[Feature] Build pipeline
准备数据集
一、数据集
Ref: 6. Dataset loading utilities【各种数据集选项】
第一部分,加载原始iris数据集的数据;
第二部分,先增加一行,再增加一列;
- #%% part one.
- from sklearn.datasets import load_iris
- iris = load_iris()
- iris.data
- iris.target
- print(type(iris.data))
- print(type(iris.target))
- print()
- preview_line = 5
- print("data X is: \n{}".format(iris.data[:preview_line]))
- print("data Y is: \n{}".format(iris.target[:preview_line]))
#%% part two- from numpy import hstack, vstack, array, median, nan
- from numpy.random import choice
##########################################################################################- # 1.特征矩阵加工
- # 1.1.1 使用vstack增加一行含缺失值的样本(nan, nan, nan, nan), reshape相当于升维度
- nan_tmp = array([nan, nan, nan, nan]).reshape(1,-1)
- print(nan_tmp)
- # 1.1.2 合并两个array
- iris.data = vstack((iris.data, array([nan, nan, nan, nan]).reshape(1,-1)))
- # 1.2.1 使用hstack增加一列表示花的颜色(0-白、1-黄、2-红),花的颜色是随机的,意味着颜色并不影响花的分类
- random_feature = choice([0, 1, 2], size=iris.data.shape[0]).reshape(-1,1)
- # 1.2.2 合并两个array
- iris.data = hstack((random_feature, iris.data))
- preview_line = 5
- print("data X is: \n{}".format(iris.data[:preview_line]))
##########################################################################################- # 2 目标值向量加工
- # 2.1 增加一个目标值,对应含缺失值的样本,值为众数
- iris.target = hstack((iris.target, array([median(iris.target)])))
另一个写法版本,编辑器友好,但读者不友好。
- # Edit data
- iris.data = np.hstack((np.random.choice([0, 1, 2], size=iris.data.shape[0]+1).reshape(-1,1), np.vstack((iris.data, np.full(4, np.nan).reshape(1,-1)))))
- iris.target = np.hstack((iris.target, np.array([np.median(iris.target)])))
串行、并行流
一、串行结合并行流
有若干知识点:FeatureUnion, fit, transform, pipeline。
大概的思路是:
(1)先构建FeatureUnion,找到合适的features.
(2)再利用这些features进一步地做分类、拟合或者聚类。
- from sklearn.pipeline import Pipeline, FeatureUnion
- from sklearn.model_selection import GridSearchCV
- from sklearn.svm import SVC
- from sklearn.datasets import load_iris
- from sklearn.decomposition import PCA
- from sklearn.feature_selection import SelectKBest
- iris = load_iris()
- X, y = iris.data, iris.target
#############################################################################- # This dataset is way too high-dimensional. Better do PCA:
- pca = PCA(n_components=2)
- # 可以依据“相关性”对特征进行选择,保留k个评分最高的特征。
selection = SelectKBest(k=1)
- # Build estimator from PCA and Univariate selection:
- combined_features = FeatureUnion([("pca", pca), ("univ_select", selection)])
#############################################################################- # Use combined features to transform dataset:
