Solr6.6 配置中文分词库mmseg4j
1、准备
首先安装solr:参照搜索引擎Solr-6.6.0搭建,如果版本高于6,可能会不支持,需要改mmseg4j包
mmseg4j包下载: mmseg4j-solr-2.3.0-with-mmseg4j-core.zip 或https://pan.baidu.com/s/1dD7qMFf#list/path=%2F
开源地址:https://github.com/chenlb/mmseg4j-solr
解压下载的压缩包mmseg4j-solr-2.3.0-with-mmseg4j-core.zip,得到mmseg4j-core-1.10.0.jar和mmseg4j-solr-2.3.0.jar把这两个文件拷贝到tomcat的webapps\solr\WEB-INF\lib路径下

2、建立core
建立mycore,具体参见搜索引擎Solr-6.6.0搭建的“四、Solr6.6.0环境搭建”部分。
3、修改配置文件
修改mycore/conf的配置文件managed-schema,增加以下内容:
<!-- mmseg4j fieldType-->
<fieldType name="text_mmseg4j_complex" class="solr.TextField" positionIncrementGap="100" >
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="complex" />
</analyzer>
</fieldType>
<fieldType name="text_mmseg4j_maxword" class="solr.TextField" positionIncrementGap="100" >
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="max-word" />
</analyzer>
</fieldType>
<fieldType name="text_mmseg4j_simple" class="solr.TextField" positionIncrementGap="100" >
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="simple" />
</analyzer>
</fieldType>
启动重新启动tomcat,在浏览器中输入http://localhost:8080/solr/index.html,
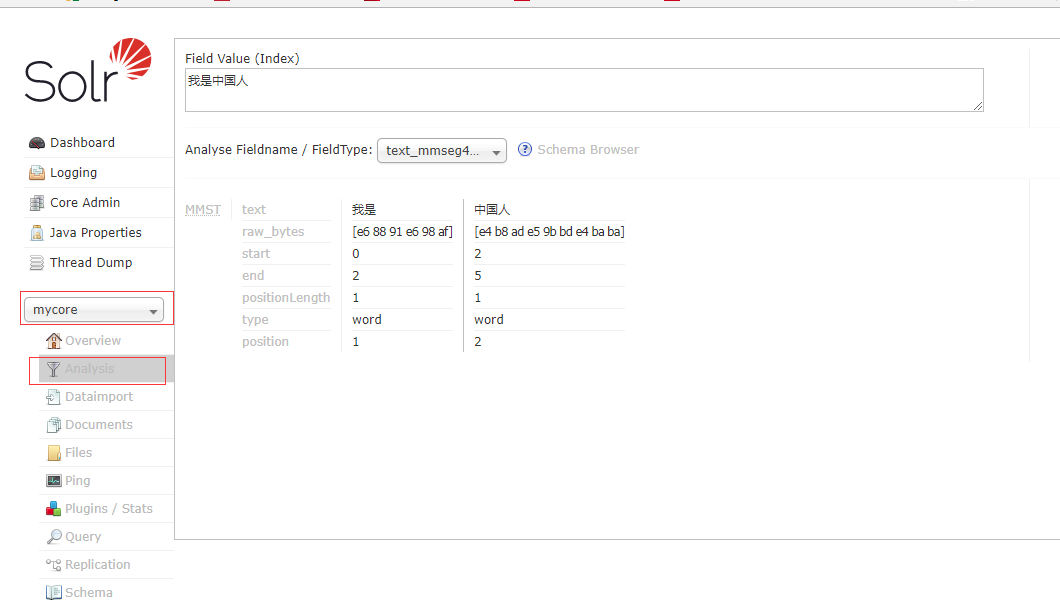
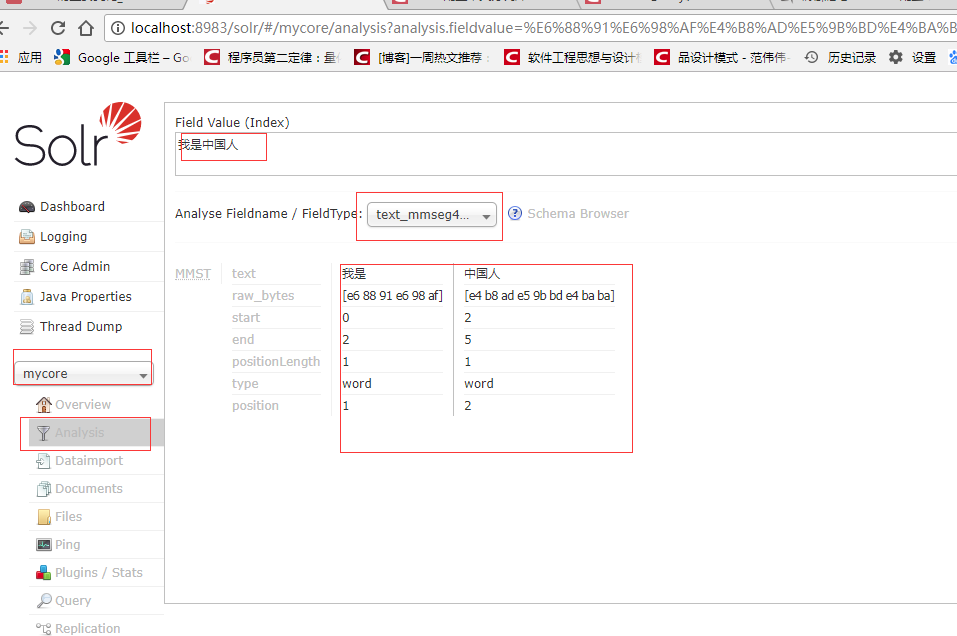
在管理界面选择分析,输入“我是中国人” 类型选择上面的三种的一种进行分析如下:
4、直接启动solr自带的Jetty,不用tomcat
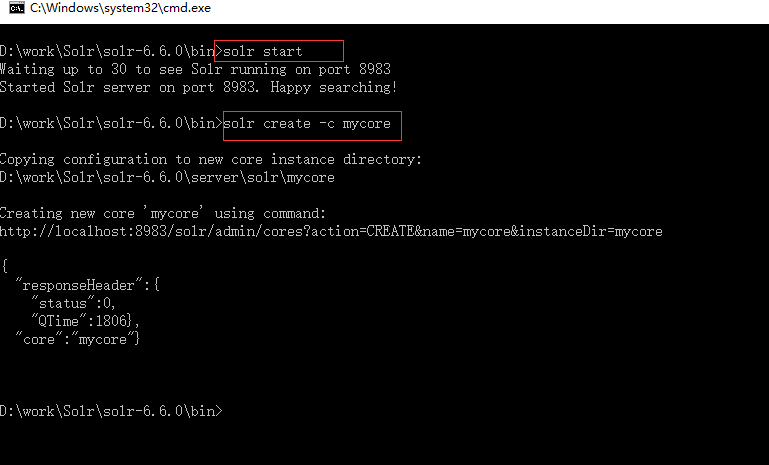
进入solr6.6的bin目录,启动solr,通过命令建立core
solr create -c mycore
这样在solr-6.6.0\server\solr目录下生成mycore

修改mycore\conf文件夹下的配置文件managed-schema,在最后新增一项内容
<!-- mmseg4j fieldType-->
<fieldType name="text_mmseg4j_complex" class="solr.TextField" positionIncrementGap="100" >
