MAPREDUCE的原理和使用
简介:
Mapreduce是一个分布式运算程序的编程框架,是用户开发“基于hadoop的数据分析应用”的核心框架;
Mapreduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个hadoop集群上;
1.1为什么要MAPREDUCE
(1)海量数据在单机上处理因为硬件资源限制,无法胜任
(2)而一旦将单机版程序扩展到集群来分布式运行,将极大增加程序的复杂度和开发难度
(3)引入mapreduce框架后,开发人员可以将绝大部分工作集中在业务逻辑的开发上,而将分布式计算中的复杂性交由框架来处理
设想一个海量数据场景下的wordcount需求:
|
单机版:内存受限,磁盘受限,运算能力受限 分布式: 1、文件分布式存储(HDFS) 2、运算逻辑需要至少分成2个阶段(一个阶段独立并发,一个阶段汇聚) 3、运算程序如何分发 4、程序如何分配运算任务(切片) 5、两阶段的程序如何启动?如何协调? 6、整个程序运行过程中的监控?容错?重试? |
可见在程序由单机版扩成分布式时,会引入大量的复杂工作。为了提高开发效率,可以将分布式程序中的公共功能封装成框架,让开发人员可以将精力集中于业务逻辑。
而mapreduce就是这样一个分布式程序的通用框架,其应对以上问题的整体结构如下:
|
1、MRAppMaster(mapreduce application master) 2、MapTask 3、ReduceTask |
1.2 MAPREDUCE框架结构及核心运行机制
一个完整的mapreduce程序在分布式运行时有三类实例进程:
1、MRAppMaster:负责整个程序的过程调度及状态协调
2、mapTask:负责map阶段的整个数据处理流程
3、ReduceTask:负责reduce阶段的整个数据处理流程
MR程序运行流程
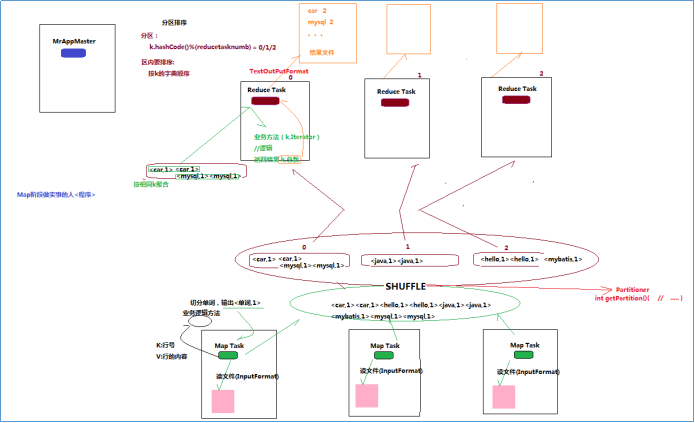
流程解析
1、 一个mr程序启动的时候,最先启动的是MRAppMaster,MRAppMaster启动后根据本次job的描述信息,计算出需要的maptask实例数量,然后向集群申请机器启动相应数量的maptask进程
2、 maptask进程启动之后,根据给定的数据切片范围进行数据处理,主体流程为:
a) 利用客户指定的inputformat来获取RecordReader读取数据,形成输入KV对
b) 将输入KV对传递给客户定义的map()方法,做逻辑运算,并将map()方法输出的KV对收集到缓存
c) 将缓存中的KV对按照K分区排序后不断溢写到磁盘文件
1、 MRAppMaster监控到所有maptask进程任务完成之后,会根据客户指定的参数启动相应数量的reducetask进程,并告知reducetask进程要处理的数据范围(数据分区)
2、 Reducetask进程启动之后,根据MRAppMaster告知的待处理数据所在位置,从若干台maptask运行所在机器上获取到若干个maptask输出结果文件,并在本地进行重新归并排序,然后按照相同key的KV为一个组,调用客户定义的reduce()方法进行逻辑运算,并收集运算输出的结果KV,然后调用客户指定的outputformat将结果数据输出到外部存储
1.3MapTask并行度决定机制
maptask的并行度决定map阶段的任务处理并发度,进而影响到整个job的处理速度那么,mapTask并行实例是否越多越好呢?其并行度又是如何决定呢?
