Hadoop(17)-MapReduce框架原理-MapReduce流程,Shuffle机制,Partition分区
MapReduce工作流程
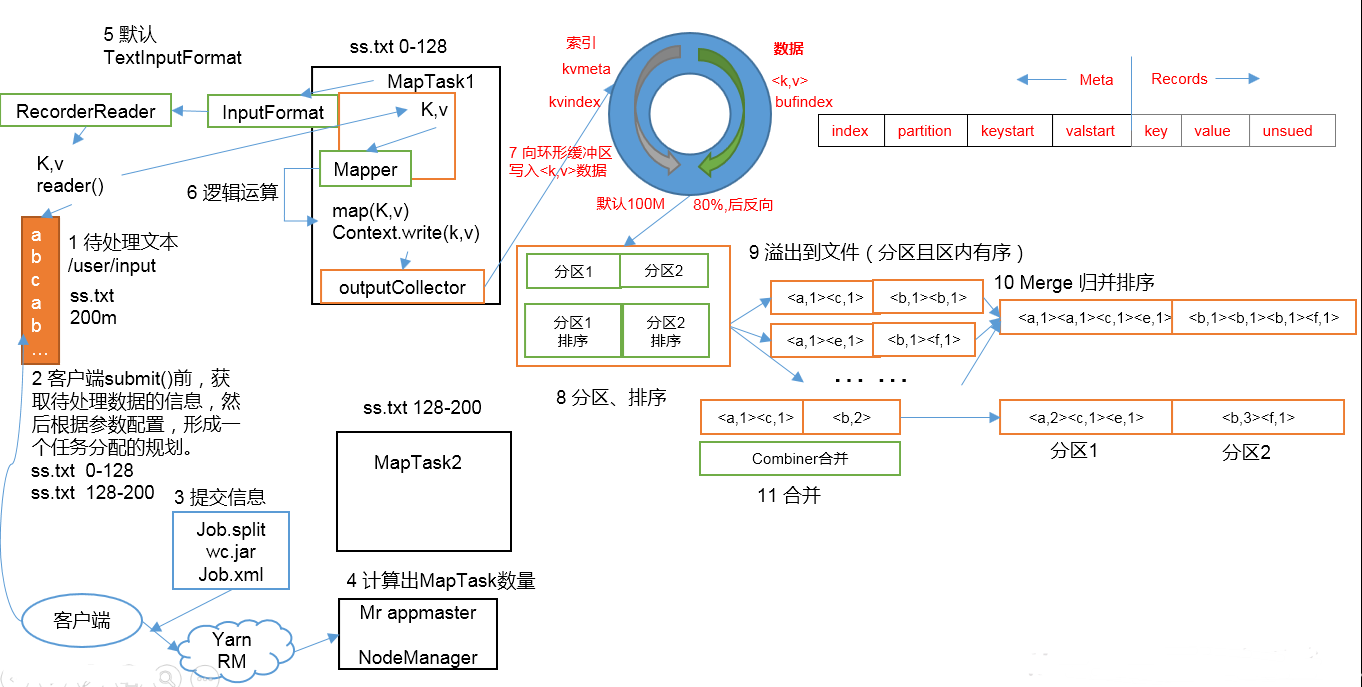
1.准备待处理文件
2.job提交前生成一个处理规划
3.将切片信息job.split,配置信息job.xml和我们自己写的jar包交给yarn
4.yarn根据切片规划计算出MapTask的数量
(以一个MapTask为例)
5.Maptask调用inputFormat生成RecordReader,将自己处理的切片文件内容打散成K,V值
6.MapTask将打散好的K,V值交给Mapper,Mapper经过一系列的处理将KV值写出
7.写出的KV值被outputCollector收集起来,写入一个在内存的环形缓冲区
8,9.当环形缓冲区被写入的空间等于80%时,会触发溢写.此时数据是在内存中,所以在溢写之前,会对数据进行排序,是一个二次排序的快排(先根据分区排序再根据key排序).然后将数据有序的写入到磁盘上.
缓冲区为什么是环形的?这样做是为了可以在缓冲区的任何地方进行数据的写入.

