大数据学习笔记【一】:Hadoop-3.1.2完全分布式环境搭建(Windows 10)
一、前言
Hadoop原理架构本人就不在此赘述了,可以自行百度,本文仅介绍Hadoop-3.1.2完全分布式环境搭建(本人使用三个虚拟机搭建)。
首先,步骤:
① 准备安装包和工具:
- hadoop-3.1.2.tar.gz
- jdk-8u221-linux-x64.tar.gz(Linux环境下的JDK)
- CertOS-7-x86_64-DVD-1810.iso(CentOS镜像)
- 工具:WinSCP(用于上传文件到虚拟机),SecureCRTP ortable(用于操作虚拟机,可复制粘贴Linux命令。不用该工具也可以,但是要纯手打命令),VMware Workstation Pro
② 安装虚拟机:本人使用的是VMware Workstation Pro,需要激活。(先最小化安装一个虚拟机Master,配置完Hadoop之后再克隆两个Slave)
③ 配置虚拟机:修改用户名,设置静态IP地址,修改host文件,关闭防火墙,安装Hadoop,安装JDK,配置系统环境,配置免密码登录(必要)。
④ 配置Hadoop:配置hadoop-env.sh,hdfs-site.xml,core-site.xml,mepred-site.xml,yarn-site.xml,workers文件(在Hadoop-2×中是slaves文件,用于存放从节点的主机名称,或者IP地址)
⑤ 克隆虚拟机:克隆两个Slave,主机名称分别是Slave1,Slave2。然后修改Slave的Hadoop配置。
⑥ namenode格式化:分别对Master、Slave1,Slave2执行hadoop namenode -format命令。
⑦ 启动hdfs和yarn:在Master上执行start-all.sh命令。待启动完成之后,执行jps命令查看进程,应包含namenode,secondarynamenode,resourcemaneger三个进程。Slave上有datanode,nodemanager进程。
⑧ 检查测试:先修改真实主机的host(IP地址与Master的映射)在浏览器中输入Master:9870回车,进入hdfs,点击上方datanode应该可以看到下面有两个节点;输入Master:8088回车,进入资源调度管理(yarn)
好了,开始吧。
二、准备工具
hadoop-3.1.2.tar.tz下载地址:http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-3.1.2/hadoop-3.1.2.tar.gz
jdk-8u221-linux-x64.tar.gz下载地址:https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
CentOS下载地址:http://isoredirect.centos.org/centos/7/isos/x86_64/CentOS-7-x86_64-DVD-1810.iso
WinSCP下载地址: https://winscp.net/eng/download.php
SecureCRTP ortable下载地址: http://fs2.download82.com/software/bbd8ff9dba17080c0c121804efbd61d5/securecrt-portable/scrt675_u3.exe
