搜索引擎如何检索结果:Python和spaCy信息提取简介
概览
- 像Google这样的搜索引擎如何理解我们的查询并提供相关结果?
- 了解信息提取的概念
- 我们将使用流行的spaCy库在Python中进行信息提取
介绍
作为一个数据科学家,在日常工作中,我严重依赖搜索引擎(尤其是Google)。我的搜索结果涉及各种查询:Python代码问题,机器学习算法,自然语言处理(NLP)框架的比较等。我一直很好奇这些搜索引擎如何理解我的查询并提取相关结果,就像他们知道我在想什么一样。我想了解NLP方面在这里是如何工作的:该算法如何理解非结构化文本数据并将其转换为结构化数据并显示相关结果?让我们举个例子。我在Google上输入了两个不同的查询:

首先,Google迅速确定了实体(world cup)和动作(won)。在第二个查询中,在得到结果之前,我甚至还没有完成句子!你认为Google如何理解这些查询背后的上下文?这是一个令人着迷的想法,我们将在本文中对其 讲解。我们将了解根据搜索查询如何生成这些有意义且相关的结果的核心思想。是的,我们甚至将深入研究Python代码并动手实践。让我们开始吧!
注意:我建议你阅读这篇有关数据科学中的计算语言学和依赖树简介的文章1,以更好地了解我们将在此处学习的内容。
信息抽取
信息提取(IE)在自然语言处理(NLP)和语言学领域是至关重要的。它广泛用于诸如问答系统,机器翻译,实体提取,事件提取,命名实体链接,指代消解,关系提取等任务。在信息提取中,有一个重要的三元组概念。
三元组代表实体以及它们之间的关系。例如,(奥巴马,出生于,夏威夷)是一个三元组,其中"奥巴马"和"夏威夷"是相关实体,它们之间的关系是"出生于"。
在本文中,我们将重点介绍从给定文本中提取这些类型的三元组。
在继续之前,让我们看一下信息提取的不同方法。我们可以将信息提取大致分为两个分支,如下所示:

在传统信息提取中,要提取的关系是预先定义的。在本文中,我们将仅介绍基于规则的方法。
在开放信息提取中,关系不是预先定义的。该系统可以自由提取在处理文本数据时遇到的任何关系。
语义关系:从非结构化文本中获取结构化知识
看看下面的文字片段:

你能想到从该文本中提取有意义的信息的任何方法吗?让我们尝试逐句解决此问题:

在第一句话中,我们有两个实体 (“Food Tutorials” 和 “Wes Anderson”),这些实体通过术语 "Directed"相关起来的,因此, (Wes Anderson, directed, Food Tutorials) 是一个三元组。同样,我们也可以从其他句子中提取关系:

事实证明,我们可以根据文本的句法结构和语法来获得结构化信息,如上例所示。
信息提取的不同方法
在上一节中,我们设法从几个句子中轻松提取出三元组。但是,在现实世界中,数据量巨大,并且人工提取结构化信息是不可行的。因此,自动化此信息提取变得很重要。
有多种方法可以自动执行信息提取。让我们一一理解它们:
- 基于规则的方法:我们为自然语言的语法和其他语法属性定义了一组规则,然后使用这些规则从文本中提取信息
- 监督学习的方法:假设我们有一个句子S。它有两个实体E1和E2。现在,监督机器学习模型必须检测E1和E2之间是否存在任何关系®。因此,在一种有监督的方法中,关系提取的任务变成了关系检测的任务。这种方法的唯一缺点是,它需要大量标记数据来训练模型
- 半监督学习的方法:当没有足够的标签数据时,我们可以使用一组示例(三元组)来制定高精度模式,该模式可用于从文本中提取更多关系
使用Python和spaCy提取信息
我们在这里对理论有所了解,因此让我们进入Python代码层面。我敢肯定,你很想了解本节内容!