mapTask并行度的决定机制
一个job的map阶段并行度由客户端在提交job时决定
而客户端对map阶段并行度的规划的基本逻辑为:
将待处理数据执行逻辑切片(即按照一个特定切片大小,将待处理数据划分成逻辑上的多个split),然后每一个split分配一个mapTask并行实例处理
这段逻辑及形成的切片规划描述文件,由FileInputFormat实现类的getSplits()方法完成,其过程如下图:

FileInputFormat切片机制
1.切片定义在InputFormat类中的getSplit()方法
2、FileInputFormat中默认的切片机制:
a) 简单地按照文件的内容长度进行切片
b) 切片大小,默认等于block大小
c) 切片时不考虑数据集整体,而是逐个针对每一个文件单独切片
比如待处理数据有两个文件:
|
file1.txt 320M file2.txt 10M |
经过FileInputFormat的切片机制运算后,形成的切片信息如下:
|
file1.txt.split1-- 0~128 file1.txt.split2-- 128~256 file1.txt.split3-- 256~320 file2.txt.split1-- 0~10M |
FileInputFormat中切片的大小的参数配置
通过分析源码,在FileInputFormat中,计算切片大小的逻辑:Math.max(minSize, Math.min(maxSize, blockSize)); 切片主要由这几个值来运算决定
|
minsize:默认值:1 配置参数: mapreduce.input.fileinputformat.split.minsize |
|
maxsize:默认值:Long.MAXValue 配置参数:mapreduce.input.fileinputformat.split.maxsize |
|
blocksize |
因此,默认情况下,切片大小=blocksize
maxsize(切片最大值):
参数如果调得比blocksize小,则会让切片变小,而且就等于配置的这个参数的值
minsize (切片最小值):
参数调的比blockSize大,则可以让切片变得比blocksize还大
选择并发数的影响因素:
1、运算节点的硬件配置
2、运算任务的类型:CPU密集型还是IO密集型
3、运算任务的数据量
1.4 map并行度的经验之谈
如果硬件配置为2*12core + 64G,恰当的map并行度是大约每个节点20-100个map,最好每个map的执行时间至少一分钟。
1.如果job的每个map或者 reduce task的运行时间都只有30-40秒钟,那么就减少该job的map或者reduce数,每一个task(map|reduce)的setup和加入到调度器中进行调度,这个中间的过程可能都要花费几秒钟,所以如果每个task都非常快就跑完了,就会在task的开始和结束的时候浪费太多的时间。
配置task的JVM重用可以改善该问题:
(mapred.job.reuse.jvm.num.tasks,默认是1,表示一个JVM上最多可以顺序执行的task
数目(属于同一个Job)是1。也就是说一个task启一个JVM)
2. 如果input的文件非常的大,比如1TB,可以考虑将hdfs上的每个block size设大,比如设成256MB或者512MB
1.5ReduceTask并行度的决定
reducetask的并行度同样影响整个job的执行并发度和执行效率,但与maptask的并发数由切片数决定不同,Reducetask数量的决定是可以直接手动设置:
//默认值是1,手动设置为4
job.setNumReduceTasks(4);
如果数据分布不均匀,就有可能在reduce阶段产生数据倾斜
注意: reducetask数量并不是任意设置,还要考虑业务逻辑需求,有些情况下,需要计算全局汇总结果,就只能有1个reducetask
尽量不要运行太多的reduce task。对大多数job来说,最好rduce的个数最多和集群中的reduce持平,或者比集群的 reduce slots小。这个对于小集群而言,尤其重要。
1.6MAPREDUCE程序运行演示
Hadoop的发布包中内置了一个hadoop-mapreduce-example-2.4.1.jar,这个jar包中有各种MR示例程序,可以通过以下步骤运行:
启动hdfs,yarn
然后在集群中的任意一台服务器上启动执行程序(比如运行wordcount):
hadoop jar hadoop-mapreduce-example-2.4.1.jar wordcount /wordcount/data /wordcount/out
MAPREDUCE的原理和使用的更多相关文章
- MapReduce工作原理讲解
第一部分:MapReduce工作原理 MapReduce 角色•Client :作业提交发起者.•JobTracker: 初始化作业,分配作业,与TaskTracker通信,协调整个作业.•TaskT ...
- MapReduce工作原理
第一部分:MapReduce工作原理 MapReduce 角色•Client :作业提交发起者.•JobTracker: 初始化作业,分配作业,与TaskTracker通信,协调整个作业.•Tas ...
- 王家林的“云计算分布式大数据Hadoop实战高手之路---从零开始”的第十一讲Hadoop图文训练课程:MapReduce的原理机制和流程图剖析
这一讲我们主要剖析MapReduce的原理机制和流程. “云计算分布式大数据Hadoop实战高手之路”之完整发布目录 云计算分布式大数据实战技术Hadoop交流群:312494188,每天都会在群中发 ...