- X_features = combined_features.fit(X, y).transform(X)
- print("Combined space has", X_features.shape[1], "features")
- svm = SVC(kernel="linear")
#############################################################################
# Do grid search over k, n_components and C:- pipeline = Pipeline([("features", combined_features), ("svm", svm)])
- #############################################################################
# pca, univ_select其实本来已设置,这里呢,可以设置“一组参数”, fit后找到最好的参数设置
param_grid = dict(features__pca__n_components=[1, 2, 3],- features__univ_select__k=[1, 2],
- svm__C=[0.1, 1, 10])
- grid_search = GridSearchCV(pipeline, param_grid=param_grid, cv=5, verbose=10)
- grid_search.fit(X, y)
- print(grid_search.best_estimator_)
二、串行 Pipeline
(a) Pipleline中最后一个之外的所有estimators都必须是变换器(transformers),最后一个estimator可以是任意类型(transformer,classifier,regresser)。
transformers --> transformers --> transformers --> ... --> transformer or classifier or regresser
(b) pipeline继承最后一个estimator的所有方法。带来两点好处:
1. 直接调用fit和predict方法来对pipeline中的所有算法模型进行训练和预测。
2. 可以结合 grid search 对参数进行选择。
继承了哪些方法呢,如下:
| 1 | transform | 依次执行各个学习器的transform方法; |
| 2 | inverse_transform | 依次执行各个学习器的inverse_transform方法; |
| 3 | fit | 依次对前n-1个学习器执行 fit 和 transform 方法,第n个学习器 (最后一个学习器) 执行fit方法; |
| 4 | predict | 执行第n个学习器的 predict方法; |
| 5 | score | 执行第n个学习器的 score方法; |
| 6 | set_params | 设置第n个学习器的参数; |
| 7 | get_param | 获取第n个学习器的参数; |
(c) 训练和预测时的串行工作流。
Ref: sklearn :Pipeline 与 FeatureUnion入门指南
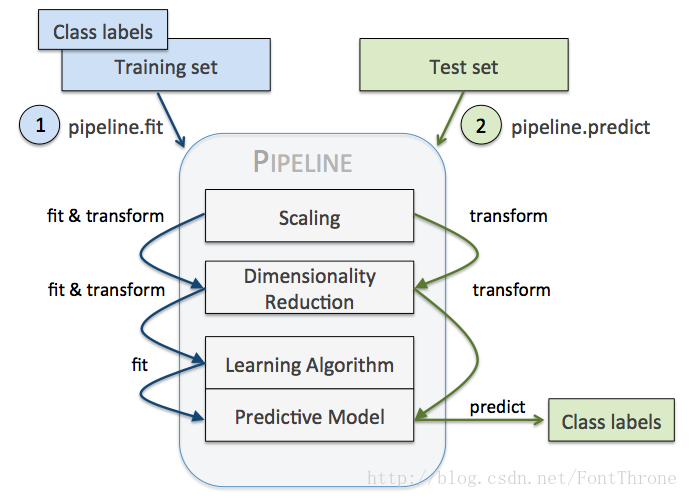
(d) 改变pipeline的参数:set_params
- from sklearn.pipeline import Pipeline
- from sklearn.preprocessing import StandardScaler
- from sklearn.svm import SVC
- from sklearn.decomposition import PCA
- from sklearn.datasets import load_iris
- iris=load_iris()
- pipe=Pipeline([('sc', StandardScaler()), ('pca',PCA()),('svc',SVC())])
- #例如‘sc’是StandardScaler()的简称,亦或者是代称
- pipe.set_params(sc__copy=False)
- #改变参数的格式为 学习器简称__该学习器对应参数名=参数值
- pipe.fit(iris.data, iris.target)
该参数后,能看到pipeline类中的子函数的对应的参数也变了。
- #可以看到sc中的copy确实由true改为false
- Pipeline(memory=None,
- steps=[('sc', StandardScaler(copy=False, with_mean=True, with_std=True)), ('pca', PCA(copy=True, iterated_power='auto', n_components=None, random_state=None,
- svd_solver='auto', tol=0.0, whiten=False)), ('svc', SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
- decision_function_shape='ovr', degree=3, gamma='auto_deprecated',
- kernel='rbf', max_iter=-1, probability=False, random_state=None,
- shrinking=True, tol=0.001, verbose=False))])
三、并行 FeatureUnion
特征联合 FeatureUnion 是个啥?与pipeline有啥区别?