我们将做一个小项目,从非结构化数据(在本例中为文本数据)中提取结构化信息。我们已经看到,文本中的信息以不同实体之间的关系形式存在。
因此,在本节中,我们将尝试发现和提取与某种关系或另一种关联的不同实体对。

spaCy基于规则的匹配
在开始之前,让我们谈谈Marti Hearst。她是计算语言学研究员,也是加州大学伯克利信息学院的教授。
Marti教授实际上已经对信息提取主题进行了广泛的研究。她最有趣的研究之一是致力于建立一组文本模式,这些模式可用于从文本中提取有意义的信息。这些模式俗称“Hearst Patterns”。
让我们看下面的例子:

仅通过查看句子的结构,我们就可以推断出"Gelidium"是"red algae"的一种。
我们可以将此模式形式化为"X such as Y",其中X是上位词,Y是下位词。这是"Hearst Patterns"中的许多模式之一。下图可让你直观了解该想法:

现在,我们尝试使用这些模式/规则来提取上位词-下为词对。我们将使用spaCy的基于规则的匹配器来执行此任务。
首先,我们将导入所需的库:
import re
import string
import nltk
import spacy
import pandas as pd
import numpy as np
import math
from tqdm import tqdm
from spacy.matcher import Matcher
from spacy.tokens import Span
from spacy import displacy
pd.set_option('display.max_colwidth', 200)
接下来,加载一个spaCy模型:
# 加载spaCy模型
nlp = spacy.load("en_core_web_sm")
我们将根据这些Hearst Patterns从文本中挖掘信息。
模式: X such as Y
# 示例文本
text = "GDP in developing countries such as Vietnam will continue growing at a high rate."
# 创建spaCy对象
doc = nlp(text)
为了能够从上面的句子中提取所需的信息,理解其句法结构(例如主语,宾语,修饰语和词性(POS))非常重要。
通过使用spaCy,我们可以轻松地探索句子中的这些语法细节:
# 打印标记,依赖和词性标记
for tok in doc:
print(tok.text, "-->",tok.dep_,"-->", tok.pos_)
output:
GDP --> nsubj --> NOUN
in --> prep --> ADP
developing --> amod --> VERB
countries --> pobj --> NOUN
such --> amod --> ADJ
as --> prep --> ADP
Vietnam --> pobj --> PROPN
will --> aux --> VERB
continue --> ROOT --> VERB
growing --> xcomp --> VERB
at --> prep --> ADP
a --> det --> DET
high --> amod --> ADJ
rate --> pobj --> NOUN
. --> punct --> PUNCT
看看术语"such"和"as"。它们跟在一个名词(“countries”)后。在它们之后,我们有一个专有名词(“Vietnam”)充当下位词。因此,让我们使用依赖项标签和词性标签创建所需的模式:
# 定义模式
pattern = [{'POS':'NOUN'},
{'LOWER': 'such'},
{'LOWER': 'as'},
{'POS': 'PROPN'} # 专有名词]
让我们从文本中提取模式:
# Matcher类对象
matcher = Matcher(nlp.vocab)
matcher.add("matching_1", None, pattern)
matches = matcher(doc)
span = doc[matches[0][1]:matches[0][2]]
print(span.text)
output:
‘countries such as Vietnam’
好像不错。但是,如果我们可以得到 “developing countries"而不只是"countries”,那么输出将更有意义。
因此,我们现在还将通过使用以下代码来捕获"such as"之前的名词的修饰语:
# Matcher类对象
matcher = Matcher(nlp.vocab)
# 定义模式
pattern = [{'DEP':'amod', 'OP':"?"}, # 形容词修饰
{'POS':'NOUN'},
{'LOWER': 'such'},
{'LOWER': 'as'},
{'POS': 'PROPN'}]
matcher.add("matching_1", None, pattern)
matches = matcher(doc)
span = doc[matches[0][1]:matches[0][2]]
print(span.text)
ouutput:
‘developing countries such as Vietnam’
在这里,"developing countries"是上位词,"Vietnam’"是下位词。两者在语义上都是相关的。
注意:以上模式中的键" OP":"?"表示修饰符(“amod”)可以出现一次,也可以不出现。
以类似的方式,我们可以从其他文本中获得:
- Fruits such as apples
- Cars such as Ferrari
- Flowers such as rose
现在,让我们使用其他一些Hearst Patterns来提取更多的上位词和下位词。
模式: X and/or Y
doc = nlp("Here is how you can keep your car and other vehicles clean.")
