AMBARI部署HADOOP集群(4)
通过 Ambari 部署 hadoop 集群
1. 打开 http://192.168.242.181:8080 登陆的用户名/密码是 : admin/admin
2. 点击 “LAUNCH INSTALL WIZARD”,开始创建一个集群
3. 为集群取一个名字
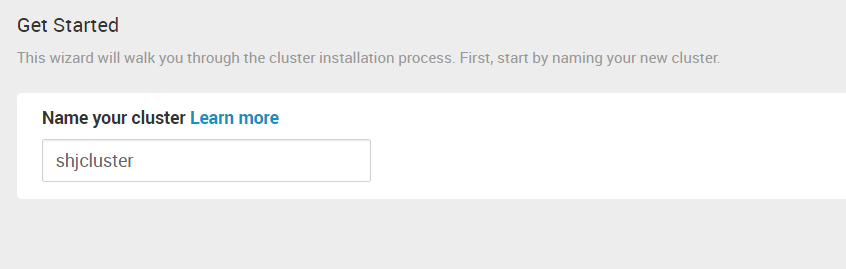
4. 前面我们建了本地的资源库,这里选择 “Use Local Repository”。删除其它的 OS,只留 redhat7 那一行。并且在 Base URL 那一列里填入前面搭建的 web 服务对应的地址。
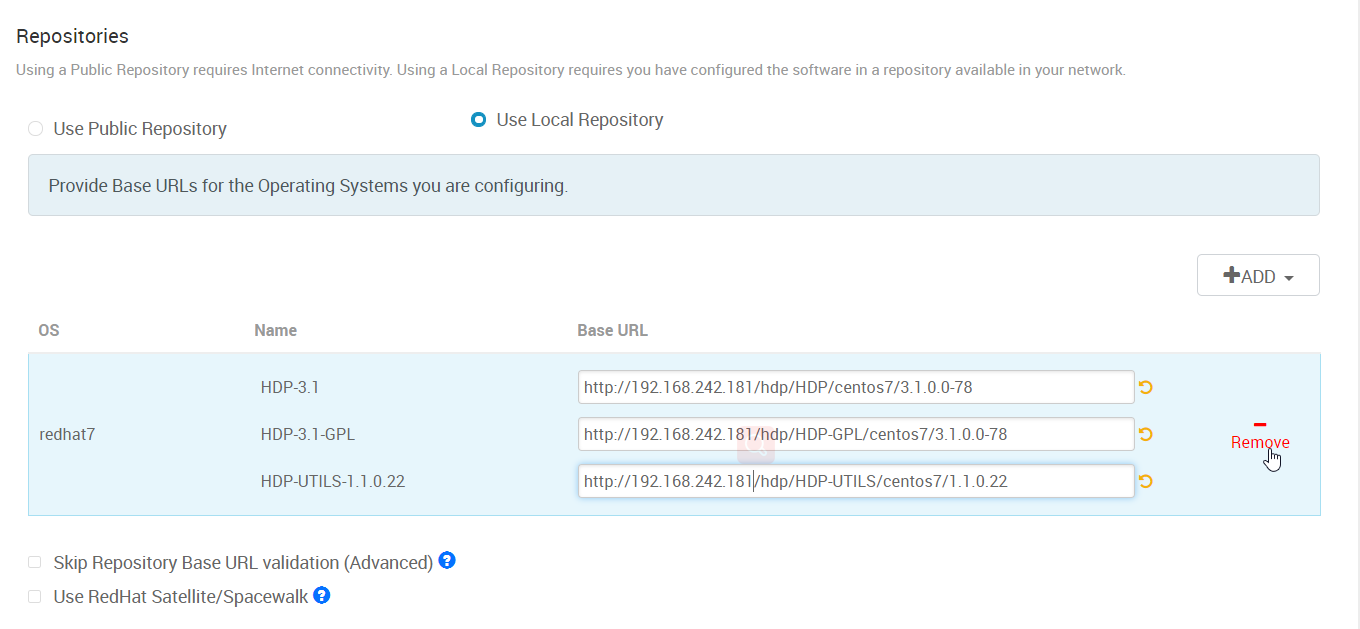