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="complex" />
</analyzer>
</fieldType>
<fieldType name="text_mmseg4j_maxword" class="solr.TextField" positionIncrementGap="100" >
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="max-word" />
</analyzer>
</fieldType>
<fieldType name="text_mmseg4j_simple" class="solr.TextField" positionIncrementGap="100" >
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="simple" />
</analyzer>
</fieldType>
把mmseg4j-core-1.10.0.jar和mmseg4j-solr-2.3.0.jar拷贝到solr-6.6.0\server\solr-webapp\webapp\WEB-INF\lib文件夹下
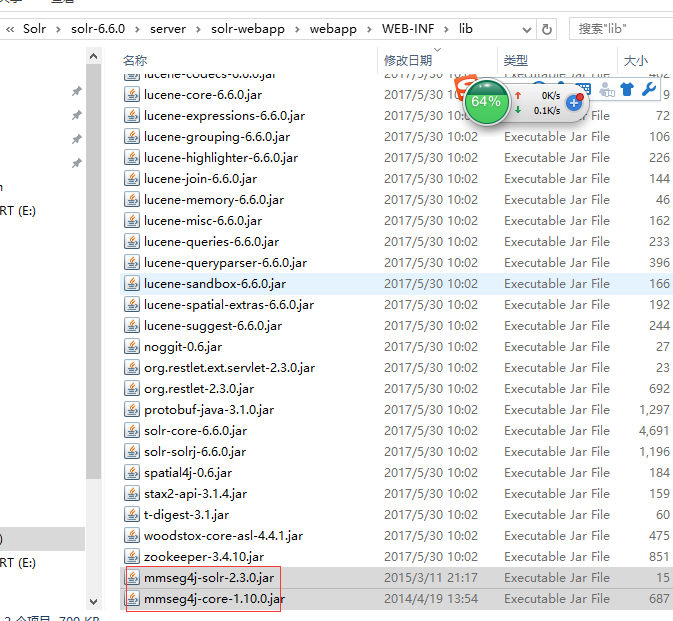
执行命令solr stop -all
重新启动solr
重新打开浏览器输入:http://localhost:8983/solr/#/
或者直接修改solr-6.6.0\server\solr\configsets\data_driven_schema_configs\conf文件夹下的配置文件managed-schema,在最后新增以下内容:
<!-- mmseg4j fieldType-->
<fieldType name="text_mmseg4j_complex" class="solr.TextField" positionIncrementGap="100" >
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="complex" />
</analyzer>
</fieldType>
<fieldType name="text_mmseg4j_maxword" class="solr.TextField" positionIncrementGap="100" >
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="max-word" />
</analyzer>
</fieldType>
<fieldType name="text_mmseg4j_simple" class="solr.TextField" positionIncrementGap="100" >
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="simple" />
</analyzer>
</fieldType>
这样在新建core的时候就不用每次都修改单个core的managed-schema配置文件了
参照资料:http://blog.csdn.net/jiangchao858/article/details/53026374
Solr6.6 配置中文分词库mmseg4j的更多相关文章
- 转:solr6.0配置中文分词器IK Analyzer
solr6.0中进行中文分词器IK Analyzer的配置和solr低版本中最大不同点在于IK Analyzer中jar包的引用.一般的IK分词jar包都是不能用的,因为IK分词中传统的jar不支持s ...
