蒙特卡罗树搜索(MCTS)【转】
简介
最近AlphaGo Zero又火了一把,paper和各种分析文章都有了,有人看到了说不就是普通的Reinforcement learning吗,有人还没理解估值网络、快速下子网络的作用就放弃了。
实际上,围棋是一种零和、信息对称的combinatorial game,因此AlphaGo用的是蒙特卡罗树搜索算法的一种,在计算树节点Q值时使用了ResNet等神经网络模型,只是在论文中也归类为增强学习而已。
如果你想真正了解AlphaGo的原理(或者不被其他AI将统治人类的文章所忽悠),理解蒙特卡罗树搜索(Monte Carlo Tree Search)、博弈论(Game Theory)、多臂laohu机(Multi-arm Bandit)、探索与利用(Exploration and Exploitation)等基础必不可少。
MCTS初探
MCTS也就是蒙特卡罗树搜索(Monte Carlo Tree Search),是一类树搜索算法的统称,可以较为有效地解决一些探索空间巨大的问题,例如一般的围棋算法都是基于MCTS实现的。
这类算法要解决的问题是这样的,我们把围棋的每一步所有可能选择都作为树的节点,第零层只有1个根节点,第1层就有361种下子可能和节点,第2层有360种下子可能和节点,这是一颗非常大的树,我们要在每一层树节点中搜索出赢概率最大的节点,也就是下子方法。
那么树搜索的算法有很多,如果树的层数比较浅,我们可以穷举计算每个节点输赢的概率,那么可以使用一种最简单的策略,叫做minmax算法。基本思路是这样的,从树的叶子结点开始看,如果是本方回合就选择max的,如果是对方回合就是min的,实际上这也是假设对方是聪明的也会使用minmax算法,这样在博弈论里面就达到一个纳什均衡点。
这是搜索空间比较小的时候的策略,MCTS要解决的问题是搜索空间足够大,不能计算得到所有子树的价值,这是需要一种较为高效的搜索策略,同时也得兼顾探索和利用,避免陷入局部最优解。MCTS实现这些特性的方式有多种,例如经典的UCB(Upper Confidence Bounds)算法,就是在选择子节点的时候优先考虑没有探索过的,如果都探索过就根据得分来选择,得分不仅是由这个子节点最终赢的概率来,而且与这个子节点玩的次数成负相关,也就是说这个子节点如果平均得分高就约有可能选中(因为认为它比其他节点更值得利用),同时如果子节点选中次数较多则下次不太会选中(因为其他节点选择次数少更值得探索),因此MCTS根据配置探索和利用不同的权重,可以实现比随机或者其他策略更有启发式的方法。
到这里我们需要理解,蒙特卡罗树搜索是一种基于树数据结构、能权衡探索与利用、在搜索空间巨大仍然比较有效的的搜索算法。至于这个树搜索算法主要包括Selection、Expansion、Simulation和Backpropagation四个阶段,具体原理和实现会在后面介绍。
前面提到MCTS的使用场景需要是搜索空间巨大,因为搜索空间如果在计算能力以内,其实是没必要用MCTS的,而真正要应用上还需要有其他的假设。涉及到博弈论的概念,我们要求的条件是zero-sum、fully information、determinism、sequential、discrete,也就是说这个场景必须是能分出输赢(不能同时赢)、游戏的信息是完全公开的(不像打牌可以隐藏自己的手牌)、确定性的(每一个操作结果没有随机因素)、顺序的(操作都是按顺序执行的)、离散的(没有操作是一种连续值),除了博弈论我们要求场景是类似多臂laohu机的黑盒环境,不能通过求导或者凸优化方法找到最优解,否则使用MCTS也是没有意义。因此在讨论蒙特卡罗树搜索前,我们需要先有下面的理论基础。
Game theory基础
