(原创)BFS广度优先算法,看完这篇就够了
BFS算法
上一篇文章讲解了DFS深度优先遍历的算法,我们说 DFS 顾名思义DEEPTH FIRET,以深度为第一标准来查找,以不撞南墙不回头的态度来发掘每一个点,这个算法思想get到了其实蛮简单。那么 BFS 和DFS有什么相同点和不同点呢?
我觉得有一种比喻对于 DFS 和 BFS 从方法论的角度解释很到位,DFS 就像是小明要在家里找到钥匙,因为对位置的不确定,所以一间一间的来找,深度遍历能确保小明走过所有的屋子。而 BFS 像是近视的小明的眼镜掉在了地上,小明肯定是先摸索离手比较近的位置,然后手慢慢向远方延伸,直至摸到眼镜,像是以小明为中心搜索圈不断扩大的过程。所以如果说 DFS 从遍历的层次结构上类似树的先序遍历,那么BFS算法按照里外顺序逐渐增加深度的做法,就像极了朴素的层次遍历,例如:
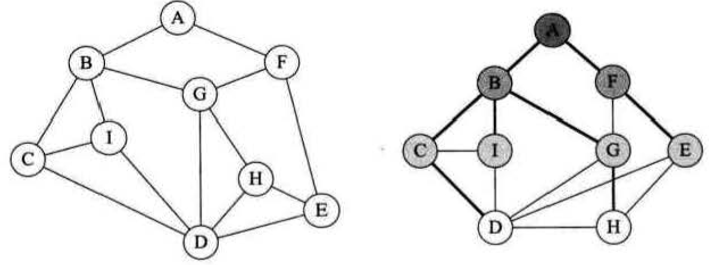
把左图拉平,按照层序把结点排列下来,各节点的连接关系并没有变,图结构没有发生变化,但是这时,我们从A出发,按层序遍历可以得到顺序是 A B F C I G E D H
结合上一篇文章的 DFS ,我们可以发现这两种算法的区别在每一个点上都能得以体现,比如 A 点,DFS 鼓励结点向着一个方向冲,BFS 则会在一个点上按照顶点下标次序遍历完所有没有访问过的结点,比如A点遍历完,马上开始扫描,如果 B F这两个点没有被宠幸过,那么一定要翻完 B、F 这两个点的牌子之后,才会继续访问第二层,即把A点相连的结点全部遍历完成才行,当然到了第二层 发现 B、F 早就被A安排过了,就不再进入这两个点的循环,后面的一样,这里就不再赘述。
我们回忆一下DFS算法,DFS沿着一个方向走最后是要走回头路的,因为它迟早会遍历到一个所有分支都被访问过的结点,那么要走回头路意味着我们实现 DFS 时应该选择后进先出的栈结构,而现在的 BFS 算法是每经过一个点就会遍历所有没访问过的点,同时,一个点如果已经访问完,那么它就没有利用价值了,所以应该使用队列先进先出的特点
这里是图形演示:
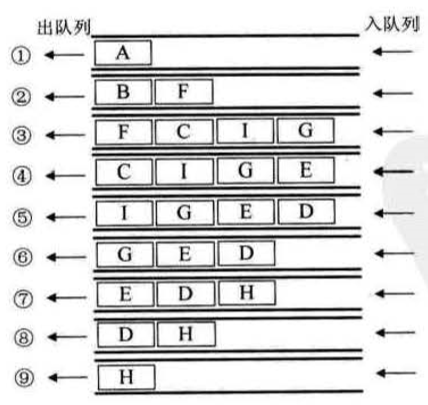
下面我们来看代码实现:
这是邻接矩阵实现 BFS 算法,结构定义见上一篇文章
void BFS(MGraph *G)
{
int i,j;
Queue Q;
InitQueue(&Q);
for(i = ; i < G.numVertexes;i++)
{
visited[i] = FALSE;
}
for(i = ;i < G.numVertexes;i++)
{
if(!visited[i])
{
visited[i] = TRUE;
printf("%c",&G.vexs[i]);
EnQueue(&Q,i);
while(!QueueEmpty(Q))
{
DeQueue(&Q,&i);
for(j = ;j < G.numVertexes;j++)
{
while(G.arc[i][j] == && !visited[j])
{
visited[j] = TRUE;
printf("%c",G.vexs[j]);
EnQueue(&Q,j);
}
}
}
}
}
}
这是邻接表实现的代码:
void BFS(GraphAdjList GL)
{
int i;
Queue Q;
EdgeNode *p;
InitQueue (&Q);
for(i = ;i < GL->shuliang;i++)
{
visited[i] = FALSE;
}
for(i = ;i < GL->shuliang;i++)
{
if(!visited[i])
{
visited[i] = TURE;
printf("%c",GL->adjlist[i].data);
EnQueue(&Q,i);
while(!QueueEmpty(Q))
{
DeQueue(&Q,&i);
p = GL->adjlist[i].firstedge;
while(p)
{
if(!visited[p -> adjvex])
{
visited[p -> adjvex] = TRUE;
printf("%c",GL->adjlist[p -> adjvex].data);
EnQueue(&Q,p->adjvex);
}
p = p -> next;
}
}
}
} }
个人感觉代码蛮好懂,这一块感觉需要多多思考,广度优先和深度优先小到日常生活,大到数据模型,有着广泛的作用,而这篇文章中的两种方法,因为都要遍历整张图,所以其算法时间复杂度相同,所以对于全图遍历并没有什么明确选择的优势,而如果目的在于尽快地找到目的点,那么深度优先更占优势;而如果是不断扩大遍历范围,寻找相对最优解则是广度优先看起来更划算。算法就到这里,经验和思路只能靠大家自己在实践中多多总结,得到自己使用的一套方法。
(原创)BFS广度优先算法,看完这篇就够了的更多相关文章
- 关于 Docker 镜像的操作,看完这篇就够啦 !(下)
紧接着上篇<关于 Docker 镜像的操作,看完这篇就够啦 !(上)>,奉上下篇 !!! 镜像作为 Docker 三大核心概念中最重要的一个关键词,它有很多操作,是您想学习容器技术不得不掌 ...