- 我与solr(六)--solr6.0配置中文分词器IK Analyzer
转自:http://blog.csdn.net/linzhiqiang0316/article/details/51554217,表示感谢. 由于前面没有设置分词器,以至于查询的结果出入比较大,并且无 ...
- Solr6.5配置中文分词IKAnalyzer和拼音分词pinyinAnalyzer (二)
之前在 Solr6.5在Centos6上的安装与配置 (一) 一文中介绍了solr6.5的安装.这篇文章主要介绍创建Solr的Core并配置中文IKAnalyzer分词和拼音检索. 一.创建Core: ...
- Solr6.5配置中文分词器
Solr作为搜索应用服务器,我们在使用过程中,不可避免的要使用中文搜索.以下介绍solr自带的中文分词器和第三方分词器IKAnalyzer. 注:下面操作在Linux下执行,所添加的配置在windo ...
- Hanlp等七种优秀的开源中文分词库推荐
Hanlp等七种优秀的开源中文分词库推荐 中文分词是中文文本处理的基础步骤,也是中文人机自然语言交互的基础模块.由于中文句子中没有词的界限,因此在进行中文自然语言处理时,通常需要先进行分词. 纵观整个 ...
- Slackware Linux or FreeBSD 配置中文环境。
配置中文环境. Slackware Linux 如果在控制面板的语言与地区选项中没有找到中文,那说明在安装系统选择软件的时候没有将国际语言支持包选上,可以从slackware的安装盘或ISO文件中提取 ...
- centos7 学习1 KDE配置中文
安装kde桌面后没有中文,可以用以下方法配置中文 #yum list kde*chinese 会显示可以安装的包,我的显示如下 kde-l10n-Chinese.noarch -.fc14 @upda ...
- 沈逸老师ubuntu速学笔记(1)--安装flashplayer,配置中文输入法以及常用命令
开篇首先感谢程序员在囧途(www.jtthink.com)以及沈逸老师,此主题笔记主要来源于沈老师课程.同时也感谢少年郎,秦少.花旦等同学分享大家的学习笔记. 1.安装flash player ctr ...
- 5.Solr4.10.3中配置中文分词器
转载请出自出处:http://www.cnblogs.com/hd3013779515/ 1.下载IK Analyzer 2012FF_hf1.zip并上传到/home/test 2.按照如下命令安装 ...
随机推荐
- v4l2 Camera详细设置【转】
转自:http://blog.csdn.net/smilefyx/article/details/39555289 转载自:http://blog.sina.com.cn/s/blog_602f877 ...
- 大话Linux内核中锁机制之原子操作、自旋锁【转】
转自:http://blog.sina.com.cn/s/blog_6d7fa49b01014q7p.html 多人会问这样的问题,Linux内核中提供了各式各样的同步锁机制到底有何作用?追根到底其实 ...
- Linux上Core Dump文件的形成和分析
原文: http://baidutech.blog.51cto.com/4114344/904419 Core,又称之为Core Dump文件,是Unix/Linux操作系统的一种机制,对于线上服务而 ...
- pressmuSpiderr
#!/usr/bin/env python # encoding: utf-8 import requests from random import choice from lxml import h ...
- 如何修改linux 的SSH的默认端口号?
http://blog.chinaunix.net/uid-7551698-id-1989086.html 在安装完毕linux,默认的情况下ssh是开放的,容易受到黑客攻击,简单,有效的操作之一 ...
- Flex slider使用方法
1.首先在页面head部位载入jquery库文件和Flexslider插件,以及Flexslider所需的基本css样式文件. <link rel="stylesheet" ...
- bootstrapValidator关于verbose需要优化的地方
开发中需要用到bootstrapValidator的配置verbose:false,达到当前验证不通过不往下在验证的效果 问题: 当前字段需要remote验证时,此配置无效,原因在于remote是异步 ...
- Selenium2+python自动化65-js定位几种方法总结【转载】
前言 本篇总结了几种js常用的定位元素方法,并用js点击按钮,对input输入框输入文本 一.以下总结了5种js定位的方法 除了id是定位到的是单个element元素对象,其它的都是elements返 ...
- python算法:LinkedList(双向线性链表)的实现
LinkedList是一个双向线性链表,但是并不会按线性的顺序存储数据,而是在每一个节点里存到下一个节点的指针(Pointer).由于不必须按顺序存储,链表在插入的时候可以达到O(1)的复杂度,比另一 ...
- [BZOJ1475]方格取数 网络流 最小割
1475: 方格取数 Time Limit: 5 Sec Memory Limit: 64 MBSubmit: 1025 Solved: 512[Submit][Status][Discuss] ...