logstash搭建日志追踪系统
前言
开始博客之前,首先说下10月份没写博客的原因 = =。 10月份赶上国庆,回了趟老家休息了下,回来后自己工作内容发生了点改变,开始搞一些小架构的东西以及研究一些新鲜东西,当时我听到这个消息真的是开心得不得了, 0 0。 然后就是把搜索模块交给我搞了,哇咔咔,以前学过lucene和solr,所以不陌生,花了1个多星期将搜索模块的原型搭出来了,果然不负leader对我的信任,之后就是搞日志分析,日志追踪, 然后就有了现在这篇文字,那么就进入主题吧。
作为一只程序猿,写的代码的过程需要加入一些日志信息,这些日志信息包括debug调试信息,异常记录日志等。 Java猿一般都是使用log4j,logback等第三方库记录日志。 那么问题来了,挖掘机到底哪家强?...... 扯个淡,那么问题来了,如果我们想看日志信息,怎么办, ssh到服务器上,vim然后查询。每次都这样,是不是很蛋疼 = =; 还有另外一个问题,如果我们想分析、追踪日志,或者找关键字(分词后的关键字),这样简简单单看日志文件是不可能的。 因此,我们就需要开源力量了!
logstash介绍##
摘自官网上的一句话:logstash is a tool for managing events and logs. You can use it to collect logs, parse them, and store them for later use (like, for searching)。logstash是一个用来管理事件和日志的工具,它的作用是收集日志,解析日志,存储日志为以后使用。
官网上有tutorials。 本文也就是对tutorials做一个总结。
logstash日志追踪系统搭建过程
要搭建logstash日志追踪系统需要以下几个环境:
- JDK
- logstash
- elasticsearch
没有JDK的小伙伴首先先去下载吧。 logstash和elasticsearch都先下载过来吧~。
logstash环境搭建
首先先进入logstash的bin目录建立一个logstash.conf配置文件:
input { stdin { } }
output {
stdout { codec => rubydebug }
}
然后执行:
./logstash -f logstash.conf
这时控制台等待输入内容,我们输入hello world,这个时候控制台会打印出:
{
"message" => "hello world",
"@version" => "1",
"@timestamp" => "2014-11-01T12:38:17.217Z",
"host" => "format-2.local"
}
这个说明我们的logstash本地配置成功了。
配置文件有2个内容组成,input和output,其实还有2个配置:filter和codec。
