实时跟踪之TRACA
背景:
目前,在实时跟踪领域存在着越来越多的先进方法,同时也极大地促进了该领域的发展。主要有两种不同的基于深度学习的跟踪方法:1、由在线跟踪器组成,这些跟踪器依赖网络连续的微调来学习目标的变化外观,精度虽高,但无法满足实时要求;2、基于相关滤波器的跟踪器组成,利用原始深度卷积特征,如Imagenet中包含的一般对象,存在高维度的问题,另外,相关滤波器计算时间随着特征维度的增加而增加,也不满足实时要求。
在2018年的CVPR会议上,出现了这样一篇文章:《Context-aware Deep Feature Compression for High-speed Visual Tracking》,引起了不小的反响。主要提出了一种新的基于上下文感知的相关滤波器的跟踪框架,以实现一个实时跟踪器。在计算速度和精度方面都有着不错的成绩。速度提升主要来源于深度特征压缩,利用多个expert auto-encoder的上下文感知方案;上下文是指根据不同层特征图对跟踪目标的粗略分类。在预训练阶段,每个类别训练一个expert auto-encoder。在跟踪阶段,指定一个最佳expert auto-encoder。为了实现高效跟踪性能,引入外部去噪处理和新的正交性损失项orthogonality loss,用于expert auto-encoder的预训练和微调。在保持当前最佳性能的同时,可以达到100fps的速度。
正文:
本文提出了一种基于相关滤波器的跟踪器,使用原始深度特征的上下文感知压缩,可减少计算时间,从而提高了速度。较低维度的特征图可以充分地表示单个目标对象,可从大数据集的分类和检测任务中学到;使用自动编码器将高维特征压缩成低维特征图。采用了多个自动编码器,每个编码器专门用于特定类别的对象,被称为expert auto-encoder。
引入了一种无监督的方法,通过根据上下文信息聚类训练样本来找到类别,然后每个群集训练一个expert auto-encoder。在视觉跟踪期间,特定的目标根据上下文感知网络选择一个最合适的expert auto-encoder。根据一个考虑到相关滤波器的相关性的新颖的损失函数微调选择的expert auto-encoder,之后得到压缩特征图。压缩特征图减少了冗余和减轻了稀疏性,这提高了跟踪框架的准确性和计算效率。为了跟踪目标,将相关滤波器应用于压缩特征图。

图1 CVPR2013数据集
主要创新点:
基于上下文信息的深度特征压缩与多个自动编码器(TRACA)的TRAcker提议由多个expert auto-encoder,上下文感知网络和相关滤波器组成,如图2所示。expert auto-encoder可以强大地压缩VGG-Net的原始深度卷积特征。它们中的每一个都根据不同的上下文进行训练,从而执行依赖于上下文的压缩。我们建议使用上下文感知网络来选择最适合特定跟踪目标的expert auto-encoder,并且在线跟踪期间仅运行此自动编码器。在推荐选择的expert auto-encoder适用于跟踪特定目标之后,其压缩特征图被用作在线跟踪目标的相关滤波器的输入。

图2提出的算法方案。 专家自动编码器由上下文感知网络选择,并由初始帧(I(1))处的ROI部分微调一次。对于以下帧,我们首先提取以前一目标位置为中心的ROI patch(I(t))。然后,通过VGG-Net获得原始深度卷积特征(X),并由微调专家自动编码器压缩。压缩特征(Z 0)用作相关滤波器的特征图,目标的位置由滤波器响应的峰值位置确定。在每帧之后,通过新发现的目标的压缩特征在线更新相关滤波器。
1、专家级自动编码器Expert auto-encoders
自动编码器适用于无监督学习的特征。提供了一种学习输入的紧凑表示的方法,同时保留最重要的信息在紧凑的表示下恢复输入。本文使用一组相同的Ne auto-encoders,每个编码器覆盖不同的上下文。要压缩的输入是从VGG-Net中的一个卷积层获得的原始深度卷积特征图。为了实现高压缩比,我们堆叠N1个编码层,后面跟着自动编码器中的N1个解码层。第l层编码层f-l是一个卷积层,f-l:Rwxhxcl->Rwxhxcl+1,从而减少了通道数,保持了特征图的大小。f-l的输出作为为fl+1的输入,使得通道数c随着特征图通过编码层而减小。一个编码层将通道数减少了一半,i.e. cl+1 = cl/2 for l ∈ {1, · · · , N l }。在第(Nl − k + 1)解码层,g-k使用与f-l相反的方式解码,gk : Rw×h×c k+1 → R w×h×c k 扩展输入的通道数从c_k+1 到c_k,在解码器的最后一层回复X的原始通道数到C1.于是自动编码器可以表示成AE(X) ≡ g1 (· · · (g N l (f N l (· · · (f 1 (X))))) ∈ R w×h×c1,对于原始卷积特征图X∈Rw×h×c1。自动编码器中的压缩特征映射定义为Z≡fN l(···(f1(X)))∈Rw×h×c Nl +1。所有卷积层之后是ReLU激活函数,其卷积滤波器的大小设置为3×3。