VMware Workstation Pro下载地址:http://download3.vmware.com/software/wkst/file/VMware-workstation-full-15.1.0-13591040.exe
附VMware Workstation Pro秘钥:
YG5H2-ANZ0H-M8ERY-TXZZZ-YKRV8
UG5J2-0ME12-M89WY-NPWXX-WQH88
UA5DR-2ZD4H-089FY-6YQ5T-YPRX6
三、安装虚拟机
此步略,详情之后发布
四、配置虚拟机
1.修改用户名:
hostnamectl --static set-hostname Master
2.设置静态IP地址
首先查看一下原本自动获取到的网关和DNS,记下来
[root@Master ~]# cat /etc/resolv.conf
# Generated by NetworkManager
nameserver 192.168.28.2 //DNS
[root@Master ~]# IP routing table
Destination Gateway Genmask Flags MSS Window irtt Iface
default 192.168.28.2(网关) 0.0.0.0 UG 0 0 0 ens33
192.168.28.0 0.0.0.0 255.255.255.0 U 0 0 0 ens33
[root@Master ~]# vi /etc/sysconfig/network-scripts/ifcfg-ens33 //修改ifcfg-ens33文件,执行此命令后进入如下界面
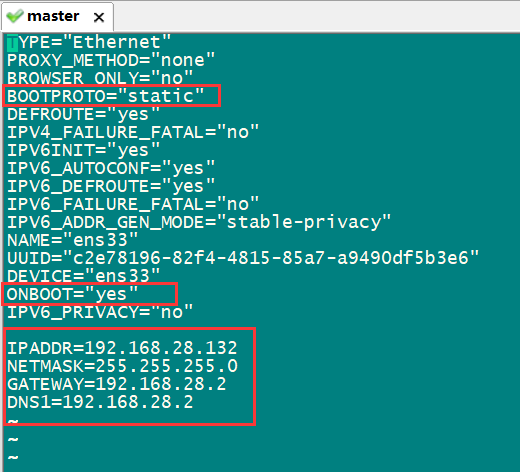
进入界面后按“I”键进入编辑模式,修改或添加图中标红部分。“static”表示静态地址,“netmask”子网掩码,gateways是网关,设置为上一步查看得到的即可。修改后按“esc”退出编辑模式。输入":wq"保存退出。然后输入以下代码更新网络配置。
systemctl restart network
3.修改hosts文件
注明:本人设置Master的IP地址为192.168.28.132,Slave1和Slave2分别为192.168.28.133,192.168.28.134
输入以下代码修改hosts文件(在真实主机中也需要添加):
vi /etc/hosts
添加:
192.168.28.132 Master
192.168.28.133 Slave1
192.168.28.134 Slave2
4.关闭防火墙
关闭防火墙代码:
systemctl stop firewalld.service //临时关闭
systemctl disable firewalld.service //设置开机不自启
5.安装Hadoop和JDK
先创建两个文件夹:
mkdir /tools //用来存放安装包
mkdir /bigdata //存放解压之后的文件夹
使用WinSCP上传压缩包:登录后找到已下载好的压缩包按如下步骤点击上传即可。
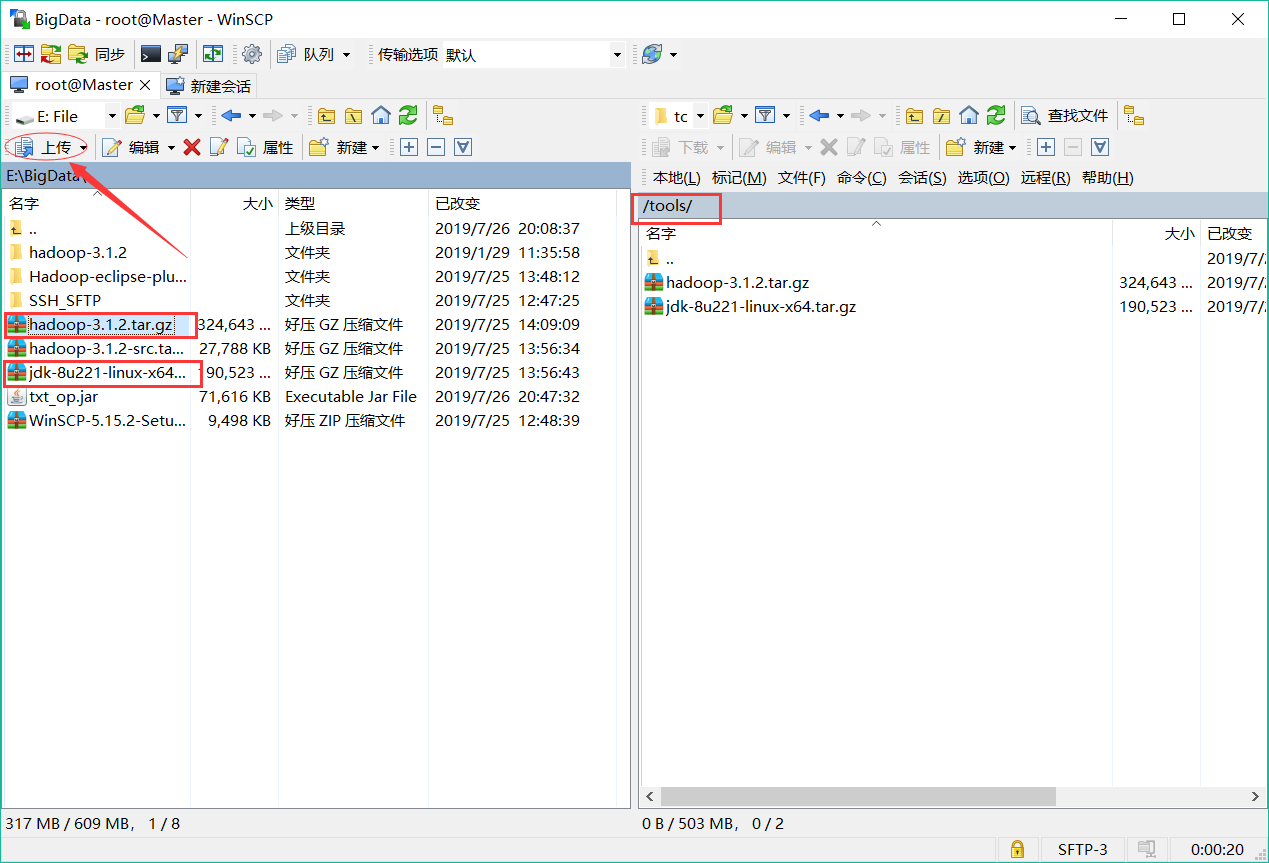
上传文件后,虚拟机端进入tools文件夹并解压文件:
