python之路 - 爬虫
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
Scrapy
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中。
其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
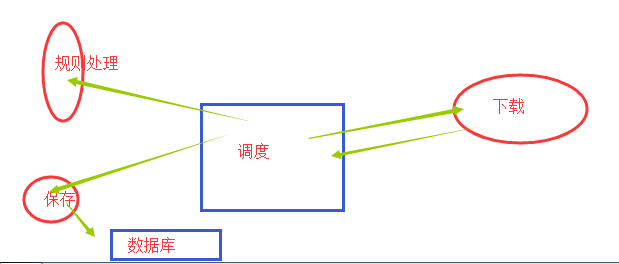
Scrapy 使用了 Twisted异步网络库来处理网络通讯。整体架构大致如下

Scrapy主要包括了以下组件:
引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心)
调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。
调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy运行流程大概如下:
- 引擎从调度器中取出一个链接(URL)用于接下来的抓取
- 引擎把URL封装成一个请求(Request)传给下载器
- 下载器把资源下载下来,并封装成应答包(Response)
- 爬虫解析Response
- 解析出实体(Item),则交给实体管道进行进一步的处理
- 解析出的是链接(URL),则把URL交给调度器等待抓取
一、安装
1 pip install Scrapy
自动创建目录:
project_name/
scrapy.cfg
project_name/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
文件说明:
- scrapy.cfg 项目的配置信息,主要为Scrapy命令行工具提供一个基础的配置信息。(真正爬虫相关的配置信息在settings.py文件中)
- items.py 设置数据存储模板,用于结构化数据,如:Django的Model
- pipelines 数据处理行为,如:一般结构化的数据持久化
- settings.py 配置文件,如:递归的层数、并发数,延迟下载等
- spiders 爬虫目录,如:创建文件,编写爬虫规则
注意:一般创建爬虫文件时,以网站域名命名
2、编写爬虫
在spiders目录中新建 xiaohuar_spider.py 文件
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import scrapy class XiaoHuarSpider(scrapy.spiders.Spider):
name = "nnnnn" # 命名 # allowed_domains = ["xiaohuar.com"] start_urls = [ # 起始url 内部是for循环
"http://www.xiaohuar.com/hua/",
]
#response 里面封装着所有返回的数据
def parse(self, response): # 回调函数
# print(response, type(response))
# from scrapy.http.response.html import HtmlResponse
# print(response.body_as_unicode()) current_url = response.url # 当前请求的url
body = response.body # 当前返回的内容
unicode_body = response.body_as_unicode() # 编码
print body
3、运行
进入project_name目录,运行命令
scrapy crawl spider_name --nolog
4、递归的访问
以上的爬虫仅仅是爬去初始页,而我们爬虫是需要源源不断的执行下去,直到所有的网页被执行完毕
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import scrapy
from scrapy.http import Request
from scrapy.selector import HtmlXPathSelector
import re
import urllib
import os class XiaoHuarSpider(scrapy.spiders.Spider):
name = "xiaohuar"
allowed_domains = ["xiaohuar.com"]
start_urls = [
"http://www.xiaohuar.com/list-1-1.html",
] def parse(self, response):
# 分析页面
# 找到页面中符合规则的内容(校花图片),保存
# 找到所有的a标签,再访问其他a标签,一层一层的搞下去 hxs = HtmlXPathSelector(response) # 如果url是 http://www.xiaohuar.com/list-1-\d+.html
if re.match('http://www.xiaohuar.com/list-1-\d+.html', response.url):
items = hxs.select('//div[@class="item_list infinite_scroll"]/div')
for i in range(len(items)):
src = hxs.select('//div[@class="item_list infinite_scroll"]/div[%d]//div[@class="img"]/a/img/@src' % i).extract()
name = hxs.select('//div[@class="item_list infinite_scroll"]/div[%d]//div[@class="img"]/span/text()' % i).extract()
school = hxs.select('//div[@class="item_list infinite_scroll"]/div[%d]//div[@class="img"]/div[@class="btns"]/a/text()' % i).extract()
if src:
ab_src = "http://www.xiaohuar.com" + src[0]
file_name = "%s_%s.jpg" % (school[0].encode('utf-8'), name[0].encode('utf-8'))
file_path = os.path.join("/Users/wupeiqi/PycharmProjects/beauty/pic", file_name)
urllib.urlretrieve(ab_src, file_path) # 获取所有的url,继续访问,并在其中寻找相同的url
all_urls = hxs.select('//a/@href').extract()
for url in all_urls:
if url.startswith('http://www.xiaohuar.com/list-1-'):
yield Request(url, callback=self.parse)
以上代码将符合规则的页面中的图片保存在指定目录,并且在HTML源码中找到所有的其他 a 标签的href属性,从而“递归”的执行下去,直到所有的页面都被访问过为止。以上代码之所以可以进行“递归”的访问相关URL,关键在于parse方法使用了 yield Request对象。
注:可以修改settings.py 中的配置文件,以此来指定“递归”的层数,如: DEPTH_LIMIT = 1 深度
两种定义查找的方式:
1, 即将过期的
from scrapy.selector import HtmlXPathSelector
hxs = HtmlXPathSelector(response) # 即将过期了
items = hxs.select('//div[@class="item_list infinite_scroll"]/div')
2,建议使用
from scrapy.selector import Selector # 推荐使用这一种
ret = Selector(response=response).xpath('//div[@class="item_listinfinite_scroll"]/div')
