sqoop学习2(数据导入与导出)
最近学习了下这个导数据的工具,但是在export命令这里卡住了,暂时排不了错误。先记录学习的这一点吧
sqoop是什么
sqoop(sql-on-hadoop):是用来实现结构型数据(如关系型数据库)和hadoop之间进行数据迁移的工具。它充分利用了mapreduce的并行特点以及批处理的方式加快数据的传输,同时也借助mapreduce实现了容错。
sqoop架构
1)sqoop目前有两个版本sqoop1(1.4.x)和sqoop2(1.99.x),这里安装的是sqoop1版本
2)sqoop1是由client端直接接入hadoop,任务通过解析生成对应的mapreduce执行
3)sqoop1架构图

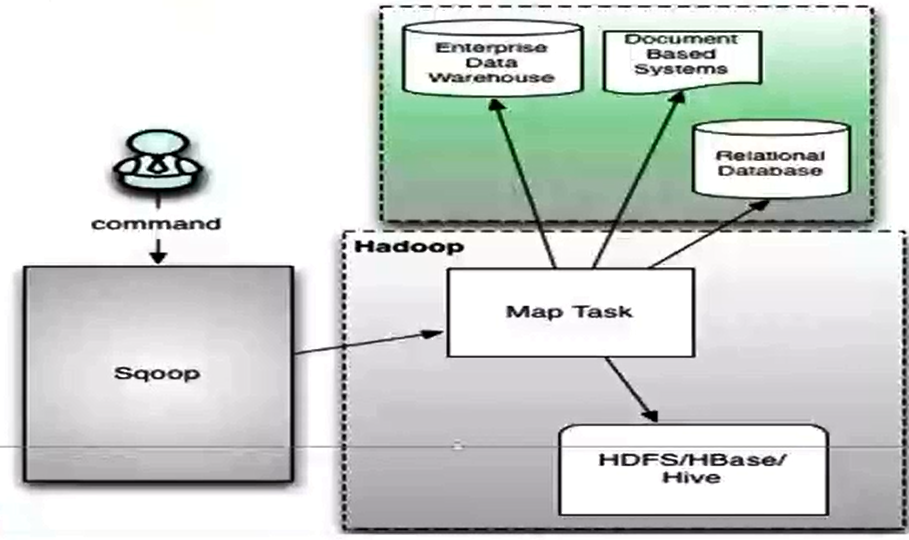
4)导入(import)与导出(export)
导入:往hdfs上导数据
导出:从hdfs上导出去
导入流程:
1)读取要导入数据的表结构
2)读取参数,设置好job
3)调用mapreduce执行任务
----a 首先要对数据进行切分
----b 写入范围,以便读取
----c 读取范围参数(第二步中设置的参数)
----d 创建RecordReader并从数据库中读取数据
----e 创建map
----f 执行map
导出流程:导入过程的逆向过程
sqoop常用命令
命令初步认识
[root@spark1 ~]# sqoop import --connect jdbc:mysql://spark1:3306/wujiadong --username root --table stud_info --target-dir 'hdfs://spark1:9000/user/sqoop_test'
注释:
sqoop:表示sqoop命令
import:表示导入
--connect jdbc:mysql://spark1:3306 :表示告诉jdbc,连接mysql的url。这个是在hive的hive-site.xml中设置的
wujiadong:表示mysql数据库中的一个数据库
--username root: 连接mysql的用户名
--password xxx: 连接mysql的密码,我这里省略了
--table stud_info: 从mysql要导出数据的表名称
--fields-terminated-by '\t': 指定输出文件中的行的字段分隔符,我这没有写
-m 1 表示复制过程使用1个map作业,如果不写的话默认是4个map
注:因我安装mysql时没有设置密码,所以没有加密码项
我导数据时候有时遇到导入不成功,报10020端口连接不上,试试在namenode上执行命令:
mr-jobhistory-daemon.sh start historyserver 之后再去导数据
1)version:显示sqoop版本
查看安装的sqoop版本
[root@spark1 ~]# sqoop version
2)help:查看sqoop帮助信息
[root@spark1 ~]# sqoop help
3)list-databases:打印出关系数据库所有的数据库名
显示出mysql数据库下所有数据库名
[root@spark1 sqoop]# sqoop list-databases --connect jdbc:mysql://spark1:3306 --username root

数据库连接参数
–connect <jdbc-uri> :Jdbc连接url,示例如--connect jdbc:mysql://spark1:3306
–connection-manager :指定要使用的连接管理类
–driver :指定jdbc要使用的驱动类
-P :从控制台读取输入的密码,注意P是大写的
