hadoop安装zookeeper-3.4.12
在安装hbase的时候,需要安装zookeeper,当然也可以用hbase自己管理的zookeeper,在这里我们独立安装zookeeper-3.4.12。
下载地址:https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/zookeeper-3.4.12/
zookeeper-3.4.12.tar.gz 上传到主节点上的目录下:/home/hadoop
解压tar -xvf zookeeper-3.4.12.tar.gz
重命名:mv zookeeper-3.4.12/ zookeeper
创建在主目录zookeeper下创建data和logs两个目录用于存储数据和日志:
[hadoop@master zookeeper]$ mkdir data
[hadoop@master zookeeper]$ mkdir logs
修改配置文件:
cp zoo_sample.cfg zoo.cfg
vi zoo.cfg #修改内容已经用红色字体标出
[hadoop@master conf]$ more zoo.cfg
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/home/hadoop/zookeeper/data
dataLogDir=/home/hadoop/zookeeper/logs
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
server.1=master:2888:3888
server.2=saver1:2888:3888
server.3=saver2:2888:3888
配置文件简单说明
============ zookeeper配置文件说明 ============
在ZooKeeper的设计中,集群中所有机器上zoo.cfg文件的内容都应该是一致的。 tickTime: 服务器与客户端之间交互的基本时间单元(ms)
initLimit : 此配置表示允许follower连接并同步到leader的初始化时间,它以tickTime的倍数来表示。当超过设置倍数的tickTime时间,则连接失败。
syncLimit : Leader服务器与follower服务器之间信息同步允许的最大时间间隔,如果超过次间隔,默认follower服务器与leader服务器之间断开链接。
dataDir: 保存zookeeper数据路径
dataLogDir:保存zookeeper日志路径,当此配置不存在时默认路径与dataDir一致 clientPort(2181) : 客户端与zookeeper相互交互的端口 server.id=host:port:port
id代表这是第几号服务器
在服务器的data(dataDir参数所指定的目录)下创建一个文件名为myid的文件,
这个文件的内容只有一行,指定的是自身的id值。比如,服务器“1”应该在myid文件中写入“1”。
这个id必须在集群环境中服务器标识中是唯一的,且大小在1~255之间。
host代表服务器的IP地址
第一个端口号(2888)是follower服务器与集群中的“领导者”leader机器交换信息的端口
第二个端口号(3888)是当领导者失效后,用来执行选举leader时服务器相互通信的端口 maxClientCnxns : 限制连接到zookeeper服务器客户端的数量
修改/etc/profile
export ZOOKEEPER_HOME=/home/hadoop/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin:$ZOOKEEPER_HOME/conf
使配置文件生效:
source /etc/profile
在master机器上:/home/hadoop/zookeeper/data目录下创建一个文件:myid
[hadoop@master data]$ more myid
1
在saver1机器上创建myid文件
[hadoop@master data]$ more myid
2
在saver2机器上创建myid文件
[hadoop@master data]$ more myid