# 打印依赖项标签和词性标签
for tok in doc:
print(tok.text, "-->",tok.dep_, "-->",tok.pos_)
output:
Here --> advmod --> ADV
is --> ROOT --> VERB
how --> advmod --> ADV
you --> nsubj --> PRON
can --> aux --> VERB
keep --> ccomp --> VERB
your --> poss --> DET
car --> dobj --> NOUN
and --> cc --> CCONJ
other --> amod --> ADJ
vehicles --> conj --> NOUN
clean --> oprd --> ADJ
. --> punct --> PUNCT
# Matcher类对象
matcher = Matcher(nlp.vocab)
# 定义模式
pattern = [{'DEP':'amod', 'OP':"?"},
{'POS':'NOUN'},
{'LOWER': 'and', 'OP':"?"},
{'LOWER': 'or', 'OP':"?"},
{'LOWER': 'other'},
{'POS': 'NOUN'}]
matcher.add("matching_1", None, pattern)
matches = matcher(doc)
span = doc[matches[0][1]:matches[0][2]]
print(span.text)
output:
‘car and other vehicles’
让我们尝试相同的代码来捕获"X or Y"模式:
# 将'and'替换为'or'
doc = nlp("Here is how you can keep your car or other vehicles clean.")
其余代码将保持不变:
# Matcher类对象
matcher = Matcher(nlp.vocab)
#定义模式
pattern = [{'DEP':'amod', 'OP':"?"},
{'POS':'NOUN'},
{'LOWER': 'and', 'OP':"?"},
{'LOWER': 'or', 'OP':"?"},
{'LOWER': 'other'},
{'POS': 'NOUN'}]
matcher.add("matching_1", None, pattern)
matches = matcher(doc)
span = doc[matches[0][1]:matches[0][2]]
print(span.text)
output:
‘car or other vehicles’
模式: X, including Y
doc = nlp("Eight people, including two children, were injured in the explosion")
for tok in doc:
print(tok.text, "-->",tok.dep_, "-->",tok.pos_)
output:
Eight --> nummod --> NUM
people --> nsubjpass --> NOUN
, --> punct --> PUNCT
including --> prep --> VERB
two --> nummod --> NUM
children --> pobj --> NOUN
, --> punct --> PUNCT
were --> auxpass --> VERB
injured --> ROOT --> VERB
in --> prep --> ADP
the --> det --> DET
explosion --> pobj --> NOUN
# Matcher类对象
matcher = Matcher(nlp.vocab)
#定义模式
pattern = [{'DEP':'nummod','OP':"?"}, # 数值修饰
{'DEP':'amod','OP':"?"}, # 形容词修饰
{'POS':'NOUN'},
{'IS_PUNCT': True},
{'LOWER': 'including'},
{'DEP':'nummod','OP':"?"},
{'DEP':'amod','OP':"?"},
{'POS':'NOUN'}]
matcher.add("matching_1", None, pattern)
matches = matcher(doc)
span = doc[matches[0][1]:matches[0][2]]
print(span.text)
output:
‘Eight people, including two children’
模式: X, especially Y
doc = nlp("A healthy eating pattern includes fruits, especially whole fruits.")