–password :Jdbc url中的数据库连接密码
–username :Jdbc url中的数据库连接用户名
–verbose :在控制台打印出详细运行信息
–connection-param-file :一个记录着数据库连接参数的文件
4)list-tables:打印出关系数据库某一数据库的所有表名
显示mysql数据库中wujiadong这个数据库中所有的表名
[root@spark1 ~]# sqoop list-tables --connect jdbc:mysql://spark1:3306/wujiadong -username root


5)import:将数据库表的数据导入到hive中,如果在hive中没有对应的表,则自动生成与数据库表名相同的表
–append : 数据追加到HDFS上一个已存在的数据集上
–as-avrodatafile : 将数据导入到一个Avro数据文件中
–as-sequencefile : 将数据导入到一个sequence文件中
–as-textfile : 将数据导入到一个普通文本文件中,生成该文本文件后,可以在hive中通过sql语句查询出结果
–boundary-query : 边界查询,也就是在导入前先通过SQL查询得到一个结果集,然后导入的数据就是该结果集内的数据,格式如:–boundary-query ‘select id,creationdate from person where id = 3’,表示导入的数据为id=3的记录.注意查询的字段中不能有数据类型为字符串的字段,否则会报错:java.sql.SQLException: Invalid value for
–columns : 指定要导入的字段值,格式如:–columns id,username
–query,-e<statement> : 从查询结果中导入数据,该参数使用时必须指定–target-dir、–hive-table,在查询语句中一定要有where条件且在where条件中需要包含$CONDITIONS,示例:–query ‘select * from person where $CONDITIONS ‘ –target-dir /user/hive/warehouse/person –hive-table person
–split-by<column-name> :表的列名,用来切分工作单元,一般后面跟主键ID
–table <table-name> :关系数据库表名,数据从该表中获取
–target-dir <dir> :指定hdfs路径
增量导入
–check-column (col):用来作为判断的列名,如id
–incremental (mode):append:追加,比如对大于last-value指定的值之后的记录进行追加导入。lastmodified:最后的修改时间,追加last-value指定的日期之后的记录
–last-value (value):指定自从上次导入后列的最大值(大于该指定的值),也可以自己设定某一值
数据从mysql导入到hdfs
实例1:将mysql中wujiadong数据库中的表stud_info表中的数据导入到hdfs(--target-dir)
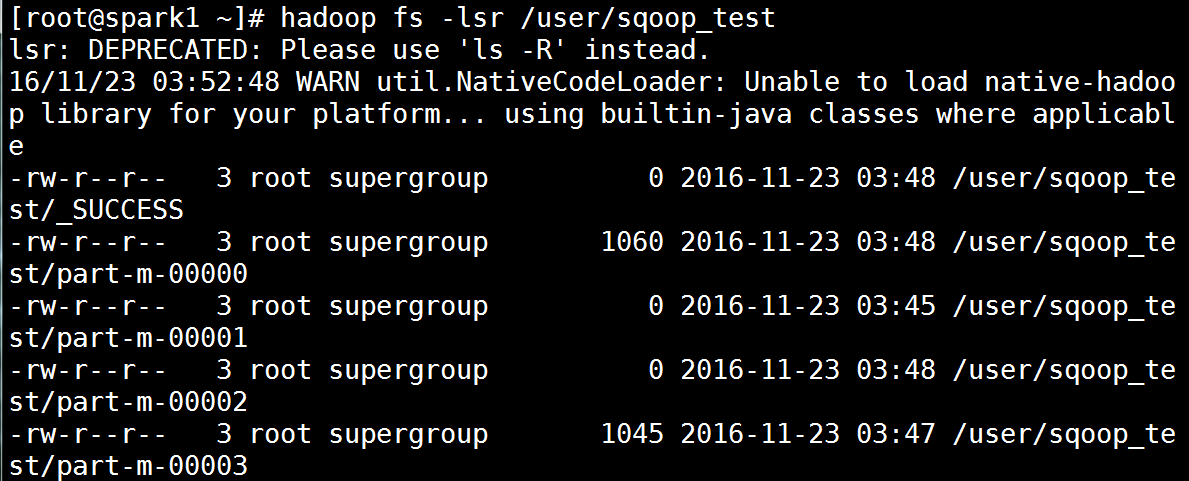
[root@spark1 ~]# sqoop import --connect jdbc:mysql://spark1:3306/wujiadong --username root --table stud_info --target-dir 'hdfs://spark1:9000/user/sqoop_test' 如果这个目录存在会报错。
[root@spark1 ~]# hadoop fs -lsr /user/sqoop_test 导入成功后查看