预训练
expert auto-encoders的预训练阶段分为三个部分,每个部分都有不同的用途。首先,我们使用所有训练样本训练 auto-encoders AE0,以找到与上下文无关的初始压缩特征图。然后,我们对AE0得到的初始压缩特征图执行上下文聚类,以找到Ne个依赖于上下文的集合。最后,这些集合被用于训练expert auto-encoders,利用其中的一个集合初始化expert auto-encoders。
使用基本自动编码器的目的有两个:使用与上下文无关的压缩特征图来聚类训练样本,并找到良好的初始权重参数,expert auto-encoders可以从中进行微调。基本自动编码器由原始卷积特征图{Xj} mj = 1训练,batch大小为m。X j来自VGG-Net卷积层的输出,输入图像为来自诸如ImageNet的大图像数据库的随机选择的训练图像。
为了使基本自动编码器对外观变化和遮挡更加鲁棒,我们使用两个去噪标准来帮助捕获输入分布中的不同结构(如图3所示)。第一个去噪准则是一个通道破坏过程,其中随机选择固定数量的特征通道,并将这些通道的值设置为0。移除了这些通道的所有信息,并且训练自动编码器以恢复该信息。第二个标准是交换过程,其中卷积特征的一些空间特征向量是随机互换的。由于特征向量的感受域覆盖图像内的不同区域,因此交换特征向量类似于在输入图像内交换区域。因此,交换背景区域和目标区域的特征向量起到了类似遮挡目标的效果。我们记{ X̌ j } mj=1是经过两步去噪之后的批次。然后我们可以通过最小化 原始的特征图和输入去噪特征图自动编码生成的特征图的距离,来训练基础的自动编码器。
当只考虑基本自动编码器的输入和最终输出之间的距离时,经常会出现过拟合和不稳定的训练收敛。为了解决该类问题,设计了一个新的损失函数:这个损失由部分自动编码器的输入和输出的距离组成。部分自动编码器{AEi (X)} Ni=1 仅包含其原始自动编码器AE(X)的一部分编码和解码层,而输入和输出大小与原始自动编码器的大小一样,i.e. AE 1 (X) = g 1 (f 1 (X)),AE 2 (X) = g 1 (g 2 (f 2 (f 1 (X)))), · · · when AE(X) =g 1 (· · · (g N l (f N l (· · · (f 1 (X)))))).因此,基于多级距离的损失可以描述为
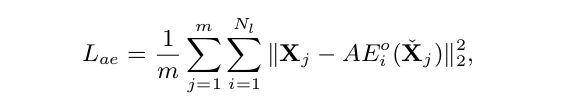
其中AE i o(X)是AE o(X)的第i个部分自动编码器,并且m表示批量大小。
根据由基本自动编码器压缩的各个样本的特征图,对训练样本{I j} Nj = 1进行聚类,其中N表示训练样本的总数。为了避免由于聚类得到簇太小而导致expert auto-encoders过度拟合,我们引入了两步聚类算法,避免了小簇。
第一步,我们找到2Ne样本,这些样本是从基本自动编码器压缩的特征图中随机选择的(请注意,这是所需群集量的两倍,Ne为指定的聚类个数)。我们重复1000次随机选择,找到其中欧几里德距离最大的样本作为初始质心。然后,使用k = 2Ne,对所有样本的压缩特征图像使用K-means进行聚类;
第二步,我们在得到的2NE个聚类中心,去除其中的NE个小的聚类中心。然后在使用这些聚类中心聚类,这样就保证了每个类都有足够多的样本,防止过拟合。我们将I j的聚类索引表示为dj∈{1,...,N e}。第d个expert auto-encoders AE-d是有基本的自动编码器在第d簇上微调后得到的。训练过程(包括去噪标准)与训练样本中的基本自动编码器不同。
2、基于上下文的网络 Context-aware Network
