流量分析系统---kafka集群部署
1、集群部署的基本流程
Storm上游数据源之Kakfa
下载安装包、解压安装包、修改配置文件、分发安装包、启动集群
2、基础环境准备
安装前的准备工作(zk集群已经部署完毕)
关闭防火墙
chkconfig iptables off && setenforce 0
创建工作目录并赋权
mkdir -p /export/servers
chmod 755 -R /export
3、集群部署
3.1下载安装包
wget http://mirrors.hust.edu.cn/apache/kafka/0.8.2.2/kafka_2.11-0.8.2.2.tgz
3.2解压安装包
tar -zxvf /export/software/kafka_2.11-0.8.2.2.tgz -C /export/servers/
cd /export/servers/
ln -s kafka_2.11-0.8.2.2 kafka
3.3修改配置文件
cp /export/servers/kafka/config/server.properties
/export/servers/kafka/config/server.properties.bak
vi /export/servers/kafka/config/server.properties
输入以下内容:
(提前创建好mkdir -p /export/servers/logs/kafka)
#broker的全局唯一编号,不能重复
broker.id=1 #每台机器递增 #用来监听链接的端口,producer或consumer将在此端口建立连接
port=9092 #处理网络请求的线程数量
num.network.threads=3 #用来处理磁盘IO的线程数量
num.io.threads=8 #发送套接字的缓冲区大小
socket.send.buffer.bytes=102400 #接受套接字的缓冲区大小
socket.receive.buffer.bytes=102400 #请求套接字的缓冲区大小
socket.request.max.bytes=104857600 #kafka运行日志存放的路径,需要提前创建好
log.dirs=/export/servers/logs/kafka #topic在当前broker上的分片个数
num.partitions=2 #用来恢复和清理data下数据的线程数量
num.recovery.threads.per.data.dir=1 #segment文件保留的最长时间,超时将被删除
log.retention.hours=168 #滚动生成新的segment文件的最大时间
log.roll.hours=168 #日志文件中每个segment的大小,默认为1G
log.segment.bytes=1073741824 #周期性检查文件大小的时间
log.retention.check.interval.ms=300000 #日志清理是否打开
log.cleaner.enable=true #broker需要使用zookeeper保存meta数据
zookeeper.connect=192.168.32.201:2181,192.168.32.202:2181,192.168.32.203:2181 #zookeeper链接超时时间
zookeeper.connection.timeout.ms=6000 #partion buffer中,消息的条数达到阈值,将触发flush到磁盘
log.flush.interval.messages=10000 #消息buffer的时间,达到阈值,将触发flush到磁盘
log.flush.interval.ms=3000 #删除topic需要server.properties中设置delete.topic.enable=true否则只是标记删除
delete.topic.enable=true #此处的host.name为本机IP(重要),如果不改,则客户端会抛出:Producer connection to localhost:9092
host.name=kafka01
advertised.host.name=192.168.32.201 #每台机子都要做相应修改
3.4分发安装包
scp -r /export/servers/kafka_2.11-0.8.2.2 kafka02:/export/servers
然后分别在各机器上创建软连
cd /export/servers/
ln -s kafka_2.11-0.8.2.2 kafka
3.5依次修改配置文件
依次修改各服务器上配置文件的的broker.id,分别是1,2,3不得重复。
host.name 改成自己的
advertised.host.name 改成自己的
配置环境变量
export KAFKA_HOME=/export/servers/kafka
export PATH=$PATH:$KAFKA_HOME/bin
3.6刷新环境变量
source /etc/profile
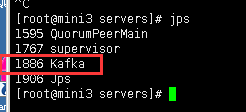
4、启动集群
启动集群各个节点启动zookeeper
各个节点启动集群
#启动
nohup kafka-server-start.sh /export/servers/kafka/config/server.properties &
#停止
kafka-server-stop.sh
流量分析系统---kafka集群部署的更多相关文章
- 流量分析系统--zookeeper集群部署
安装zookeeper mkdir apps tar -zxvf zookeeper-3.4.5.tar.gz -C apps [root@mini1 zookeeper-3.4.5]# rm -rf ...