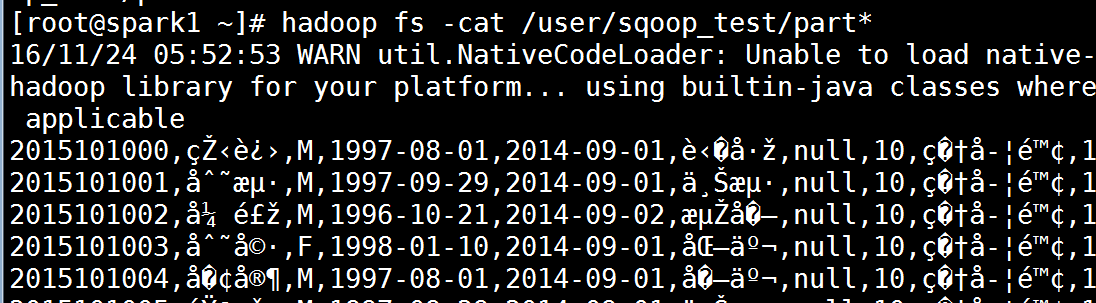
[root@spark1 ~]# hadoop fs -cat /user/sqoop_test/part* 可以直接查看导入的数据。这里出现了中文乱码暂时不管,后面解决
如果执行之后不成功可以试试在命令后加上-m 1 只启动一个map


实例2:在1的基础上继续往这个文件中导入数据(append)
[root@spark1 ~]# sqoop import --connect jdbc:mysql://spark1:3306/wujiadong --username root --table stud_info --append --target-dir 'hdfs://spark1:9000/user/sqoop_test' 可以看到比原来的多了解一个文件

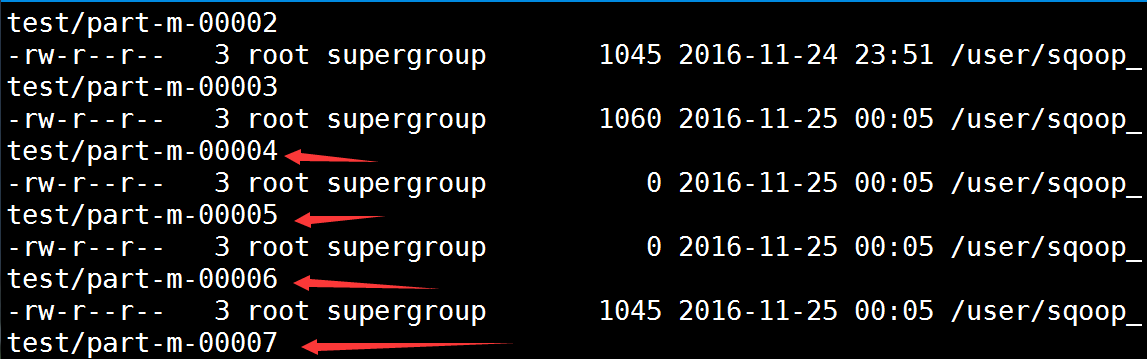
实例3:在1基础上删除已存在文件并导入数据(--delete-target-dir)
[root@spark1 ~]# sqoop import --connect jdbc:mysql://spark1:3306/wujiadong --username root --table stud_info --target-dir 'hdfs://spark1:9000/user/sqoop_test' --delete-target-dir
实例4:增量导入数据到hdfs
实例5:指定条件导入(注意不能含中文)
[root@spark1 ~]# sqoop import --connect jdbc:mysql://spark1:3306/wujiadong --username root --table stud_info --target-dir 'hdfs://spark1:9000/user/sqoop_test' -m 1 --where "stud_gend='M'" --append
模糊查询
[root@spark1 ~]# sqoop import --connect jdbc:mysql://spark1:3306/wujiadong --username root --table stud_info --target-dir 'hdfs://spark1:9000/user/sqoop_test' -m 1 --where "stud_code like '%201510%'" --append


实例6:启用压缩
[root@spark1 ~]# sqoop import --connect jdbc:mysql://spark1:3306/wujiadong --username root --table stud_info --target-dir 'hdfs://spark1:9000/user/sqoop_test' -m 1 --where "stud_gend='M'" --append -z
默认Gzip压缩;其它压缩方式用--compression-codec xxx
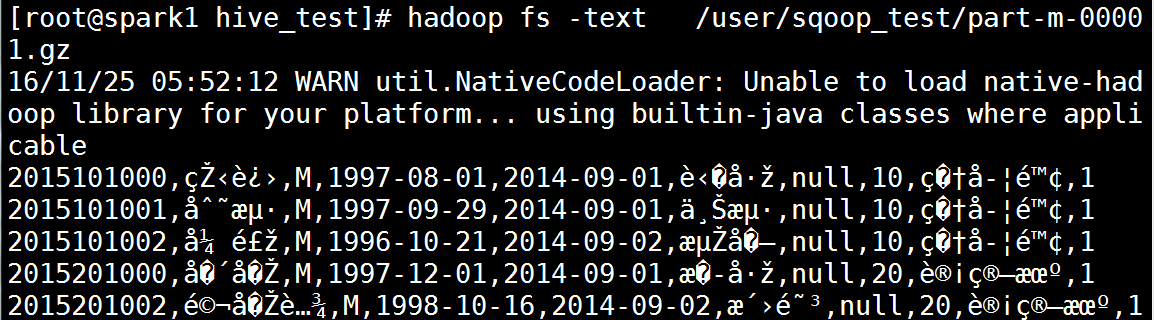
使用text命令查看压缩文件
[root@spark1 ~]# hadoop fs -text /user/sqoop_test/part-m-00001.gz



实例7:导入空值(NULL)处理
字符串类型
[root@spark1 ~]# sqoop import --connect jdbc:mysql://spark1:3306/wujiadong --username root --table stud_info --target-dir 'hdfs://spark1:9000/user/sqoop_test' -m 1 --where "stud_gend='M'" --append --null-string "**"
