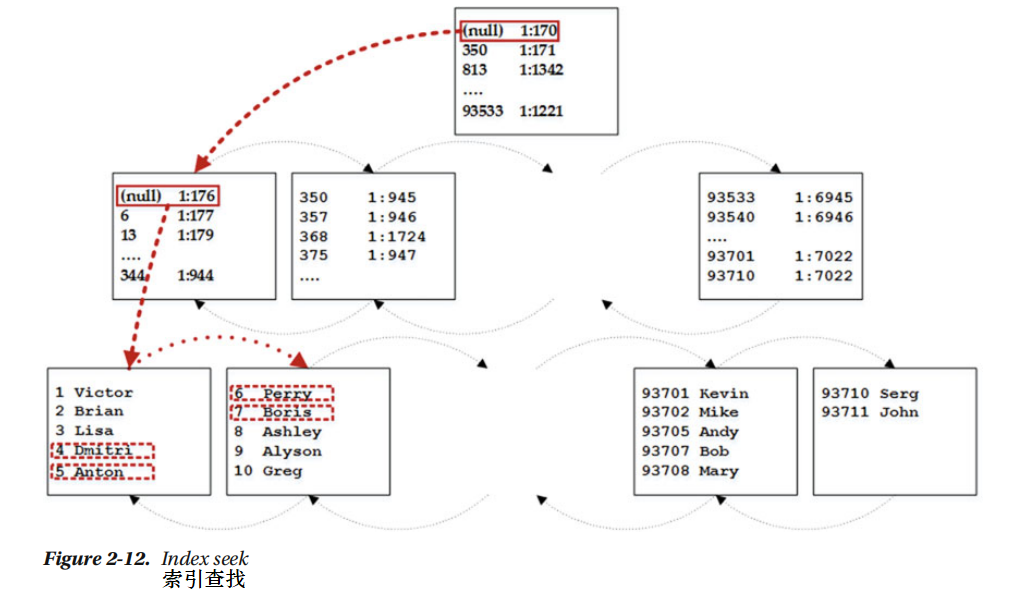
为了从表中读取一定范围的行,SQL服务器用最小键值需要找到行,这个最小值为4,SQL服务器从根页面开始,它的第二行参照页面最小键值350。这个比我们在寻找(4)需要更大的键值,SQL服务器参照根页面的第一行读取中间维护级页面(1:170)。
类似的中间维护级页面引导SQL服务器到第一个叶级页面(1:176)。SQL服务器读取页面然后用CustomerIds e等于4或5来读取行,最后在第二页读取到两行。
执行计划如如2-13

可以看出索引查找比索引扫描更有效率,因为SQL服务器进程只是行和数据页的子集,而不是臊面整个表。
从技术角度出发,有两种索引查找操作。第一种是单例查找,或者指针查找,它使SQL服务器查找返回单个行。以WHERE CustomerId = 2 为例,另一个类型的索引查找叫做范围扫描,它使SQL服务器找到键的最大和最小值并扫描(前向后向扫描)行的集合直到到达扫描范围的末端。 查询语句”WHERE CustomerId BETWEEN 4 AND 7 “进行范围扫描,这两种情况在执行计划中都属于索引查找。
你能猜到,范围扫描完全可能让SQL服务器处理索引中大量甚至全部数据。例如你改变查询命令为 WHERE CustomerId > 0,SQL服务器会读取所有页所有行,尽管能用索引查找显示执行计划,还是要记得在查询语句性能调节时,分析范围扫描的效率。
关系数据库有一个概念叫 SARGable 预测,代表搜索参数,这个预测是SARGable当SQL服务器能耐隔离出单独值或范围的索引键值时,在预测评价时限制查询。显然,SARGable预测还有利用索引查找对写查询语句很有利。
SARGable 预测包括这些操作符号:= , > , >= , < , <= , IN , BETWEEN , LIKE(防止前置匹配)。非SARGable操作符包括:NOT , <> , LIKE(防止非前置匹配),NOT IN。
非SARGable预测时的另一种情况是使用功能或数学计算与表中的列产生冲突,sql服务器必须调用该函数或对其处理的每行执行计算。幸运的是,在某些情况下您可以重构查询来预测SARgable。表2-1列举了一些例子。