这就是logstash内部的一个叫做事件处理管道(pipeline)的核心概念的3大组成部分:
input:
生成事件(logstash中的事件是由队列实现的,这个队列由ruby的SizedQueue实现)的数据来源,常见的有file(文件)、syslog(系统日志)、redis(缓存系统)、lumberjack(lumberjack协议)。
filter:
修改事件内容,常见的filter有grok(常用,解析文本并结构化地存储下来,用来处理没有结构的文本)、mutate、drop、clone、geoip
output:
展现结果,常见的有elasticsearch(搜索引擎)、file、graphite、statsd
codec:
可以作为input或output的一部分,主要用来处理日志过程中产生的消息,常见的codec有json、rubydebug
现在我们回过头看来我们的logstash.conf配置文件,只配置了input和output,其中input由一个stdin组成,这个stdin没有任何参数,output由stdout组成,这个stdout由codec参数,且使用了rebydebug,因此控制台打印出的信息是reby的对象格式。 我们把codec改成json的话,将会打印出以下内容:
{"message":"hello world","@version":"1","@timestamp":"2014-11-01T13:16:38.221Z","host":"format-2.local"}
elasticsearch环境搭建
elasticsearch的环境搭建比较简单,download elasticsearch之后进入bin目录,执行:
./elasticsearch
之后打开浏览器进入http://localhost:9200/,发现有一串json文本就表示elasticsearch服务器已启。 但是貌似没有发现什么界面,是不是很不友好= =。
elasticsearch支持插件功能,我们使用kibana插件,下载之后修改config.js文件,把elasticsearch对应的地址改成elasticsearch服务器地址,然后把kibana解压出来的所有文件放到$elasticsearch_home/plugins_/kibana/_site/目录中。
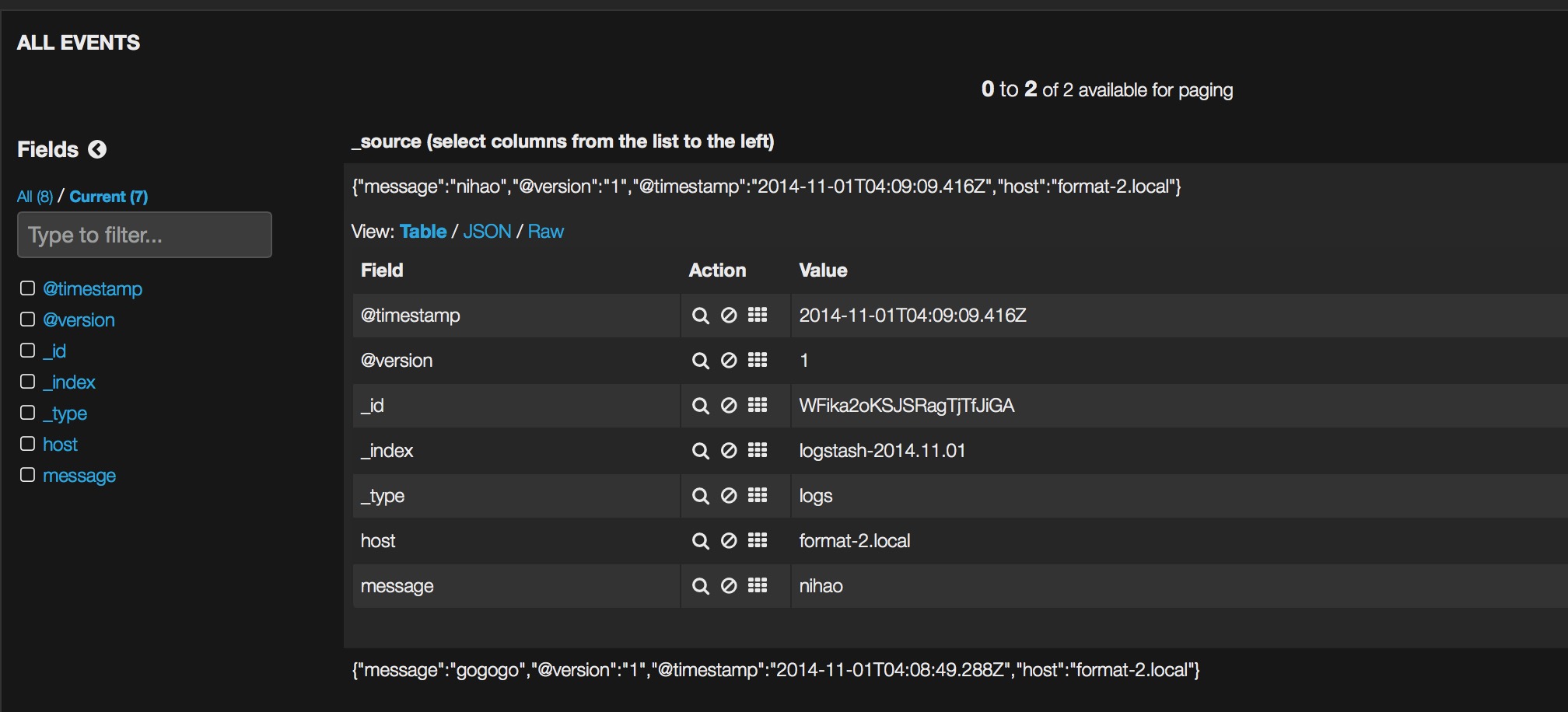
之后打开http://localhost:9200/_plugin/kibana
logstash整合elasticsearch
配置完logstash和elasticsearch之后,整合一下这两个框架。
logstash配置文件(input、output可以配置多个):
input { stdin { } }
output {
stdout { codec => json }
elasticsearch { host => localhost }
}