非字符串类型
[root@spark1 hive_test]# sqoop import --connect jdbc:mysql://spark1:3306/wujiadong --username root --table stud_info --target-dir 'hdfs://spark1:9000/user/sqoop_test' -m 1 --where "stud_gend='M'" --append --null-string "**" --null-non-string "##"
实例8:sql导入
数据从mysql导入到hive
--hive-home <dir>:直接指定hive安装目录
--hive-import:使用默认分隔符导入hive
--hive-overwrite:覆盖掉在hive表中已经存在的数据
--create-hive-table:生成与关系数据库表的表结构对应的HIVE表。如果表不存在,则创建,如果存在,报错
--hive-table <table-name>:导入到hive指定的表,可以创建新表
--hive-drop-import-delims:入数据到hive时,删除字符串字段中的 \n, \r, and \01
--hive-delims-replacement:用自定义的字符串替换掉数据中的\n, \r, and \01等字符
--hive-partition-key:创建分区,后面直接跟分区名即可,创建完毕后,通过describe 表名可以看到分区名,默认为string型
--hive-partition-value <v>:该值是在导入数据到hive中时,与–hive-partition-key设定的key对应的value值
--map-column-hive <map>:生成hive表时,可以更改生成字段的数据类型,格式如:–map-column-hive LAST_ACCESS_TIME=string
--fields-terminated-by:指定分隔符(hive默认的分隔符是/u0001)
实例1 :将mysql数据库wujiadong1中的stud_info表中数据导入到hive总的stud_info1表中(该表未先创建)
[root@spark1 ~]# sqoop import --connect jdbc:mysql://192.168.220.144:3306/wujiadong1 --username root -table stud_info --hive-import -m 1 --hive-table stud_info1
没有指定导入到哪个数据库,默认导入到default数据库中
实例2:将mysql数据库wujiadong1中的stud_info表中数据导入到hive的sqoop_test数据库的stud_info表中(该表未先创建)
在hive中创建数据库sqoop_test
hive> create database sqoop_test;
使用sqoop创建表并导入表
[root@spark1 ~]# sqoop import --connect jdbc:mysql://192.168.220.144:3306/wujiadong1 --username root --table stud_info --hive-import -m 1 --hive-table sqoop_test.stud_info #指定导入到那个数据库中
进入hive查看是否导入成功
hive> use sqoop_test;
hive> show tables;
hive> desc stud_info;
hive> select * from stud_info;