5. 在 “Target Hosts” 里填入 hadoop 集群需要部署到哪些机器。可以填 IP。
SSH Private Key 里选择的文件是 从零开始安装 Ambari (1) -- 安装前的准备工作 中配置免密登陆到其它机器的那台机器的 id_rsa 这个文件(ambari主机)。我用的是 root 帐号,所以这个文件是在 /root/.ssh/ 目录下。
6. “Confirm Hosts” 这一步,ambari 会在上面的配置的 hosts 中安装 ambari agent,只需等待即可。
7. 根据需要,选择服务。如果某些服务依赖其它服务,而没有选择依赖的服务的话,点击“Next”时,会做相应的提示。
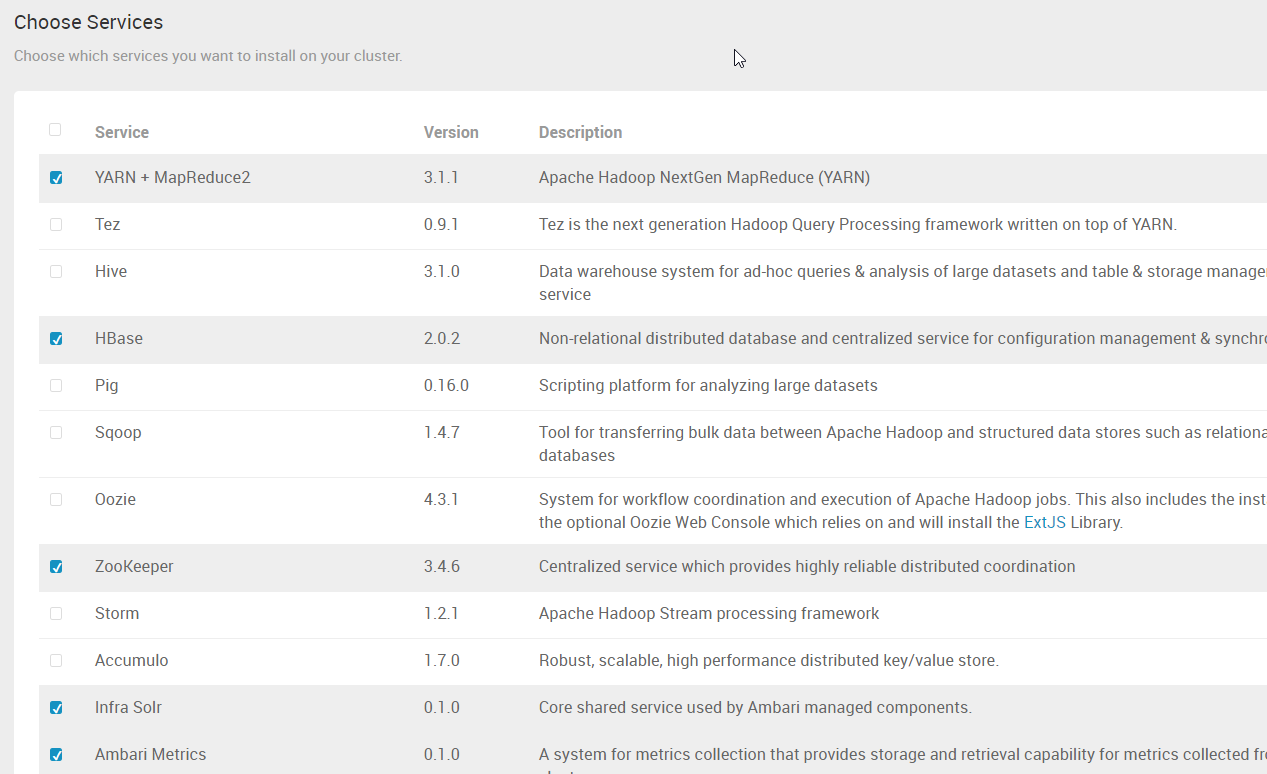