Game theory翻译过来就是博弈论,其实是研究多个玩家在互相交互中取胜的方法。例如在耶鲁大学的博弈论公开课中,有一个游戏是让全班同学从0到100中选一个数,其中如果选择的数最接近所有数的平均值的三分之一则这个玩家获胜。首先大家应该不会选择比33大的数,因为其他人都选择100也不能赢不了,那么如果大家都选择比33小,自己就应该选择比11小的数,考虑到其他人也是这样想的,那么自己应该选择比11小很多的数,如果我知道别人也知道自己选择比11小很多的数的话,那应该选择更小的数。那么这个游戏的理想值是0,也就是纳什均衡点,就是当对方也是深晦游戏规则并且知道你也很懂游戏规则时做出的最优决定,当然第一次游戏大家都不是完美的决策者(或者不知道对方是不是完美的决策者),因此不一定会选择纳什均衡点,但多次游戏后结果就是最终取胜的就是非常接近0的选择。
那么前面提到的什么是纳什均衡点呢?这是Game theory里面很神奇的概念,就是所有人已经选择了对自己而言的最优解并且自己单方面做其他选择也无法再提高的点。也就是说,如果玩家都是高手,能达到或者逼近纳什均衡的策略就是最优策略,如果对手不是高手不会选择最优策略,那么纳什均衡点不一定保证每局都赢,但长远来看极大概率会赢这样的新手。
那么前面提到MCTS适用于特定的游戏场景,因此MCTS也是一种找到逼近纳什均衡的搜索策略。那么逼近纳什均衡点的策略还有很多,例如前面提到的minmax算法,还有适用于非信息对称游戏的CFR(Counterfactual Regret)算法。像德州扑克我们就会考虑用CFR而不是MCTS,为什么呢?因为MCTS要求是一种Combinatorial Game而不能是信息不对称的。
在博弈论里,信息对称(Perfect information / Fully information)是指游戏的所有信息和状态都是所有玩家都可以观察到的,因此双方的游戏策略只需要关注共同的状态即可,而信息不对称(Imperfect information / Partial information)就是玩家拥有只有自己可以观察到的状态,这样游戏决策时也需要考虑更多的因素。
还有一个概念就是零和(zero-sum),就是所有玩家的收益之和为零,如果我赢就是你输,没有双赢或者双输,因此游戏决策时不需要考虑合作等因素。
那么博弈论中,我们把zero-sum、perfect
information、deterministic、discrete、sequential的游戏统称为Combinatorial Game,例如围棋、象棋等,而MCTS只能解决Combinatorial Game的问题。
对博弈论感兴趣的,可以在 网易公开课 参加耶鲁大学博弈论公开课。
Black box optimization基础
了解完Game theory,第二个需要了解的是Black box optimization,也就是黑盒优化。我们知道优化就是根据给定的数据集找到更好的选择,例如机器学习就是典型的优化过程,但我们用的机器学习算法如LR、SVM、DNN都不是黑盒,而是根据数学公式推导通过对函数求导等方式进行的优化。如果我们能把问题描述成一个函数或者凸优化问题,那么我们通过数学上的求导就可以找到最优解,这类问题并不需要用到MCTS等搜索算法,但实际上很多问题例如围棋就无法找到一个描述输赢的函数曲线,这样就无法通过纯数学的方法解决。
这类问题统称为黑盒优化问题,我们不能假设知道这个场景内部的函数或者模型结构,只能通过给定模型输入得到模型输出结果来优化。例如多臂laohu机(Multi-arm Bandit)问题,我们有多台laohu机可以投币,但不知道每一台输赢的概率,只能通过多次投币来测试,根据观察的结果预估每台机器的收益分布,最终选择认为收益最大的,这种方法一般会比随机方法效果好。
黑盒优化的算法也有很多,例如进化算法、贝叶斯优化、MCTS也算是,而这些算法都需要解决如何权衡探索和利用(Exploration and Exploitation)的问题。如果我们只有一个投币,那么当前会选择期望收益最高的laohu机来投(Exploitation),但如果我们有一万个投币,我们不应该只投一个laohu机,而应该用少量币来探索一下其他laohu机(Exploration),说不定能跳过局部最优解找到更优解,当然我们也不能全部投币都用来探索了。
对于Exploration和Exploitation,我在 一种更好的超参数调优方式 有更详细的剖析,感兴趣可以关注下 。