实例3:在2的基础上用--hive-overwrite覆盖导入
[root@spark1 ~]# sqoop import --connect jdbc:mysql://192.168.220.144:3306/wujiadong1 --username root --table stud_info --hive-import -m 1 --hive-table sqoop_test.stud_info --hive-overwrite
只覆盖数据,不覆盖表结构
实例4:使用非默认分隔符“,”分隔hive表字段
[root@spark1 ~]# sqoop import --connect jdbc:mysql://192.168.220.144:3306/wujiadong1 --username root --table stud_info --hive-import -m 1 --hive-table sqoop_test.stud_info1 --fields-terminated-by ","
hive> show create table stud_info1; 查看详细信息


实例5:增量导入
数据从mysql导入到hbase(学完hbase再学)
文件输出参数
–enclosed-by <char> : 给字段值前后加上指定的字符,比如双引号,示例:–enclosed-by ‘\”‘,显示例子:”3″,”jimsss”
–fields-terminated-by <char> : 设定每个字段是以什么符号作为结束的,默认是逗号,也可以改为其它符号
–lines-terminated-by <char> : 设定每条记录行之间的分隔符,默认是换行,但也可以设定自己所需要的字符串
–delete-target-dir : 每次运行导入命令前,若有就先删除target-dir指定的目录
6)export:从hdfs中导出数据到关系数据库中
--validate <class-name>:启用数据副本验证功能,仅支持单表拷贝,可以指定验证使用的实现类
--validation-threshold <class-name>:指定验证门限所使用的类
--direct:使用直接导出模式(优化速度)
--export-dir <dir>:导出过程中HDFS源路径
--m,--num-mappers <n>:使用n个map任务并行导出
--table <table-name>:导出的目的表名称
--update-key <col-name>:更新参考的列名称,多个列名使用逗号分隔
--input-null-string <null-string>:使用指定字符串,替换字符串类型值为null的列
--input-null-non-string <null-string>:使用指定字符串,替换非字符串类型值为null的列
--staging-table <staging-table-name>:在数据导出到数据库之前,数据临时存放的表名称
参考资料1:
sqoop中文手册
参考资料2:
Sqoop导入关系数据库到Hive
参考资料3:
sqoop安装文档
参考资料4:
Sqoop之导入导出操作
sqoop学习2(数据导入与导出)的更多相关文章
- 利用sqoop将hive数据导入导出数据到mysql
一.导入导出数据库常用命令语句 1)列出mysql数据库中的所有数据库命令 # sqoop list-databases --connect jdbc:mysql://localhost:3306 ...
- sqoop将oracle数据导入hdfs集群
使用sqoop将oracle数据导入hdfs集群 集群环境: hadoop1.0.0 hbase0.92.1 zookeeper3.4.3 hive0.8.1 sqoop-1.4.1-incubati ...