for tok in doc:
print(tok.text, tok.dep_, tok.pos_)
output:
A --> det --> DET
healthy --> amod --> ADJ
eating --> compound --> NOUN
pattern --> nsubj --> NOUN
includes --> ROOT --> VERB
fruits --> dobj --> NOUN
, --> punct --> PUNCT
especially --> advmod --> ADV
whole --> amod --> ADJ
fruits --> appos --> NOUN
. --> punct --> PUNCT
# Matcher类对象
matcher = Matcher(nlp.vocab)
# 定义模式
pattern = [{'DEP':'nummod','OP':"?"},
{'DEP':'amod','OP':"?"},
{'POS':'NOUN'},
{'IS_PUNCT':True},
{'LOWER': 'especially'},
{'DEP':'nummod','OP':"?"},
{'DEP':'amod','OP':"?"},
{'POS':'NOUN'}]
matcher.add("matching_1", None, pattern)
matches = matcher(doc)
span = doc[matches[0][1]:matches[0][2]]
print(span.text)
output:
‘fruits, especially whole fruits’
####2.子树匹配以进行关系提取
简单的基于规则的方法非常适合信息提取任务。但是,它们有一些缺点和不足。
我们必须极富创造力,以提出新的规则来捕获不同的模式。很难建立能在不同句子之间很好地概括的模式。
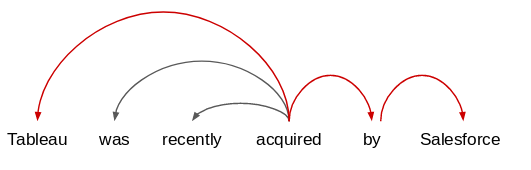
为了增强基于规则的关系/信息提取方法,我们应该尝试了解现有句子的依存关系结构。让我们以示例文本为例,构建其依赖关系图表树:
text = "Tableau was recently acquired by Salesforce."
# 绘制依赖图
doc = nlp(text)
displacy.render(doc, style='dep',jupyter=True)
output:

你能在这句话中找到任何有趣的关系吗?如果你查看句子中的实体:Tableau和Salesforce,它们与术语"acquired"相关。因此,我可以从这句话中提取的模式是" Salesforce acquired Tableau"或" X acquired Y"。
现在考虑以下说法:Careem, a ride-hailing major in the middle east, was acquired by Uber."
其依赖图将如下所示:
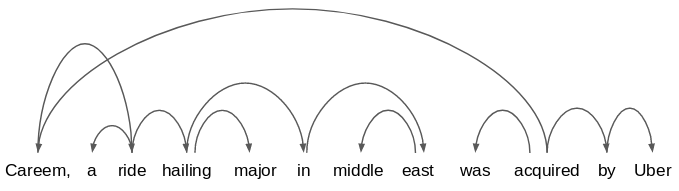
很吓人吧?
不过不用担心我们需要检查的是,多个句子之间有哪些共同依赖路径。此方法称为子树匹配。
例如,如果我们将此语句与上一个语句进行比较:
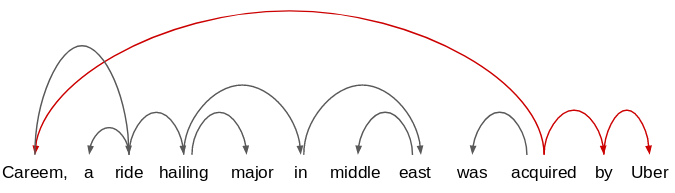
我们将仅考虑公共依赖路径,并提取实体以及它们之间的关系(acquired)。因此,从这些句子中提取的关系为:
Salesforce acquired Tableau
Uber acquired Careem
让我们尝试在Python中实现此技术。我们将再次使用spaCy,因为它很容易遍历依赖树。
我们将首先查看句子中单词的依赖项标签和POS:
text = "Tableau was recently acquired by Salesforce."
doc = nlp(text)
for tok in doc:
print(tok.text,"-->",tok.dep_,"-->",tok.pos_)
output:
Tableau --> nsubjpass --> PROPN
was --> auxpass --> VERB
recently --> advmod --> ADV
acquired --> ROOT --> VERB
by --> agent --> ADP
Salesforce --> pobj --> PROPN
. --> punct --> PUNCT
在这里," Tableau"的依赖项标签是nsubjpass,它表示被动主语(因为它是被动句子)。另一个实体"Salesforce"是该句子中的宾语,术语"acquired"是句子的根,这意味着它以某种方式将宾语和主语联系起来。
让我们定义一个函数来执行子树匹配:
def subtree_matcher(doc):
x = ''
y = ''
# 遍历输入句子中的所有标记
for i,tok in enumerate(doc):
# 抽取主语
if tok.dep_.find("subjpass") == True:
y = tok.text
# 抽取宾语
if tok.dep_.endswith("obj") == True:
x = tok.text
return x,y
在这种情况下,我们只需要查找所有符合以下条件的句子:
- 有两个实体,并且"acquired"一词是句子中唯一的根
然后,我们可以从句子中捕获主语和宾语。让我们调用上面的函数:
subtree_matcher(doc)
output:
(‘Salesforce’, ‘Tableau’)
这里,主语是收购者,宾语是被收购的实体。让我们使用相同的函数subtree_matcher()来提取通过相同关系(“acquired”)关联的实体:
text_2 = "Careem, a ride hailing major in middle east, was acquired by Uber."
