scikit-learn中的机器学习算法封装——kNN
接前面 https://www.cnblogs.com/Liuyt-61/p/11738399.html
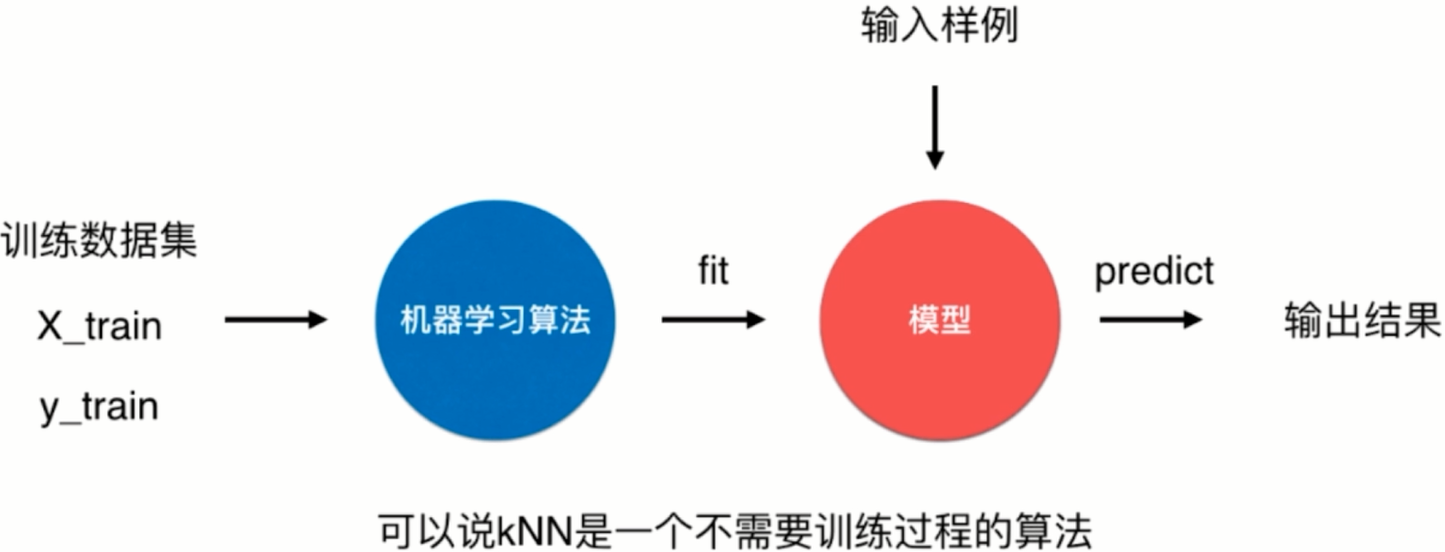
回过头来看这张图,什么是机器学习?就是将训练数据集喂给机器学习算法,在上面kNN算法中就是将特征集X_train和Y_train传给机器学习算法,然后拟合(fit)出一个模型,然后输入样例到该模型进行预测(predict)输出结果。
而对于kNN来说,算法的模型其实就是自身的训练数据集,所以可以说kNN是一个不需要训练过程的算法。
k近邻算法是非常特殊的,可以被认为是没有模型的算法
为了和其他算法统一,可以认为训练数据集就是模型本身
使用scikit-learn中的kNN实现
#先导入我们需要的包
from sklearn.neighbors import KNeighborsClassifier #特征点的集合
raw_data_X = [[3.393533211, 2.331273381],
[3.110073483, 1.781539638],
[1.343808831, 3.368360954],
[3.582294042, 4.679179110],
[2.280362439, 2.866990263],
[7.423436942, 4.696522875],
[5.745051997, 3.533989803],
[9.172168622, 2.511101045],
[7.792783481, 3.424088941],
[7.939820817, 0.791637231]
]
#0就代表良性肿瘤,1就代表恶性肿瘤
raw_data_y = [, , , , , , , , , ]
#我们使用raw_data_X和raw_data_y作为我们的训练集
X_train = np.array(raw_data_X) #训练数据集的特征
Y_train = np.array(raw_data_y) #训练数据集的结果(标签) #首先我们需要对包中的KNeighborsClassifier进行实例化,其中可以传入k的值作为参数
kNN_classifier = KNeighborsClassifier(n_neighbors=)
#然后先执行fit方法进行拟合操作得出模型,将训练数据集作为参数传入
kNN_classifier.fit(X_train,Y_train)
#执行predict预测操作,传入样本数据
#因为使用scikit-learn中的kNN算法是对一组矩阵形式的数据进行一条条的预测,所以我们传入的样本数据集参数也应该先转换为矩阵的形式
X_predict = x.reshape(,-) #因为我们已知我们传入的数据只有一行
y_predict = kNN_classifier.predict(X_predict)
In[]: y_predict
Out[]: array([])
#所以此时的y_predict即为我们所需要的样本的预测结果
In[]: y_predict[]
Out[]:
基于scikit-learn的fit-predict模式,进行重写我们的Python实现,进行简单的自定义fit和predict方法实现kNN
import numpy as np
from math import sqrt
from collections import Counter class KNNClassifier: def __init__(self, k):
'''初始化KNN分类器'''
#使用断言进行判定传入的参数的合法性
assert k >= , "k must be valid"
self.k = k;
#此处定义为私有变量,外部成员不可访问进行操作
self._X_train = None
