StratifiedShuffleSplit 交叉验证
python中数据集划分函数StratifiedShuffleSplit的使用
文章开始先讲下交叉验证,这个概念同样适用于这个划分函数
1.交叉验证(Cross-validation)
交叉验证是指在给定的建模样本中,拿出其中的大部分样本进行模型训练,生成模型,留小部分样本用刚建立的模型进行预测,并求这小部分样本的预测误差,记录它们的平方加和。这个过程一直进行,直到所有的样本都被预测了一次而且仅被预测一次,比较每组的预测误差,选取误差最小的那一组作为训练模型。下图所示
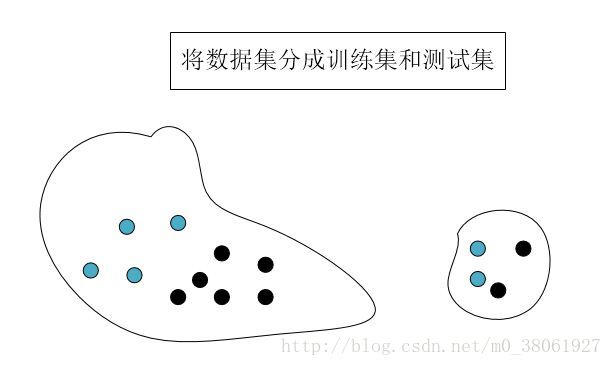
2.StratifiedShuffleSplit函数的使用
官方文档
用法:
from sklearn.model_selection import StratifiedShuffleSplit
StratifiedShuffleSplit(n_splits=10,test_size=None,train_size=None, random_state=None)2.1 参数说明
参数 n_splits是将训练数据分成train/test对的组数,可根据需要进行设置,默认为10
参数test_size和train_size是用来设置train/test对中train和test所占的比例。例如:
1.提供10个数据num进行训练和测试集划分
2.设置train_size=0.8 test_size=0.2
3.train_num=num*train_size=8 test_num=num*test_size=2
4.即10个数据,进行划分以后8个是训练数据,2个是测试数据
注*:train_num≥2,test_num≥2 ;test_size+train_size可以小于1*
参数 random_state控制是将样本随机打乱
2.2 函数作用描述
1.其产生指定数量的独立的train/test数据集划分数据集划分成n组。
2.首先将样本随机打乱,然后根据设置参数划分出train/test对。
3.其创建的每一组划分将保证每组类比比例相同。即第一组训练数据类别比例为2:1,则后面每组类别都满足这个比例
2.3 具体实现
from sklearn.model_selection import StratifiedShuffleSplit
import numpy as np
X = np.array([[1, 2], [3, 4], [1, 2], [3, 4],
[1, 2],[3, 4], [1, 2], [3, 4]])#训练数据集8*2
y = np.array([0, 0, 1, 1,0,0,1,1])#类别数据集8*1
ss=StratifiedShuffleSplit(n_splits=5,test_size=0.25,train_size=0.75,random_state=0)#分成5组,测试比例为0.25,训练比例是0.75
for train_index, test_index in ss.split(X, y):
print("TRAIN:", train_index, "TEST:", test_index)#获得索引值
X_train, X_test = X[train_index], X[test_index]#训练集对应的值
y_train, y_test = y[train_index], y[test_index]#类别集对应的值
运行结果:
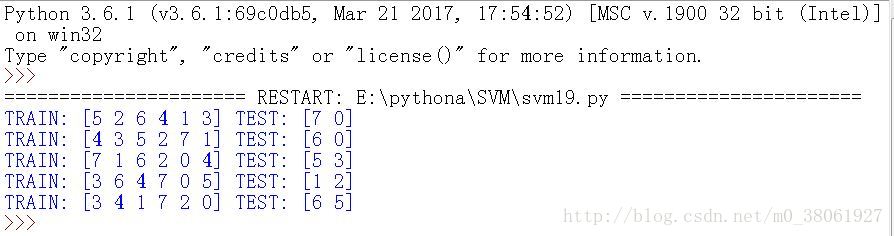
从结果看出,1.训练集是6个,测试集是2,与设置的所对应;2.五组中每组对应的类别比例相同
from:https://blog.csdn.net/m0_38061927/article/details/76180541
StratifiedShuffleSplit 交叉验证的更多相关文章
- 使用sklearn进行交叉验证
模型评估方法 假如我们有一个带标签的数据集D,我们如何选择最优的模型? 衡量模型好坏的标准是看这个模型在新的数据集上面表现的如何,也就是看它的泛化误差.因为实际的数据没有标签,所以泛化误差是不可能直接 ...
