hbase实践之写流程
内容提要
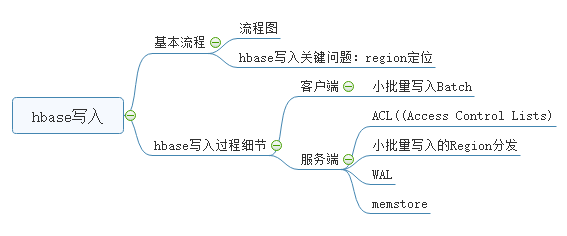
一、写入流程

- 初始化ZooKeeper Session,建立长连接,获取META Region的地址。
- 获取rowkey对应的Region路由信息:来自.meta.
- 写入region


如何快速定位rowkey所在的Region?
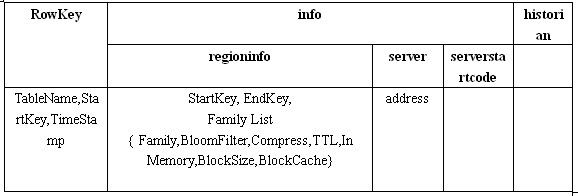
rowkey=tableName+startkey+TimeStamp
regioninfo, server, serverstartcode。
其中regioninfo就是Region的详细信息,包括StartKey, EndKey 以及每个Family的信息等等。
server存储的就是管理这个Region的RegionServer的地址。

基于一条用户数据RowKey,快速查询该RowKey所属的Region的方法其实很简单:只需要基于表名以及该用户数据RowKey,构建一个虚拟的Region Key,然后通过Reverse Scan的方式,读到的第一条Region记录就是该数据所关联的Region。
- Q: 如果Region不迁移,client如何提高查询性能?
缓存
将region信息缓存,避免每次读写去访问zookeeper或meta region
- Q: Client会缓存.META.的数据,该数据更新了怎么办?
其实,Client的元数据缓存不更新,当.META.的数据发生更新。比如因为region重新均衡,某个Region的位置发生了变化,Client再次根据缓存去访问的时候,会出现错误,当出现异常达到最大重试次数后,client就会重新去.META.所在的RegionServer获取最新的Region信息,如果.META.所在的RegionServer也变了,Client就会重新去ZK上获取.META.所在的RegionServer的最新地址。
二、客户端小批量导入Batch Put
客户端写数据的几种方式
- Single Put
- Batch Put:小批量导入
- Bulkload:该方式与前面两种写入不同,没有使用memstrore、WAL等,故不在本文讨论范围之内。
单条写入是基础,本文主要探讨如何做小批量数据导入。
- Q:小批量导入Batch Put如何做性能优化?
- 背景:每个RegionServer由多个Region组成

可以将数据按Region分组,按RegionServer打包。
后面内容涉及服务端
三、ACL安全访问控制
HBase提供了权限控制Access Control List,具体内容如下:

四、小批量写入的Region分发
在每个RegionServer遍历 按Region分组的数据,相当于串行写入Region数据:

HBase Write Path
HBase Write Path时序图如下图所示:

后面内容主要简单阐述wal、memstore、HFile,详细内容在其他文中再展示。
五、预写式日志WAL(Write-ahead logging)
类似于MySQL的binary log,WAL存储了对数据的所有更改,这使得服务器崩溃的时候,可以有效地回放日志,是数据得以恢复到崩溃以前。这也就意味着如果将记录写入到WAL失败时,整个操作也可以认为是失败的。
如果位于内存中的数据尚未持久化,而且突然遇到了机器断电,只需要将WAL中的数据回放到Region中即可:

在HBase中,默认一个RegionServer只有一个可写的WAL文件。WAL中写入的记录,以Entry为基本单元,而一个Entry中,包含:
WALKey 包含{Encoded Region Name,Table Name,Sequence ID,Timestamp}等关键信息,其中,Sequence ID在维持数据一致性方面起到了关键作用,可以理解为一个事务ID。
WALEdit WALEdit中直接保存待写入数据的所有的KeyValues,而这些KeyValues可能来自一个Region中的多行数据。
WAL Roll
当正在写的WAL文件达到一定大小以后,会创建一个新的WAL文件

WAL Archive
如果一个WAL中所关联的所有的Region中的数据,都已经被持久化存储了,那么,这个WAL文件会被暂时归档到另外一个目录中:

- WAL文件通常不允许直接被删除,至于何时可以被清理,还需要额外的控制逻辑
WAL的挑战与优化
- Q: 高并发随机写入如何优化?
利用Disruptor提升写并发性能
利用化零为整的思想,合并执行Sync操作,可以降低Sync次数,提高吞吐量。
- Q: 如何提高IOPS(Input/Output Operations Per Second)?
如果拥有多块磁盘
Multi-WAL可以在一个RegionServer中同时启动几个WAL Writer,可按照一定的策略,将一个Region与其中某一个WAL Writer绑定,这样可以充分发挥多块盘的性能优势。
六、写MemStore
MemStore中用来存放所有的KeyValue的数据结构,称之为CellSet,而CellSet的核心是一个ConcurrentSkipListMap,我们知道,ConcurrentSkipListMap是Java的跳表实现,数据按照Key值有序存放,而且在高并发写入时,性能远高于ConcurrentHashMap。