UCB算法基础
前面讲了Game theory和Black box optimization,这里再补充一个UCB算法基础,这是MCTS的经典实现UCT(Upper Confidence bounds for Trees)里面用到的算法。
算法本身很简单,公式如下。
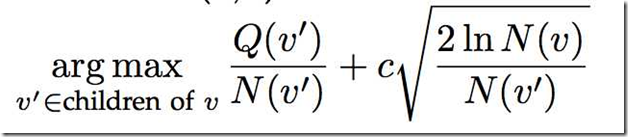
其中v'表示当前树节点,v表示父节点,Q表示这个树节点的累计quality值,N表示这个树节点的visit次数,C是一个常量参数(可以控制exploitation和exploration权重)。
这个公式的意思时,对每一个节点求一个值用于后面的选择,这个值有两部分组成,左边是这个节点的平均收益值(越高表示这个节点期望收益好,越值得选择,用于exploitation),右边的变量是这个父节点的总访问次数除以子节点的访问次数(如果子节点访问次数越少则值越大,越值得选择,用户exploration),因此使用这个公式是可以兼顾探索和利用的。
用Python也很容易实现这个算法,其中C常量我们可以使用 ,这是Kocsis、Szepesvari提出的经验值,完整代码如下。
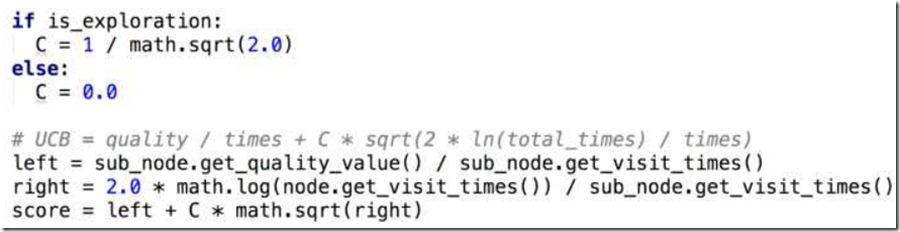
这样我们就有了MCTS的最基础选择算法实现了,下面讨论完整的MCTS算法实现。
MCTS算法原理
首先,MCTS的完整实现代码在 tobegit3hub/ml_implementation ,想直接看源码或者测试的可以去下载运行。
然后,我们需要知道MCTS的算法步骤,可以参考论文 A Survey of Monte Carlo Tree Search Methods http://pubs.doc.ic.ac.uk/survey-mcts-methods/survey-mcts-methods.pdf 。
MCTS的算法分为四步,第一步是Selection,就是在树中找到一个最好的值得探索的节点,一般策略是先选择未被探索的子节点,如果都探索过就选择UCB值最大的子节点。第二步是Expansion,就是在前面选中的子节点中走一步创建一个新的子节点,一般策略是随机自行一个操作并且这个操作不能与前面的子节点重复。第三步是Simulation,就是在前面新Expansion出来的节点开始模拟游戏,直到到达游戏结束状态,这样可以收到到这个expansion出来的节点的得分是多少。第四步是Backpropagation,就是把前面expansion出来的节点得分反馈到前面所有父节点中,更新这些节点的quality value和visit times,方便后面计算UCB值。
基本思路就是这样的,通过不断的模拟得到大部分节点的UCB值,然后下次模拟的时候根据UCB值有策略得选择值得利用和值得探索的节点继续模拟,在搜索空间巨大并且计算能力有限的情况下,这种启发式搜索能更集中地、更大概率找到一些更好的节点。下面是论文的伪代码实现。

其中TREE_POLICY就是实现了Selection和和Expansion两个阶段,DEFAULT_POLICY实现了Simulation阶段,BACKUP实现了Backpropagation阶段,基本思路和前面介绍的一样。
MCTS算法实现
最后我们看一下前面基于Python的MCTS代码实现,源码在 tobegit3hub/ml_implementation ,这是整理的代码实现架构图。

由于这是一棵树,我们需要定义N叉树的Node数据结构。

首先Node包含了parent和children属性,还有就是用于计算UCB值的visit times和quality value,为了关联游戏状态,我们还需要为每个Node绑定一个State对象。Node需要实现增加节点、删除节点等功能,还有需要提供函数判断子节点的个数和是否有空闲的子节点位置。
而State的定义与我们使用MCTS的游戏定义有关,我们定义下面的数据结构。
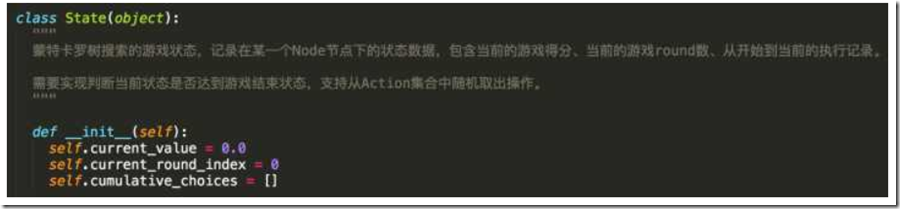