doc_2 = nlp(text_2)
subtree_matcher(doc_2)
output:
(‘Uber’, ‘Careem’)
你看到这里发生了什么吗?这句话有更多的单词和标点符号,但我们的逻辑仍然有效并成功地提取了相关实体。
但是,等等-如果我将句子从被动语态更改为主动语态怎么办?我们的逻辑仍然有效吗?
text_3 = "Salesforce recently acquired Tableau."
doc_3 = nlp(text_3)
subtree_matcher(doc_3)
output:
(‘Tableau’, ‘ ‘)
那不是我们所期望的。该功能未能捕获" Salesforce",并错误地将" Tableau"返回为收购方。
那么是什么问题了?让我们了解一下这句话的依赖关系树:
for tok in doc_3:
print(tok.text, "-->",tok.dep_, "-->",tok.pos_)
output:
Salesforce --> nsubj --> PROPN
recently --> advmod --> ADV
acquired --> ROOT --> VERB
Tableau --> dobj --> PROPN
. --> punct --> PUNCT
事实证明," Salesforce"和" Tableau"这两个术语的语法功能(主语和宾语)已经在主动语态中互换了。但是,现在该主语的依赖项标签已从" nsubjpass"更改为" nsubj"。他的标签表明句子是主动语态。
我们可以使用此属性来修改子树匹配功能。下面给出的是子树匹配的新功能:
def subtree_matcher(doc):
subjpass = 0
for i,tok in enumerate(doc):
# 发现包含"subjpass" 文本的依赖项标签
if tok.dep_.find("subjpass") == True:
subjpass = 1
x = ''
y = ''
# 如果subjpass == 1 那么句子是主动语态
if subjpass == 1:
for i,tok in enumerate(doc):
if tok.dep_.find("subjpass") == True:
y = tok.text
if tok.dep_.endswith("obj") == True:
x = tok.text
# 如果subjpass == 0 那么句子是被动语态
else:
for i,tok in enumerate(doc):
if tok.dep_.endswith("subj") == True:
x = tok.text
if tok.dep_.endswith("obj") == True:
y = tok.text
return x,y
让我们在主动语句子上尝试这个新函数:
new_subtree_matcher(doc_3)
output:
(‘Salesforce’, ‘Tableau’)
输出正确。让我们将之前的被动语句传递给此函数:
new_subtree_matcher(nlp("Tableau was recently acquired by Salesforce."))
output:
(‘Salesforce’, ‘Tableau’)
这正是我们想要的。我们使函数稍微更通用。我希望你深入研究不同类型句子的语法结构,并尝试使此功能更加灵活。
结语
在本文中,我们了解了信息提取,关系和三元组的概念以及关系提取的不同方法。就我个人而言,我真的很乐于对此主题进行研究,并计划撰写更多有关更高级信息提取方法的文章。
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/
欢迎关注PyTorch官方中文教程站:
http://pytorch.panchuang.net/
https://www.analyticsvidhya.com/blog/2017/12/introduction-computational-linguistics-dependency-trees/?utm_source=blog&utm_medium=introduction-information-extraction-python-spacy ↩︎
搜索引擎如何检索结果:Python和spaCy信息提取简介的更多相关文章
- Shodan搜索引擎详解及Python命令行调用
shodan常用信息搜索命令 shodan配置命令 shodan init T1N3uP0Lyeq5w0wxxxxxxxxxxxxxxx //API设置 shodan信息收集 shodan myip ...
- python从入门到大神---Python的jieba模块简介
python从入门到大神---Python的jieba模块简介 一.总结 一句话总结: jieba包是分词技术,也就是将一句话分成多个词,有多种分词模型可选 1.分词模块包一般有哪些分词模式(比如py ...