当第一次溢写时,数据会从余下的20%空间中的中间位置,再分左右继续写入,也就是从第一次是从上往下写数据变成了从下往上写数据
10,11.当多次溢写产生多个有序的文件后,会触发归并排序,将多个有序的文件合并成一个有序的大文件.当文件数>=10个时,会触发归并排序,取文件的一小部分放入内存的缓冲区,再生成一个小文件部分大小x文件数的缓冲区,逐个比较放入大文件缓冲区,依次比较下去,再将大文件缓冲写入到磁盘,归并结束后将大文件放在文件列表的末尾,继续重复此动作,直到合并成一个大文件.此次归并排序的时间复杂度要求较低.
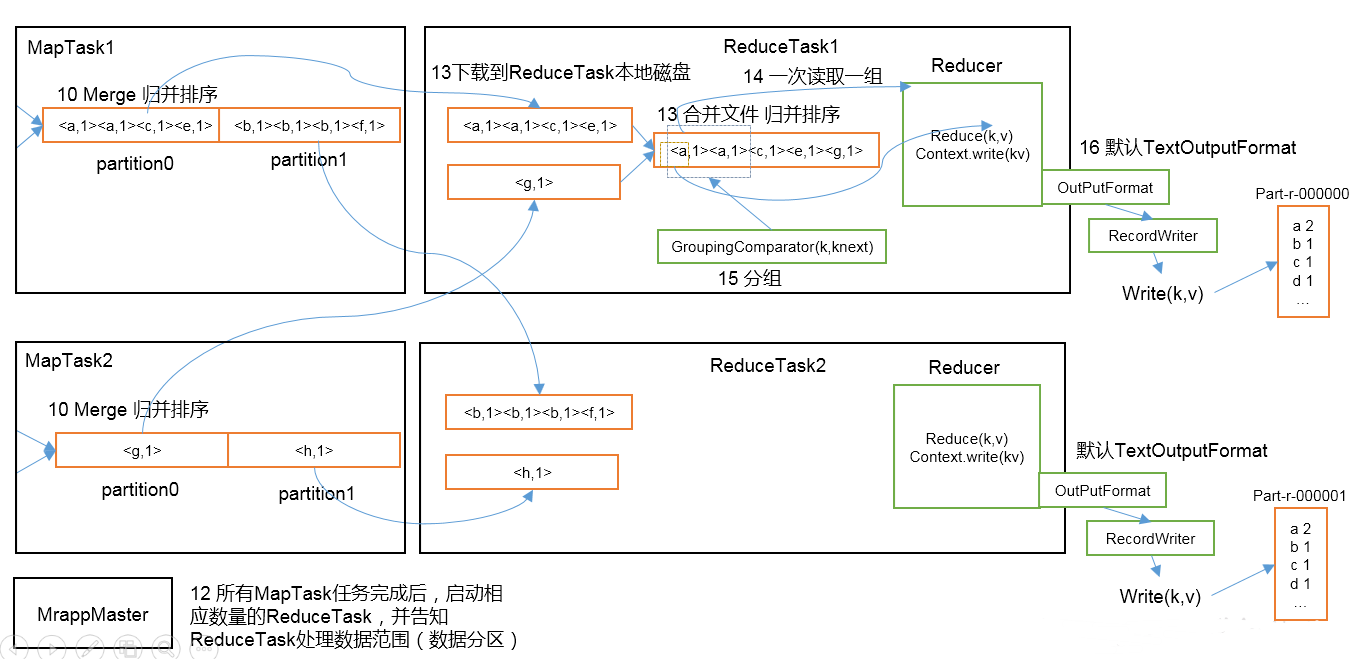
12.当所有的MapTask执行完任务后,启动相应数量的ReduceTask,并告知每一个ReduceTask应该处理的数据分区
13.ReduceTask将指定分区的文件下载到本地,如有多个分区文件的话,ReduceTask上将会有多个大文件,再一次归并排序,形成一个大文件.
