hive元数据库理解
在hive2.1.1 里面一共有59张表
表1 VERSION
select * from VERSION limit ;
version表存hive的版本信息,该表中数据只有一条,如果存在多条,会造成hive启动不起来。
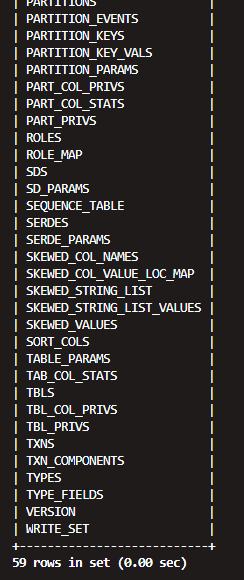
表2 DBS
select * from DBS;
DB_ID:数据库ID,DESC:数据库描述,DB_LOCATION_URI:数据HDFS路径,NAME:数据库名,OWNER_NAME:数据库所有者用户名,OWNER_TYPE:所有者角色。
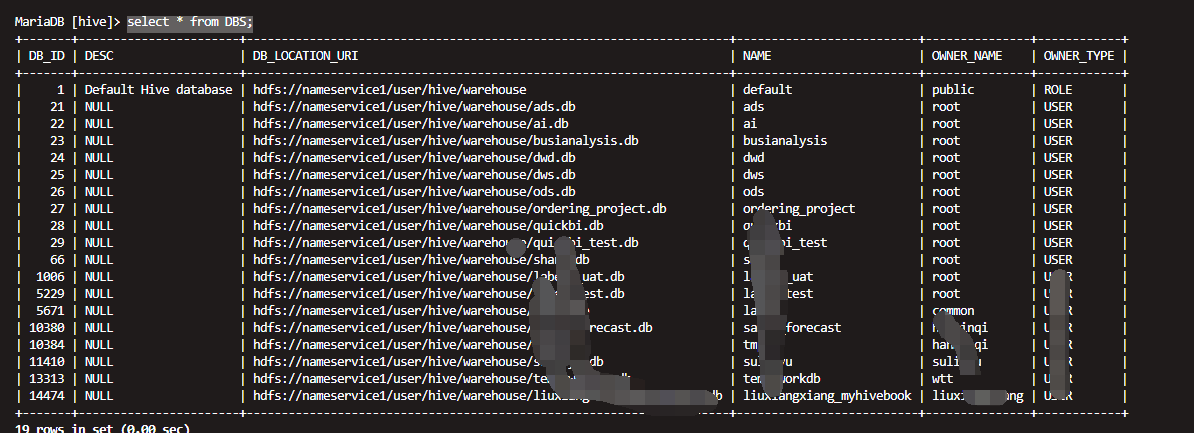
表3 DATABASE_PARAMS
select * from DATABASE_PARAMS
该表存储数据库的相关参数,在CREATE DATABASE时候用 WITH DBPROPERTIES (property_name=property_value, …)指定的参数。
表4 TBLS
select * from TBLS limit ;
bls表显示表的详细信息,tbl_id为主键,唯一表示该表,里面存放表的创建时间create_time,表所属的库id(DB_ID),表的拥有着(OWNER),SD_ID ,表的名称TBL_NAME,表的类型(TBL_TYPE)表示内部表还是外部表.

表5
select * from table_params

如表的最后一次ddl时间,表的注释,如果是非分区表还有该表对应着HDFS文件个数,大小.(通过TBL_ID 来关联表)
表6 TBL_PRIVS
select * from TBL_PRIVS
如表的最后一次ddl时间,表的注释,如果是非分区表还有该表对应着HDFS文件个数,大小