- 使用 sqoop 将mysql数据导入到hdfs(import)
Sqoop 将mysql 数据导入到hdfs(import) 1.创建mysql表 CREATE TABLE `sqoop_test` ( `id` ) DEFAULT NULL, `name` va ...
- 数据分析(7):pandas介绍和数据导入和导出
前言 Numpy Numpy是科学计算的基础包,对数组级的运算支持较好 pandas pandas提供了使我们能够快速便捷地处理结构化数据的大量数据结构和函数.pandas兼具Numpy高性能的数组计 ...
- Sqoop将mysql数据导入hbase的血与泪
Sqoop将mysql数据导入hbase的血与泪(整整搞了大半天) 版权声明:本文为yunshuxueyuan原创文章.如需转载请标明出处: https://my.oschina.net/yunsh ...
- 使用sqoop把mysql数据导入hive
使用sqoop把mysql数据导入hive export HADOOP_COMMON_HOME=/hadoop export HADOOP_MAPRED_HOME=/hadoop cp /hive ...
- 使用 sqoop 将mysql数据导入到hive表(import)
Sqoop将mysql数据导入到hive表中 先在mysql创建表 CREATE TABLE `sqoop_test` ( `id` ) DEFAULT NULL, `name` varchar() ...
- 如何利用sqoop将hive数据导入导出数据到mysql
运行环境 centos 5.6 hadoop hive sqoop是让hadoop技术支持的clouder公司开发的一个在关系数据库和hdfs,hive之间数据导入导出的一个工具. 上海尚学堂 ...
- Hadoop Hive概念学习系列之HDFS、Hive、MySQL、Sqoop之间的数据导入导出(强烈建议去看)
Hive总结(七)Hive四种数据导入方式 (强烈建议去看) Hive几种数据导出方式 https://www.iteblog.com/archives/955 (强烈建议去看) 把MySQL里的数据 ...
随机推荐
- poj1837
Balance Time Limit: 1000MS Memory Limit: 30000K Total Submissions: 12995 Accepted: 8142 Descript ...
- Error: member names cannot be the same as their enclosing type
在编译的时候会遇到如下问题:member names cannot be the same as their enclosing type 原因:方法名和类名不能一样,如果一样就是一个构造函数.而构造 ...
- Java中Jedis操作Redis与Spring的整合
Redis是一个key-value存储系统.它支持存储的value类型相对更多,包括string(字符串).list(链表).set(集合)和zset(有序集合).这些数据类型都支持push/pop. ...
- 《UNIX网络编程》 -- 第五章
str_cli 和 str_echo 函数 需要先弄清楚 3.9 readn.writen 和 readline 函数 str_cli void str_cli(FILE *fp, int sockf ...
- <2013 12 01> 一篇很好的关于windows编程的入门指导(2013年末写的,比较前沿)
我之前做了不少嵌入式开发,从单片机到ARM到RTOS到Linux等等,可以说走的是电气工程师的路线,对编程也是实用性的,跟计算机学院的科班套路不同.最近同学做一个windowsCE的项目请我帮忙,之前 ...
- 类 String、StringBuffer、StringBuilder
类 String String 类代表字符串.Java 程序中的所有字符串字面值(如 "abc" )都作为此类的实例实现.字符串是常量:它们的值在创建之后不能更改.字符串缓冲区支持 ...
- 编译java-cef
javacef即java Chromium Embedded Framework,其功能是通过在java应用中嵌入谷歌浏览器内核Chromium. 编译java-cef的过程可参考以下文档及视频: h ...
- rpm命令相关命令运用实例
1) 挂载光盘文件到/media目录 2) 进去/media目录下的Packages目录 3) 查看系统已安装的所有rpm包 4) 查看系统是否安装dhcp软件包 5,安装dhcp软件包 6) 查看d ...
- MySQL 5.6 死锁演示 及 日志分析
1. 表结构 CREATE TABLE dead_update ( a ) ', PRIMARY KEY (a) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 ; ), ...
- sql server2005版本中,len函数计算了字符串末尾的空格
sql server2005版本中,len函数计算了字符串末尾的空格的长度,以下是测试脚本: print @@version declare @v varchar(max) set @v = 'hp, ...