cd /tools //进入tools文件夹
tar -zvxf jdk-8u221-linux-x64.tar.gz -C /bigdata/ //解压文件到bigdata目录下
tar -zvxf hadoop-3.1.2.tar.gz -C /bigdata/
6.配置系统环境
vi ~/.bash_profile
添加:
export JAVA_HOME=/bigdata/jdk1.8.0_221
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin export HADOOP_HOME=/bigdata/hadoop-3.1.2
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin 保存退出,让环境变量生效:
source ~/.bash_profile
7.配置免密登录(重要)
ssh-keygen -t rsa (直接回车3次)
cd ~/.ssh/
ssh-copy-id -i id_rsa.pub root@Master
ssh-copy-id -i id_rsa.pub root@Slave1
ssh-copy-id -i id_rsa.pub root@Slave2 测试是否成功配置(在配置完Slave之后测试):
ssh Slave1
可以登录到Slave1节点
五、配置Hadoop
Hadoop-3.1.2中有许多坑,在2X版本中有些默认的不需要特别配置,但在Hadoop-3.1.2中需要。
hadoop-env.sh配置:
cd /bigdata/hadoop-3.1.2/etc/hadoop/
vi hadoop-env.sh
添加:
export JAVA_HOME=/bigdata/jdk1.8.0_221
export HADOOP_HOME=/bigdata/hadoop-3.1.2
export PATH=$PATH:/bigdata/hadoop-3.1.2/bin
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib/native"
export HADOOP_PID_DIR=/bigdata/hadoop-3.1.2/pids //PID存放目录,若没有此配置则默认存放在tmp临时文件夹中,在启动和关闭HDFS时可能会报错
#export HADOOP_ROOT_LOGGER=DEBUG,console //先注释掉,有问题可以打开,将调试信息打印在console上
hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name> //冗余度,默认为3
<value>1</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/bigdata/hadoop-3.1.2/dfs/tmp/data</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/bigdata/hadoop-3.1.2/dfs/tmp/name</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
mapred.site.xml:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>Master:9001</value>