- pipeline相当于feature串行处理,后一个transformer处理前一个transformer的feature结果;
- featureunion相当于feature的并行处理,将所有transformer的处理结果拼接成大的feature vector。
FeatureUnion提供了两种服务:
- Convenience: 你只需调用一次fit和transform就可以在数据集上训练一组estimators。
- Joint parameter selection: 可以把grid search用在FeatureUnion中所有的estimators的参数组合上面。
从如下例子可见:PCA和KernelPCA是同一个等级的 estimator,自然是使用 “并行” 策略。
例子一:
- from sklearn.pipeline import FeatureUnion
- from sklearn.decomposition import PCA # transformer
- from sklearn.decomposition import KernelPCA # transformer
- estimators = [('linear_pca',PCA()),('kernel_pca',KernelPCA())]
- combined = FeatureUnion(estimators)
- print(combined)
- #FeatureUnion(n_jobs=1, transformer_list=[('linear_pca', PCA(copy=True, iterated_power='auto', n_components=None, random_state=None, svd_solver='auto', tol=0.0, whiten=False)), ('kernel_pca', KernelPCA(alpha=1.0, coef0=1, copy_X=True, degree=3, eigen_solver='auto', fit_inverse_transform=False, gamma=None, kernel='linear', kernel_params=None, max_iter=None, n_components=None, n_jobs=1, random_state=None, remove_zero_eig=False, tol=0))],transformer_weights=None)
例子二:
- from numpy import log1p
- from sklearn.preprocessing import FunctionTransformer # transformer
- from sklearn.preprocessing import Binarizer # transformer
- from sklearn.pipeline import FeatureUnion
- # 新建将整体特征矩阵进行对数函数转换的对象。
- step2_1 = ('ToLog', FunctionTransformer(log1p))
- # 新建将整体特征矩阵进行二值化类的对象。
- step2_2 = ('ToBinary', Binarizer())
- # 新建整体并行处理对象。
- # 该对象也有fit和transform方法,fit和transform方法均是并行地调用需要并行处理的对象的fit和transform方法。
- # 参数transformer_list为需要并行处理的对象列表,该列表为二元组列表,第一元为对象的名称,第二元为对象。
- step2 = ('FeatureUnion', FeatureUnion(transformer_list=[step2_1, step2_2]))
知识点:FunctionTransformer(log1p) 基于对数函数
把原始数据取对数后进一步处理。之所以这样做是基于对数函数在其定义域内是单调增函数,取对数后不会改变数据的相对关系。
1. 缩小数据的绝对数值,方便计算。
2. 取对数后,可以将乘法计算转换称加法计算。
3. 某些情况下,在数据的整个值域中的在不同区间的差异带来的影响不同。
4. 取对数之后不会改变数据的性质和相关关系,但压缩了变量的尺度,例如800/200=4, 但log800/log200=1.2616,数据更加平稳,也消弱了模型的共线性、异方差性等。
5. 所得到的数据易消除异方差问题。
6. 在经济学中,常取自然对数再做回归,这时回归方程为 lnY=a lnX+b ,两边同时对X求导,1/Y*(DY/DX) = a*1/X, b = (DY/DX)*(X/Y) = (DY*X)/(DX*Y) = (DY/Y)/(DX/X) 这正好是弹性的定义。
知识点:Binarizer() 二值化特征
使用的是歌曲的数据:对歌曲听过的次数做二值化操作,听过大于等于1的次数的设置为1,否者设置为0。
- import numpy as np
- import matplotlib.pyplot as plt
- import matplotlib as mpl
- import pandas as pd
- plt.style.reload_library()
- plt.style.use('classic')
- # 设置颜色
- mpl.rcParams['figure.facecolor'] = (1, 1, 1, 0)
- # 设置图形大小
- mpl.rcParams['figure.figsize'] = (6.0, 4.0)
- # 设置图形的分辨率
- mpl.rcParams['figure.dpi'] = 100
- popsong_df = pd.read_csv('datasets/song_views.csv', encoding='utf-8')
- # 我们对listen_count听歌的次数进行二值化操作, 听过的次数大于等于1的为1,次数为0的为0
- # 第一种方法
- # listened = popsong_df['listen_count'].copy()
- # listened[listened >= 1] = 1
- # popsong_df['listened'] = listened
- # print(popsong_df[['listen_count', 'listened']])
- # 第二种方法:使用 Binarizer
- from sklearn.preprocessing import Binarizer
- bin = Binarizer(threshold=0.9)