要记住的另一个重要因素是类型转换,在某些情况下,您可以通过使用不正确的数据类型来预测非SARGable。我们创建一个带有可变长字符列的表并填充一些数据,如2-6

聚集索引键列定义为可变长字符,虽然它存储的是整型值。现在,让我们进行两个选择,如表2-7,查看执行计划。

如图2-14,在整数参数的情况下,S QL 服务器扫描聚集索引,将每行的可变长字符型转换为整型。在第二种情况下,S QL Server将整数参数转换为可变长字符型并且利用更有效的聚类索引搜索操作。

注意在加入预测中的列数据类型,隐式或显式的数据类型转换可以显著降低查询的性能。您会观察到非常相似的行为,在Unicode字符串参数的情况下。执行2-8表中的执行语句,图2-15显示声明的执行计划。

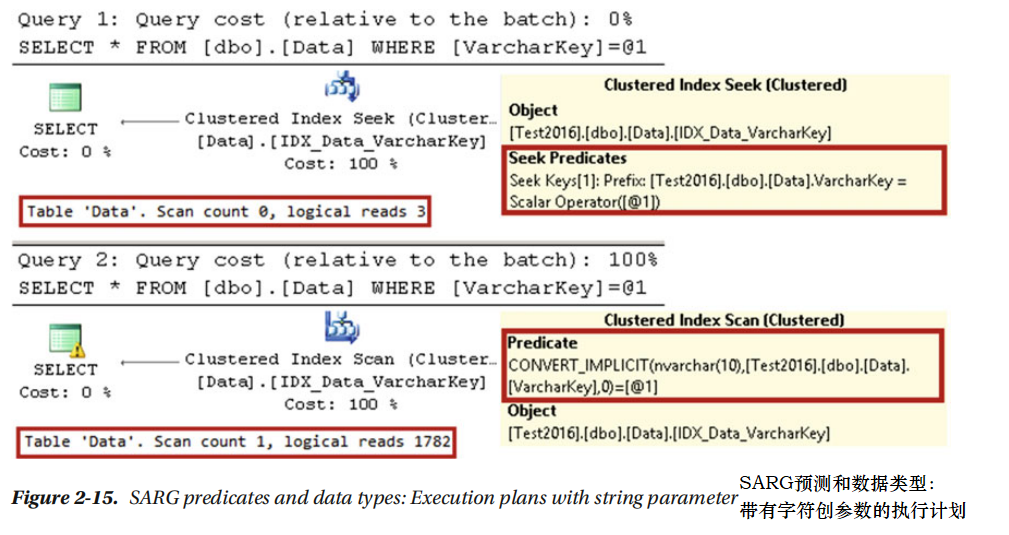
正如您所看到的,Unicode字符串参数对于varchar列是非SARGable 。这是一个比表面看来更大的问题。虽然很少用这种方式写查询语句,如表2-8,现在大多数应用程序开发环境将字符串视为Unicode。Sql服务器客户端库对于字符串对象产生Unicode(nvarchar)参数,除非参数数据类型明确指定为可变长字符型.使预测非SARGable,而且由于不必要的扫描,它会导致主要的性能命中即使是在可变长字符型列被索引的时候。
重要提示:始终在客户端应用程序中指定参数数据类型。例如在 ADO.Net,中使用Parameters.Add("@ParamName",SqlDbType.Varchar, <Size>).Value = stringVariable,而不是超载的Parameters.Add("@ParamName").Value = stringVariable 在orm框架中使用映射来显式指定类中的非unicode属性。
值得一提的是可变长字符类型参数可用于nvarchar Unicode数据列
第二章 表与指针Pro SQL Server Internal (Dmitri Korotkev)的更多相关文章
- Pro SQL Server Internal (Dmitri Korotkev)电子书翻译P8-14(12w)
数据行与数据列 数据库的控件逻辑上分成8KB的页,这些页从0开始,连续排序,对特定的文件ID和页码有借鉴意义.页码编号一定是连续的,当SQL服务器中的数据库文件增加时,新的数据页从最高的页码开始编码. ...
- 第十三周翻译-《Pro SQL Server Internals, 2nd edition》
<Pro SQL Server Internals, 2nd edition> 作者:Dmitri Korotkevitch 翻译:赖慧芳 译文: 聚集索引 聚集索引指示表中数据的物理顺序 ...
- 《Pro SQL Server Internals, 2nd edition》的CHAPTER 2 Tables and Indexes中的Clustered Indexes一节(翻译)
<Pro SQL Server Internals> 作者: Dmitri Korotkevitch 出版社: Apress出版年: 2016-12-29页数: 804定价: USD 59 ...
- 第十五周翻译-《Pro SQL Server Internals, 2nd edition》
<Pro SQL Server Internals, 2nd edition> 作者:Dmitri Korotkevitch 翻译:赖慧芳 译文: 55-58页 第三章 统计 SQL Se ...
- 第十四周翻译-《Pro SQL Server Internals, 2nd edition》
<Pro SQL Server Internals, 2nd edition> 作者:Dmitri Korotkevitch 翻译:赖慧芳 译文: 设计和优化索引 定义一种应用于所有地方的 ...
- 第十二周翻译-《Pro SQL Server Internals, 2nd edition》
<Pro SQL Server Internals, 2nd edition> 作者:Dmitri Korotkevitch 翻译:赖慧芳 译文: 专业SQL服务器内部 了解在引擎盖下发生 ...
- 《Pro SQL Server Internals, 2nd edition》
