MATLAB分类与预测算法函数
1、glmfit()
功能:构建一个广义线性回归模型。
使用格式:b=glmfit(X,y,distr),根据属性数据X以及每个记录对应的类别数据y构建一个线性回归模型,distr可取值为:binomial、gamma、inverse gaussian、normal(默认值)和poisson,分别代表不同类型的回归模型。
2、patternnet()
功能:构建一个模式识别神经网络。
模式识别神经网络是一个前馈神经网络,通过对已知含有标签的数据进行训练得到神经网络模型,从而可以对新的不含标签的数据进行分类。用于输入的标签数据需要进行特殊编码,即一个类别使用一个向量进行表示,比如一共有3个类别,那么类别1可以编码为[1,0,0],类别3可以编码为[0,0,1]。
使用格式:net=patternnet(hiddenSizes,trainFcn,performFcn),构建一个隐含层神经元个数为hiddenSizes,模型函数为trainFcn,性能函数为performFcn的神经网络net。
主要的模型函数有:
Trainscg:使用标度共梯度算法更新权值和偏移值
Trainlm:使用LM算法更新权值和偏移值
Trainbr:使用LM算法更新权值和偏移值(贝叶斯正则化)
Trainrp:根据弹反向传播算法更新权值和偏移值
3、fitctree()
功能:构建一个二叉分类树,每个分支节点根据输人数据进行确定。
使用格式:tree=fitctree(x,y),根据数据的属性数据x以及每个记录对应的类别数据y构建一个二叉分类树tree。
4、fitensemble()
功能:创建一个模型,该函数可以根据不同的参数构建不同的模型,可以用于分类或者回归。
使用格式:Ensemble=fitensemble(x,y,Method,NLearn,Learners),根据输入属性数据x以及每个记录对应的y值(如y是离散型变量,则模型为分类模型;如y是连续型变量,则模型为回归模型)、Method(用于构建的模型名称)、NLearn(模型学习的循环次数)以及Learners值(弱学习算法名称,有三个值,分别是“Discriminant”“KNN”“Tree”)构建一个分类或者回归模型。该模型的性能依赖于弱学习算法的参数设置,如果这些参数设置不合理,将导致较差的性能。
常用的method:
①参数值:AdaBoostM1
适用范围:适用于二类别分类
②参数值:LogitBoost
适用范围:适用于二类别分类
③参数值:GentleBoost
适用范围:适用于二类别分类
④参数值:AdaBoostM2
适用范围:适用于三类别分类及以上
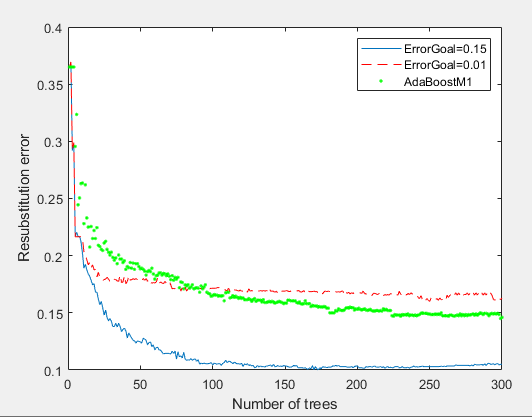
使用fitensemble函数构建三个模型,对比三个模型的误差。
rng(,'twister')
Xtrain=rand(,);
Ytrain=sum(Xtrain(:,:),)>2.5;
idx=randsample(,);
Ytrain(idx)=~Ytrain(idx);
%构建一个AdaBoostM1模型
ada=fitensemble(Xtrain,Ytrain,'AdaBoostM1',,'Tree','LearnRate',0.1);
%构建一个RobustBoost模型,设置误差阈值为0.
rb1=fitensemble(Xtrain,Ytrain,'RobustBoost',,'Tree','RobustErrorGoal',0.15,'RobustMaxMargin',);
%构建一个RobustBoost模型,设置误差阈值为0.
rb2=fitensemble(Xtrain,Ytrain,'RobustBoost',,'Tree','RobustErrorGoal',0.01)
figure
plot(resubLoss(rb1,'Mode','Cumulative'))
hold on
plot(resubLoss(rb2,'Mode','Cumulative'),'r--');
plot(resubLoss(ada,'Mode','Cumulative'),'g.');
hold off
xlabel('Number of trees');
ylabel('Resubstitution error');
legend('ErrorGoal=0.15','ErrorGoal=0.01','AdaBoostM1','Location','NE');
5、fitNaiveBayes()
功能:创建一个朴素贝叶斯分类器。
使用格式:NBModel=fitNaiveBayes(x,y),根据输入数据x以及每个x对应的类别号y(如果y为NaN或者空字符串‘’或者unidefined,都会被视为缺失值,朴素贝叶斯分类器会直接忽略这些值对应的x)构建一个朴素贝叶斯分类器。
MATLAB分类与预测算法函数的更多相关文章
- 详细BP神经网络预测算法及实现过程实例
1.具体应用实例.根据表2,预测序号15的跳高成绩. 表2 国内男子跳高运动员各项素质指标 序号 跳高成绩() 30行进跑(s) 立定三级跳远() 助跑摸高() 助跑4—6步跳高() 负重深蹲杠铃() ...