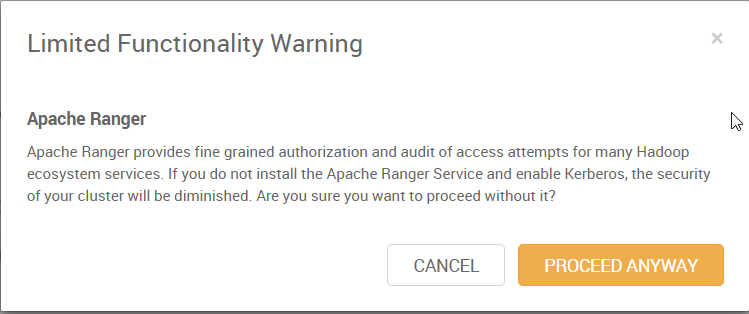
8. 点击 “Next”,如果出现类似下面的警告的话,可以不用管,后续如果需要的话,可以再安装
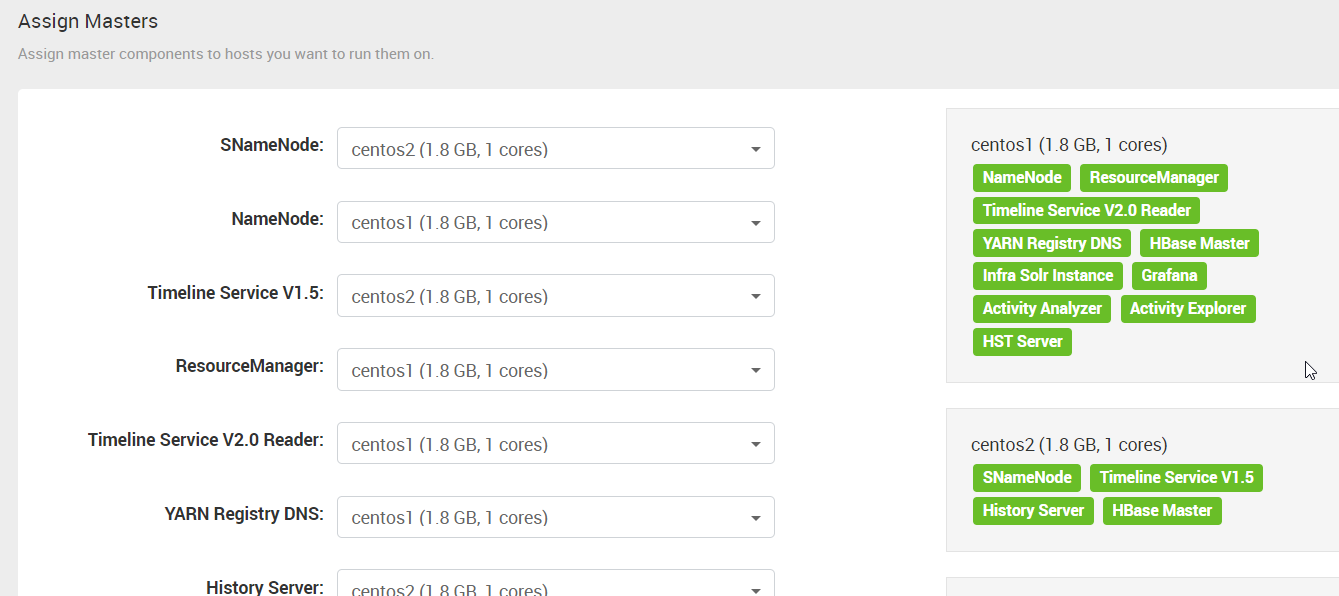
9. “Assign Masters” 这一步,ambari 会自动分配各种服务到不同的机器上。可以手动进行调整。
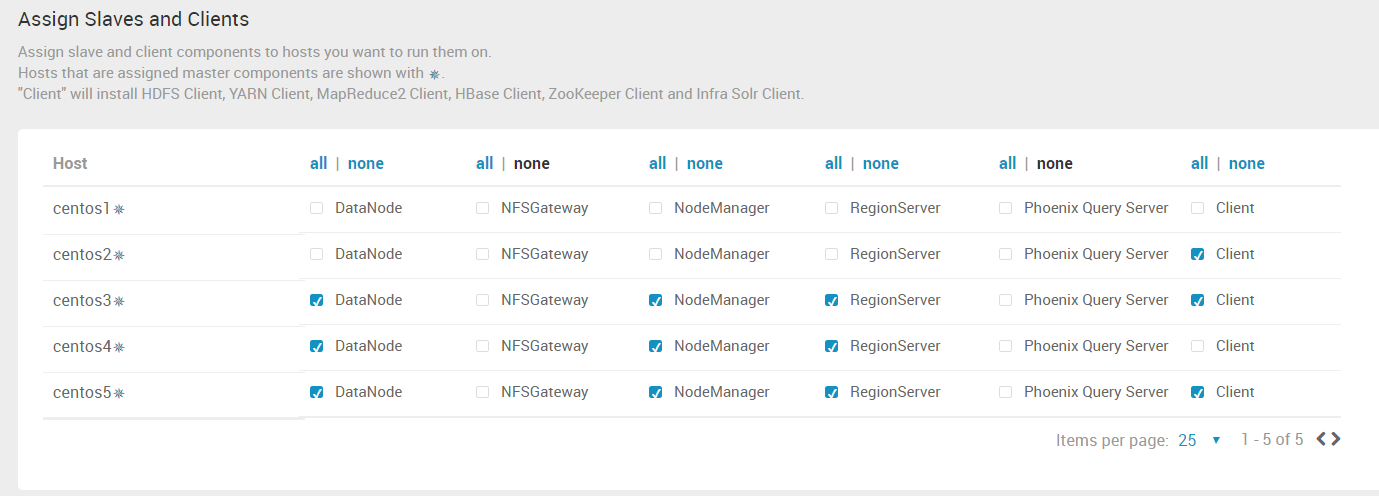
10. “Assign Slaves and Clients” 这一步,手动分配 Hadoop 的 DataNode 节点位置,YARN 的 NodeManager 的位置......