self._Y_train = None def fit(seld, X_train, Y_train):
'''根据训练集X_train和Y_train训练kNN分类器'''
assert X_train.shape[] == Y_train.shape[],\
"the size of X_train must be equal to the size of Y_train"
assert self.k <= X_train.shape[],\
"the size of X_train must be at least k" self._X_train = X_train
self._Y_train = Y_train
return self #X_predict 为传入的矩阵形式数据
def predict(self, X_predict):
'''给定待预测数据集X_train,返回表示X_predict的结果向量'''
assert self._X_train is not None and self._Y_train is not None,\
"must fit before predict!"
assert X_predict.shape[] == self._X_train.shape[],\
"the feature number of X_predict must equal to X_train" #使用私有方法_predict(x)进行对x进行预测
#循环遍历X_predict,对其中每一条样本数据集执行私有方法_predict(x),将预测结果存入y_predict中
y_predict = [self._predict(x) for x in X_predict]
return np.array(y_predict) def _predict(self, x):
'''给定单个待预测数据x,返回x的预测结果值'''
'''此处的代码逻辑和重写之前的代码逻辑一样'''
distances = [sqrt(np.sum(x_train - x) ** ) for x_train in self._X_train]
nearest = np.argsort(distances) topk_y = [self._Y_train[i] for i in nearest[:self.k]]
votes = Counter(topk_y)
return votes.most_common()[][] #重写对象的“自我描述”
def __repr__(self):
return "KNN(k=%d)" % self.k
scikit-learn中的机器学习算法封装——kNN的更多相关文章
- 在opencv3中的机器学习算法
在opencv3.0中,提供了一个ml.cpp的文件,这里面全是机器学习的算法,共提供了这么几种: 1.正态贝叶斯:normal Bayessian classifier 我已在另外一篇博文中介 ...
- 在opencv3中实现机器学习算法之:利用最近邻算法(knn)实现手写数字分类
手写数字digits分类,这可是深度学习算法的入门练习.而且还有专门的手写数字MINIST库.opencv提供了一张手写数字图片给我们,先来看看 这是一张密密麻麻的手写数字图:图片大小为1000*20 ...
- opencv3中的机器学习算法之:EM算法
不同于其它的机器学习模型,EM算法是一种非监督的学习算法,它的输入数据事先不需要进行标注.相反,该算法从给定的样本集中,能计算出高斯混和参数的最大似然估计.也能得到每个样本对应的标注值,类似于kmea ...
- 机器学习算法之——KNN、Kmeans
一.Kmeans算法 kmeans算法又名k均值算法.其算法思想大致为:先从样本集中随机选取 kk 个样本作为簇中心,并计算所有样本与这 kk 个“簇中心”的距离,对于每一个样本,将其划分到与其距离最 ...
