100天搞定机器学习|Day3多元线性回归
前情回顾
[第二天100天搞定机器学习|Day2简单线性回归分析][1],我们学习了简单线性回归分析,这个模型非常简单,很容易理解。实现方式是sklearn中的LinearRegression,我们也学习了LinearRegression的四个参数,fit_intercept、normalize、copy_X、n_jobs。然后介绍了LinearRegression的几个用法,fit(X,y)、predict(X)、score(X,y)。最后学习了matplotlib.pyplot将训练集结果和测试集结果可视化。

多元线性回归分析与简单线性回归很相似,但是要复杂一些了(影响因素由一个变成多个)。它有几个假设前提需要注意,
①线性,自变量和因变量之间应该是线性的
②同方差,误差项方差恒定
③残差负荷正态分布
④无多重共线性
出现了一些新的名词,残差(残差是指实际观察值与回归估计值的差,【计量经济学名词】2绝对残差)、多重共线性(解释变量之间由于存在精确相关关系或高度相关关系而使模型估计失真或难以估计准确)。
对R感兴趣的同学可以看一下我之前分享的几篇文章
[R多元线性回归容易忽视的几个问题(1)多重共线性][2]
[R多元线性回归容易忽视的几个问题(2)多重共线性的克服][3]
[R多元线性回归容易忽视的几个问题(3)异方差性][4]
[R多元线性回归容易忽视的几个问题(4)异方差性的克服][5]
多元线性回归中还有虚拟变量和虚拟变量陷阱的概念
虚拟变量:分类数据,离散,数值有限且无序,比如性别可以分为男和女,回归模型中可以用虚拟变量表示,1表示男,0表示女。
虚拟变量陷阱:两个或多个变量高度相关,即一个变量一个变量可以由另一个预测得出。直观地说,有一个重复的类别:如果我们放弃了男性类别,则它在女性类别中被定义为零(女性值为零表示男性,反之亦然)。 虚拟变量陷阱的解决方案是删除一个分类变量 —— 如果有多个类别,则在模型中使用m-1。 遗漏的值可以被认为是参考值。
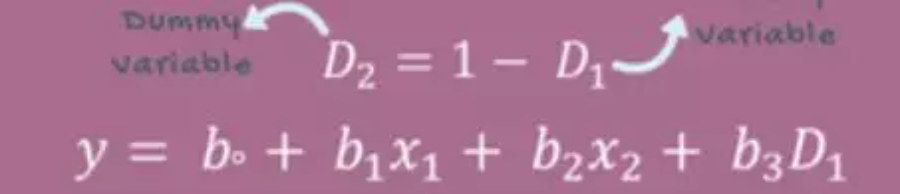
需要注意的是:变量并非越多越好,过多变量尤其是对输出没有影响的变量,可能导致模型预测精确度降低,所以要选择合适的变量,主要方法有三种,①向前选择(逐次加使RSS最小的自变量)②向后选择(逐次扔掉p值最大的变量)③双向选择
模型部分就是这样,下面开始python实现。
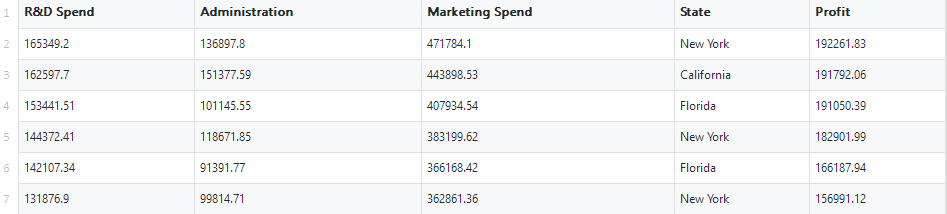
在开始操作之前,我们还是先观察一下数据,一共50组数据,有一些缺失值,也有虚拟变量(state:New York 、California、Florida)。

导入库
import pandas as pd
import numpy as np
导入数据集
dataset = pd.read_csv('50_Startups.csv')
X = dataset.iloc[ : , :-1].values
Y = dataset.iloc[ : , 4 ].values
将类别数据数字化
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
labelencoder = LabelEncoder()
X[: , 3] = labelencoder.fit_transform(X[ : , 3])
onehotencoder = OneHotEncoder(categorical_features = [3])
X = onehotencoder.fit_transform(X).toarray()
OneHotEncoderone-hot编码是一种对离散特征值的编码方式,在LR模型中常用到,用于给线性模型增加非线性能力。
躲避虚拟变量陷阱
X = X[: , 1:]
拆分数据集为训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size = 0.2, random_state = 0)
第2步: 在训练集上训练多元线性回归模型
from sklearn.linear_model import LinearRegression
regressor = LinearRegression()
regressor.fit(X_train, Y_train)
Step 3: 在测试集上预测结果
y_pred = regressor.predict(X_test)
个人感觉作为入门已经足够。但是多元线性回归分析是建立在上面说的四个假设前提上的(①线性,自变量和因变量之间应该是线性的②同方差,误差项方差恒定③残差负荷正态分布④无多重共线性),所以初步得到一个线性回归模型,并不一定可以直接拿来使用,还需要进行验证和诊断。