3, 选择器规则
selector:
// 子子孙孙
/ 孩子
//div[@class='c1'][@id='i1'] 属性选择器
//div//img/@src 获取src属性
//div//a[1] 索引 第一个
//div//a[1]//text() 内容
----- obj.extract() 真实的内容
===== 正则表达式
//.select('div//a[1]').re('昵称:(\w+)')
<li class="item-"><a href="link.html">first item</a></li>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
'//li[re:test(@class, "item-\d*")]//@href'
问题实例:
重复url 不访问
url加密 -》 集合set
nid 加密值(索引) 原来的的值
new_url ==> 加密 如何递归
DEPTH_LIMIT = 1 深度 from scrapy.selector import Selector url_list = Selector(response=response).xpath('//a/#href') for url in url_list: # DEPTH_LIMIT = 1 深度 yield scrapy.Request(url=url,callback=self.parse)
内容格式化
spider url规则 把自己的保存功能拆分到 pipelines 通过契约 items
1,yiled request() 交给下载器
#!/usr/bin/python
# -*- coding: UTF-8 -*- #!/usr/bin/env python
# -*- coding:utf-8 -*-
import scrapy
import urllib
import os
class XiaoHuarSpider(scrapy.spiders.Spider):
name = "s2" # 命名
# allowed_domains = ["xiaohuar.com"]
start_urls = [ # 起始url 内部是for循环
"http://www.xiaohuar.com/hua/",
]
def parse(self, response): # 回调函数
current_url = response.url # 当前请求的url
body = response.body # 当前返回的内容
unicode_body = response.body_as_unicode() # 编码
# 去body中获取所有url
from scrapy.selector import Selector
url_list = Selector(response=response).xpath('//a/#href')
for url in url_list: # DEPTH_LIMIT = 1 深度
yield scrapy.Request(url=url,callback=self.parse)
2, yiled item() 交给 pipeline
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import scrapy
import urllib
import os
class XiaoHuarSpider(scrapy.spiders.Spider):
name = "s2" # 命名
# allowed_domains = ["xiaohuar.com"]
start_urls = [ # 起始url 内部是for循环
"http://www.xiaohuar.com/hua/",
]
#response 里面封装着所有返回的数据
def parse(self, response): # 回调函数
# print(response, type(response))
# from scrapy.http.response.html import HtmlResponse
# print(response.body_as_unicode())
current_url = response.url # 当前请求的url
from scrapy.selector import HtmlXPathSelector
hxs = HtmlXPathSelector(response) # 即将过期了
items = hxs.select('//div[@class="item_list infinite_scroll"]/div')
for i in range(len(items)): # extract() 拿里面真实的东西
srcs = hxs.select('//div[@class="item_list infinite_scroll"]/div[%d]//div[@class="img"]/a/img/@src' % i).extract()
names = hxs.select('//div[@class="item_list infinite_scroll"]/div[%d]//div[@class="img"]/span/text()' % i).extract()
schools = hxs.select('//div[@class="item_list infinite_scroll"]/div[%d]//div[@class="img"]/div[@class="btns"]/a/text()' % i).extract()
print names,srcs,schools
if srcs and names and schools:
print names[0],schools[0],srcs[0]
try:
from spider1 import items
obj = items.Spider1Item()
obj['name'] = names[0]
obj['src'] = srcs[0]
obj['school'] = schools[0]
yield obj
except Exception as e:
print e
# ret = [/uhdsjdnsd]
# print ret uicod的表示
# print ret[0] 字符串
items 契约
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html import scrapy
class Spider1Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field()
src = scrapy.Field()
school = scrapy.Field()
pipeline 保存
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html class Spider1Pipeline(object):
def process_item(self, item, spider):
ab_src = "http://www.xiaohuar.com" + item['src'] # 前缀
file_name = item['name'].encode('utf-8') + '.jpg'
import os
import urllib
file_path = os.path.join('D:\\',file_name)
# file_name = "%s_%s.jpg" % (schools[0].encode('utf-8'), names[0].encode('utf-8'))
# file_path = os.path.join("/Users/wupeiqi/PycharmProjects/beauty/pic", file_name)
urllib.urlretrieve(ab_src, file_path) # 保存 地址和 路劲
return item
生命流程图
python之路 - 爬虫的更多相关文章
- python之路——爬虫实例
urlController.py import bsController from urllib import request class SpiderMain(object): def __init ...