3
以上三个mydi文件内容和zoo.cfg 最后的server.后对应着
然后在三台服务器上都启用
zkServer.sh start
[hadoop@master ~]$ zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /home/hadoop/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
可以观察到:
master
[hadoop@master ~]$ jps
17888 NameNode
18022 DataNode
18454 NodeManager
18807 Jps
18345 ResourceManager
18782 QuorumPeerMain
18191 SecondaryNameNode
[hadoop@master ~]$
[hadoop@master ~]$ zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/hadoop/zookeeper/bin/../conf/zoo.cfg
Mode: followe
saver1
[hadoop@saver1 ~]$ jps
9010 Jps
8979 QuorumPeerMain
8727 DataNode
8839 NodeManager
[hadoop@saver1 ~]$
[hadoop@saver1 ~]$ zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/hadoop/zookeeper/bin/../conf/zoo.cfg
Mode: leade
saver2
[hadoop@saver2 ~]$ jps
8738 NodeManager
8626 DataNode
8903 Jps
8878 QuorumPeerMain
[hadoop@saver2 ~]$
[hadoop@saver2 ~]$ zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/hadoop/zookeeper/bin/../conf/zoo.cfg
Mode: followe
然后启动Hbase
[hadoop@master ~]$ start-hbase.sh
running master, logging to /home/hadoop/hbase/logs/hbase-hadoop-master-master.out
saver1: running regionserver, logging to /home/hadoop/hbase/bin/../logs/hbase-hadoop-regionserver-saver1.out
saver2: running regionserver, logging to /home/hadoop/hbase/bin/../logs/hbase-hadoop-regionserver-saver2.out
[hadoop@master ~]$ jps
19168 Jps
17888 NameNode
18022 DataNode
18454 NodeManager
18983 HMaster
18345 ResourceManager
18782 QuorumPeerMain
18191 SecondaryNameNode
启动和停止
zkServer.sh start
zkServer.sh stop
zkServer.sh restart
zkServer.sh status
前台显示:
主节点:
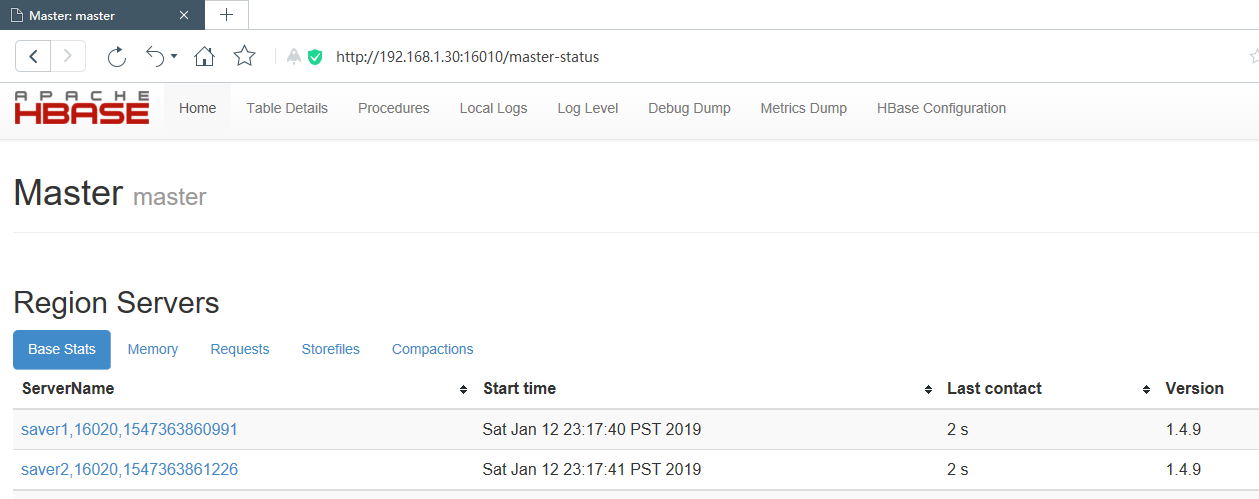
saver节点
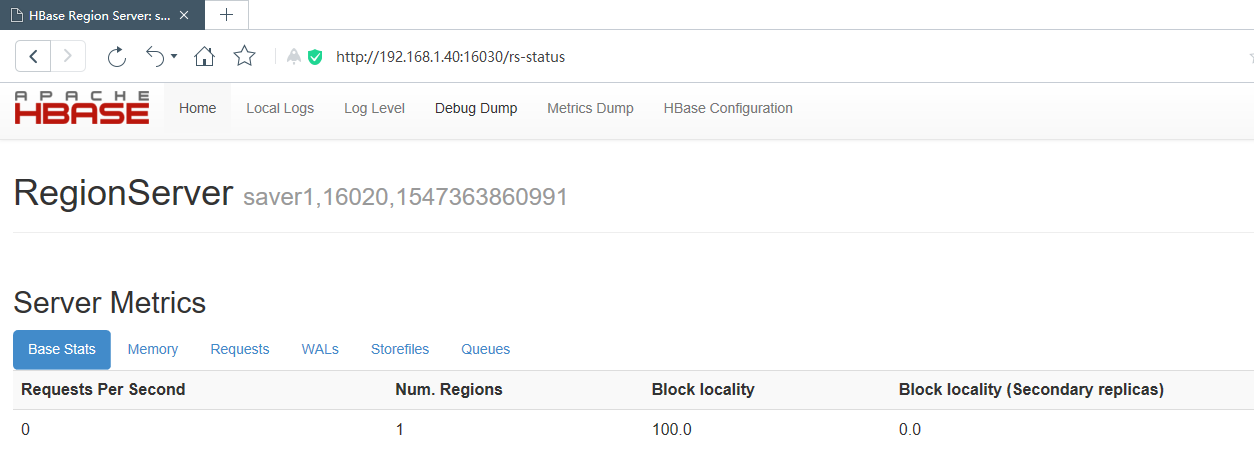
完。
hadoop安装zookeeper-3.4.12的更多相关文章
- 吴裕雄--天生自然HADOOP操作实验学习笔记:安装zookeeper集群
实验目的 了解zookeeper的概念和原理 学会安装zookeeper集群并验证 掌握zookeeper命令使用 实验原理 1.Zookeeper介绍 ZooKeeper是一个分布式的,开放源码的分 ...