- 分布式消息系统之Kafka集群部署
一.kafka简介 kafka是基于发布/订阅模式的一个分布式消息队列系统,用java语言研发,是ASF旗下的一个开源项目:类似的消息队列服务还有rabbitmq.activemq.zeromq:ka ...
- zookeeper集群+kafka集群 部署
zookeeper集群 +kafka 集群部署 1.Zookeeper 概述: Zookeeper 定义 zookeeper是一个开源的分布式的,为分布式框架提供协调服务的Apache项目 Zooke ...
- kafka 集群部署 多机多broker模式
kafka 集群部署 多机多broker模式 环境IP : 172.16.1.35 zookeeper kafka 172.16.1.36 zookeeper kafka 172.16 ...
- Zookeeper+Kafka集群部署(转)
Zookeeper+Kafka集群部署 主机规划: 10.200.3.85 Kafka+ZooKeeper 10.200.3.86 Kafka+ZooKeeper 10.200.3.87 Kaf ...
- 3、Kafka集群部署
Kafka集群部署 1)解压安装包 [ip101]$ tar -zxvf kafka_2.11-0.11.0.0.tgz -C /opt/app/ 2)修改解压后的文件名称 [ip101]$ mv k ...
- Zookeeper+Kafka集群部署
Zookeeper+Kafka集群部署 主机规划: 10.200.3.85 Kafka+ZooKeeper 10.200.3.86 Kafka+ZooKeeper 10.200.3.87 Kaf ...
- Kafka集群部署 (守护进程启动)
1.Kafka集群部署 1.1集群部署的基本流程 下载安装包.解压安装包.修改配置文件.分发安装包.启动集群 1.2集群部署的基础环境准备 安装前的准备工作(zk集群已经部署完毕) 关闭防火墙 c ...
- Kafka集群部署以及使用
Kafka集群部署 部署步骤 hadoop102 hadoop103 hadoop104 zk zk zk kafka kafka kafka http://kafka.apache.org/down ...
随机推荐
- boost中全局命名锁的使用
使用头文件相对位置为:boost/interprocess/sync/named_mutex.hpp 在程序中使用 boost::interprocess::named_mutex g_namedmu ...
- iOS大文件分片上传和断点续传
总结一下大文件分片上传和断点续传的问题.因为文件过大(比如1G以上),必须要考虑上传过程网络中断的情况.http的网络请求中本身就已经具备了分片上传功能,当传输的文件比较大时,http协议自动会将文件 ...
- Java并发编程(六)发布与逸出
"发布(Publish)"一个对象的意思指,使对象能够在作用域之外的代码中使用. 例如: 将一个指向该对象的引用保存到其他代码可以访问的地方 在一个非私有的方法中返回该引用 将引用 ...
- linux list
一篇介绍链表不错的文章: 1. 玩转C链表 2. openwrt使用list 3. 深入分析 Linux 内核链表 https://www.ibm.com/developerworks/cn/linu ...
- VMware虚拟机 Ubuntu 实用技巧 (2)桥接模式连接网络与网卡的配置
1.先用ifconfig查看当前的网卡配置,一般没有进行设置之前,打印的信息如下所示. ens33 Link encap:以太网 硬件地址 02:0c:29:c6:be:c7 inet6 地址: fe ...
- MySQL同步状态双Yes的假象及 seconds_behind_master的含义
MySQL同步状态双Yes的假象及seconds_behind_master的含义 近期由于特殊原因有一台主库宕机了一个小时没有处理,说起来这是个挺不好啥意思的事情,但是由于这个事情反而发现个比较 ...
- select option 不可以选
<select> <option>Volvo</option> <option>Saab</option> <option disab ...
- win10输入法设置
控制面板中: ok.
- OpenCV学习笔记十五:opencv_features2d模块
一,简介: 该库用于2D特征检测,描述与匹配.
- gitlab报错收集
登录502报错 一般是权限问题,解决方法: /var/log/gitlab 如果还不行,请检查你的内存,安装使用GitLab需要至少4GB可用内存(RAM + Swap)! 由于操作系统和其他正在运行 ...