- Python 3.0(一) 简介
Python 3.0(一) 简介 [目录] 1.简介 2.python特点 3.安装 简介: Python是可以称得上即简单又功能强大的少有的语言中的一种.你将会惊喜地发现,专注于问题的解决方案而不是 ...
- Python 的 six模块简介
Python 的 six模块简介 six : Six is a Python 2 and 3 compatibility library Six没有托管在Github上,而是托管在了Bitbucket ...
- Python 各种测试框架简介(三):nose
转载:https://blog.csdn.net/qq_15013233/article/details/52527260 摘要 这里将从(pythontesting.net)陆续编译四篇 Pytho ...
- Python爬虫教程-20-xml 简介
本篇简单介绍 xml 在python爬虫方面的使用,想要具体学习 xml 可以到 w3school 查看 xml 文档 xml 文档链接:http://www.w3school.com.cn/xmld ...
- Python自然语言处理---信息提取
1.数据 目前的数据总体上分为结构化和非结构化的数据.结构化的数据是指实体和关系的规范和可预测的组织.大部分的需要处理的数据都属于非结构化的数据. 2.信息提取 简言之就是从文本中获取信息意义的方法. ...
- python 使用spaCy 进行NLP处理
原文:http://mp.weixin.qq.com/s/sqa-Ca2oXhvcPHJKg9PuVg import spacy nlp = spacy.load("en_core_web_ ...
- 360搜索引擎取真实地址-python代码
还是个比较简单的,不像百度有加密算法 分析 http://www.so.com/link?url=http%3A%2F%2Fedu.sd.chinamobile.com%2Findex%2Fnews. ...
随机推荐
- WordPress 安装主题、插件时问题解决办法
--当能够在外网访问到自己的博客时,很多人都会很兴奋吧!如果环境是自己配置的,而不是用的集成环境肯定也会有点小小的成就感. --但是在我兴奋的时候遇到了个小麻烦,下载插件提示我输入FTP信任凭据,输了 ...
- Class file version does not support constant tag 16 in class file
启动服务时提示 Caused by: java.lang.ClassFormatError: Class file version does not support constant tag 16 i ...
- 一篇文章带您读懂List集合(源码分析)
今天要分享的Java集合是List,主要是针对它的常见实现类ArrayList进行讲解 内容目录 什么是List核心方法源码剖析1.文档注释2.构造方法3.add()3.remove()如何提升Arr ...
- eggjs+vue+nginx配置
安装node https://github.com/nodesource/distributions#installation-instructions-1 注意使用No root privilege ...
- Git 相关问题分享,git reset与git revert的区别?
1.如果我在git add 后想要撤销操作,该怎么做? 使用 git rm --cache [文件名/ *] 或者 git reset HEAD, 为什么这个命令也会有效果呢,实际上reset将 HE ...
- Docker: Error response from daemon: Get.........unauthorized: incorrect username or password
今天在Centos中使用docker拉取redis镜像时报Error response from daemon: Get https://registry-1.docker.io/v2/library ...
- eslint webpack2 vue-loader配置
eslint是一个代码检测工具 官网如下http://eslint.cn/ npm install eslint --save-dev 需要这几个npm包: eslint eslint-loader ...
- markdown简明语法1
目录 Cmd Markdown 简明语法手册 1. 斜体和粗体 2. 分级标题 3. 外链接 4. 无序列表 5. 有序列表 6. 文字引用 7. 行内代码块 8. 代码块 9. 插入图像 Cmd M ...
- 2020ubuntu1804server编译安装redis笔记(三)启动服务和使用redis
第一篇笔记记录了ubuntu1804server编译安装redis5,接下来要配置redis5了 网址:https://www.cnblogs.com/qumogu/p/12435694.html 第 ...
- 大型Java进阶专题(四) 设计模式之工厂模式
前言 今天开始我们专题的第三课了,开始对设计模式进行讲解,本章节介绍:了解设计模式的由来,介绍设计模式能帮我们解决那些问题以及剖析工厂模式的历史由来及应用场景.本章节参考资料书籍<Sprin ...