其中 NFSGateway 是通过挂载的方式,像访问本地文件系统一样访问 Hadoop 的文件系统。
Phoenix Query Server 是一个HBase的开源SQL引擎。你可以使用标准的JDBC API代替HBase客户端API来创建表,插入数据,查询你的HBase数据。
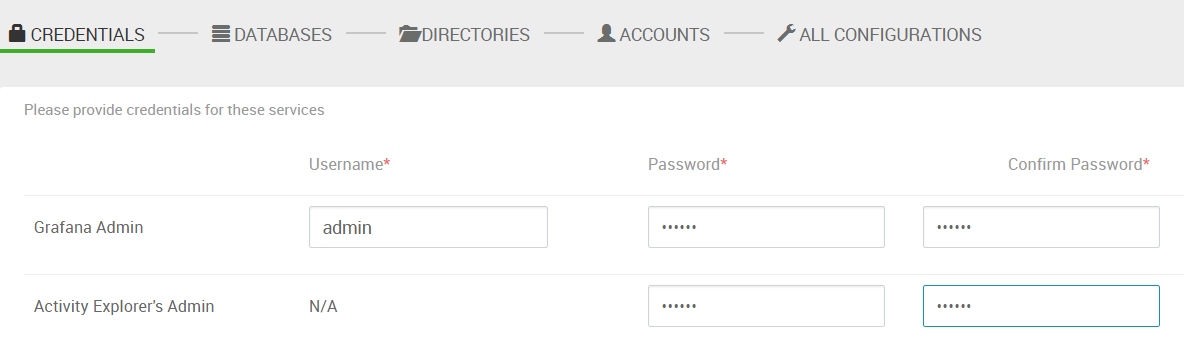
11. 设置密码。(有一行的 username 是 N/A,比较奇怪,不知道用在哪)