- Python之路【第十九篇】:爬虫
Python之路[第十九篇]:爬虫 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本.另外一些不常使用 ...
- python之路 目录
目录 python python_基础总结1 python由来 字符编码 注释 pyc文件 python变量 导入模块 获取用户输入 流程控制if while python 基础2 编码转换 pych ...
- Python 之路
Python之路[第一篇]:Python简介和入门 Python之路[第二篇]:Python基础(一) Python之路[第三篇]:Python基础(二) Python之路[第四篇]:模块 Pytho ...
- Python之路【第一篇】python基础
一.python开发 1.开发: 1)高级语言:python .Java .PHP. C# Go ruby c++ ===>字节码 2)低级语言:c .汇编 2.语言之间的对比: 1)py ...
- Python之路
Python学习之路 第一天 Python之路,Day1 - Python基础1介绍.基本语法.流程控制 第一天作业第二天 Python之路,Day2 - Pytho ...
- Python 开发轻量级爬虫08
Python 开发轻量级爬虫 (imooc总结08--爬虫实例--分析目标) 怎么开发一个爬虫?开发一个爬虫包含哪些步骤呢? 1.确定要抓取得目标,即抓取哪些网站的哪些网页的哪部分数据. 本实例确定抓 ...
- Python 开发轻量级爬虫07
Python 开发轻量级爬虫 (imooc总结07--网页解析器BeautifulSoup) BeautifulSoup下载和安装 使用pip install 安装:在命令行cmd之后输入,pip i ...
- Python 开发轻量级爬虫06
Python 开发轻量级爬虫 (imooc总结06--网页解析器) 介绍网页解析器 将互联网的网页获取到本地以后,我们需要对它们进行解析才能够提取出我们需要的内容. 也就是说网页解析器是从网页中提取有 ...
随机推荐
- Python~字典
if not isinstance(x, (int, float)): raise TypeError('bad operand type') range() raw_input(‘birth’) ...
- flask_sqlalchemy 乱码问题
简言之, /etc/my.conf default_character_set=utf8 配置成了 default_character_set=utf-8 继而 sqlalchemy 创建表使用的字符 ...
- php给客户端返回数据注意。
亲身测试: 返回的时候不要直接返回字符串,要用数组的方式返回数据客户端才能接收. 看代码. <?php require_once("../base.php"); functi ...
- 修改linux的系统时间和时区
时间: date命令将日期设置为2016年12月16日 ---- date -s 12/16/16 将时间设置为9点28分50秒 ---- date -s 09:28:50 时区: tzsel ...
- Redis的Python实践,以及四中常用应用场景详解——学习董伟明老师的《Python Web开发实践》
首先,简单介绍:Redis是一个基于内存的键值对存储系统,常用作数据库.缓存和消息代理. 支持:字符串,字典,列表,集合,有序集合,位图(bitmaps),地理位置,HyperLogLog等多种数据结 ...
- 编译安装 varnish-4.1.2和yum 安装 varnish-4.0.3
vanish可以让用户自己选择缓存数据是存于内存还是硬盘,存于内存一般基于二八法则即常访问的数据是磁盘存储的总数据五分之一,因此内存也应该是硬盘文件大概五分之一.如果有多台vanish则,总内存满足即 ...
- Js 日期 多少分钟前,多少秒前
;(function(window){ /** * [dateDiff 算时间差] * @param {[type=Number]} hisTime [历史时间戳,必传] * @param {[typ ...
- IO边读边写
using (FileStream fs = new FileStream(@"C:\Users\Desktop\lijia1.txt",FileMode.Open)) ...
- python import cv2 出错:cv2.x86_64-linux-gnu.so: undefined symbol
之前写过一个python使用opencv处理图片的脚本,当时是可以使用的,现在突然发现执行时出错: ImportError: /usr/lib/python2.7/dist-packages/cv2. ...
- 【Java EE 学习 54】【OA项目第一天】【SSH事务管理不能回滚问题解决】【struts2流程回顾】
一.SSH整合之后事务问题和总结 1.引入问题:DAO层测试 假设将User对象设置为懒加载模式,在dao层使用load方法. 注意,注释不要放开. 使用如下的代码块进行测试: 会报错:no sess ...