- 数据挖掘入门系列教程(二)之分类问题OneR算法
数据挖掘入门系列教程(二)之分类问题OneR算法 数据挖掘入门系列博客:https://www.cnblogs.com/xiaohuiduan/category/1661541.html 项目地址:G ...
- 【彩票】彩票预测算法(一):离散型马尔可夫链模型C#实现
前言:彩票是一个坑,千万不要往里面跳.任何预测彩票的方法都不可能100%,都只能说比你盲目去买要多那么一些机会而已. 已经3个月没写博客了,因为业余时间一直在研究彩票,发现还是有很多乐趣,偶尔买买,娱 ...
- matlab 对图像操作的函数概览
转自博客:http://blog.163.com/fei_lai_feng/blog/static/9289962200991713415422/ 一. 读写图像文件 1. imread imread ...
- 【年终分享】彩票数据预测算法(一):离散型马尔可夫链模型实现【附C#代码】
原文:[年终分享]彩票数据预测算法(一):离散型马尔可夫链模型实现[附C#代码] 前言:彩票是一个坑,千万不要往里面跳.任何预测彩票的方法都不可能100%,都只能说比你盲目去买要多那么一些机会而已. ...
- 基于MATLAB的腐蚀膨胀算法实现
本篇文章要分享的是基于MATLAB的腐蚀膨胀算法实现,腐蚀膨胀是形态学图像处理的基础,腐蚀在二值图像的基础上做“收缩”或“细化”操作,膨胀在二值图像的基础上做“加长”或“变粗”的操作. 什么是二值图像 ...
- MATLAB粒子群优化算法(PSO)
MATLAB粒子群优化算法(PSO) 作者:凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/ 一.介绍 粒子群优化算法(Particle Swarm Optim ...
- surprise库官方文档分析(二):使用预测算法
1.使用预测算法 Surprise提供了一堆内置算法.所有算法都派生自AlgoBase基类,其中实现了一些关键方法(例如predict,fit和test).可以在prediction_algorith ...
- 【机器学习】【条件随机场CRF-2】CRF的预测算法之维特比算法(viterbi alg) 详解 + 示例讲解 + Python实现
1.CRF的预测算法条件随机场的预测算法是给定条件随机场P(Y|X)和输入序列(观测序列)x,求条件概率最大的输出序列(标记序列)y*,即对观测序列进行标注.条件随机场的预测算法是著名的维特比算法(V ...
随机推荐
- maven-setting.xml文件详解
<?xml version="1.0" encoding="UTF-8"?> <settings xmlns="http://mav ...
- REST与RPC区别
OSI网络七层模型 第一层:应用层.定义了用于在网络中进行通信和传输数据的接口: 第二层:表示层.定义不同的系统中数据的传输格式,编码和解码规范等: 第三层:会话层.管理用户的会话,控制用户间逻辑连接 ...
- java后台防止XSS的脚本攻击
import java.util.regex.Pattern; //具体过滤关键字符public class XSSUtil { private static Pattern[] patterns = ...
- svn diff 只显示文件名
svn diff --summarize
- luogu 4211
题意 存在一棵树,每次询问 \(l, r, z\) 求 \[\sum_{i = l} ^ {r} deep(lca(i, z))\] 考虑 lca 的实质:两点到根的路径的交集中深度最大的点 其中一点 ...
- P1899 魔法物品
题目描述 //又是一个好(nan)题好(nan)题 //首先,普通物品一开始就卖掉就可以,因为它不会增值 //至于魔法物品 //如果一个魔法物品使用了卷轴后的价值减去买卷轴的钱还不如鉴定前的价值高,那 ...
- 超轻量级虚拟终端sakura和tilda
一.安装: manjaro:pacman -S sakura ubunt:sudo apt install sakura 小当然是他的最大优点了,虽小但是功能挺全 可以同时打开好多个终端,termin ...
- web目录
Proj app controllers jobs models view user xxx.html init.go conf message public img js css html
- HttpClient学习(二)—— MinimalHttpClient源码解析
依赖关系 方法 class MinimalHttpClient extends CloseableHttpClient { //连接管理器 private final HttpClientConnec ...
- CodeForces - 1183E Subsequences (easy version) (字符串bfs)
The only difference between the easy and the hard versions is constraints. A subsequence is a string ...