14.15,如果有分组要求的话,ReduceTask会将数据一组一组的交给Reduce,处理完后准备将数据写出
16.Reduce调用output生成RecordWrite将数据写入到指定路径中
Shuffle机制
上图中,数据从Mapper写出来之后到数据进入到Reduce之前,这一阶段就叫做Shuffle
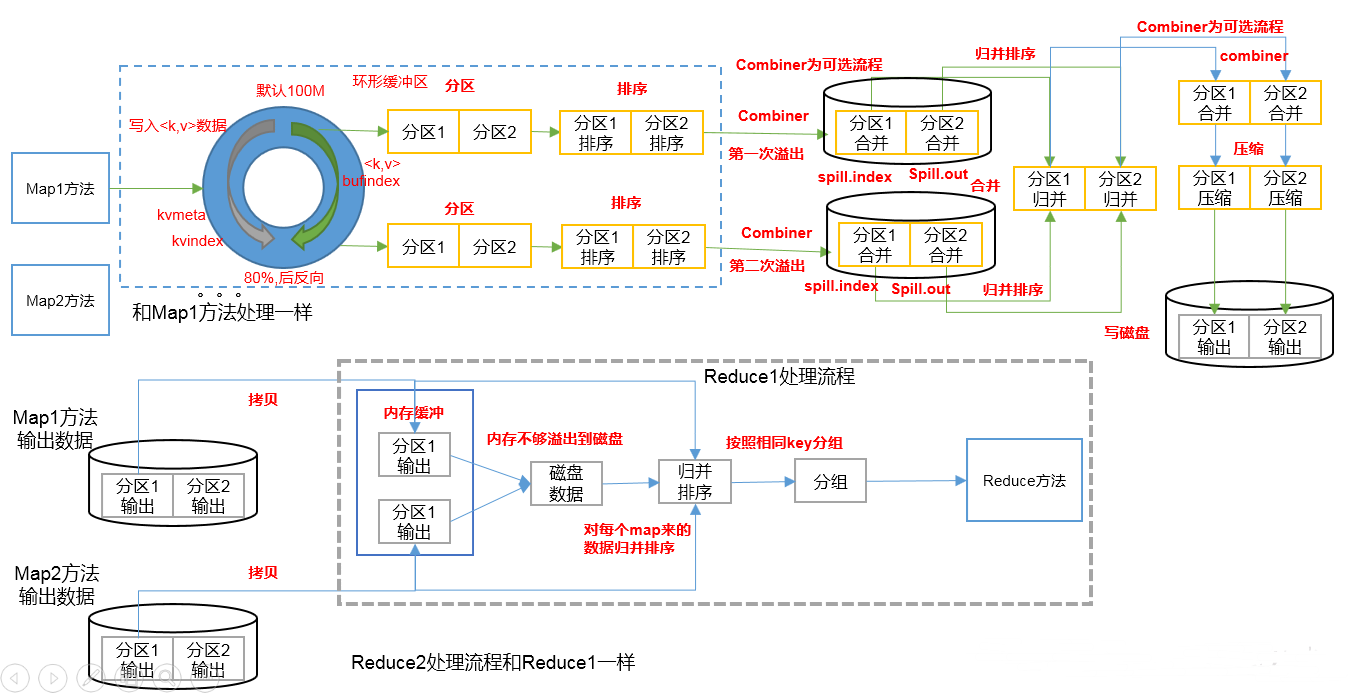
Shuffle时,会有三次排序,第一次是数据从环形缓冲区写入到磁盘时,会有一次快排,第二次是在MapTask中,将多个分区且内部有序的小文件归并成一个分区且内部有序的大文件,第三次是在ReduceTask中,从多个MapTask中获取指定分区的大文件,再进行一个归并排序,合并成一个大文件.