</property>
</configuration>
yarn-site.xml:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
core-site.xml:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://Master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/bigdata/hadoop-3.1.2/tmp</value>
</property>
</configuration>
workers:把默认的localhost删掉
Slave1 192.168.28.133
Slave2 192.168.28.134
yarn-env.sh 添加:
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
进入/bigdata/hadoop-3.1.2/sbin,修改start-dfs.sh,stop-dfs.sh,都添加:
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
六、克隆虚拟机

克隆两个从节点虚拟机,主机名称分别为Slave1,Slave2(需要进入虚拟机中修改),然后分别修改IP地址(具体方法上面有)重启网络,重启虚拟机。
重启完成后进行namenode格式化:分别对Master、Slave1,Slave2执行:
hadoop namenode -format
对Master执行
start-all.sh //启动hdfs和yarn
待完成后用jps查看进程:
[root@Master ~]# jps
7840 ResourceManager
8164 Jps
7323 NameNode
7564 SecondaryNameNode
两Slave的进程:
包含以下两个:
DataNode
NodeManager
七、检查
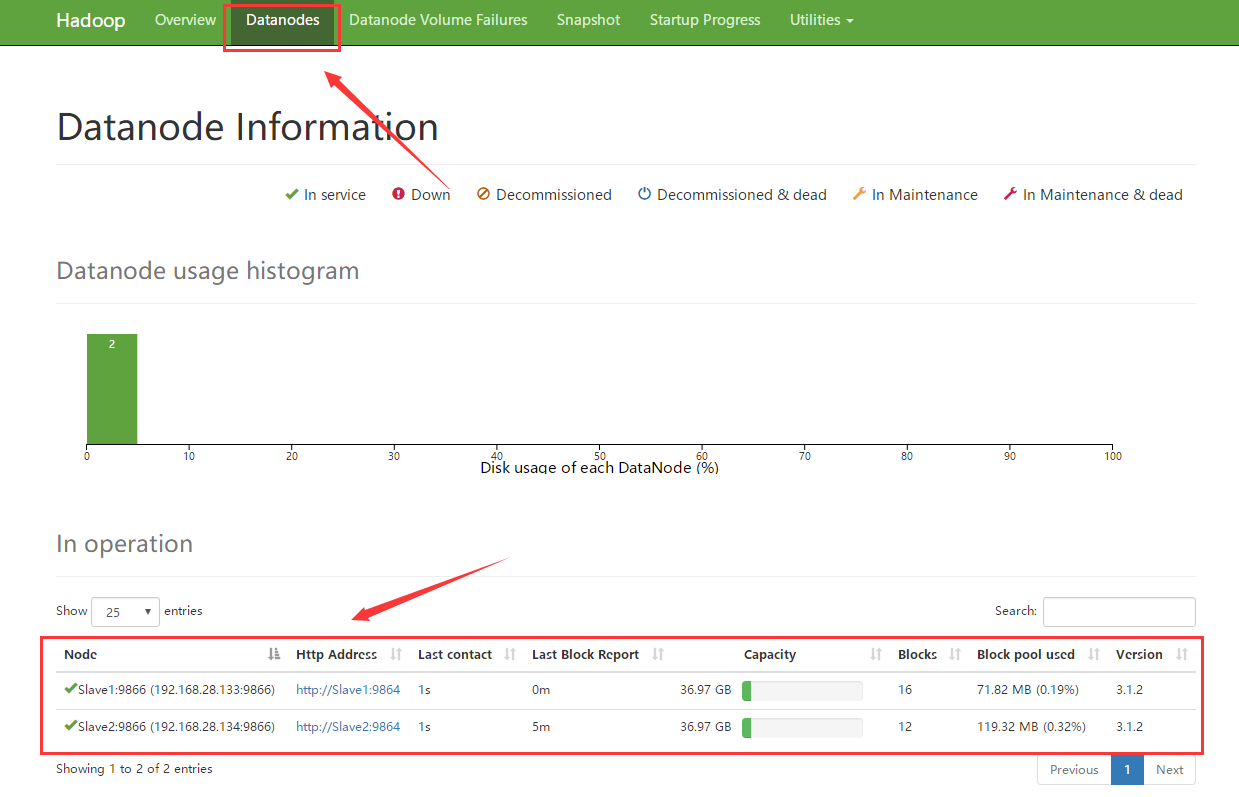
浏览器输入:在浏览器中输入Master:9870回车,进入hdfs管理页面,点击上方datanode应该可以看到下面有两个节点;
输入Master:8088回车,进入资源调度管理(yarn)
配置到此结束。接下来学习编写Job程序。有任何问题欢迎留言讨论。
大数据学习笔记【一】:Hadoop-3.1.2完全分布式环境搭建(Windows 10)的更多相关文章
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- 大数据学习笔记之Hadoop(一):Hadoop入门
文章目录 大数据概论 一.大数据概念 二.大数据的特点 三.大数据能干啥? 四.大数据发展前景 五.企业数据部的业务流程分析 六.企业数据部的一般组织结构 Hadoop(入门) 一 从Hadoop框架 ...
- 大数据学习笔记之Hadoop(二):HDFS文件系统
文章目录 一 HDFS概念 1.1 概念 1.2 组成 1.3 HDFS 文件块大小 二 HFDS命令行操作 三 HDFS客户端操作 3.1 eclipse环境准备 3.1.1 jar包准备 3.2 ...
