11_Hive TransForm 案例
1.需求:将Json格式的数据处理后插入新表中
数据文件如下:rating.json,文件格式:{"movie":"2858","rate":"5","timeStamp":"978159467","uid":"17"}
- {"movie":"2028","rate":"5","timeStamp":"978301619","uid":"1"}
- {"movie":"531","rate":"4","timeStamp":"978302149","uid":"1"}
- {"movie":"3114","rate":"4","timeStamp":"978302174","uid":"1"}
- {"movie":"608","rate":"4","timeStamp":"978301398","uid":"1"}
- {"movie":"1246","rate":"4","timeStamp":"978302091","uid":"1"}
- {"movie":"1357","rate":"5","timeStamp":"978298709","uid":"2"}
- {"movie":"3068","rate":"4","timeStamp":"978299000","uid":"3"}
- {"movie":"1537","rate":"4","timeStamp":"978299620","uid":"3"}
- {"movie":"434","rate":"2","timeStamp":"978300174","uid":"4"}
- {"movie":"2126","rate":"3","timeStamp":"978300123","uid":"5"}
- {"movie":"2067","rate":"5","timeStamp":"978298625","uid":"6"}
- {"movie":"1265","rate":"3","timeStamp":"978299712","uid":"7"}
实现步骤:
1.使用Hive创建原始表rate_json,并将rating.json文件加载到该表
hive> create table rat_json(line string) row format delimited;
hive> load data local inpath '/root/rating.json' into table rat_json;
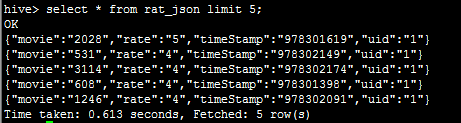
2.实现方案1:自定义函数实现json数据字段的切分
2.1:开发java类继承UDF,然后重载evaluate方法
2.2:上传jar包至服务器,并将jar包添加到hive的classpath下:hive>add jar /data/udf.jar;
2.3:创建临时函数与开发好的java class关联:create temporary function parsejson as 'cn.hive.demo.JsonParser';
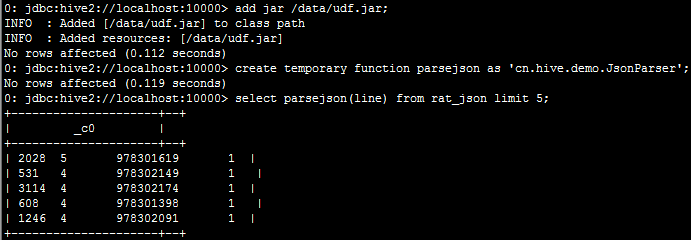
3.实现方案2:使用内置函数split进行字段切分,然后保存到一张新表中;

insert overwrite table t_rating
select split(parsejson(line),'\t')[0]as movieid,split(parsejson(line),'\t')[1] as rate,
split(parsejson(line),'\t')[2] as timestring,split(parsejson(line),'\t')[3] as uid
from rat_json limit 10;

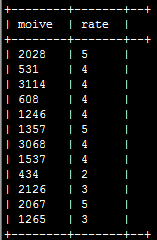
4.实现方案3:使用内置jason函数;
select get_json_object(line,'$.movie') as moive,get_json_object(line,'$.rate') as rate from rat_json;
5.实现方案4:Hive的 Transform 关键字提供了在SQL中调用自写脚本的功能,适合实现Hive中没有的功能又不想写UDF的情况
使用transform+python脚本的方式
根据上述过程,将原始表rat_json中的json格式的数据进行切分并存储到t_rating表中:
5.1:编辑一个Python脚本:weekday_mapper.py
- #!/bin/python
- import sys
- import datetime
- for line in sys.stdin://标准输出到屏幕上的东西
- line = line.strip()
- movieid, rating, unixtime,userid = line.split('\t')//t_rating表输出到屏幕上的数据是以table键隔开显示的
- weekday = datetime.datetime.fromtimestamp(float(unixtime)).isoweekday()
- print '\t'.join([movieid, rating, str(weekday),userid])
5.2:将文件加入hive的classpath:hive> add file /root/weekday_mapper.py;
5.3:执行查询
hive>create table u_data_new as
SELECT
TRANSFORM (movieid, rate, timestring,uid)
USING 'python weekday_mapper.py'
AS (movieid, rate, weekday,uid)
FROM t_rating;
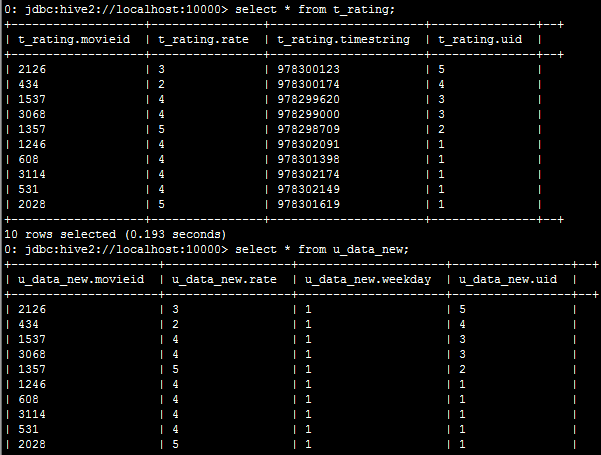
使用transform+python的方式去转换unixtime为weekday
11_Hive TransForm 案例的更多相关文章
- day11hadoop高可用和Hive
PS:视频一直就是在演示 高可用(比较偏运维一点) PS:Active是对外提供服务的,standBy是从属备用的:但是他们是怎样保证同步的数据的呢?一个运行中zookeeper上的第三方那个工具 ...