以WordCount为例,试想一下,在第一次从环形缓冲区写入到磁盘时,排好序的数据为(w1,1),(w1,1),(w1,1),(w2,1),(w2,1),(w3,1),这样的数据会增加网络传输量,所以在这里可以使用Combiner进行数据合并.最后形成的数据是(w1,3),(w2,2),(w3,1),后续会详细讲解~
Partition分区
将Mapper想象成一个水池,数据是池里的水.默认分一个区,只有一根水管.如果只有一个ReduceTask,则水会全部顺着唯一的水管流入到ReduceTask中.如果此时有3根水管,则水会被分成三股水流流入到3个ReduceTask中,而且哪些水进哪个水管,并不受我们主观控制,也就是数据处理速度加快了~~Partition分区就决定了分几根水管.试想一下,如果有4根水管,末端只有3个ReduceTask,那么有一股水流会丢失.也就是造成数据丢失,程序会报错.如果只有2根水管,那么则有一个ReduceTask无事可做,最后生成的是一个空文件,浪费资源
所以,一般来说,有几个ReduceTask就要分几个区,至于partition和ReduceTask设置为几,要看集群性能,数据集,业务,经验等等~
对应流程图上,也就是从环形缓冲区写入到磁盘时,会分区



collector出现了,除了将key,value收集到缓冲区中之外,还收集了partition分区


key.hashCode() & Integer.MAX_VALUE,保证取余前的数为正数
比如,numReduceTasks = 3, 一个数n对3取余,结果会有0,1,2三种可能,也就是分三个区,再一次印证了要 reduceTask number = partition number
默认分区是根据key的hashcode和reduceTasks的个数取模得到的,用户无法控制哪个key存储到哪个分区上
案例演练
以12小章的统计流量案例为例,大数据-Hadoop生态(12)-Hadoop序列化和源码追踪
将手机号136、137、138、139开头都分别放到一个独立的4个文件中,其他开头的放到一个文件中
自定义Partition类
package com.atguigu.partitioner; import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner; public class MyPartitioner extends Partitioner<Text, FlowBean> {
public int getPartition(Text text, FlowBean flowBean, int numPartitions) {
//1. 截取手机前三位
String start = text.toString().substring(0, 3); //2. 按照手机号前三位返回分区号
switch (start) {
case "136":
return 0;
case "137":
return 1;
case "138":
return 2;
case "139":
return 3;
default:
return 4;
} }
}
Driver类的main()中增加以下代码
job.setPartitionerClass(MyPartitioner.class); job.setNumReduceTasks(5);
输出结果,5个文件

如果job.setNumReduceTasks(10),会生成10个文件,其中5个是空文件
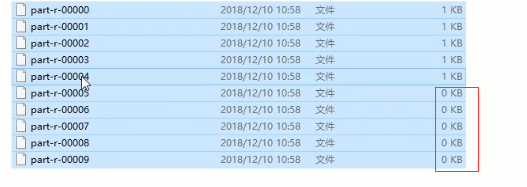
如果job.setNumReduceTasks(2),程序会直接执行失败报异常

如果job.setNumReduceTasks(1),程序会运行成功,因为如果numReduceTasks=1时,根本就不会执行分区的过程
如果是以下情况,也会执行失败.MapReduce会认为你分了41个区,所以分区号必须从0开始,逐一累加.
job.setNumReduceTasks(5)
switch (start) {
case "136":
return 0;
case "137":
return 1;
case "138":
return 2;
case "139":
return 3;
default:
return 40;
}

Hadoop(17)-MapReduce框架原理-MapReduce流程,Shuffle机制,Partition分区的更多相关文章
- MapReduce框架中的Shuffle机制
Shuffle是map和reduce中间的数据调度过程,包括:缓存.分区.排序等. Shuffle数据调度过程: map task处理hdfs文件,调用map()方法,map task的collect ...
- java大数据最全课程学习笔记(6)--MapReduce精通(二)--MapReduce框架原理
目前CSDN,博客园,简书同步发表中,更多精彩欢迎访问我的gitee pages 目录 MapReduce精通(二) MapReduce框架原理 MapReduce工作流程 InputFormat数据 ...
- MapReduce框架原理--Shuffle机制
Shuffle机制 Mapreduce确保每个reducer的输入都是按键排序的.系统执行排序的过程(Map方法之后,Reduce方法之前的数据处理过程)称之为Shuffle. partition分区 ...
- 【hadoop代码笔记】Mapreduce shuffle过程之Map输出过程
一.概要描述 shuffle是MapReduce的一个核心过程,因此没有在前面的MapReduce作业提交的过程中描述,而是单独拿出来比较详细的描述. 根据官方的流程图示如下: 本篇文章中只是想尝试从 ...