- 大数据学习系列之八----- Hadoop、Spark、HBase、Hive搭建环境遇到的错误以及解决方法
前言 在搭建大数据Hadoop相关的环境时候,遇到很多了很多错误.我是个喜欢做笔记的人,这些错误基本都记载,并且将解决办法也写上了.因此写成博客,希望能够帮助那些搭建大数据环境的人解决问题. 说明: ...
- 大数据学习笔记4 - Hadoop的优化与发展(Hadoop 2.0)
前面介绍了Hadoop核心组件HDFS和MapReduce,Hadoop发展之初在架构设计和应用性能方面仍然存在不足,Hadoop的优化与发展一方面体现在两个核心组件的架构设计改进,一方面体现在Had ...
- 大数据学习笔记之Hadoop(三):MapReduce&YARN
文章目录 一 MapReduce概念 1.1 为什么要MapReduce 1.2 MapReduce核心思想 1.3 MapReduce进程 1.4 MapReduce编程规范(八股文) 1.5 Ma ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
- 大数据学习笔记——Hadoop编程实战之HDFS
HDFS基本API的应用(包含IDEA的基本设置) 在上一篇博客中,本人详细地整理了如何从0搭建一个HA模式下的分布式Hadoop平台,那么,在上一篇的基础上,我们终于可以进行编程实操了,同样,在编程 ...
- 大数据学习笔记——Java篇之集合框架(ArrayList)
Java集合框架学习笔记 1. Java集合框架中各接口或子类的继承以及实现关系图: 2. 数组和集合类的区别整理: 数组: 1. 长度是固定的 2. 既可以存放基本数据类型又可以存放引用数据类型 3 ...
随机推荐
- ckeditor实现ctrl+v粘贴word图片并上传
官网地址http://ueditor.baidu.com Git 地址 https://github.com/fex-team/ueditor 参考博客地址 http://blog.ncmem.com ...
- xpath简介备查
xpath简介 xpath 使用路径表达式在xml和html中进行导航 xpath包含标准函数库 xpath是一个w3c的标准 xpath节点关系 父节点 子节点 同袍节点 先辈节点 后代节点 xpa ...
- 2-SAT两题
看了大白书,学习了一下two-sat,很有意思的算法.题目就是大白书上的两题. 仅仅放一下代码作为以后的模板参考. #include <stdio.h> #include <algo ...
- G-LAB四月份作业-数据可视化问题探讨
G-LAB四月份作业-数据可视化问题探讨 引子: 数据平台项目建设正在按照公司的计划开展执行中,作为平台建设项目参与者之一,感觉目前我们现有的MIS报表平台数据也不可谓不丰富,但是不论从提供给用户的数 ...
- redis数据结构有哪些
1.String 可以是字符串,整数或者浮点数,对整个字符串或者字符串中的一部分执行操作,对整个整数或者浮点执行自增(increment)或者自减(decrement)操作. 2.list 一个链表, ...
- OAuth2.0的四种授权模式
1.什么是OAuth2 OAuth(开放授权)是一个开放标准,允许用户授权第三方移动应用访问他们存储在另外的服务提供者上的信息,而不需要将用户名和密码提供给第三方移动应用或分享他们数据的所有内容,OA ...
- Flutter移动电商实战 --(18)首页_火爆专区商品接口制作
1.获取接口的方法 在service/service_method.dart里制作方法.我们先不接收参数,先把接口调通. Future getHomePageBeloConten() async{ t ...
- 使用python获取微医数据
用到的包: BeautifulSoup pymysql requests json 碰到的问题: 1.医生查询分页数据不能超过38页,超过无法返回数据 2.某些字段对应的html元素包含一些无效的cl ...
- python Image 模块处理图片
Python-Image 基本的图像处理操作,有需要的朋友可以参考下. Python 里面最常用的图像操作库是 pip install Pillow #安装模块 from PIL import Ima ...
- Eclipse的断点调试
A:Debug的作用 调试程序 查看程序执行流程 B:如何查看程序执行流程 什么是断点: 就是一个标记,从哪里开始. 如何设置断点: 你想看哪里的程序,你就在那个有效程序的左边双击即可. 在哪里设置断 ...