12. 数据库配置。如果选择了安装 hive 或 Ranger,需要输入相关的数据库的信息。此例中没有这一步。
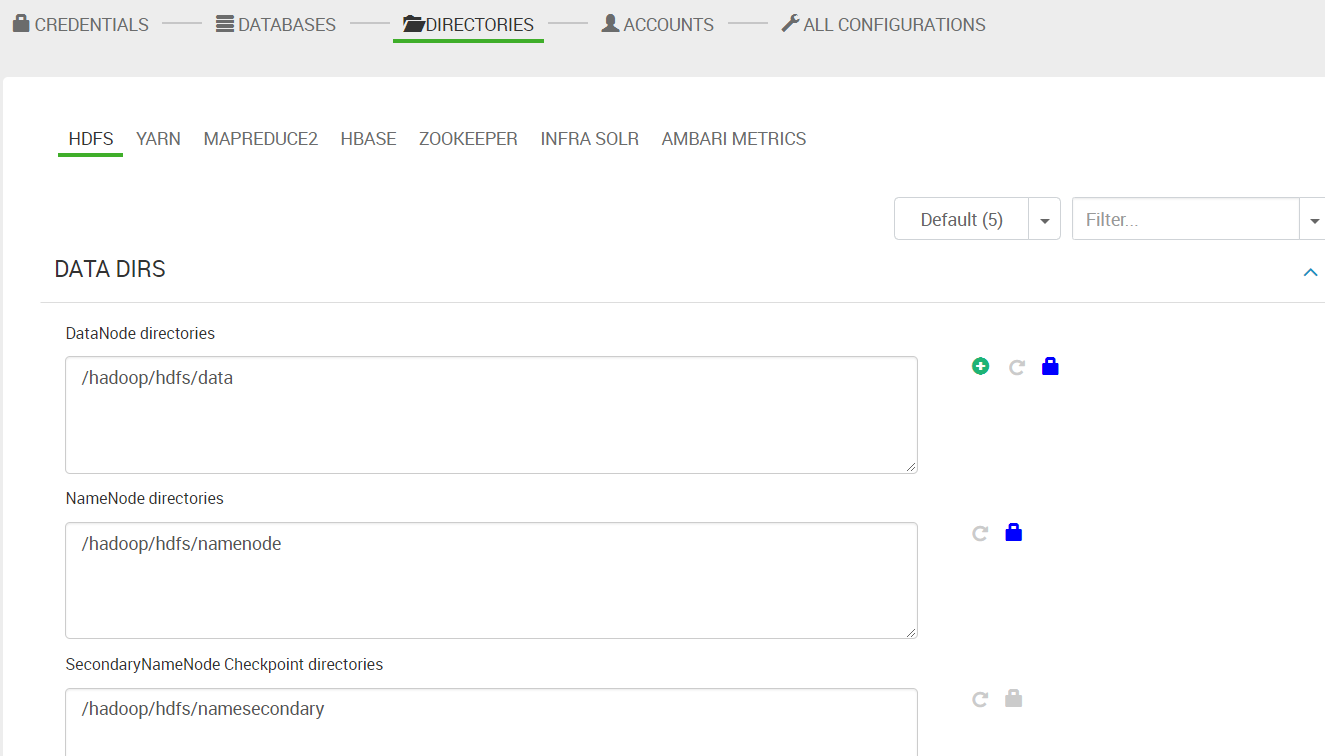
13. 目录配置。配置各个服务需要用到的目录。使用默认值即可。
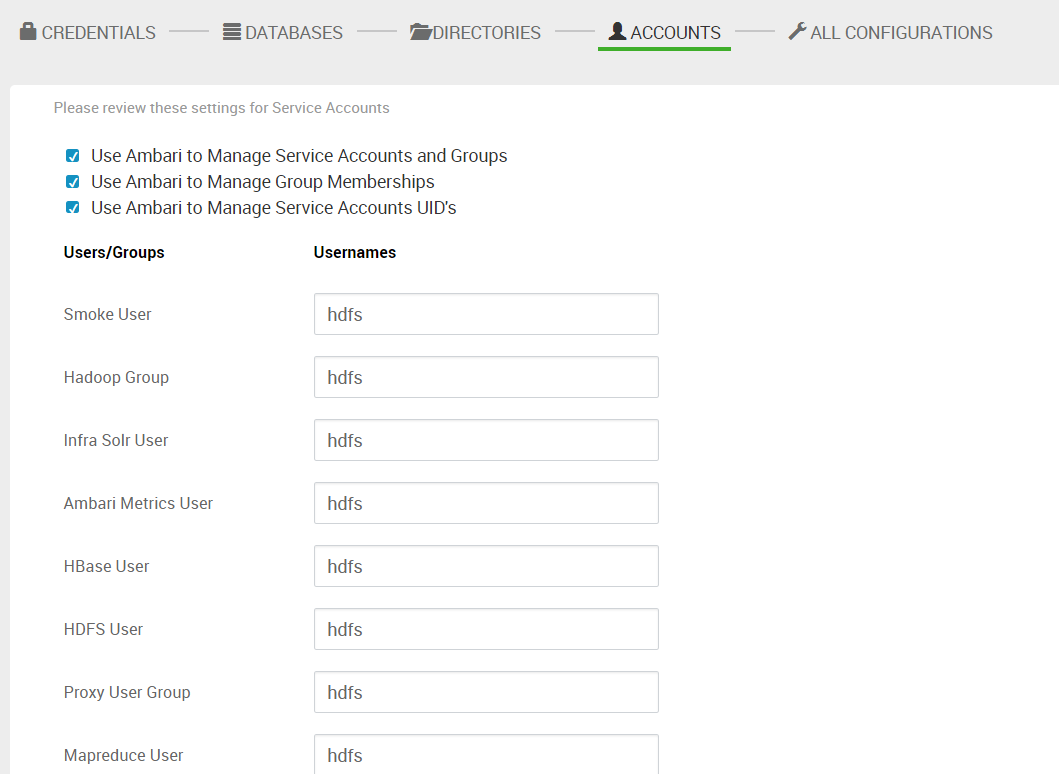
14. 创建用户。默认情况下, ambari 会为每个服务创建一个 linux 的用户,用不同的用户启动不同的服务。我设成了同一个用户。
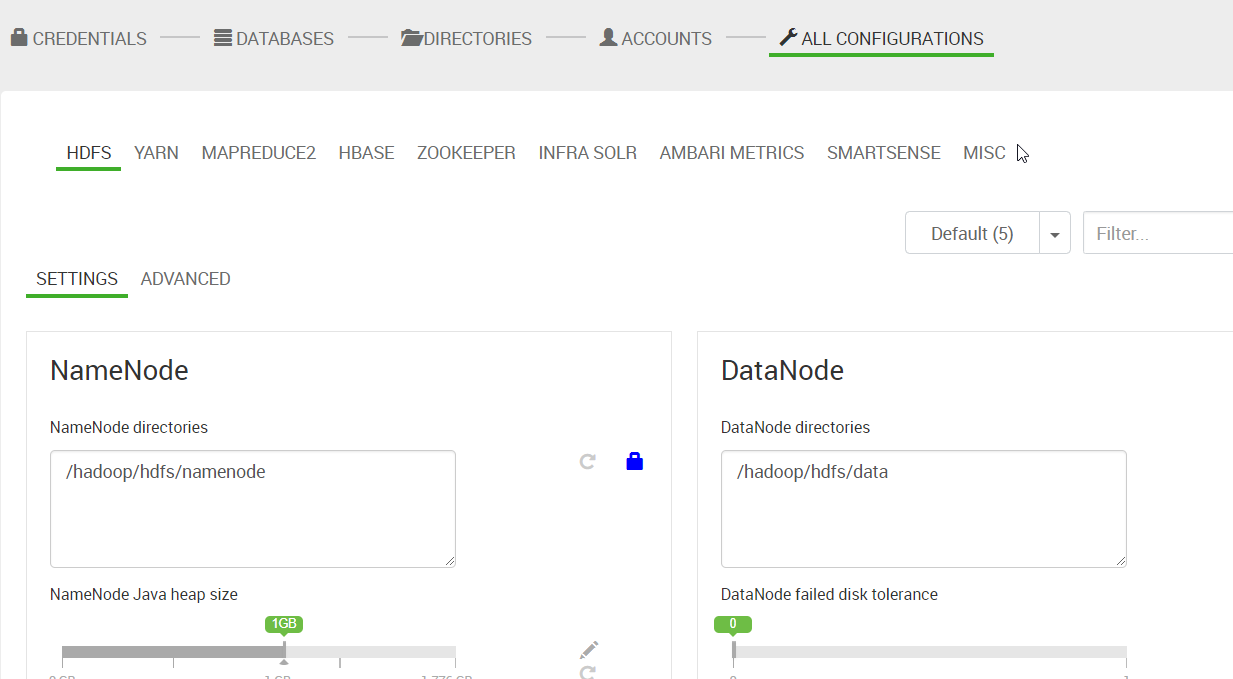