- hadoop笔记之MapReduce的运行流程
MapReduce的运行流程 MapReduce的运行流程 基本概念: Job&Task:要完成一个作业(Job),就要分成很多个Task,Task又分为MapTask和ReduceTask ...
- MapReduce实例2(自定义compare、partition)& shuffle机制
MapReduce实例2(自定义compare.partition)& shuffle机制 实例:统计流量 有一份流量数据,结构是:时间戳.手机号.....上行流量.下行流量,需求是统计每个用 ...
- MapReduce(五) mapreduce的shuffle机制 与 Yarn
一.shuffle机制 1.概述 (1)MapReduce 中, map 阶段处理的数据如何传递给 reduce 阶段,是 MapReduce 框架中最关键的一个流程,这个流程就叫 Shuffle:( ...
- hadoop的mapReduce和Spark的shuffle过程的详解与对比及优化
https://blog.csdn.net/u010697988/article/details/70173104 大数据的分布式计算框架目前使用的最多的就是hadoop的mapReduce和Spar ...
- MapReduce框架原理
MapReduce框架原理 3.1 InputFormat数据输入 3.1.1 切片与MapTask并行度决定机制 1.问题引出 MapTask的并行度决定Map阶段的任务处理并发度,进而影响到整个J ...
随机推荐
- Android 隐式 Intent 跳转注意事项
前几天正好看到<阿里巴巴 Android 开发手册>中提到的: “Activity 间通过隐式 Intent 的跳转,在发出 Intent 之前必须通过 resolveActivity 检 ...
- 《ArcGIS Runtime SDK for Android开发笔记》——数据制作篇:紧凑型切片制作(Server缓存切片)
1.前言 在ArcGIS 10中出现了一种新的切片缓存文件格式:紧凑型存储(Compact).与之前的松散型存储(Exploded)相比,它有迁移方便.创建更快.减少存储空间等诸多优点,已经成为了现在 ...
- CSS样式编写案例
1.制作如图三角形效果: 步骤一:将右侧盒子设置为相对定位 步骤二:在右侧盒子里面新建个子盒子,设置宽高相等,为正方形,绝对定位 步骤三:将绝对定位的盒子用CSS3旋转属性旋转 2.制定如图的序列号 ...
- python在Android下的自动化测试用法
# This Python file uses the following encoding: utf-8from com.android.monkeyrunner import MonkeyRunn ...
- 缓存溢出Buffer Overflow
缓存溢出(Buffer overflow),是指在存在缓存溢出安全漏洞的计算机中,攻击者可以用超出常规长度的字符数来填满一个域,通常是内存区地址.在某些情况下,这些过量的字符能够作为“可执行”代码来运 ...
- OC extern和函数
#include <stdio.h> // 定义一个one函数 // 完整地定义一个外部函数需要extern关键字 //extern void one() { // printf(&quo ...
- Android应用经典主界面框架之中的一个:仿QQ (使用Fragment, 附源代码)
备注:代码已传至https://github.com/yanzi1225627/FragmentProject_QQ 欢迎fork,如今来审视这份代码,非常多地方写的不太好,欢迎大家指正.有时间我会继 ...
- POJ1990 MooFest
嘟嘟嘟 题目大意:一群牛参加完牛的节日后都有了不同程度的耳聋(汗……),第i头牛听见别人的讲话,别人的音量必须大于v[i],当两头牛i,j交流的时候,交流的最小声音为max{v[i],v[j]}*他们 ...
- 【洛谷P1159】排行榜
排行榜 题目链接 看到题解中一个很巧妙的做法: 先确定SAME的位置, 将DOWN的按输入顺序从上往下输出 再将UP的接着从上往下输出 这样便可以保证DOWN的人名次一定下降了 UP的人名次一定上升了 ...
- SqlSugar之DbContext
创建一个DbContext和DbSet进行使用,我们可以在DbSet中进行扩展我们的方法 //可以直接用SimpleClient也可以扩展一个自个的类 //推荐直接用 SimpleClient //为 ...