- Hive的DML操作
1. Load 在将数据加载到表中时,Hive 不会进行任何转换.加载操作是将数据文件移动到与 Hive表对应的位置的纯复制/移动操作. 语法结构: load data [local] inpath ...
- css3 知识点积累
-moz- 兼容火狐浏览器-webkit- 兼容chrome 和safari1.角度 transform:rotate(30dge) 水平线与div 第四象限30度 transform: ...
- 机械表小案例之transform的应用
这个小案例主要是对transform的应用. 时钟的3个表针分别是3个png图片,通过setInterval来让图片转动.时,分,秒的转动角度分别是30,6,6度. 首先,通过new Date函数获取 ...
- 56、Spark Streaming: transform以及实时黑名单过滤案例实战
一.transform以及实时黑名单过滤案例实战 1.概述 transform操作,应用在DStream上时,可以用于执行任意的RDD到RDD的转换操作.它可以用于实现,DStream API中所没有 ...
- H5案例分享:移动端滑屏 touch事件
移动端滑屏 touch事件 移动端触屏滑动的效果的效果在电子设备上已经被应用的越来越广泛,类似于PC端的图片轮播,但是在移动设备上,要实现这种轮播的效果,就需要用到核心的touch事件.处理touch ...
- 通过案例对 spark streaming 透彻理解三板斧之三:spark streaming运行机制与架构
本期内容: 1. Spark Streaming Job架构与运行机制 2. Spark Streaming 容错架构与运行机制 事实上时间是不存在的,是由人的感官系统感觉时间的存在而已,是一种虚幻的 ...
- 通过案例对 spark streaming 透彻理解三板斧之一: spark streaming 另类实验
本期内容 : spark streaming另类在线实验 瞬间理解spark streaming本质 一. 我们最开始将从Spark Streaming入手 为何从Spark Streaming切入 ...
- 精选19款华丽的HTML5动画和实用案例
下面是本人收集的19款超酷HTML5动画和实用案例,觉得不错,分享给大家. 1.HTML5 Canvas火焰喷射动画效果 还记得以前分享过的一款HTML5烟花动画HTML5 Canvas烟花特效,今天 ...
随机推荐
- windows下初安装xgboost
1.先检查一下自己的版本,如图python3.6,win64 我的之前环境是已经安装了anaconda. 2.去相关的网站下载 3.把下载的文件拷到此目录下(同pip在一个目录下) 4.cmd在此目录 ...
- CSS - clearfix清除浮动
首先,我们来解释一下为什么要使用 clearfix(清除浮动). 通常我们在写html+css的时候,如果一个父级元素内部的子元素是浮动的(float),那么常会发生父元素不能被子元素正常撑开的情况, ...
- 移动端自动化测试之android模拟器问题集合
黑屏 在做移动端自动化测试过程中,android模拟器启动黑屏的问题一直困扰着我,网上找了许多方法尝试了都不能解决我的问题,最后重新安装了镜像文件,问题才得以解决,当然并不是网上的解决办法都是错的,只 ...
- 【ARM-Linux开发】arm-none-Linux-gnueabi-gcc下载安装
arm-none-Linux-gnueabi-gcc是 Codesourcery 公司(目前已经被Mentor收购)基于GCC推出的的ARM交叉编译工具.可用于交叉编译ARM系统中所有环节的代码,包括 ...
- 阻止移动端input按钮聚焦时唤起软键盘的方法
一.设置input为readonly 二.使用JS代码,在input按钮fous时就让其blur
- 36.HTTP协议
HTTP简介 HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW:World Wide Web )服务器传输超文本到本地浏览器的传送 ...
- CentOS 7系统KVM虚拟机安装过程详解
什么是 KVM ? KVM 在标准的 Linux 内核中增加了虚拟技术,从而我们可以通过优化的内核来使用虚拟技术.在 KVM 模型中,每一个虚拟机都是一个由 Linux 调度程序管理的标准进程,你可以 ...
- 《你必须知道的495个C语言问题》读书笔记之第4-7章:指针
1. Q:为什么我不能对void *指针进行算术运算? A:因为编译器不知道所值对象的大小,而指针的算法运算总是基于所指对象的大小的. 2. Q:C语言可以“按引用传参”吗? A:不可以.严格来说,C ...
- Java基础语法知识你真的都会吗?
第一阶段 JAVA基础知识 第二章 Java基础语法知识 在我们开始讲解程序之前,命名规范是我们不得不提的一个话题,虽说命名本应该是自由的,但是仍然有一定的"潜规则",通过你对命名 ...
- Facebook推荐算法模型DLRM解读
参考:https://mp.weixin.qq.com/s/mUNjLuOG2UvztCEP3wyPPw 代码:https://github.com/facebookresearch/dlrm