15. “ALL CONFIGURATIONS”,这一步可以修改前面的一些配置
16. 点击 “Next”后,出现总结页。可以下载创建这个集群的元数据信息。点击 “DEPLOY” 后,就开始部署了。
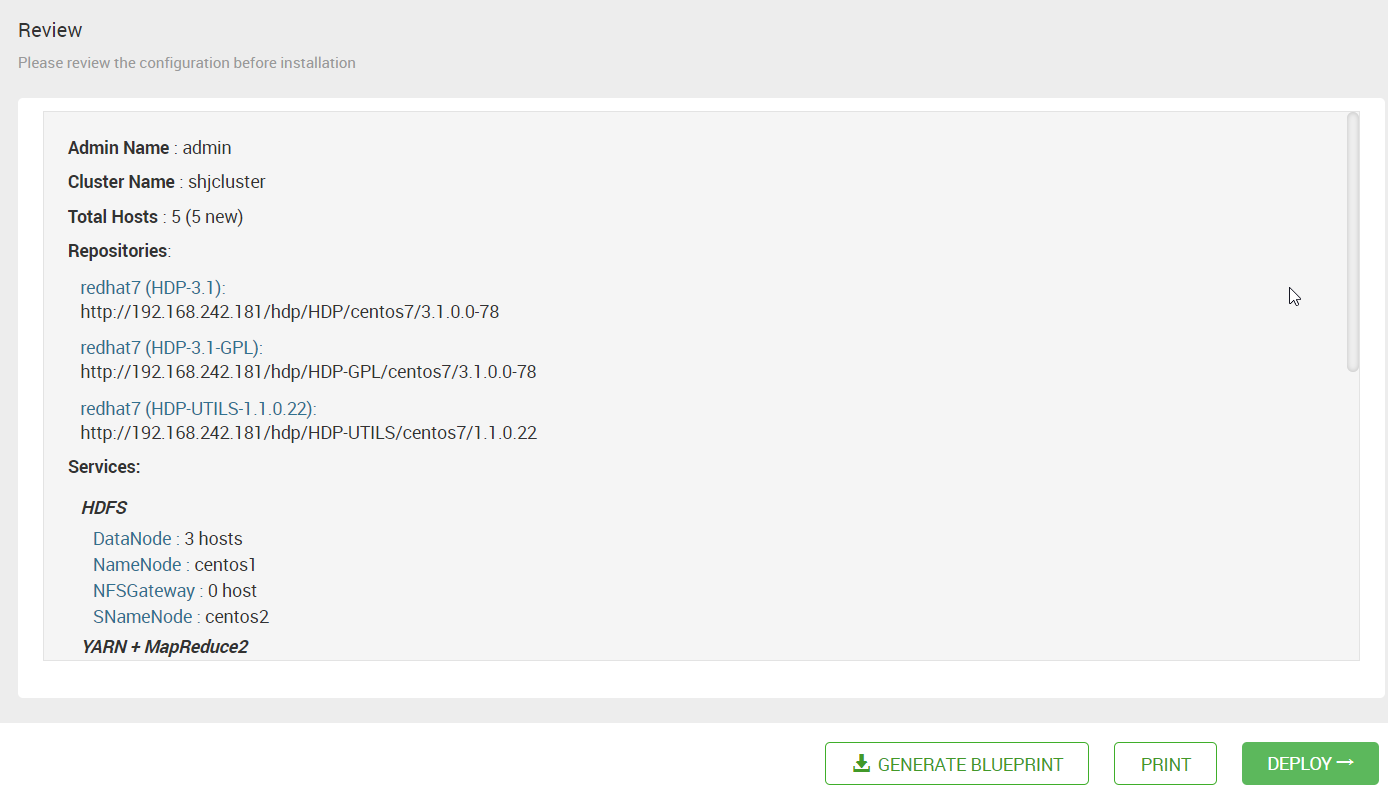
17. 效果展示。
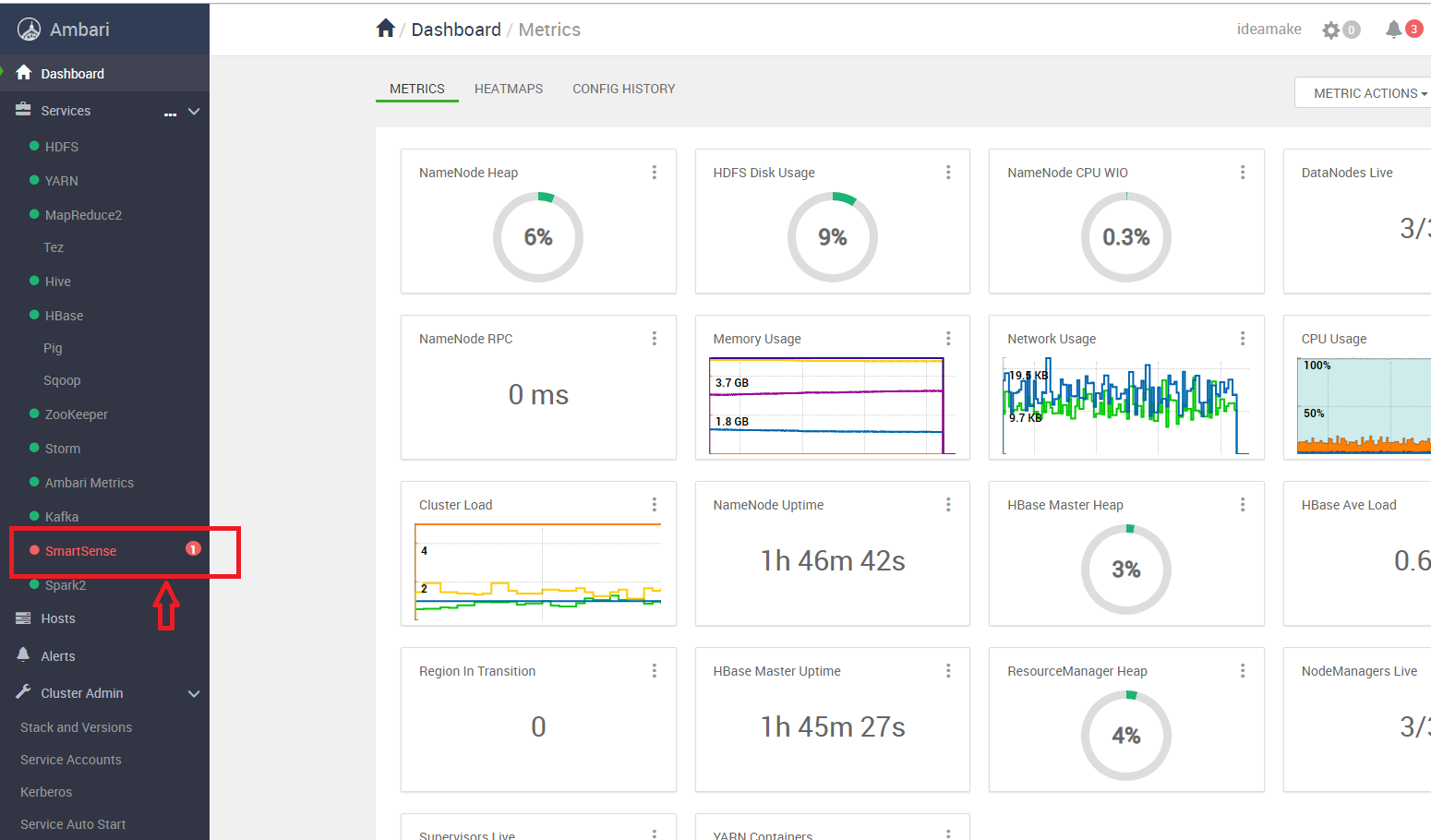
此时SmartSense有报错,
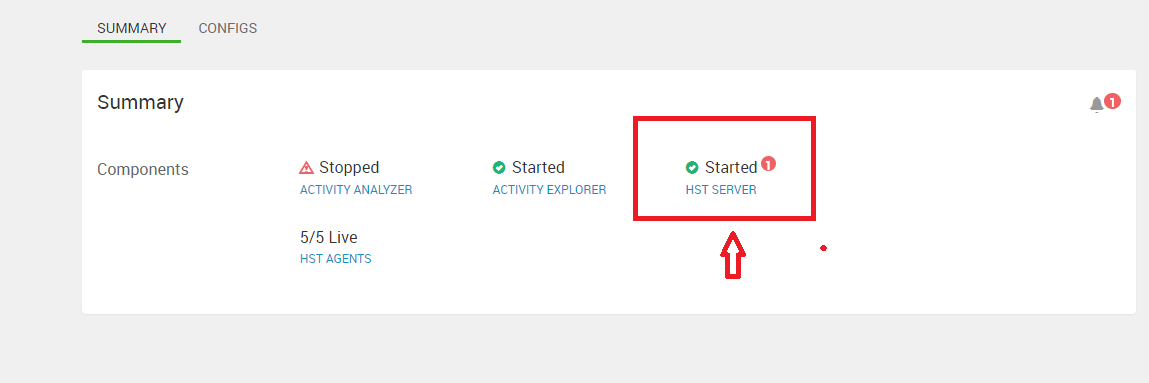
这是HST SERVER未安装,HST是ambari的收费子项目,安装在集群子节点,用于集群整体的性能反馈调优。这里没有安装,如何需要安装,可单独进行。
AMBARI部署HADOOP集群(4)的更多相关文章
- ambari部署Hadoop集群(2)
准备本地 repository 1. 下载下面的包 wget http://public-repo-1.hortonworks.com/ambari/centos7/2.x/updates/2.7.3 ...