- MapReduce工作原理图文详解 (炼数成金)
MapReduce工作原理图文详解 1.Map-Reduce 工作机制剖析图: 1.首先,第一步,我们先编写好我们的map-reduce程序,然后在一个client 节点里面进行提交.(一般来说可以在 ...
- [转载] MapReduce工作原理讲解
转载自http://www.aboutyun.com/thread-6723-1-1.html 有时候我们在用,但是却不知道为什么.就像苹果砸到我们头上,这或许已经是很自然的事情了,但是牛顿却发现了地 ...
- Hadoop MapReduce工作原理
在学习Hadoop,慢慢的从使用到原理,逐层的深入吧 第一部分:MapReduce工作原理 MapReduce 角色 •Client :作业提交发起者. •JobTracker: 初始化作业,分配 ...
- 【转载】Hadoop mapreduce 实现原理
1. 如何用通俗的方法解释MapReduce MapReduce是Google开源的三大技术之一,是对海量数据进行“分而治之”计算框架.为了简单的理解并讲述给客户理解.我们举下面的例子来说明. 首先 ...
- Hadoop学习---Hadoop的MapReduce的原理
MapReduce的原理 MapReduce的原理 NameNode:存放文件的元数据信息 DataNode:存放文件的具体内容 ResourceManager:资源管理,管理内存.CPU等 Node ...
- <转>MapReduce工作原理图文详解
转自 http://weixiaolu.iteye.com/blog/1474172前言: 前段时间我们云计算团队一起学习了hadoop相关的知识,大家都积极地做了.学了很多东西,收获颇丰.可是开学 ...
- Mapreduce简要原理与实践
探索Mapreduce简要原理与实践 目录-探索mapreduce 1.Mapreduce的模型简介与特性?Yarn的作用? 2.mapreduce的工作原理是怎样的? 3.配置Yarn与Mapred ...
随机推荐
- Redis 数据备份与恢复,安全,性能测试,客户端连接,管道技术,分区(四)
Redis 数据备份与恢复 Redis SAVE 命令用于创建当前数据库的备份. 语法 redis Save 命令基本语法如下: redis 127.0.0.1:6379> SAVE 实例 re ...
- ionic2——开发利器之Visual Studio Code 常用插件整理
1.VsCode官方插件地址: http://code.visualstudio.com/docs 2.使用方法,可以在官网中搜索需要的插件或者在VsCode的“”扩展“”中搜索需要的插件 添加方法使 ...
- 【Codeforces】894D. Ralph And His Tour in Binary Country 思维+二分
题意 给定一棵$n$个节点完全二叉树,$m$次询问,每次询问从$a$节点到其它所有节点(包括自身)的距离$L$与给定$H_a$之差$H_a-L$大于$0$的值之和 对整棵树从叶子节点到父节点从上往下预 ...
- php压缩文件帮助类
<?php /* File name: /include/zip.php Author: Horace 2009/04/15 */ class PHPZip{ var $dirInfo = ar ...
- Arcgis for Javascript之统计图的实现
首先,截个图给大家看看效果: 初始化状态 放大后的状态 点击选中后的状态 如上图所示,一般的涉及到的地图的统计涉及到上述所展示的三个状态:1.初始化状态:2.缩放后的状态:3.点击选中显示详情状态.第 ...
- beego数据输出
beego数据输出 概览 直接输出字符串 模板数据输出 静态模板数据输出 动态模板数据输出 json格式数据输出 xml格式数据输出 jsonp调用 概览 直接输出字符串 通过beego.Cont ...
- 【MFC】MFC绘图不闪烁——双缓冲技术
MFC绘图不闪烁——双缓冲技术[转] 2010-04-30 09:33:33| 分类: VC|举报|字号 订阅 [转自:http://blog.163.com/yuanlong_zheng@126/ ...
- Java得到当前系统时间,精确到毫秒的几种方法
import java.text.SimpleDateFormat; import java.util.Date; import java.util.Calendar; public class Ma ...
- MATLAB的一些应用--最近用的比较多
MATLAB的一些应用--最近用的比较多 1.MATLAB分析信号的频谱 快速Fourier变换(FFT)是离散傅里叶变换的快速算法,他是根据离散傅里叶变换的奇.偶.虚.实等特性,对离散傅里叶变换的算 ...
- CALayer 实现的动画效果(一)
先看下效果图: (备注: 上面GIF 是Mac 下录制视频的并转化成gif 的而成,工具为GIF Brewery 3 [这款软件挺不错的]) 那么主题来了如何实现上面效果呢? 1.创建自定义CALay ...