- 安装高可用Hadoop生态 (二) 安装Zookeeper
2. 安装Zookeeper 2.1. 解压程序 ※ 3台服务器分别执行 .tar.gz -C/opt/cloud/packages /opt/cloud/bin/zookeeper /conf ...
- Hadoop、Zookeeper、Hbase分布式安装教程
参考: Hadoop安装教程_伪分布式配置_CentOS6.4/Hadoop2.6.0 Hadoop集群安装配置教程_Hadoop2.6.0_Ubuntu/CentOS ZooKeeper-3.3 ...
- hadoop安装及配置入门篇
声明: author: 龚细军 时间: -- 类型: 笔记 转载时请注明出处及相应链接. 链接地址: http://www.cnblogs.com/gongxijun/p/5726024.html 本 ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- Linux上安装Zookeeper以及一些注意事项
最近打算出一个系列,介绍Dubbo的使用. 分布式应用现在已经越来越广泛,Spring Could也是一个不错的一站式解决方案,不过据我了解国内目前貌似使用阿里Dubbo的公司比较多,一方面这个框架也 ...
- Ubuntu16下Hadoop安装
1. 安装Ubuntu 2. 新装Ubuntu常用软件安装和系统设置 (1) 安装vim yum install vim (2) 更改hostname为hadoop_master sudo vim / ...
- HADOOP+SPARK+ZOOKEEPER+HBASE+HIVE集群搭建(转)
原文地址:https://www.cnblogs.com/hanzhi/articles/8794984.html 目录 引言 目录 一环境选择 1集群机器安装图 2配置说明 3下载地址 二集群的相关 ...
- Hadoop生态圈-zookeeper本地搭建以及常用命令介绍
Hadoop生态圈-zookeeper本地搭建以及常用命令介绍 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.下载zookeeper软件 下载地址:https://www.ap ...
随机推荐
- 阶段3 3.SpringMVC·_04.SpringMVC返回值类型及响应数据类型_1 搭建环境
创建项目 使用骨架,创建webapp 为了创建项目更快速maven设置 archetypeCatalog internal 修改编译的版本 从昨天的课程内复制 相关的坐标.上面是版本锁定. 复制前端的 ...
- httpClient调用接口的时候,解析返回报文内容
比如我httpclient调用的接口返回的格式是这样的: 一:data里是个对象 { "code": 200, "message": "执行成功&qu ...
- 使用 joblib 对 Pandas 数据进行并行处理
使用 joblib 对 Pandas 数据进行并行处理 如果需要对一个很大的数据集进行操作,而基于一列数据生成新的一列数据可能都需要耗费很长时间. 于是可以使用 joblib 进行并行处理. 假设我们 ...
- 2019.11.10【每天学点SAP小知识】Day3 - ABAP 7.40新语法 值转化和值赋值
1.语法为 CONV dTYPE|#(...)\ # 代表任意类型 "7.40之前表达式 . DATA helper TYPE string. DATA xstr TYPE xstring. ...
- MySQL乱码的原因和设置UTF8数据格式
https://segmentfault.com/a/1190000018662023 MySQL使用时,有一件很痛苦的事情肯定是结果乱码.将编码格式都设置为UTF8可以解决这个问题,我们今天来说下为 ...
- springboot子模块 @Autowired无法找到其他模块的接口和类的解决方法
在main的启动类上添加 @SpringBootApplication(scanBasePackages = {"com.shangsheng"})或者@ComponentScan ...
- CDH spark 命令行测试
一. 参考 https://www.cnblogs.com/bovenson/p/5801536.html [root@node- test]# chown hdfs:hdfs /root/test/ ...
- 史上最简单的CentOS7破解密码方法,有图有真相
#############破解CentOS7密码详细过程 一.开机重启,按任意键停住,有时没停住,是鼠标键未在服务器中,点一下就好 二.按e键进入单用户模式 三.在UTF-8后面加上i ...
- PJzhang:任意密码重置的常规姿势
猫宁!!! 之前在360补天看过carry_your分享的46分钟短视频“任意用户密码重置的10种姿势”. 在京东SRC安全小课堂第89期,也有一篇他的文章:web漏洞之逻辑漏洞挖掘.内容朴实无华. ...
- 【机器学习理论】概率论与数理统计--假设检验,卡方检验,t检验,F检验,方差分析
显著性水平α与P值: 1.显著性水平是估计总体参数落在某一区间内,可能犯错误的概率,用α表示. 显著性是对差异的程度而言的,是在进行假设检验前确定的一个可允许作为判断界限的小概率标准. 2.P值是用来 ...