- popsong_df['listened'] = bin.transform( popsong_df['listen_count'].values.reshape(-1, 1) )
- print(popsong_df[['listen_count', 'listened']].iloc[:10])
在这里,为了满足 .transform() 的要求,参数需通过 reshape 变为 “小列表” 元素的形式。
- In [12]: df['score'].values
- Out[12]: array([1, 4])
- In [13]: df['score'].values.reshape(-1,1) # 需要这个形式,然后给 bin.transform
- Out[13]:
- array([[1],
- [4]])
四、"部分并行”处理
使用需求
整体并行处理有其缺陷,在一些场景下,我们只需要对特征矩阵的某些列进行转换,而不是所有列。
pipeline并没有提供相应的类(仅OneHotEncoder类实现了该功能),需要我们在FeatureUnion的基础上进行优化。
使用方法
(1) 这里自定义并使用了 FeatureUnionExt(...) 函数接口,用起来比较方便。
- from numpy import log1p
- from sklearn.preprocessing import OneHotEncoder
- from sklearn.preprocessing import FunctionTransformer
- from sklearn.preprocessing import Binarizer
- #新建将部分特征矩阵进行定性特征编码的对象
- step2_1 = ('OneHotEncoder', OneHotEncoder(sparse=False))
- #新建将部分特征矩阵进行对数函数转换的对象
- step2_2 = ('ToLog', FunctionTransformer(log1p))
- #新建将部分特征矩阵进行二值化类的对象
- step2_3 = ('ToBinary', Binarizer())
- #新建部分并行处理对象
- #参数transformer_list为需要并行处理的对象列表,该列表为二元组列表,第一元为对象的名称,第二元为对象
- #参数idx_list为相应的需要读取的特征矩阵的列
- step2 = ('FeatureUnionExt', FeatureUnionExt(transformer_list=[step2_1, step2_2, step2_3], idx_list=[[0], [1, 2, 3], [4]]))
(2) 这里对 FeatureUnionExt(...) 函数接口 进行了实现,重点是使用了 Parallel方法。【实现使用的老版本,调试请参考github中新版本】
- from sklearn.pipeline import FeatureUnion, _fit_one_transformer, _fit_transform_one, _transform_one
- from sklearn.externals.joblib import Parallel, delayed
- from scipy import sparse
- import numpy as np
- # 部分并行处理,继承FeatureUnion
- class FeatureUnionExt(FeatureUnion):
- # 相比FeatureUnion,多了idx_list参数,其表示每个 "并行工作" 需要读取的特征矩阵的列。
- def __init__(self, transformer_list, idx_list, n_jobs=1, transformer_weights=None):
- self.idx_list = idx_list
- FeatureUnion.__init__(self, transformer_list=map(lambda trans:(trans[0], trans[1]), transformer_list), n_jobs=n_jobs, transformer_weights=transformer_weights)
- # 由于只部分读取特征矩阵,方法fit_transform需要重构
- def fit_transform(self, X, y=None, **fit_params):
- transformer_idx_list = map(lambda trans, idx:(trans[0], trans[1], idx), self.transformer_list, self.idx_list)
- result = Parallel(n_jobs=self.n_jobs)(
- #从特征矩阵中提取部分输入fit_transform方法
- delayed(_fit_transform_one)(trans, name, X[:,idx], y,
- self.transformer_weights, **fit_params)
- for name, trans, idx in transformer_idx_list)
- Xs, transformers = zip(*result)
- self._update_transformer_list(transformers)
- if any(sparse.issparse(f) for f in Xs):
- Xs = sparse.hstack(Xs).tocsr()
- else:
- Xs = np.hstack(Xs)
- return Xs
- ... 其他代码,略
五、流水线处理
- from numpy import log1p
- from sklearn.preprocessing import Imputer
- from sklearn.preprocessing import OneHotEncoder
- from sklearn.preprocessing import FunctionTransformer
- from sklearn.preprocessing import Binarizer
- from sklearn.preprocessing import MinMaxScaler
- from sklearn.feature_selection import SelectKBest
- from sklearn.feature_selection import chi2