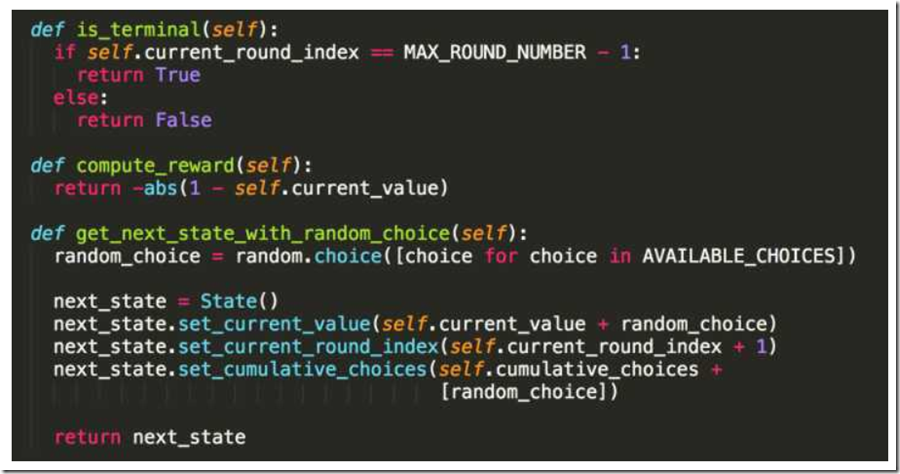
每一个State都需要包含当前的游戏得分,可以继续当前游戏玩到第几轮,还有每一轮的选择是什么。当然更重要的,它还需要实现is_terminal()方法判断游戏是否结局,实现compute_reward()方法告诉用户当前得分是多少,还有提供get_next_state()方法用户进行游戏得到新的状态,几个函数与游戏场景游戏,这里简单实现了一个“选择数字保证累加和为1”的游戏。
要实现伪代码提到的几个方法,我们直接定义一个monte_carlo_tree_search()函数,然后依次调用tree_policy()、default_policy()、backup()这些方法实现即可。
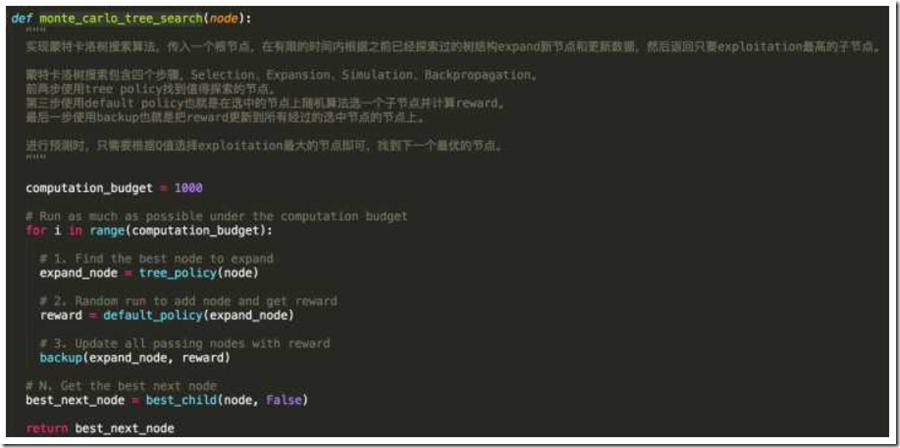
为了避免程序无限搜索下去,我们需要定义一个computation budget,限制搜索次数或者搜索时间,这里限制只能向下搜索1000次,然后通过下面的方法来找到expansion node、计算reward、并且backpropation到所有有关的节点中。我们继续看一下tree_policy()实现。
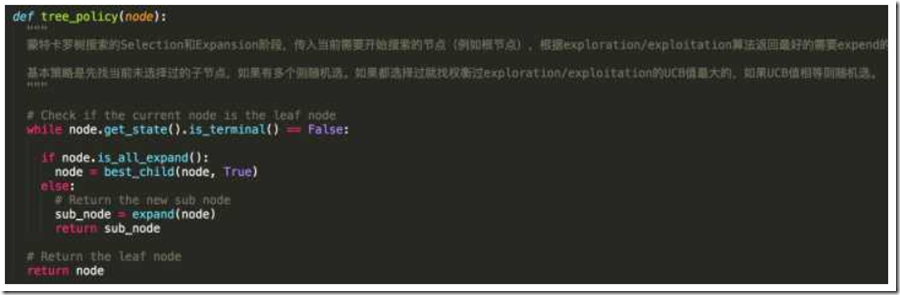
这里代码很简洁,实现了一个策略,就是检查如果一个节点下面还有未探索的子节点,那么先expansion下面的子节点就可以了,如果没有子节点,那么就用best_child()函数(其实也就是UCB算法)来得到下一个子节点,然后便利下直到有未探索的节点可以探索。
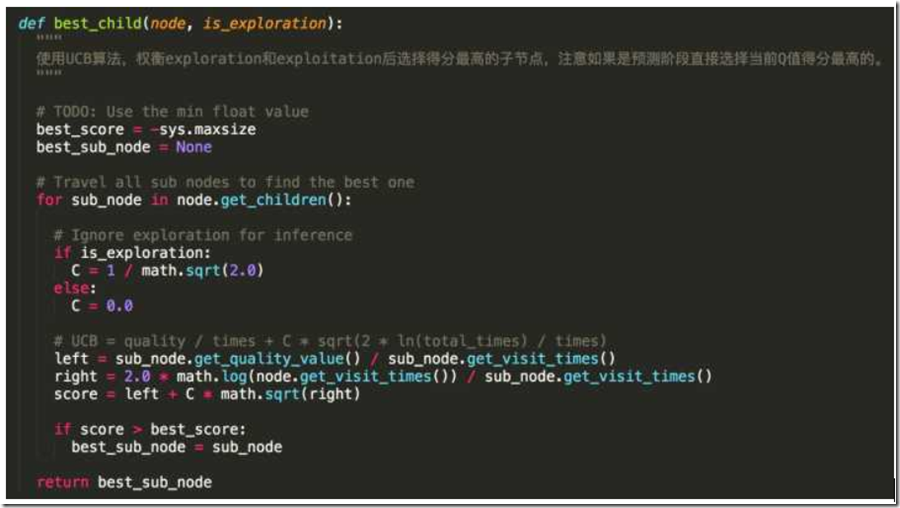
best_child()算法很简单,就是根据Node的State获取quality value和visit times,然后计算出UCB值,然后比较返回UCB值最大的子节点而已。
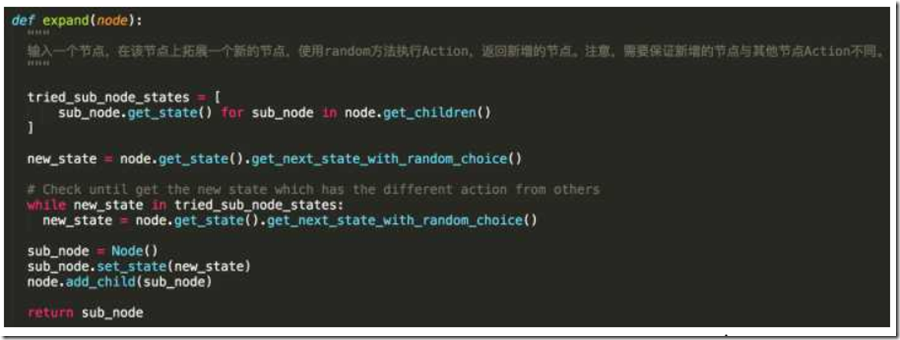
expand()函数实现稍微复杂些,实际上就是在当前节点下,选择一个未被执行的Action来执行即可,策略就是随机选,如果有随机选中之前已经执行过的则重新选。
因此tree_policy()方法就是根据是否有未探索子节点和UCB值(也就是权衡和exploration和exploitation)后选出了expansion节点,然后就是用default_policy()来模拟剩下的游戏了。
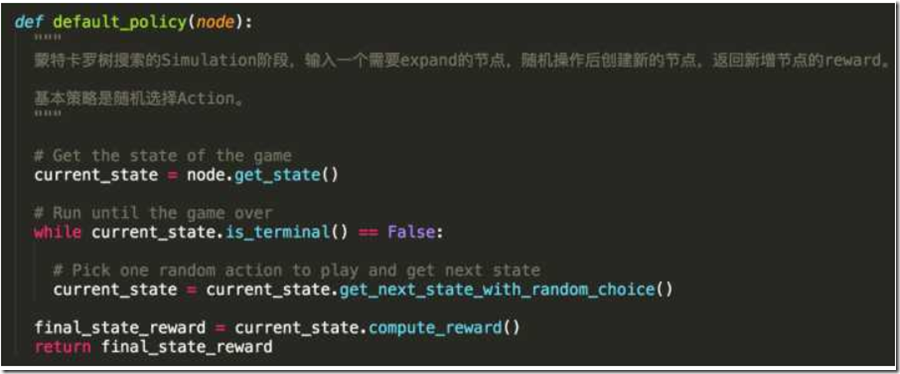
在这个游戏种模拟也很简单,我们直接调用State类中实现的随机玩游戏策略,一直玩到最后得到一个reward值即可,当然对于AlphaGo等其他游戏可能需要实现一个更优的快速走子网络实现类似的功能,后面会细谈区别与AlphaGo的区别。
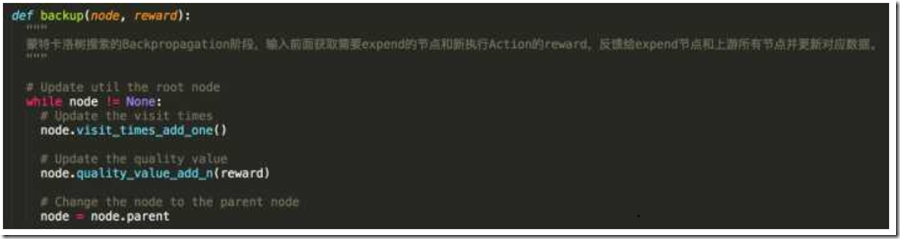
那么最后我们就需要把前面计算的这个reward反馈到“相关的”的节点上了,这个相关的意思是从根节点开始一直到这个expansion节点经过的所有节点,他们的quality value和visit times都需要更新,backup()函数实现如下。
这就是实现一个典型MCTS算法的完整实现,大概两百多行代码即可,可以通过它来玩搜索空间很大的游戏,并且在给定一定计算能力的基础上找到较优的解。感兴趣的还可以关注下 tobegit3hub/ml_implementation,里面有更多机器学习算法的实现源码,也可以提Pull-request贡献更多的算法代码。
AlphaGo算法区别
前面我们实现的这种基于UCB的MCTS算法,实际上离训练围棋机器人的算法还是比较远的,其中AlphaGo也是基于MCTS算法,但做了很多优化。
我简单看了下 http://www.algorithmdog.com/alphago-zero-notes 的介绍,AlphaGo不仅替换了经典实现的UCB算法,而是使用policy network的输出替换父节点访问次数,同样使用子节点访问次数作为分母保证exploration,Q值也改为从快速走子网络得到的所有叶子节点的均值,神经网络也是从前代的CNN改为最新的ResNet,这样复杂的神经网络模型比一般的UCB算法效果会好更多。