- MATLAB曲面插值及交叉验证
在离散数据的基础上补插连续函数,使得这条连续曲线通过全部给定的离散数据点.插值是离散函数逼近的重要方法,利用它可通过函数在有限个点处的取值状况,估算出函数在其他点处的近似值.曲面插值是对三维数据进行离 ...
- 交叉验证(Cross Validation)原理小结
交叉验证是在机器学习建立模型和验证模型参数时常用的办法.交叉验证,顾名思义,就是重复的使用数据,把得到的样本数据进行切分,组合为不同的训练集和测试集,用训练集来训练模型,用测试集来评估模型预测的好坏. ...
- scikit-learn一般实例之一:绘制交叉验证预测
本实例展示怎样使用cross_val_predict来可视化预测错误: # coding:utf-8 from pylab import * from sklearn import datasets ...
- oracle ebs应用产品安全性-交叉验证规则
转自: http://blog.itpub.net/298600/viewspace-625138/ 定义: Oracle键弹性域可以根据自定义键弹性域时所定义的规则,执行段值组合的自动交叉验证.使用 ...
- SVM学习笔记(二):什么是交叉验证
交叉验证:拟合的好,同时预测也要准确 我们以K折交叉验证(k-folded cross validation)来说明它的具体步骤.{A1,A2,A3,A4,A5,A6,A7,A8,A9} 为了简化,取 ...
- 交叉验证 Cross validation
来源:CSDN: boat_lee 简单交叉验证 hold-out cross validation 从全部训练数据S中随机选择s个样例作为训练集training set,剩余的作为测试集testin ...
- k-折交叉验证(k-fold crossValidation)
k-折交叉验证(k-fold crossValidation): 在机器学习中,将数据集A分为训练集(training set)B和测试集(test set)C,在样本量不充足的情况下,为了充分利用数 ...
- paper 35 :交叉验证(CrossValidation)方法思想
交叉验证(CrossValidation)方法思想简介 以下简称交叉验证(Cross Validation)为CV.CV是用来验证分类器的性能一种统计分析方法,基本思想是把在某种意义下将原始数据(da ...
随机推荐
- unknown facet type would you like to ignore facet from module
去idea plugin 里面把红色的插件 重新勾选一下,点apply 重启就可以了
- 024-Spring Boot 应用的打包和部署
一.概述 二.手工打包[不推荐] 打包命令:maven clean package 打包并导出依赖:maven clean package dependency:copy-dependencies 1 ...
- Retrofit2.2说明-简单使用
很久前就想学习下Retrofit了,不过总是没有时间,正好最近新项目要用到网络请求,正好研究了下Retrofit2.2的简单使用方法,大致记录如下: Retrofit与okhttp共同出自于Squar ...
- Oracle 11G无法导出空表的解决办法
11G中有个新特性,当表无数据时,不分配segment,以节省空间解决方法:1.insert一行,再rollback就产生segment了.该方法是在在空表中插入数据,再删除,则产生segment.导 ...
- eval in Shell
语法:eval cmdLine eval会对后面的cmdLine进行两遍扫描,如果第一遍扫描后,cmdLine是个普通命令,则执行此命令: 如果cmdLine中含有变量的间接引用,则保证间接引用的语义 ...
- requirejs源码分析: requirejs 方法–1. 主入口
该方法是 主要的入口点 也是最常用的方法. req = requirejs = function (deps, callback, errback, optional) { //Find the ri ...
- 使用新浪IP库获取IP详细地址
使用新浪IP库获取IP详细地址 <?php class Tool{ /** * 获取IP的归属地( 新浪IP库 ) * * @param $ip String IP地址:112.65.102.1 ...
- python 课堂笔记-for语句
for i in range(10): print("----------",i) for j in range(10): print("world",j) i ...
- Linux常用指令——周琛
ps ax | grep java 查看进程命令里带“java”字样的进程信息,第一列是进程号 kill -9 1234 强制杀死1234号进程 cd /xxx/xxx 进入/xxx/xxx目录 cd ...
- 八、linux优化一
1.关闭selinux sed –I ‘s#SELINUX=enforcing#SELINUX=disabled#g’ /etc/selinux/config grep SELINUX=disable ...