Hive文件存储信息相关的元数据表
SDS:
该表对应的文件存储的基本信息,如INPUT_FORMAT、OUTPUT_FORMAT、是否压缩等。TBLS表中的SD_ID与该表关联,可以获取Hive表的存储信息
SDS、SD_PARAMS、SERDES、SERDE_PARAMS,由于HDFS支持的文件格式很多,而建Hive表时候也可以指定各种文件格式,Hive在将HQL解析成MapReduce时候,需要知道去哪里,使用哪种格式去读写HDFS文件,而这些信息就保存在这几张表中.
hive元数据库理解的更多相关文章
- hive元数据库表分析及操作
在安装Hive时,需要在hive-site.xml文件中配置元数据相关信息.与传统关系型数据库不同的是,hive表中的数据都是保存的HDFS上,也就是说hive中的数据库.表.分区等都可以在HDFS找 ...
- hive 元数据库表描述
元数据库表描述 这一节描述hive元数据库中比较重要的一些表的作用,随着后续对hive的使用逐渐补充更多的内容. mysql元数据库hive中的表: 表名 作用 BUCKETING_COLS 存储bu ...
- hive 的理解
什么是Hive 转自: https://blog.csdn.net/qingqing7/article/details/79102691 1.Hive简介 Hive 是建立在 Hadoop 上的数据仓 ...
- Hive 元数据库表信息
Hive 的元数据信息通常存储在关系型数据库中,常用MySQL数据库作为元数据库管理. 1. 版本表 i) VERSION -- 查询版本信息 2. 数据库.文件存储相关 i) DBS -- 存储 ...
- 配置hive元数据库mysql时候出现 Unable to find the JDBC database jar on host : master
解决办法: cd /usr/share/java/,(没有java文件夹,自行创建)rz mysql-connector-java-***.jar,mv mysql-connector-java-* ...
- 【原创】大数据基础之Hive(4)hive元数据库核心表结构
1 dbs +-------+-----------------------+----------------------------------------------+------------+- ...
- hive 未初始化元数据库报错
启动hive-metastore和hive-server2 用beeline连接hive报错 [root@node04 hive]# beeline Beeline version 0.13.1-cd ...
- hive的简单理解--笔记
Hive的理解 数据仓库的工具 Hive仅仅是在hadoop上面包装了SQL: Hive的数据存储在hadoop上 Hive的计算由MR进行 Hive批量处理数据 Hive的特点 1 可扩展性(h ...
- Hive体系结构介绍
http://www.aboutyun.com/thread-6217-1-1.html 1.Hive架构与基本组成 下面是Hive的架构图. 图1.1 Hive体系结构 Hive ...
随机推荐
- CFS理论模型
参考资料:<调度器笔记>Kevin.Liu <Linux kernel development> <深入Linux内核架构> version: 2.6.32.9 下 ...
- JS判定数据类型
1.typeof 我们能够使用typeof判断变量的身份,判断字符串得到string,数字和NaN得到number,函数会得到function等,但是判断数组,对象和nu ...
- tensorflow二进制文件读取与tfrecords文件读取
1.知识点 """ TFRecords介绍: TFRecords是Tensorflow设计的一种内置文件格式,是一种二进制文件,它能更好的利用内存, 更方便复制和移动,为 ...
- Mongdb、Mysql、Redis、Memcache场景
个人的一点理解,不确定一定准确,有不对处欢迎指出 全部数据使用mysql存储,确保安全.准确和持久 大数据.非安全性数据使用Mongodb 小数据.结构丰富.持久化(主从数据)使用redis 小数据. ...
- 阶段3 3.SpringMVC·_02.参数绑定及自定义类型转换_3 配置解决中文乱码的过滤器
输入中文 中文后台接收到 全部乱码 springMvc提供了过滤器 配置过滤器 characterEncodingFilter是首字母小写当做起的名称.当然这里也可以任意起名字.为了对应所以修改类名首 ...
- SQL学习(八)日期处理
不同数据库中,针对日期处理的函数不同 Oracle中常用日期函数 (1.sysdate: 获取当前系统时间 如: select sysdate() ----返回当前时间,包括年月日 时分秒 (2.to ...
- "美团"APP学习记录知识点
1.APP进入加载广告视图展示: -(void)initAdvView{ // 判断图片是否已经存在 NSArray *paths = NSSearchPathForDirectoriesInDoma ...
- Matlab中psf2otf()函数在opencv中的实现
在Matlab中有个psf2otf()函数,可以将小尺寸的点扩散函数,扩大尺寸,并作二维傅里叶变换,opencv中没有这个函数,所以编了这么个函数: /************************ ...
- Go语言集成开发工具JetBrains GoLandMac2.3中文版
JetBrAIns GoLand for Mac是是专为Go开发人员构建的跨平台IDE,功能非常强大拥有强大的代码洞察力,帮助所有Go开发人员即时错误检测和修复建议,快速和安全的重构,一步撤销,智能 ...
- Mac下的Pycharm教程
除非你是用记事本写代码,或者用vim写代码的大牛,那么推荐使用PyCharm编写Python代码. PyCharm是一种Python IDE,带有一整套可以帮助用户在使用Python语言开发时提高其效 ...