- from sklearn.decomposition import PCA
- from sklearn.linear_model import LogisticRegression
- from sklearn.pipeline import Pipeline
- #新建计算缺失值的对象
- step1 = ('Imputer', Imputer())
- #新建将部分特征矩阵进行定性特征编码的对象
- step2_1 = ('OneHotEncoder', OneHotEncoder(sparse=False))
- #新建将部分特征矩阵进行对数函数转换的对象
- step2_2 = ('ToLog', FunctionTransformer(log1p))
- #新建将部分特征矩阵进行二值化类的对象
- step2_3 = ('ToBinary', Binarizer())
#新建部分并行处理对象,返回值为每个并行工作的输出的合并- step2 = ('FeatureUnionExt', FeatureUnionExt(transformer_list=[step2_1, step2_2, step2_3], idx_list=[[0], [1, 2, 3], [4]]))
- #新建无量纲化对象
- step3 = ('MinMaxScaler', MinMaxScaler())
- #新建卡方校验选择特征的对象
- step4 = ('SelectKBest', SelectKBest(chi2, k=3))
- #新建PCA降维的对象
- step5 = ('PCA', PCA(n_components=2))
- #新建逻辑回归的对象,其为待训练的模型作为流水线的最后一步
- step6 = ('LogisticRegression', LogisticRegression(penalty='l2'))
- #新建流水线处理对象
- #参数steps为需要流水线处理的对象列表,该列表为二元组列表,第一元为对象的名称,第二元为对象
- pipeline = Pipeline(steps=[step1, step2, step3, step4, step5, step6])
自动化调参
一、自动化调参
通过GridSearchCV函数接口,对比不同结果,找到最棒的参数设置【可能会出现Runtime Error】
- from sklearn.grid_search import GridSearchCV
- #新建网格搜索对象
- #第一参数为待训练的模型
- #param_grid为待调参数组成的网格,字典格式,键为参数名称(格式“对象名称__子对象名称__参数名称”),值为可取的参数值列表
- grid_search = GridSearchCV(pipeline, param_grid={'FeatureUnionExt__ToBinary__threshold':[1.0, 2.0, 3.0, 4.0], 'LogisticRegression__C':[0.1, 0.2, 0.4, 0.8]})
- #训练以及调参
- grid_search.fit(iris.data, iris.target)
Ref: sklearn :Pipeline 与 FeatureUnion入门指南【代码可运行】
- # Author: Andreas Mueller <amueller@ais.uni-bonn.de>
- #
- # License: BSD 3 clause
- from sklearn.pipeline import Pipeline, FeatureUnion
- from sklearn.grid_search import GridSearchCV
- from sklearn.svm import SVC
- from sklearn.datasets import load_iris
- from sklearn.decomposition import PCA
- from sklearn.feature_selection import SelectKBest
- iris = load_iris()
- X, y = iris.data, iris.target
- # This dataset is way to high-dimensional. Better do PCA:
- pca = PCA(n_components=2)
- # Maybe some original features where good, too?
- selection = SelectKBest(k=1)
- # Build estimator from PCA and Univariate selection:
- combined_features = FeatureUnion([("pca", pca), ("univ_select", selection)])
- # Use combined features to transform dataset:
- X_features = combined_features.fit(X, y).transform(X)
- svm = SVC(kernel="linear")
- # Do grid search over k, n_components and C:
- pipeline = Pipeline([("features", combined_features), ("svm", svm)])
- param_grid = dict(features__pca__n_components=[1, 2, 3],
- features__univ_select__k=[1, 2],
- svm__C=[0.1, 1, 10])
- grid_search = GridSearchCV(pipeline, param_grid=param_grid, verbose=10)
- grid_search.fit(X, y)
- print(grid_search.best_estimator_)
运行时错误 RuntimeError
- $ python dm.py
- /usr/local/anaconda3/lib/python3.7/site-packages/sklearn/model_selection/_split.py:1978: FutureWarning: The default value of cv will change from 3 to 5 in version 0.22. Specify it explicitly to silence this warning.