首先,AlphaGo每个节点可选action太多了,selection阶段不能像前面先遍历完所有子节点再expansion,这里是用改进的UCB算法来找到最优的需要expansion子节点,算法基本类似也是有控制exploration/exploitation的常量C并且与该子节点visit times成反比。
其次,进行expansion时不会像前面这样直接random选择任意的action,而是这里也考虑到exploration/exploitation,一般前30步根据visit times成正比来选择,这样可以尽可能得先探索(根节点加入了狄利克雷分布保证所有点都经过),后面主要是根据visit times来走了。
第三,新版AlphaGo Zero去掉了基于handcraft规则的rollout policy,也就是快速走子网络,以前是必须有快速走子直到完成比赛才能得到反馈,现在是直接基于神经网络计算预估的winer value概率值,然后平均得到每个子节点的state-action value也就是Q值。
第四,AlphaGo在MCTS基础上收集最终的比赛结果作为label,MCTS作为policy evalution和policy iteration来实现增强学习。
当然AlphaGo在MCTS上还可以做更懂优化,只是一旦我们理解了MCTS的核心原理,看这些paper和介绍就更加清晰明了。
总结
最后再次推荐蒙特卡罗树搜索的论文 A Survey of Monte Carlo Tree Search Methods http://pubs.doc.ic.ac.uk/survey-mcts-methods/survey-mcts-methods.pdf ,里面提到MCTS适用于各种Combinatorial game的场景,当然也提到它的不足,例如在象棋游戏种就不如围棋效果好。
希望大家看完有所启发,也能用蒙特卡罗树搜索做出更有意思的东西!!!
转自:https://zhuanlan.zhihu.com/p/30458774
知乎对于人机大战的关注度很高,所以写这个系列,希望能让大家对于人工智能和围棋有更多的了解。如果有收获,请记得点一下赞。
本系列已更新多篇,其它几篇的传送门:
- (1) : 围棋 AI 基础 知乎专栏
- (2) : 安装 MXNet 搭建深度学习环境 知乎专栏
- (3) : 训练策略网络,真正与之对弈 知乎专栏
- (4) : 对于策略网络的深入分析(以及它的弱点所在) 知乎专栏
- (4.5):后文预告(Or 为什么你应该试试 Batch Normalization 和 ResNet)知乎专栏
- (5):结合强化学习与深度学习的 Policy Gradient(左右互搏自我进化的基础) 知乎专栏
蒙特卡洛树搜索(MCTS)是所有现代围棋程序的核心组件。在此之上可以加入各种小技巧(如 UCT,RAVE/AMAF,Progressive Bias,Virtual win & lose,Progressive Widening,LGR,Criticality 等等)和大改进(如 AlphaGo 的策略网络和价值网络)。
网上很少见到关于 MCTS 的详细介绍,而且许多看似详细的介绍实际有错误,甚至许多人会混淆蒙特卡洛树搜索和蒙特卡洛方法。这两者有本质区别。用做过渲染器的朋友会理解的话来说:蒙特卡洛方法有偏差(Bias),而MCTS没有偏差(Bias)。我们在后文会解释。
一、极小极大(Minimax)搜索
先看传统的博弈游戏树搜索,著名的极小极大(Minimax)搜索,学过算法的朋友会清楚。看下图,假设现在轮到黑棋,黑棋有b1和b2两手可选,白棋对于b1有w1和w2两手可选,白棋对于b2有w3 w4 w5三手可选:
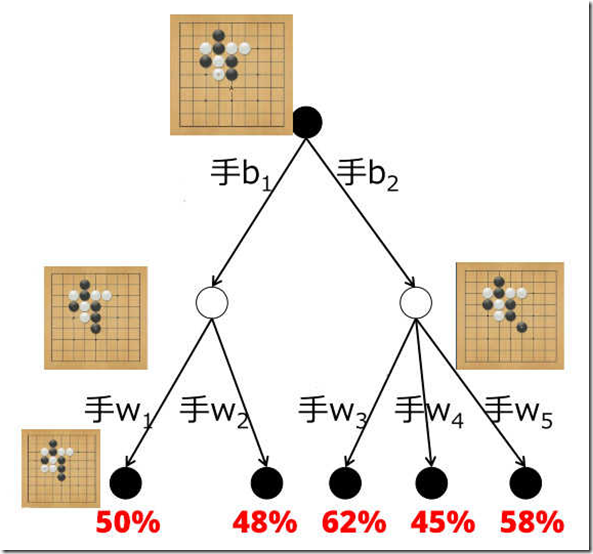
