利用贝叶斯算法实现手写体识别(Python)
在开始介绍之前,先了解贝叶斯理论知识
https://www.cnblogs.com/zhoulujun/p/8893393.html
简单来说就是:贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。而朴素朴素贝叶斯分类是贝叶斯分类中最简单,也是常见的一种分类方法。
那么既然是朴素贝叶斯分类算法,它的核心算法又是什么呢?
贝叶斯公式如下:
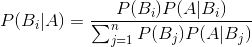
P(A|B)=P(B|A)P(A)/P(B)
可以概括为:

完整的代码如下:
#!/usr/bin/python
# -*- coding: utf-8 -*-
#########################################
# Bayes : 用来描述两个条件概率之间的关系 # 参数: inX: vector to compare to existing dataset (1xN)
# dataSet: size m data set of known vectors (NxM)
# labels: data set labels (1xM vector)
# 公式:P(A|B)=P(B|A)P(A)/P(B)
# 输出: 出错率
######################################### import numpy as npy
import os
import time #P(B|A)=P(A|B)*P(A)/P(B) # 数据集目录
dataSetDir ='E:/digits/' class Bayes:
def __init__(self):
self.length=-1
self.labelrate=dict()
self.vectorrate=dict() def fit(self,dataset:list,labels:list):
print("训练开始")
if len(dataset)!=len(labels):
raise ValueError("输入测试数组和类别数组长度不一致")
self.length=len(dataset[0])#训练数据特征值的长度
labelsnum=len(labels) #类别的数量
norlabels=set(labels) #不重复类别的数量
for item in norlabels:
self.labelrate[item]=labels.count(item)/labelsnum #求当前类别占总类别的比例
for vector,label in zip(dataset,labels):
if label not in self.vectorrate:
self.vectorrate[label]=[]
self.vectorrate[label].append(vector)
print("训练结束")
return self def btest(self,testdata,labelset):
if self.length==-1:
raise ValueError("未开始训练,先训练")
#计算testdata分别为各个类别的概率
lbDict=dict()
for thislb in labelset:
p = 1
alllabel = self.labelrate[thislb]
allvector = self.vectorrate[thislb]
vnum=len(allvector)
allvector=npy.array(allvector).T
for index in range(0,len(testdata)):
vector=list(allvector[index])
p*=vector.count(testdata[index])/vnum
lbDict[thislb]=p * alllabel
thislbabel=sorted(lbDict,key=lambda x:lbDict[x],reverse=True)[0]
return thislbabel #加载数据
def datatoarray(fname):
arr=[]
fh=open(fname)
for i in range(0,32):
thisline=fh.readline()
for j in range(0 , 32):
arr.append(int(thisline[j]))
return arr #建立一个函数取出labels
def seplabel(fname):
filestr=fname.split(".")[0]
label=int(filestr.split("_")[0])
return label #建立训练数据
def traindata():
labels=[]
trainfile=os.listdir(dataSetDir+"trainingDigits") # 加载测试数据
num=len(trainfile)
trainarr=npy.zeros((num,1024))
for i in range(num):
thisfname=trainfile[i]
thislabel=seplabel(thisfname)
labels.append(thislabel)
trainarr[i,]=datatoarray(dataSetDir+"trainingDigits/"+thisfname)
return trainarr,labels # 贝叶斯算法手写识别主流程
bys=Bayes()
start = time.time() # # step 1: 训练数据集
train_data,labels=traindata()
train_data=list(train_data)
bys.fit(train_data,labels) # # step 2:测试数据集
thisdata=datatoarray(dataSetDir+"testDigits/8_90.txt")
labelsall=[0,1,2,3,4,5,6,7,8,9] # # 识别单个手写体数字
# test=bys.btest(thisdata,labelsall)
# print(test) # # 识别多个手写体数字(批量处理),并输出结果
testfile=os.listdir(dataSetDir+"testDigits")
num=len(testfile)
x=0
for i in range(num):
thisfilename=testfile[i]
thislabel=seplabel(thisfilename)
thisdataarr=datatoarray(dataSetDir+"testDigits/"+thisfilename)
label=bys.btest(thisdataarr,labelsall)
print("测试数字是:"+str(thislabel)+" 识别出来的数字是:"+str(label))
if label!=thislabel:
x+=1
print("识别出错")
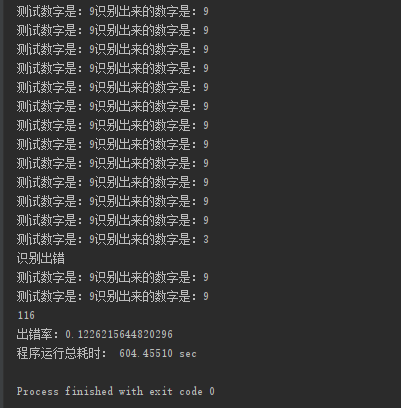
print(x)
print("出错率:"+str(x/num)) end = time.time()
running_time = end-start
print('程序运行总耗时: %.5f sec' %running_time)
最后运行的结果:
贝叶斯Python代码及数据集下载地址:https://download.csdn.net/download/kongxiaoshuang509/11248193
需要源代码或者有问题的可以私信。
利用贝叶斯算法实现手写体识别(Python)的更多相关文章
- 朴素贝叶斯算法--python实现
朴素贝叶斯算法要理解一下基础: [朴素:特征条件独立 贝叶斯:基于贝叶斯定理] 1朴素贝叶斯的概念[联合概率分布.先验概率.条件概率**.全概率公式][条件独立性假设.] 极大似然估计 ...