- warnings.warn(CV_WARNING, FutureWarning)
- Traceback (most recent call last):
- File "dm.py", line 77, in <module>
- main()
- File "dm.py", line 70, in main
- datamining(iris, featureList)
- File "dm.py", line 36, in datamining
- grid_search.fit(iris.data, iris.target)
- File "/usr/local/anaconda3/lib/python3.7/site-packages/sklearn/model_selection/_search.py", line 632, in fit
- base_estimator = clone(self.estimator)
- File "/usr/local/anaconda3/lib/python3.7/site-packages/sklearn/base.py", line 64, in clone
- new_object_params[name] = clone(param, safe=False)
- File "/usr/local/anaconda3/lib/python3.7/site-packages/sklearn/base.py", line 52, in clone
- return estimator_type([clone(e, safe=safe) for e in estimator])
- File "/usr/local/anaconda3/lib/python3.7/site-packages/sklearn/base.py", line 52, in <listcomp>
- return estimator_type([clone(e, safe=safe) for e in estimator])
- File "/usr/local/anaconda3/lib/python3.7/site-packages/sklearn/base.py", line 52, in clone
- return estimator_type([clone(e, safe=safe) for e in estimator])
- File "/usr/local/anaconda3/lib/python3.7/site-packages/sklearn/base.py", line 52, in <listcomp>
- return estimator_type([clone(e, safe=safe) for e in estimator])
- File "/usr/local/anaconda3/lib/python3.7/site-packages/sklearn/base.py", line 75, in clone
- (estimator, name))
- RuntimeError: Cannot clone object FeatureUnionExt(idx_list=[[0], [1, 2, 3], [4]], n_jobs=1,
- transformer_list=[('OneHotEncoder',
- OneHotEncoder(categorical_features=None,
- categories=None, drop=None,
- dtype=<class 'numpy.float64'>,
- handle_unknown='error',
- n_values=None, sparse=False)),
- ('ToLog',
- FunctionTransformer(accept_sparse=False,
- check_inverse=True,
- func=<ufunc 'log1p'>,
- inv_kw_args=None,
- inverse_func=None,
- kw_args=None,
- pass_y='deprecated',
- validate=None)),
- ('ToBinary',
- Binarizer(copy=True, threshold=0.0))],
- transformer_weights=None), as the constructor either does not set or modifies parameter transformer_list
调参fit时报错
Error log来源;https://gplearn.readthedocs.io/en/stable/_modules/sklearn/base.html
模型保存
一、持久化
参考:[Python] 05 - Load data from Files
- #持久化数据
- # 第一个参数,为内存中的对象
- # 第二个参数,为保存在文件系统中的名称
- # 第三个参数,为压缩级别,0为不压缩,3为合适的压缩级别
- dump(grid_search, 'grid_search.dmp', compress=3)
- #从文件系统中加载数据到内存中
- grid_search = load('grid_search.dmp')
End.
End.
[Feature] Build pipeline的更多相关文章
- 聊聊2018.2的Scriptable Build Pipeline以及构建Assetbundle
0x00 前言 在这篇文章中,我们选择了过去几周Unity官方社区交流群以及UUG社区群中比较有代表性的几个问题,总结在这里和大家进行分享.主要涵盖了Scriptable Build Pipeline ...
- 使用 Build Pipeline View 插件图表展示Jenkins job依赖关系
使用 Build Pipeline View 查看Jenkins的Job的依赖关系图表 安装 Build Pipeline View 插件下载地址 下载后再jenkins的"插件管理&quo ...
- [Feature] Final pipeline: custom transformers
有视频:https://www.youtube.com/watch?v=BFaadIqWlAg 有代码:https://github.com/jem1031/pandas-pipelines-cust ...