然后假设走完w1/w2/w3/w4/w5后,经过局面评估,黑棋的未来胜率分别是 50%/48%/62%/45%/58%(等一下,这些胜率是怎么评估出来的?我们后文会说这个问题)。
请问,黑棋此时最佳的着法是b1还是b2?如果是用蒙特卡洛方法,趋近的会是其下所有胜率的平均值。例如经过蒙特卡洛模拟,会发现b1后续的胜率是49% = (50+48)/2,而b2后续的胜率是55% = (62+45+58)/3。
于是蒙特卡洛方法说应该走b2,因为55%比49%的胜率高。但这是错误的。因为如果白棋够聪明,会在黑棋走b1的时候回应以w2(尽量降低黑棋的胜率),在黑棋走b2的时候回应以w4(尽量降低黑棋的胜率)。
所以走b1后黑棋的真实胜率是48%,走b2后黑棋的真实胜率是45%。黑棋的正解是b1。这就是 Minimax 搜索的核心思想:在搜索树中,每次轮到黑棋走时,走对黑棋最有利的;轮到白棋走时,走对黑棋最不利的。由于围棋是零和游戏,这就可以达到最优解。这是一个由底往上的过程:先把搜索树画到我们可以承受的深度,然后逐层往上取最大值或最小值回溯,就可以看到双方的正解(如果胜率评估是准确的)。而实际编程的时候,是往下不断生长节点,然后动态更新每个父节点的胜率值。
下图是一个更多层的例子:
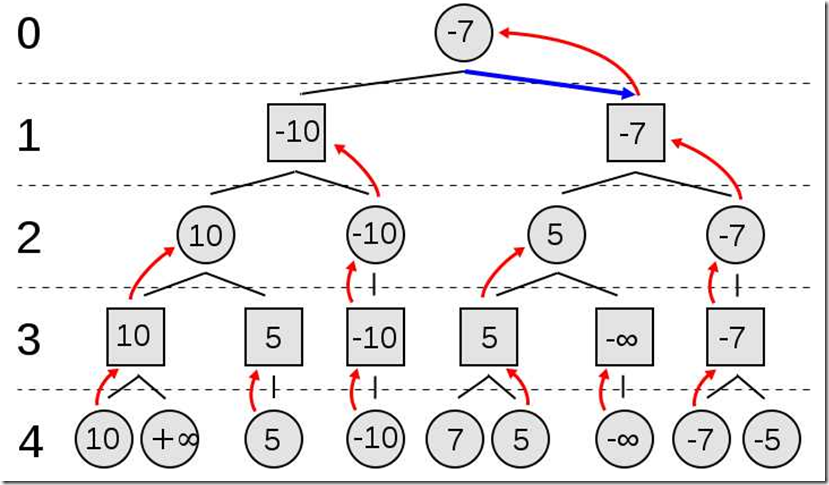
值得注意的是,在实际对局中,胜率评估会有不准确的地方,这就会导致“地平线效应”,即由于电脑思考的深度不够,且胜率评估不够准确,因此没有看见正解。
Minimax 搜索还有许多后续发展,如课本会说的 Alpha-beta 剪枝,以及更进一步的 Null Window / NegaScout / MTD(f) 等等。可惜这些方法更适合象棋等棋类,对于围棋的意义不大(除非已经接近终局),请读者思考原因。
蒙特卡洛树搜索和蒙特卡洛方法的区别在于:
- 如果用蒙特卡洛方法做上一百万次模拟,b1和b2的胜率仍然会固定在49%和55%,不会进步,永远错误。所以它的结果存在偏差(Bias),当然,也有方差(Variance)。
- 而蒙特卡洛树搜索在一段时间模拟后,b1和b2的胜率就会向48%和45%收敛,从而给出正确的答案。所以它的结果不存在偏差(Bias),只存在方差(Variance)。但是,对于复杂的局面,它仍然有可能长期陷入陷阱,直到很久之后才开始收敛到正确答案。
二、蒙特卡洛树搜索
如果想把 Minimax 搜索运用到围棋上,立刻会遇到两个大问题:
- 搜索树太广。棋盘太大了,每一方在每一步都有很多着法可选。
- 很难评估胜率。除非把搜索树走到终局,这意味着要走够三百多步(因为对于电脑来说,甚至很难判断何时才是双方都同意的终局,所以只能傻傻地填子,一直到双方都真的没地方可以走为止)。简单地说,搜索树也需要特别深。
蒙特卡洛树搜索的意义在于部分解决了上述两个问题:
- 它可以给出一个局面评估,虽然不准,但比没有强。这就部分解决了第二个问题。
- 根据它的设计,搜索树会较好地自动集中到“更值得搜索的变化”(注意,也不一定准)。如果发现一个不错的着法,蒙特卡洛树搜索会较快地把它看到很深,可以说它结合了广度优先搜索和深度优先搜索,类似于启发式搜索。这就部分解决了第一个问题。
最后,随着搜索树的自动生长,蒙特卡洛树搜索可以保证在足够长的时间后收敛到完美解(但可能需要极长的时间)。下面看具体过程(需要指出,下图是网络上常见的一个图,但其实有错误):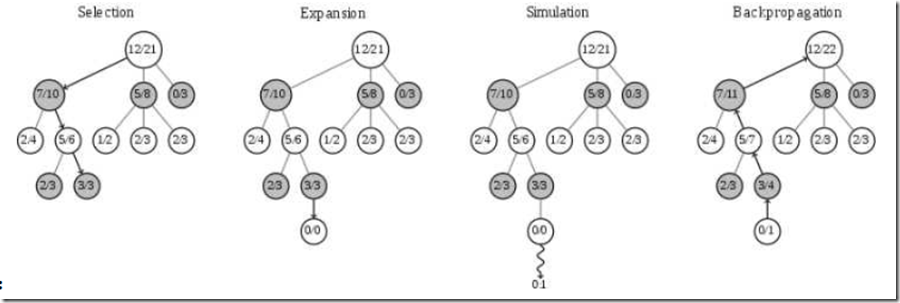
上图中每个节点代表一个局面。而 A/B 代表这个节点被访问 B 次,黑棋胜利了 A 次。例如一开始的根节点是 12/21,代表总共模拟了 21 次,黑棋胜利了 12 次。
我们将不断重复一个过程(很多万次):
- 这个过程的第一步叫选择(Selection)。从根节点往下走,每次都选一个“最值得看的子节点”(具体规则稍后说),直到来到一个“存在未扩展的子节点”的节点,如图中的 3/3 节点。什么叫做“存在未扩展的子节点”,其实就是指这个局面存在未走过的后续着法。
- 第二步叫扩展(Expansion),我们给这个节点加上一个 0/0 子节点,对应之前所说的“未扩展的子节点”,就是还没有试过的一个着法。