- 使用Ambari部署hadoop集群
准备工作 1. 设置sudo免密码登陆 由于CentOS安装之后,普通用户无sudo权限,故应该设置sudo权限. 参考文章:http://www.cnblogs.com/maybob/p/32988 ...
- 从零开始安装 Ambari (4) -- 通过 Ambari 部署 hadoop 集群
1. 打开 http://192.168.242.181:8080 登陆的用户名/密码是 : admin/admin 2. 点击 “LAUNCH INSTALL WIZARD”,开始创建一个集群 3 ...
- ambari部署Hadoop集群(1)
本例使用hortonworks 提供了 ambari 的安装方法,而且还很详细.以下是在 centos7 上的安装步骤. 基础配置: 1. 修改电脑的主机名 hostnamectl set-hostn ...
- AMBARI部署HADOOP集群(3)
1. 安装ambari-server yum -y install ambari-server 2. ambari server 需要一个数据库存储元数据,默认使用的 Postgres 数据库.默认的 ...
- 手把手教你通过Ambari新建Hadoop集群图解案例
手把手教你通过Ambari新建Hadoop集群图解案例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 登陆系统之后,会看到Ambari空空如也的欢迎界面,接下来我们就需要介绍如何通 ...
- 通过ambari安装hadoop集群,ZT
通过ambari安装hadoop集群,ZT http://www.cnblogs.com/cenyuhai/p/3295635.html http://www.cnblogs.com/cenyuhai ...
- Docker部署Hadoop集群
Docker部署Hadoop集群 2016-09-27 杜亦舒 前几天写了文章"Hadoop 集群搭建"之后,一个朋友留言说希望介绍下如何使用Docker部署,这个建议很好,Doc ...
- 如何部署hadoop集群
假设我们有三台服务器,他们的角色我们做如下划分: 10.96.21.120 master 10.96.21.119 slave1 10.96.21.121 slave2 接下来我们按照这个配置来部署h ...
随机推荐
- SVN主从备份
SVN主从备份 两套环境:192.168.67.63(主SVN) 192.168.67.60(从SVN) 1.主环境上已经装好SVN并且存在数据仓库/home/svndata在从环境上,新建一/hom ...
- payload免杀之Installutil.exe&csc.exe利用
0x00 前言 C#的在Windows平台下的编译器名称是Csc.exe.Installutil.exe工具是一个命令行实用程序,允许您通过执行指定程序集中的安装程序组件来安装和卸载服务器资源,可以执 ...
- netfilter/iptables全攻略
转:http://www.linuxso.com/linuxpeixun/10332.html 内容简介防火墙的概述iptables简介iptables基础iptables语法iptables实例案例 ...
- weakref:对象的弱引用
介绍 weakref支持对象的弱引用,正常的引用会增加对象的引用计数,并避免它被垃圾回收.但结果并不是总和期望的那样,比如有时候可能会出现一个循环引用,或者有时候需要内存时可能要删除对象的缓存.而弱引 ...
- XML基础介绍【一】
XML基础介绍[一] 1.XML简介(Extensible Markup Language)[可扩展标记语言] XML全称为Extensible Markup Language, 意思是可扩展的标记语 ...
- 四、Attribute(2)授权角色过滤器
一.授权过滤器 1.新建一个mvc 项目 2.首先创建一个过滤器 MyAuthorizeAttribute 继承AuthorizeAttribute,并重写 AuthorizeCore public ...
- 8.3.ZooKeeper集群安装配置
1.Zookeeper的搭建方式 Zookeeper安装方式有三种,单机模式和集群模式以及伪集群模式. 单机模式:Zookeeper只运行在一台服务器上,适合测试环境: 伪集群模式:就是在一台物理机上 ...
- Nginx中虚拟主机配置
一.Nginx中虚拟主机配置 1.基于域名的虚拟主机配置 1.修改宿主机的hosts文件(系统盘/windows/system32/driver/etc/HOSTS) linux : vim /etc ...
- 解决docker容器的窗口大小问题
解决docker容器的窗口大小问题 最近哥们在是使用docker时,发现有些容器内部窗口大小有问题. 如下午所示,vi窗口只占据左上角一部分.正常情况下vi应该铺满整个窗口才对呀. 所以哥们找到了解决 ...
- Summer training #9
A:树形DP 给出一棵树,但是它的边是有向边,选择一个城市,问最少调整多少条边的方向能使一个选中城市可以到达所有的点,输出最小的调整的边数,和对应的点 要改变的边的权值为1,不需要改变的边的权值为0, ...