100天搞定机器学习|Day3多元线性回归的更多相关文章
- 100天搞定机器学习|Day11 实现KNN
机器学习100天|Day1数据预处理 100天搞定机器学习|Day2简单线性回归分析 100天搞定机器学习|Day3多元线性回归 100天搞定机器学习|Day4-6 逻辑回归 100天搞定机器学习|D ...
- 100天搞定机器学习|Day8 逻辑回归的数学原理
机器学习100天|Day1数据预处理 100天搞定机器学习|Day2简单线性回归分析 100天搞定机器学习|Day3多元线性回归 100天搞定机器学习|Day4-6 逻辑回归 100天搞定机器学习|D ...
- 100天搞定机器学习|Day9-12 支持向量机
机器学习100天|Day1数据预处理 100天搞定机器学习|Day2简单线性回归分析 100天搞定机器学习|Day3多元线性回归 100天搞定机器学习|Day4-6 逻辑回归 100天搞定机器学习|D ...
- 100天搞定机器学习|Day16 通过内核技巧实现SVM
前情回顾 机器学习100天|Day1数据预处理100天搞定机器学习|Day2简单线性回归分析100天搞定机器学习|Day3多元线性回归100天搞定机器学习|Day4-6 逻辑回归100天搞定机器学习| ...
- 100天搞定机器学习|Day17-18 神奇的逻辑回归
前情回顾 机器学习100天|Day1数据预处理 100天搞定机器学习|Day2简单线性回归分析 100天搞定机器学习|Day3多元线性回归 100天搞定机器学习|Day4-6 逻辑回归 100天搞定机 ...
- 100天搞定机器学习|Day19-20 加州理工学院公开课:机器学习与数据挖掘
前情回顾 机器学习100天|Day1数据预处理 100天搞定机器学习|Day2简单线性回归分析 100天搞定机器学习|Day3多元线性回归 100天搞定机器学习|Day4-6 逻辑回归 100天搞定机 ...
- 100天搞定机器学习|Day21 Beautiful Soup
前情回顾 机器学习100天|Day1数据预处理 100天搞定机器学习|Day2简单线性回归分析 100天搞定机器学习|Day3多元线性回归 100天搞定机器学习|Day4-6 逻辑回归 100天搞定机 ...
- 100天搞定机器学习|Day22 机器为什么能学习?
前情回顾 机器学习100天|Day1数据预处理 100天搞定机器学习|Day2简单线性回归分析 100天搞定机器学习|Day3多元线性回归 100天搞定机器学习|Day4-6 逻辑回归 100天搞定机 ...
- 100天搞定机器学习|Day33-34 随机森林
前情回顾 机器学习100天|Day1数据预处理 100天搞定机器学习|Day2简单线性回归分析 100天搞定机器学习|Day3多元线性回归 100天搞定机器学习|Day4-6 逻辑回归 100天搞定机 ...
随机推荐
- Yarn状态机
1 概述 为了增大并发性,Yarn采用事件驱动的并发模型,将各种处理逻辑抽象成事件和调度器,将事件的处理过程用状态机表示.什么是状态机? 如果一个对象,其构成为若干个状态,以及触发这些状态发生相互转移 ...
- ros资料记录,详细阅读
ROS源码分析--子话题-catkin:https://blog.csdn.net/sukha/article/details/52460492 ROS源码分析:https://blog.csdn.n ...
- 小程序tab切换代码
<!--index.wxml--> <view class="container"> <view class="navtap" & ...
- 关于$internalField边界条件【翻译】
翻译自:CFD-online 帖子地址:http://www.cfd-online.com/Forums/openfoam-pre-processing/122386-about-internalfi ...
- GO 类型断言
在Go语言中,我们可以使用type switch语句查询接口变量的真实数据类型,语法如下: switch x.(type) { // cases } x必须是接口类型. 来看一个详细的示例: type ...
- lucene正向索引(续)——每次commit会形成一个新的段,段"_1"的域和词向量信息可能存在"_0.fdt"和"_0.fdx”中
DocStoreOffset DocStoreSegment DocStoreIsCompoundFile 对于域(Stored Field)和词向量(Term Vector)的存储可以有不同的方式, ...
- hibernate的各种查询
Hibernate Query Language(HQL)Criteria QueryNative SQL下面对其分别进行解释select子句:有时并不需要取得对象的所有属性,这时可以使用select ...
- jeecg使用心得
接触到jeecg框架是在去年,接触到了jeecg开源框架,此框架为企业级急速开发框架,不了解的可以百度下这类框架的,对于目前状态来说,此框架确实也满足了所需,此刻就开始接触jeecg框架,去年六七月份 ...
- Angular 执行 css3 简单的动画
<div class="content"> 内容区域 <button (click)="showAside()">弹出侧边栏</b ...
- Android仿微信底部选项卡
第一步 添加依赖 dependencies { compile 'com.yinglan.alphatabs:library:1.0.5' } 第二步 布局使用 <?xml version=&q ...