- MAC上的爬虫软件怎么选?看完这篇就够了
在上一篇文章:网络爬虫软件哪个好用? 中,我们介绍了目前市面上比较成熟好用的网络爬虫软件, 但是其中有些不能在MAC上使用,因此今天这篇文章我们单独介绍一下在MAC操作系统中有哪些好用的爬虫软件,给大 ...
- 还不会ida*算法?看完这篇或许能理解点。
IDA* 算法分析 IDA* 本质上就是带有估价函数和迭代加深优化的dfs与,A * 相似A *的本质便是带 有估价函数的bfs,估价函数是什么呢?估价函数顾名思义,就是估计由目前状态达 到目标状态的 ...
- 研究分布式唯一ID生成,看完这篇就够
很多大的互联网公司数据量很大,都采用分库分表,那么分库后就需要统一的唯一ID进行存储.这个ID可以是数字递增的,也可以是UUID类型的. 如果是递增的话,那么拆分了数据库后,可以按照id的hash,均 ...
- HTML教程(看完这篇就够了)
HTML教程 超文本标记语言(英语:HyperText Markup Language,简称:HTML)是一种用于创建网页的标准标记语言.您可以使用 HTML 来建立自己的 WEB 站点,HTML 运 ...
- 关于 Docker 镜像的操作,看完这篇就够啦 !(上)
文章首发于微信公众号: 小哈学Java 镜像作为 Docker 三大核心概念中,最重要的一个关键词,它有很多操作,是您想学习容器技术不得不掌握的.本文将带您一步一步,图文并重,上手操作来学习它. 目录 ...
- 【最短路径Floyd算法详解推导过程】看完这篇,你还能不懂Floyd算法?还不会?
简介 Floyd-Warshall算法(Floyd-Warshall algorithm),是一种利用动态规划的思想寻找给定的加权图中多源点之间最短路径的算法,与Dijkstra算法类似.该算法名称以 ...
- [转帖]看完这篇文章,我奶奶都懂了https的原理
看完这篇文章,我奶奶都懂了https的原理 http://www.17coding.info/article/22 非对称算法 以及 CA证书 公钥 核心是 大的质数不一分解 还有 就是 椭圆曲线算法 ...
- Mysql快速入门(看完这篇能够满足80%的日常开发)
这是一篇mysql的学习笔记,整理结合了网上搜索的教程以及自己看的视频教程,看完这篇能够满足80%的日常开发了. 菜鸟教程:https://www.runoob.com/mysql/mysql-tut ...
随机推荐
- 【洛谷P2426】删数
删数 题目链接 一道裸的区间DP,f[l][r]表示剩下区间[l,r]时的最大价值 可以由f[1~l-1][r]和f[l][r+1~n]转移过来 详见代码: #include<algorithm ...
- JavaScript闭包简单学习
因为实验室项目要用,所以最近在学习OpenLayers,但是从来没有做过前端呀,坑爹的,硬着头皮上吧 反正正好借这个机会学习一下JS,本来对这门语言也挺感兴趣的,多多少少写过一下JS代码了,差不多学一 ...
- oracle 基础知识(四)常用函数
SQL中的单记录函数 .ASCII 返回与指定的字符对应的十进制数; SQL') zero,ascii(' ') space from dual; A A ZERO SPACE --------- - ...
- 【题解】UVA756 Biorhythms (中国剩余定理)
UVA756:https://www.luogu.org/problemnew/show/UVA756 思路 几乎是裸的中国剩余定理模板题 但是需要注意的是此题并不是求最小正整数解 而是求大于d的解 ...
- ISIS Scanner Errors codes
This section lists errors sorted by number: Error # Defined Constant String Defined In PIXDFLT 0 PIX ...
- apache开启.htaccess及使用方法
1 . 如何让的本地APACHE器.htaccess 如何让的本地APACHE呢?其实只要简朴修改一下apache的httpd.conf设置就让APACHE.htaccess开启了,来看看操作 打开h ...
- select 文字右对齐
select { direction: rtl; } select option { direction: ltr; }
- Django-rest-framework(七)swagger使用
在我们接口开发完之后,需要交付给别人对接,在没有使用swagger的时候,我们需要单独编写一份api接口文档,由postman之类的工具进行请求得到返回的结果.而有了swagger之后,可以通过提取接 ...
- c# Hash一致算法负载均衡(KetamaHash)项目升级
其实就是我最近写的一个项目,采用Hash一致满足负载均衡.Hash一致环带虚拟节点. 在前面的博文中说明了我采用的方法,MurmurHash+红黑树(底层其实是sortedlist).经过多次测试结合 ...
- web常用软件
编辑器: VSCode HBuilder WebStorm NotePad++ Eclipse Atom 常用插件: SwitchyOmega Vue-Tools server类: tomcat Ng ...