结构:上下文感知网络选择在上下文中最适合给定跟踪目标的expert auto-encoders,我们采用预先训练的VGG-M模型[3]用于上下文感知网络,因为它包含来自ImageNet预训练的大量语义信息。输入是一张224*224的RGB图片,上下文唤醒网络,先是有三个卷积层组成{conv1,conv2,conv3},后面跟了3个全连接层{fc4,fc5,fc6},其中{conv1,conv2,conv3,fc4}与VGG-M中相对应的层相同。fc5和fc6的参数以均值为0的高斯分布随机初始化。fc5之后是RELU,有1024个输出节点.最后,fc6具有Ne个输出节点并且与softmax层组合以估计每个expert auto-encoders适合于跟踪目标的概率。
预训练:
上下文感知网络将训练样本I j作为输入,并输出属于簇索引d j的该样本的估计概率。它通过批量{I j,d j} mj = 1的图像/聚类索引对进行训练,其中m 0是上下文感知网络的小批量大小。通过预训练,调整{conv1,conv2,conv3,fc4}的参数,训练{fc5,fc6}的权重,通过最小化多类损失函数L-pr使用随机梯度下降。
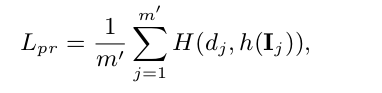
H表示交叉熵损失,h(Ij)是上下文唤醒网络h,预测的Ij属于的簇的索引。
3、协同过滤Correlation Filter
先简要介绍使用单通道特征映射的传统相关滤波器的功能。基于傅立叶域中的循环矩阵的性质,可以快速训练相关滤波器,这导致在低计算负荷下的高性能跟踪器。给定矢量化单通道训练特征图z∈Rwh×1,从2-D高斯窗口获得矢量化目标响应图y,其大小为w×h和方差σy2,矢量化相关滤波器w可以通过以下方式估算: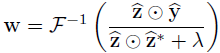
其中ŷ和ẑ分别代表y和z的傅里叶变换矢量,ẑ∗是z的共轭向量, 代表逐元素相乘。F ^(−1)代表代表逆傅里叶变换函数,λ是预定义的正则化因子。对于矢量化单通道测试的特征图z0∈wh×1R,矢量化响应图r可以通过以下方式获得:
代表逐元素相乘。F ^(−1)代表代表逆傅里叶变换函数,λ是预定义的正则化因子。对于矢量化单通道测试的特征图z0∈wh×1R,矢量化响应图r可以通过以下方式获得: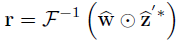
然后,在从r重建2-D响应图R∈Rw×h之后,从R的最大峰值位置找到目标位置。
4、跟踪过程Tracking Process
初始适应过程包含以下部分:
我们首先从初始帧提取包括目标的感兴趣区域(ROI),并且由上下文感知网络选择适合于目标的expert auto-encoders。然后,使用从ROI增强的训练样本的原始卷积特征图来微调所选择的expert auto-encoders。当我们从微调expert auto-encoders获得压缩特征图时,它的一些通道代表背景对象而不是目标。因此,我们引入了一种算法来查找和删除响应背景对象的通道。
感兴趣区域提取:ROI以目标的初始边界框为中心,比目标的大小大2.5倍,覆盖附近区域。然后,我们将宽度W和高度H的ROI调整为224×224,以匹配VGG-Net的预期输入大小。这使ROI区域变成了在RGB颜色空间上的I (1) ∈ R 224×224×3。对于灰度图像,灰度值被复制到三个通道上,得到I(1)。使用上下文感知网络h根据初始目标的上下文信息选择用于跟踪场景的最佳expert auto-encoders,并且我们可以将该自动编码器表示为AEh(I)。
初始样本增强:即使我们使用前面描述的两个去噪标准,我们发现expert auto-encoders的压缩特征图也存在使目标变得模糊或被翻转的问题。因此,在微调所选expert auto-encoders之前,我们以多种方式增强I(1)。为了解决模糊问题,通过用具有方 差{0.5,1.0,1.5,2.0}的高斯滤波器对I(1)进行滤波来获得四个增强图像;分别通过围绕垂直轴和水平轴翻转I(1)来获得另外两个增强图像。然后,从增强的(1)样本中提取的原始卷积特征图可以表示成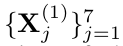
微调: 所选自动编码器的微调与expert auto-encoders的预训练过程不同。由于缺乏训练样本,优化很少在应用去噪标准时收敛。相反,我们使用相关滤波器正交性损失L ad,其考虑从expert auto-encoders的压缩特征图估计的相关滤波器的正交性,其中L定义为:
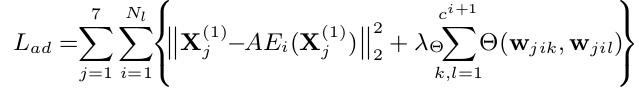
其中 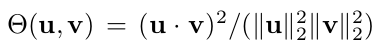