- 第三步是模拟(Simluation)。从上面这个没有试过的着法开始,用快速走子策略(Rollout policy)走到底,得到一个胜负结果。按照普遍的观点,快速走子策略适合选择一个棋力很弱但走子很快的策略。因为如果这个策略走得慢(比如用 AlphaGo 的策略网络走棋),虽然棋力会更强,结果会更准确,但由于耗时多了,在单位时间内的模拟次数就少了,所以不一定会棋力更强,有可能会更弱。这也是为什么我们一般只模拟一次,因为如果模拟多次,虽然更准确,但更慢。
- 第四步是回溯(Backpropagation)。把模拟的结果加到它的所有父节点上。例如第三步模拟的结果是 0/1(代表黑棋失败),那么就把这个节点的所有父节点加上 0/1。
三、重要细节
怎么选择节点?和从前一样:如果轮到黑棋走,就选对于黑棋有利的;如果轮到白棋走,就选对于黑棋最不利的。但不能太贪心,不能每次都只选择“最有利的/最不利的”,因为这会意味着搜索树的广度不够,容易忽略实际更好的选择。
因此,最简单有效的选择公式是这样的:
其中 x 是节点的当前胜率估计(注意,如前所述,要考虑当前是黑棋走还是白棋走!),N 是节点的访问次数。C 是一个常数。C 越大就越偏向于广度搜索,C 越小就越偏向于深度搜索。注意对于原始的 UCT 有一个理论最优的 C 值,但由于我们的目标并不是最小化“遗憾”,因此需要根据实际情况调参。
我们看例子说明这是什么意思,就看之前的图吧。假设根节点是轮到黑棋走。那么我们首先需要在 7/10、5/8、0/3 之间选择:
- 其中 7/10 对应的分数为
。
- 其中 5/8 对应的分数为
。
- 其中 0/3 对应的分数为
。
- 可以注意到,C越大,就会越照顾访问次数相对较少的子节点。
如果 C 比较小,我们将会选择 7/10,接着就要在 2/4 和 5/6 间选择。注意,由于现在是白棋走,需要把胜率估计倒过来:
- 其中 2/4 对应的分数为
。
- 其中 5/6 对应的分数为
。
那么我们下一步肯定应该选 2/4。所以说之前的图是错误的,因为制图的人并没有注意到要把胜率倒过来(有朋友会说是不是可以认为它的白圈代表白棋的胜率,但这样它的回溯过程就是错的)。
最后,AlphaGo 的策略网络,可以用于改进上述的分数公式,让我们更准确地选择需扩展的节点。而 AlphaGo 的价值网络,可以与快速走子策略的模拟结果相结合,得到更准确的局面评估结果。注意,如果想写出高效的程序,这里还有很多细节,因为策略网络和价值网络的运行毕竟需要时间,我们不希望等到网络给出结果再进行下一步,在等的时候可以先做其它事情,例如 AlphaGo 还有一个所谓 Tree policy,是在策略网络给出结果之前先用着。
相信大家现在就可以写出正确的 MCTS 程序了(注意:最终应该选择访问量最大的节点,而不是胜率最高的节点,简单地说是因为访问量最大的节点的结果更可靠)。如果要写一个高效的程序,你会发现必须自己写一个内存池。关于 MCTS 还有很多话题可以说,这篇就到这里吧。
本系列已更新多篇,其它几篇的传送门:
- (1) : 围棋 AI 基础 知乎专栏
- (2) : 安装 MXNet 搭建深度学习环境 知乎专栏
- (3) : 训练策略网络,真正与之对弈 知乎专栏
- (4) : 对于策略网络的深入分析(以及它的弱点所在) 知乎专栏
- (4.5):后文预告(Or 为什么你应该试试 Batch Normalization 和 ResNet)知乎专栏
- (5):结合强化学习与深度学习的 Policy Gradient(左右互搏自我进化的基础) 知乎专栏
转自:https://zhuanlan.zhihu.com/p/25345778
蒙特卡罗树搜索(MCTS)【转】的更多相关文章
- 强化学习(十八) 基于模拟的搜索与蒙特卡罗树搜索(MCTS)
在强化学习(十七) 基于模型的强化学习与Dyna算法框架中,我们讨论基于模型的强化学习方法的基本思路,以及集合基于模型与不基于模型的强化学习框架Dyna.本文我们讨论另一种非常流行的集合基于模型与不基 ...