设计和优化索引 定义一种应用于所有地方的索引策略是不可能的.每个系统都是独特的,需要基于工作,业务需求和其他一些因素的自己的索引方法.然而,有几个设计的注意事项和指导方针可以被应用到每个系统. 在我们 ...
- 《Pro SQL Server Internals, 2nd edition》的CHAPTER 3 Statistics中的Introduction to SQL Server Statistics、Statistics and Execution Plans、Statistics Maintenance(译)
<Pro SQL Server Internals> 作者: Dmitri Korotkevitch 出版社: Apress出版年: 2016-12-29页数: 804定价: USD 59 ...
- 《Pro SQL Server Internals, 2nd edition》中CHAPTER 7 Designing and Tuning the Indexes中的Clustered Index Design Considerations一节(译)
<Pro SQL Server Internals> 作者: Dmitri Korotkevitch 出版社: Apress出版年: 2016-12-29页数: 804定价: USD 59 ...
随机推荐
- Nuxt.js学习(二) --- Nuxt目录结构详解、Nuxt常用配置项、Nuxt路由配置和参数传递
[TOC] 1.Nuxt目录结构详解 Nuxt项目文件目录结构 |-- .nuxt // Nuxt自动生成,临时的用于编辑的文件,build |-- assets // 用于组织未编译的静态资源入LE ...
- java gc 总结
垃圾查找 1.基于计数器 对象有引用计数,计数为0的,可以被收集 2.基于有向图 从gc root(栈.静态变量.JNI 变量)遍历,能访问的对象,不用被收集,其他的,可以被收集 因为计数器不能解决 ...
- mock简单的json返回
针对非常简单的json返回串,我们也不一定非得通过freemarker模板的方式来构造返回数据,这里看实际的需求,如果返回的内容是固定的,而且json又非常简单,我们也可以直接写在程序里面,下面的接口 ...
- linux 上安装 tomcat
准备条件:安装java 一.tomcat 的安装 #新建文件夹 mkdir -p /data/tomcat #下载 tomcat8 服务器 wget http://mirrors.tuna.tsing ...
- fibonacci-Heap(斐波那契堆)原理及C++代码实现
斐波那契堆是一种高级的堆结构,建议与二项堆一起食用效果更佳. 斐波那契堆是一个摊还性质的数据结构,很多堆操作在斐波那契堆上的摊还时间都很低,达到了θ(1)的程度,取最小值和删除操作的时间复杂度是O(l ...
- SAP PM:通过接口获取设备资产基本信息
在SAP工厂维护模块中,给设备贴二维码标签是现在越来越流行的做法.因此通过扫描二维码获取设备资产信息是个非常基本的需求. 以下实例简单实现了,给SAP RFC传入设备编码获取设备资产基本信息的需求. ...
- rest framework-版本-长期维护
############### 版本 ############### # # 版本的问题: # rest_framework.versioning.URLPathVersioning # 一般就 ...
- Yii框架的学习指南(策码秀才篇)1-3 我是这么学习的yii framework (不间断更新中)
Ⅰ.基本概念一.入口文件入口文件内容:一般格式如下:<?php $yii=dirname(__FILE__).'/../../framework/yii.php';//Yii框架位置$confi ...
- elasticsearch5.4安装
1.从官网下载ES 安装包: elasticsearch-.tar.gz 2.解压到要安装的目录 注意:一定要切换用户,不能用root用户解压,不能用root用户启动 tar -zxvf elasti ...
- Centos防火墙开启端口
linux系统对外开放80.8080等端口,防火墙设置 我们很多时候在liunx系统上安装了web服务应用后(如tomcat.apache等),需要让其它电脑能访问到该应用,而Linux系统(cent ...