由方程(3)估计的矢量化相关滤波器,其使用来自所选expert auto-encoders的压缩特征映射(1)fi(···(f 1(X j)))的矢量化第k个通道。 相关滤波器正交性损失允许增加相关滤波器之间的相互作用,如从压缩特征图的不同信道估计。通过使用随机梯度下降最小化L ad的区别在补充材料的附录A中描述。
背景频道删除:压缩特征映射Z∀可以从微调expert auto-encoders获得。然后,我们删除Z∀内的通道,这些通道在目标边界框之外有大的响应。通过估计通道中前景和背景特征响应的比率来找到这些通道。首先,我们估计通道k的特征响应的 channel-wise比率为
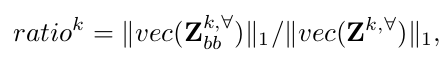
 是特征图
是特征图 第K个通道的特征图,
第K个通道的特征图, 是特征图第K个通道将bounding box之外的区域设置为0得到的。然后,在按照ratio-k以降序对所有信道进行排序之后,仅将压缩特征映射的前N c个信道用作相关滤波器的输入。我们将得到的特征图表示为Z∈RS×S×N c,其中S是特征尺寸。
是特征图第K个通道将bounding box之外的区域设置为0得到的。然后,在按照ratio-k以降序对所有信道进行排序之后,仅将压缩特征映射的前N c个信道用作相关滤波器的输入。我们将得到的特征图表示为Z∈RS×S×N c,其中S是特征尺寸。
5、在线跟踪顺序Online Tracking Sequence
相关滤波器估算和更新:我们首先使用与初始适应中相同的方法获得当前帧t的调整后的ROI,即,调整后的ROI以目标的中心为中心,其大小是目标大小的2.5倍并且调整为224×224。在将调整后的ROI馈送到VGG-Net之后,得到原始深度卷及特征,通过将VGG-Net的原始深度卷积特征图输入到自适应expert auto-encoders中,我们获得压缩特征映射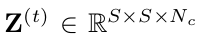 。
。
之后我们使用等式3,我们估计独立的相关滤波器的参数 ,根据每个特征图
,根据每个特征图 的第K个通道. 是特征图
的第K个通道. 是特征图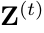 的第K个通道。参照【16】的方法,我们通过将每个与相同大小的余弦窗口相乘来抑制背景区域。 对于第一帧,我们可以根据
的第K个通道。参照【16】的方法,我们通过将每个与相同大小的余弦窗口相乘来抑制背景区域。 对于第一帧,我们可以根据 使用方程(3)估计相关滤波器
使用方程(3)估计相关滤波器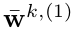
对于之后的帧(t> 1),相关过滤器更新如下: 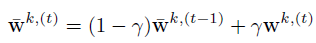 , 其中γ是插值因子。
, 其中γ是插值因子。
跟踪:在估计相关滤波器之后,我需要寻找t帧物体的位置 。由于我们假设接近前一帧
。由于我们假设接近前一帧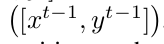 中的目标位置,我们从与前一帧的相关滤波器估计的ROI相同的位置提取跟踪ROI。这样我们就可以得到由适应的expert auto-encoder生成的特征压缩图
中的目标位置,我们从与前一帧的相关滤波器估计的ROI相同的位置提取跟踪ROI。这样我们就可以得到由适应的expert auto-encoder生成的特征压缩图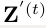 用于追踪,把和
用于追踪,把和 用于等式(4),得到通道处理过的相应图
用于等式(4),得到通道处理过的相应图 (我们以与相关滤波器估计相同的方式应用余弦窗的乘法)。
(我们以与相关滤波器估计相同的方式应用余弦窗的乘法)。
我们需要将组合成综合相应图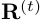 。我们使用加权平均方案,其中我们使用验证分数
。我们使用加权平均方案,其中我们使用验证分数 作为权重因子。
作为权重因子。


是一个S*S的高斯窗口,方差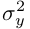 以的峰值
以的峰值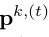 为中心。然后,综合响应图计算如下:
为中心。然后,综合响应图计算如下: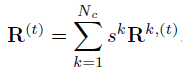
跟[5]一样,我们通过在峰值位置附近内插响应值来找到子像素目标位置。 最终目标的位置由计算: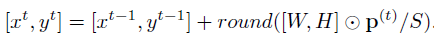
尺度变换:为了处理目标的比例变化,我们提取了两个额外的ROI补丁,这些补丁是从先前的ROI补丁大小缩放的,在跟踪序列中分别具有缩放因子1.015和1.015^(-1)。选择新的目标比例作为响应图(来自缩放的ROI)的相应最大值最大的比例。
完全遮挡处理:为了处理完全遮挡,采用了重新检测算法。 总体思路是引入所谓的重新检测相关滤波器,该滤波器未被更新并且在检测到遮挡时应用于目标的位置。当如上所述检测到最大(t)响应值Rmax≡max(R(t))的突然下降时,假设完全遮挡。如果满足该条件,则将时间(t-1)处的相关滤波器用作重新检测相关滤波器。在下一个N帧期间,如果重新检测滤波器的响应图的最大值大于由正常相关滤波器获得的响应图的最大值,则使用由重新检测相关滤波器确定的目标位置。
实验结果
使用VGG-M第2层卷积conv2的特征响应来作为原始卷积特征的输入。expert auto-encoders的数量Ne设置成10,深度Nl设置成2,所有auto-encoders的批量大小m设置10,针对auto-encoders的基础学习率设置成1e-10,针对expert auto-encoders的基础学习率设置成1e-9。auto-encoders的训练周期为10个epochs,expert auto-encoders为30个epochs。针对内在去噪两种方法的设置比率都为10%。训练context-aware network时,批量大小和学习率分别设置为m‘ =100,lr=0.01.正交化损失的权重设置成 ,在背景通道移除Nc=25后减少通道维度。基于跟踪的协同过滤参数:
,在背景通道移除Nc=25后减少通道维度。基于跟踪的协同过滤参数: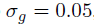 ,
,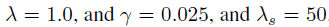 。全挡住物体的参数:
。全挡住物体的参数: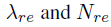
分别设置为0.7和50.
使用MATLAB和MatConvNet工具完成推荐框架。
计算环境:Intel i7-2700K CPU @ 3.50GHz, 16GB RAM, and an NVIDIA GTX1080 GPU
计算速度:在CVPR2013数据含有上达到101.3FPS
数据集:
使用VOC2012分类图像数据集的来预训练expert auto-encoders和context-aware network。使用CVPR2013数据集(51 target,50 videos),TPAMI2015(100 targets,98 videos)来评估该框架,其中每一帧都包含了真实目标的检测框。
评价方法:
作为性能测量,我们使用单程评估(OPE)的平均精度曲线。通过平均所有序列的精确度曲线来估计平均精确度曲线,其使用两个来源获得:位置误差阈值和重叠阈值。作为跟踪器的代表性分数,使用当位置误差阈值等于20个像素时的平均精度和成功曲线的曲线下面积。


参考链接:
1、https://blog.csdn.net/qq_34135560/article/details/83755395
2、https://blog.csdn.net/ms961516792/article/details/81412356
3、https://blog.csdn.net/weixin_40645129/article/details/81173088
实时跟踪之TRACA的更多相关文章
- Bugtags 实时跟踪插件 - BugtagsInsta
BugtagsInsta 是 Bugtags SDK 的官方插件,应用集成成功后,可以在 Bugtags 云端管理平台实时查看应用的运行时数据:操作步骤.用户数据.控制台日志.Bugtags 日志.网 ...
- xshell实时跟踪日志与中文乱码设置
1.实时跟踪日志命令 tail -f logName.log 动态查看名为logName的日志信息 ctrl+c 退出实时跟踪 2.中文乱码设置 在Xshell.putty.SSH Secure Sh ...