- 朴素贝叶斯算法的python实现方法
朴素贝叶斯算法的python实现方法 本文实例讲述了朴素贝叶斯算法的python实现方法.分享给大家供大家参考.具体实现方法如下: 朴素贝叶斯算法优缺点 优点:在数据较少的情况下依然有效,可以处理多类 ...
- 朴素贝叶斯算法的python实现
朴素贝叶斯 算法优缺点 优点:在数据较少的情况下依然有效,可以处理多类别问题 缺点:对输入数据的准备方式敏感 适用数据类型:标称型数据 算法思想: 朴素贝叶斯比如我们想判断一个邮件是不是垃圾邮件,那么 ...
- 利用朴素贝叶斯算法进行分类-Java代码实现
http://www.crocro.cn/post/286.html 利用朴素贝叶斯算法进行分类-Java代码实现 鳄鱼 3个月前 (12-14) 分类:机器学习 阅读(44) 评论(0) ...
- 朴素贝叶斯算法原理及Spark MLlib实例(Scala/Java/Python)
朴素贝叶斯 算法介绍: 朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法. 朴素贝叶斯的思想基础是这样的:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,在没有其它可用信息下,我 ...
- Python机器学习笔记:朴素贝叶斯算法
朴素贝叶斯是经典的机器学习算法之一,也是为数不多的基于概率论的分类算法.对于大多数的分类算法,在所有的机器学习分类算法中,朴素贝叶斯和其他绝大多数的分类算法都不同.比如决策树,KNN,逻辑回归,支持向 ...
- 机器学习:python中如何使用朴素贝叶斯算法
这里再重复一下标题为什么是"使用"而不是"实现": 首先,专业人士提供的算法比我们自己写的算法无论是效率还是正确率上都要高. 其次,对于数学不好的人来说,为了实 ...
- python 贝叶斯算法
自我理解贝叶斯算法也就是通过概率来判断C是属于A类还是B类,下面是具体代码(python3.5 测试通过) 文字流程解释一波 1 ) 加载训练数据和训练数据对应的类别 2) 生成词汇集,就是所有 ...
- Python机器学习算法 — 朴素贝叶斯算法(Naive Bayes)
朴素贝叶斯算法 -- 简介 朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法.最为广泛的两种分类模型是决策树模型(Decision Tree Model)和朴素贝叶斯模型(Naive Baye ...
随机推荐
- Dubbo 2.6.0升级到2.7.3
dubbo依赖,修改groupId和升级version版本号 <dependency> <groupId>com.alibaba</groupId> <art ...
- linux查看文件的编码格式的方法 set fileencoding
查看文件编码在Linux中查看文件编码可以通过以下几种方式:1.在Vim中 可以直接查看文件编码:set fileencoding即可显示文件编码格式.如果你只是想查看其它编码格式的文件或者想解决 用 ...
- 解决Mac OS编译安装时出现 cannot find openssl's <evp.h> 错误的问题
踩坑 最近通过pecl安装mongodb扩展时,提示以下错误 ...... configure: error: Cannot find OpenSSL's <evp.h> ...... 根 ...
- 复制粘贴引发的鸠占鹊巢——IDEA复制项目导致sources root复用了另一个项目
复制粘贴大法一向是程序猿的利器,但有时也会引发一些拎不清的麻烦关系来.比如我们现在想新建一个项目,为了快速而对原来的uis-gateway动用了复制粘贴大法,然后改改项目名就成了uis-applica ...
- 阶段5 3.微服务项目【学成在线】_day16 Spring Security Oauth2_06-SpringSecurityOauth2研究-Oauth2授权码模式-申请令牌
3.3 Oauth2授权码模式 3.3.1 Oauth2授权模式 Oauth2有以下授权模式: 授权码模式(Authorization Code) 隐式授权模式(Implicit) 密码模式(Reso ...
- 算法习题---3.11换抵挡装置(UVa1588)
一:题目 给你连个长度分别为n1,n2且每列高度只为1或2的长条,然后将他们拼在一起,高度不能超过3,问他们拼在一起的最短长度 二:实现思路 1.获取主动轮和从动轮的数据. 2.主动轮不动,从动轮从左 ...
- Node.js导入jquery.min.js报错
报错如下: 一看就是路径问题,可是代码中路径看起来貌似没错,如下: 解决方法: 引入方式如下: <script type="text/javascript" src=&quo ...
- django模板--循环控制标签
循环控制标签 在django模板中可以通过循环控制标签对列表进行迭代,循环控制标签又称for标签,语法格式如下: {% for value in value_list %} {{ value }} { ...
- SLAM十四讲中Sophus库安装
Sophus截止目前有很多版本,其中大体分为两类,一种是用模板实现的方法,一种是用非模板类实现的,SLAM十四讲中使用的是非模板类库,clone Sophus: git clone http://gi ...
- 【Leetcode_easy】599. Minimum Index Sum of Two Lists
problem 599. Minimum Index Sum of Two Lists 题意:给出两个字符串数组,找到坐标位置之和最小的相同的字符串. 计算两个的坐标之和,如果与最小坐标和sum相同, ...