Q: 先写WAL还是先写MemStore?
在0.94版本之前,Region中的写入顺序是先写WAL再写MemStore,这与WAL的定义也相符。
但在0.94版本中,将这两者的顺序颠倒了,当时颠倒的初衷,是为了使得行锁能够在WAL sync之前先释放,从而可以提升针对单行数据的更新性能。详细问题单,请参考HBASE-4528。
在2.0版本中,这一行为又被改回去了,原因在于修改了行锁机制以后(下面章节将讲到),发现了一些性能下降,而HBASE-4528中的优化却无法再发挥作用,详情请参考HBASE-15158。改动之后的逻辑也更简洁了。
七、HFile
MemStore达到设置的阈值后则把数据刷成一个磁盘上的StoreFile文件。
总结
本文简单了解HBase写流程,对于wal、memstore、HFile的细节,将在后续中详细展开。
参考文献
hbase实践之写流程的更多相关文章
- hbase实践之写流程拾遗
keyvalue KeyValue中包含了丰富的自我描述信息: KeyValue是支撑"稀疏矩阵"设计的一个关键点:一些Key相同的任意数量的独立KeyValue就可以构成一行数据 ...
- hbase实践之flush and compaction
本文主要涉及flush流程,探讨flush流程过程中引入的问题并阐述2种解决策略,最后简要说明Flush执行策略. 对于Compaction,本文主要探讨Compaction要解决的本质问题以及由Co ...
- Raid1源代码分析--写流程
正确写流程的总体步骤是,raid1接收上层的写bio,申请一个r1_bio结构,将其中的所有bios[]指向该bio.假设盘阵中有N块盘.然后克隆N份上层的bio结构,并分别将每个bios[]指向克隆 ...
- 如何使用 CODING 实践 DevOps 全流程
你好,欢迎使用 CODING!这份最佳实践将帮助你通过 CODING 研发管理系统来更好地实践 DevOps 流程. DevOps 的本质是打破各个部门之间的隔阂,打通企业的前中后台,推进跨部门协作. ...
- HDFS写流程
HDFS client首先会与NameNode交互元数据信息,然后NameNode制定策略,分配NameNode节点,客户端先会与离自己最近的DataNode进行socket连接,已经与DataNod ...
- HBase最佳实践-写性能优化策略
本篇文章来说道说道如何诊断HBase写数据的异常问题以及优化写性能.和读相比,HBase写数据流程倒是显得很简单:数据先顺序写入HLog,再写入对应的缓存Memstore,当Memstore中数据大小 ...
- HBase实践案例:知乎 AI 用户模型服务性能优化实践
用户模型简介 知乎 AI 用户模型服务于知乎两亿多用户,主要为首页.推荐.广告.知识服务.想法.关注页等业务场景提供数据和服务, 例如首页个性化 Feed 的召回和排序.相关回答等用到的用户长期兴趣特 ...
- hbase实践之协处理器Coprocessor
HBase客户端查询存在的问题 Scan 用Get/Scan查询数据, Filter 用Filter查询特定数据 以上情况只适合几千行数据以及不是很多的列的"小数据". 当表扩展为 ...
- hbase实践(十六) BlockCache
0 引言 和其他数据库一样,优化IO也是HBase提升性能的不二法宝,而提供缓存更是优化的重中之重. 根据二八法则,80%的业务请求都集中在20%的热点数据上,因此将这部分数据缓存起就可以极大地提升系 ...
随机推荐
- vue文字向上滚动
<template> <vue-seamless-scroll :data="listData" :class-option="optionHover& ...
- COCO数据集使用
一.简介 官方网站:http://cocodataset.org/全称:Microsoft Common Objects in Context (MS COCO)支持任务:Detection.Keyp ...
- 【AtCoder】ARC062
ARC062 C - AtCoDeerくんと選挙速報 / AtCoDeer and Election Report 每次看看比率至少变成多少倍能大于当前的数 然后就把两个人的票都改成那个数 #incl ...
- redis集群(多机)分布
一.实现原理 一致性哈希算法(Consistent Hashing): http://www.zsythink.net/archives/1182 二.配置两个redis服务,端口号要不一致 三.代码 ...
- @WebServlet注解
@WebServlet("/LoginServlet") jsp页面: <form action="LoginServlet" method = &quo ...
- 使用haystack实现django全文检索搜索引擎功能
前言 django是python语言的一个web框架,功能强大.配合一些插件可为web网站很方便地添加搜索功能. 搜索引擎使用whoosh,是一个纯python实现的全文搜索引擎,小巧简单. 中文搜索 ...
- Asp.net core 学习笔记 ef core Surrogate Key, Natural Key, Alternate Keys
更新: 2019-12-23 foreignkey 并不一样要配上 alternate key,其实只要是 unique 就可以了. 和 sql server 是一样的, 经常有一种错觉 primar ...
- 怎样理解undefined和 null
前言: undefined表示 "未定义", null 表示 "空" 第一步: 一般在变量或属性没有声明或者声明以后没有赋值时, 这个变量的值就是undefin ...
- .Net下二进制形式的文件存储与读取
.Net下图片的常见存储与读取凡是有以下几种:存储图片:以二进制的形式存储图片时,要把数据库中的字段设置为Image数据类型(SQL Server),存储的数据是Byte[].1.参数是图片路径:返回 ...
- C# 关键字 virtual、override和new的用法
代码如下: class A { public void foo() { Console.WriteLine("A::foo()"); } public virtual void b ...