- jenkins2 pipeline插件的10个最佳实践
jenkins pipeline的10个最佳实践. 文章来自:http://www.ciandcd.com文中的代码来自可以从github下载: https://github.com/ciandcd ...
- sklearn 中的 Pipeline 机制 和FeatureUnion
一.pipeline的用法 pipeline可以用于把多个estimators级联成一个estimator,这么 做的原因是考虑了数据处理过程中一系列前后相继的固定流程,比如feature selec ...
- [转] Jenkins Pipeline插件十大最佳实践
[From] http://blog.didispace.com/jenkins-pipeline-top-10-action/ Jenkins Pipeline 插件对于 Jenkins 用户来说可 ...
- 【转】jenkins插件pipeline使用介绍
摘要: pipeline字面意思就是流水线,将很多步骤按顺序排列好,做完一个执行下一个.下面简单介绍下如何使用该插件帮我们完成一些流水线型的任务 pipeline字面意思就是流水线,将很多步骤按顺序排 ...
- sklearn中pipeline的用法和FeatureUnion
一.pipeline的用法 pipeline可以用于把多个estimators级联成一个estimator,这么 做的原因是考虑了数据处理过程中一系列前后相继的固定流程,比如feature selec ...
- 9.Jenkins进阶之流水线pipeline基础使用实践(2)
目录一览: 0x01 基础实践 0x02 进阶实践 (1) Sonarqube 代码质量检测之 Pipeline Script from SCM (2) Gitlab 自动触发构建之 Pipeline ...
随机推荐
- C#DataGrid列值出现E形式的小数,将DataGrid表格上的数据保存至数据库表时会因格式转换不正确导致报错
问题描述:在DataGridView中调整金额一列,当输入小数0.000001后会显示1E-6,此时进行保存操作时报错,提示无法将string类型转换成Decimal 原因分析:由于列调整金额为1E- ...
- Codeforces 1187 G - Gang Up
G - Gang Up 思路: 每个点按时间拆点建边,然后跑最小费用流 一次走的人不能太多,假设每次走的人为k (k*k-(k-1)*(k-1))*d <= c+d k <= 24 代码: ...
- PEP8规范 Python
前言 从很多地方搬运+总结,以后根据这个标准再将python的一些奇技淫巧结合起来,写出更pythonic的代码~ PEP8 编码规范 英文原版请点击这里 以下是@bobo的整理,原文请见PEP8 P ...
- string::back
char& back(); const char& back() const; #include <iostream>#include <string> usi ...
- JSP常用标签
JSP常用标签可以理解为JSTL user:普通用户 admin:站点管理员 JSTL1.1.2下载地址:http://archive.apache.org/dist/jakarta/taglibs/ ...
- FFmpeg常用命令学习笔记(四)处理原始数据命令
处理原始数据命令 通过音视频设备采集的.没有经过任何加工的数据叫原始数据,而像我们平时播放的比如mp4文件是压缩后的数据.视频原始数据是YUV格式,音频原始数据是PCM格式.FFmpeg可以从封装格 ...
- redis四种部署方式
1.单点 2.主从 3.哨兵 4.集群
- springboot 项目报错问题的解决
报错如下: java.lang.IllegalStateException: Failed to load ApplicationContext at org.springframework.test ...
- [ZJOI2019]语言——树剖+树上差分+线段树合并
原题链接戳这儿 SOLUTION 考虑一种非常\(naive\)的统计方法,就是对于每一个点\(u\),我们维护它能到达的点集\(S_u\),最后答案就是\(\frac{\sum\limits_{i= ...
- 【luoguP1955 】[NOI2015]程序自动分析--普通并查集
题目描述 在实现程序自动分析的过程中,常常需要判定一些约束条件是否能被同时满足. 考虑一个约束满足问题的简化版本:假设x1,x2,x3...代表程序中出现的变量,给定n个形如xi=xj或xi≠xj的变 ...