- 在opencv3中的机器学习算法练习:对OCR进行分类
OCR (Optical Character Recognition,光学字符识别),我们这个练习就是对OCR英文字母进行识别.得到一张OCR图片后,提取出字符相关的ROI图像,并且大小归一化,整个图 ...
- 机器学习算法之:KNN
基于实例的学习方法中,最近邻法和局部加权回归法用于逼近实值或离散目标函数,基于案例的推理已经被应用到很多任务中,比如,在咨询台上存储和复用过去的经验:根据以前的法律案件进行推理:通过复用以前求解的问题 ...
- (原创)(四)机器学习笔记之Scikit Learn的Logistic回归初探
目录 5.3 使用LogisticRegressionCV进行正则化的 Logistic Regression 参数调优 一.Scikit Learn中有关logistics回归函数的介绍 1. 交叉 ...
- 机器学习算法·KNN
机器学习算法应用·KNN算法 一.问题描述 验证码目前在互联网上非常常见,从学校的教务系统到12306购票系统,充当着防火墙的功能.但是随着OCR技术的发展,验证码暴露出的安全问题越来越严峻.目前对验 ...
- (原创)(三)机器学习笔记之Scikit Learn的线性回归模型初探
一.Scikit Learn中使用estimator三部曲 1. 构造estimator 2. 训练模型:fit 3. 利用模型进行预测:predict 二.模型评价 模型训练好后,度量模型拟合效果的 ...
随机推荐
- Swift4.0复习结构体
1.基本语法: /** 定义了一个结构体 */ struct Structure { /// 一个常量存储式实例属性, /// 并直接为它初始化 let constProperty = /// ...
- ucore 源码剖析
lab1 源码剖析 从实模式到保护模式 初始化ds,es和ss等段寄存器为0 使能A20门,其中seta20.1写数据到0x64端口,表示要写数据给8042芯片的Output Port;seta20. ...
- linux定时任务每隔5分钟向文本追加一行
编写shell脚本 test.sh内容如下,上传到linux的root目录 更改文件权限 chmod 777 test.sh 编辑定时任务 crontab -e */5 * * * ...
- 记一次SQL优化
常见的SQL优化 一.查询优化 1.避免全表扫描 模糊查询前后加%也属于全表扫描 在where子句中对字段进行表达式操作会导致引擎放弃使用索引而进行全表扫描,如: select id from t w ...
- PAT(B) 1083 是否存在相等的差(Java)统计
题目链接:1083 是否存在相等的差 (20 point(s)) 题目描述 给定 N 张卡片,正面分别写上 1.2.--.N,然后全部翻面,洗牌,在背面分别写上 1.2.--.N.将每张牌的正反两面数 ...
- TCP,SYN,FIN扫描
1.TCP扫描相对来说是速度比较慢的一种,为什么会慢呢?因为这种方法在扫描的时候会从本地主机的一个端口向目标主机的一个端口发出一个连接请求报文段,而目标主机在收到这个这个请求报文后: 有回复: 若同意 ...
- c语言实现串
串 (string)是由零个或者多个字符组成的有限序列,又称字符串 一般表示为 S=“ a1 a2 a3 a4 . . . . . an” 其中S 是串名,双引号串起来的是串值,(有些书用单 ...
- 【Leetcode】746. Min Cost Climbing Stairs
题目地址: https://leetcode.com/problems/min-cost-climbing-stairs/description/ 解题思路: 官方给出的做法是倒着来,其实正着来也可以 ...
- Linux 服务器修改时间与时间同步
设置时间 date --set '2015-11-23 0:10:40' # 方法一,通用 timedatectl set-time '2015-11-23 08:10:40' # 容器内可能不支持 ...
- Linux踢出登陆用户的正确姿势
首先who(或w)查看需要杀死的终端名,然后执行: pkill -9 -t pts/? pkill相当于ps和kill的结合,用法和killall类似,根据进程名来杀死一类进程(kill是杀死单个) ...