- AlphaGo原理-蒙特卡罗树搜索+深度学习
蒙特卡罗树搜索+深度学习 -- AlphaGo原版论文阅读笔记 目录(?)[+] 原版论文是<Mastering the game of Go with deep neural ne ...
- 蒙特卡罗方法、蒙特卡洛树搜索(Monte Carlo Tree Search,MCTS)初探
1. 蒙特卡罗方法(Monte Carlo method) 0x1:从布丰投针实验说起 - 只要实验次数够多,我就能直到上帝的意图 18世纪,布丰提出以下问题:设我们有一个以平行且等距木纹铺成的地板( ...
- 基于蒙特卡洛树搜索(MCTS)的多维可加性指标的异常根因定位
摘要:本文是我在从事AIOps研发工作中做的基于MCTS的多维可加性指标的异常根因定位方案,方案基于清华大学AIOPs实验室提出的Hotspot算法,在此基础上做了适当的修改. 1 概述 ...
- AlphaGo论文的译文,用深度神经网络和树搜索征服围棋:Mastering the game of Go with deep neural networks and tree search
转载请声明 http://blog.csdn.net/u013390476/article/details/50925347 前言: 围棋的英文是 the game of Go,标题翻译为:<用 ...
- 阿里一面,给了几条SQL,问需要执行几次树搜索操作?
前言 有位朋友去阿里面试,他说面试官给了几条查询SQL,问:需要执行几次树搜索操作?我朋友当时是有点懵的,后来冷静思考,才发现就是考索引的几个基础知识点~~ 本文我们分九个索引知识点,一起来探讨一下. ...
- python kd树 搜索 代码
kd树就是一种对k维空间中的实例点进行存储以便对其进行快速检索的树形数据结构,可以运用在k近邻法中,实现快速k近邻搜索.构造kd树相当于不断地用垂直于坐标轴的超平面将k维空间切分,依次选择坐标轴对空间 ...
- Trie 树——搜索关键词提示
当你在搜索引擎中输入想要搜索的一部分内容时,搜索引擎就会自动弹出下拉框,里面是各种关键词提示,这个功能是怎么实现的呢?其实底层最基本的就是 Trie 树这种数据结构. 1. 什么是 "Tri ...
- easyui 菜单树搜索
//树形菜单搜索方法 function searchTree(treeObj,parentNode,searchCon){ var children; for(var ...
随机推荐
- IE6下css常见bug处理
1.双倍边距 如下图所示,一个样式里面既设定了“float:left:”又有“margin-left:100px:”的情况,就呈现了双倍情况.如外边距设置为100px, 而左侧则呈现出200px,解决 ...
- javascript中实现sleep函数
function sleep(d){ for(var t = Date.now();Date.now() - t <= d;);}
- nginx 中location和root,你确定真的明白他们关系?
最近公司开发新项目,web server使用nginx,趁周末小小的研究了一下,一不小心踩了个坑吧,一直404 not found!!!!!当时卡在location和root中,但是网上却比较少聊这方 ...
- 自定义注解日志功能与shrio框架冲突的问题
<beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w ...
- Emoji表情图标在iOS与PHP之间通信及MySQL存储
在某个 iOS 项目中,需要一个服务器来保存一些用户数据,例如用户信息.评论等,我们的服务器端使用了 PHP+MySQL 的搭配.在测试过程中我们发现,用户在 iOS 端里输入了 Emoji 表情提交 ...
- Oracle----Oracle 11g XE release2安装与指导
今天上午我安装了Oracle 11g企业版,发现太占内存了,考虑到MS SQL有express版本,所以寻思着尝试尝试Oracle 11g的express版本,就是EX版本.下面是具体的安装步骤. 1 ...
- struts.properties文件
此配置文件提供了一种机制来更改默认行为的框架.其实所有的struts.propertiesconfiguration文件中包含的属性也可以被配置在web.xml中使用的init-param,以及在st ...
- python django -6 常用的第三方包或工具
常用的第三方包或工具 富文本编辑器 缓存 全文检索 celery 布署 富文本编辑器 借助富文本编辑器,管理员能够编辑出来一个包含html的页面,从而页面的显示效果,可以由管理员定义,而不用完全依赖于 ...
- python 爬虫1 Urllib库的基本使用
1.简单使用 import urllib2 response = urllib2.urlopen("http://www.baidu.com") print response.re ...
- 自定义实现wcf的用户名密码验证
目前wcf分为[传输层安全][消息层安全]两种,本身也自带的用户名密码验证的功能,但是ms为了防止用户名密码明文在网络上传输,所以,强制要求一旦使用[用户名密码]校验功能,则必须使用证书,按照常理讲, ...