- 存储opline的内存地址可以实时跟踪opcode的执行
static intphp_handler(request_rec *r) { /* Initiliaze the context */ php_struct * volatile ctx; void ...
- tail -f 实时跟踪一个日志文件的输出内容
tail -f 实时跟踪一个日志文件的输出内容 http://hittyt.iteye.com/blog/1927026 https://blog.csdn.net/mengxianhua/arti ...
- 实时跟踪log变化的工具Apachetop
作为一个网站管理员,我们经常会有需要知道当前什么人正在访问我们的网站,谁正在频繁的抓取我们网站的内容,什么搜索引擎正在抓取我们网站?面对这些问题,我们虽然可以去查看log日志文件,但是却不能让我们实时 ...
- Android+OpenCV 摄像头实时识别模板图像并跟踪
通过电脑摄像头识别事先指定的模板图像,实时跟踪模板图像的移动[用灰色矩形框标识] ps:一开始以为必须使用OpenCV Manager,可是这样会导致还需要用户去额外安装一个apk,造成用户体验很差, ...
- 实时观察Apache访问情况的工具Apachetop
Linux服务器的负载.进程等信息可以通过top命令查看.而Apache的运转如何实时的观察呢?“tail -f”log文件?这是个好方法,但是太累了! 所以,感谢Chris Elsworth为我们提 ...
- TLD目标跟踪算法
1. 简介 TLD目标跟踪算法是Tracking-Learning-Detection算法的简称.这个视频跟踪算法框架由英国萨里大学的一个捷克籍博士生Zdenek Kalal提出.TLD将传统的视频跟 ...
- 推荐windows下的日志跟踪工具:SnakeTail
用过Linux的同学都知道,在Linux中要实时跟踪日志文件那是非常的方便,Tail.Less都可以做到. 开启动态跟踪后,程序会监视文件修改,从而不断刷新出最新的内容,对于线上运维特别有用. 今 ...
随机推荐
- Node.js使用Express.Router
在实际开发中通常有几十甚至上百的路由,都写在 index.js 既臃肿又不好维护,这时可以使用 express.Router 实现更优雅的路由解决方案. 目录结构如下: routes的index.js ...
- 关于CAShapeLayer的一些基本操作
设置圆形进度条: 实现效果如下: 实现代码如下:(注释很详细啦!!!) UIView *circleView = [[UIView alloc]initWithFrame:CGRectMake(, , ...
- Unity 的 [HideInInspector]
[HideInInspector] public Transform t; public Transform mm; public Transform nn3; 在变量前面加入,作用:隐藏下一条在In ...
- Docker跨主机网络实践
Docker使用中网络管理是最麻烦的,在项目初始化前期就需要进行合理的规划,如果在比较理想的单主机的网络通信是比较简单的,但如果涉及到跨主机的网络就需要使用docker自带的overlay netwo ...
- K/3 Cloud 单据关联查询
销售出库单 下推 销售退货单,如何获知他们的关联关系?T_SAL_OUTSTOCKENTRY 是销售出库单分录T_SAL_RETURNSTOCKENTRY 是销售退货单分录T_SAL_RETURNST ...
- TensorFlow.资料
1.ZC:看来 要用 TensorFlow,基本逃不过 Python了... TensorFlow物体识别——通过机器学习搭建属于自己的物体识别库 - 迷途无归的博客 - CSDN博客.html(h ...
- 最新 前程无忧java校招面经 (含整理过的面试题大全)
从6月到10月,经过4个月努力和坚持,自己有幸拿到了网易雷火.京东.去哪儿.前程无忧等10家互联网公司的校招Offer,因为某些自身原因最终选择了前程无忧.6.7月主要是做系统复习.项目复盘.Leet ...
- CentOS7 安装mysql(YUM源方式)
1.下载mysql源安装包 $ wget http://dev.mysql.com/get/mysql57-community-release-el7-8.noarch.rpm 2.安装mysql ...
- Linux Centos下软件的安装与卸载方法
转载于: http://blog.csdn.net/zolalad/article/details/11368879 Linux下软件的安装与卸载 第一章 linux下安装软件,如何知道软件安 ...
- python之并发编程(概念篇)
一.进程 1.什么是进程 进程是正在进行的一个过程或者一个任务.而负责执行任务的则是cpu. 2.进程与程序的区别 程序并不能单独运行,只有将程序装载到内存中,系统为它分配资源才能运行,而这种执行的程 ...