然后重新启动logstash,控制台输入hello elasticsearch,刷新kibana页面:
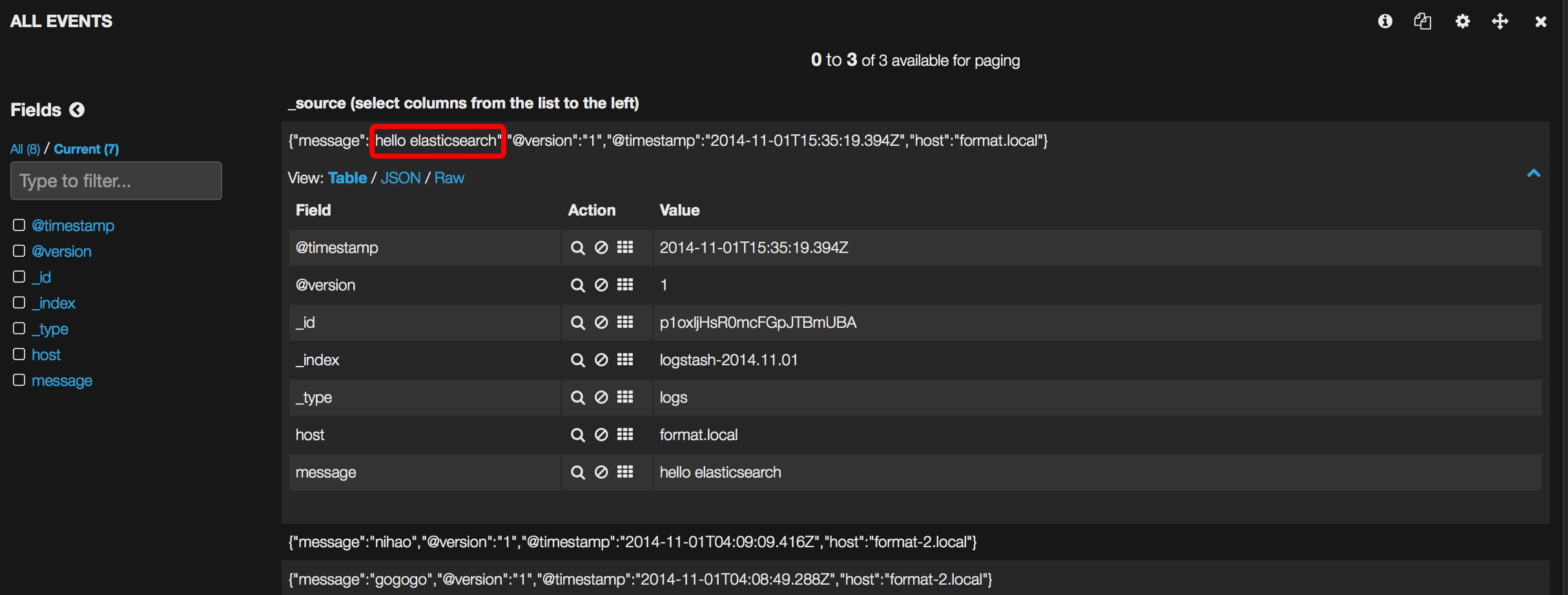
logstash日志追踪系统搭建完毕。
logstash的实际应用
以log4j为例。
logstash配置:
input {
stdin { }
log4j {
mode => "server"
host => "127.0.0.1"
port => 56789
type => "log4j"
}
}
output {
stdout { codec => rubydebug }
elasticsearch { host => localhost }
}
测试类:
public class LogTest {
private Logger logger = Logger.getLogger(DebugLogger.class);
@Before
public void setUp() {
PropertyConfigurator.configure(LogTest.class.getClassLoader().getResourceAsStream("log4j.properties"));
}
@Test
public void testLog() {
logger.debug("hello logstash, this is a message from log4j");
}
@Test
public void testException() {
logger.error("error", new TestException("sorry, error"));
}
}
log4j配置:
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p %t %c : %m%n
log4j.appender.file=org.apache.log4j.RollingFileAppender
log4j.appender.file.file=/Users/fangjian/Develop/log_file/test_log.log
log4j.appender.file.maxFileSize=1024
log4j.appender.file.layout=org.apache.log4j.PatternLayout
log4j.appender.file.layout.ConversionPattern=%d %p %t %c : %m%n
# logstash配置
log4j.appender.logstash=org.apache.log4j.net.SocketAppender
log4j.appender.logstash.port=56789
log4j.appender.logstash.remoteHost=127.0.0.1
log4j.rootLogger=debug,stdout,file,logstash
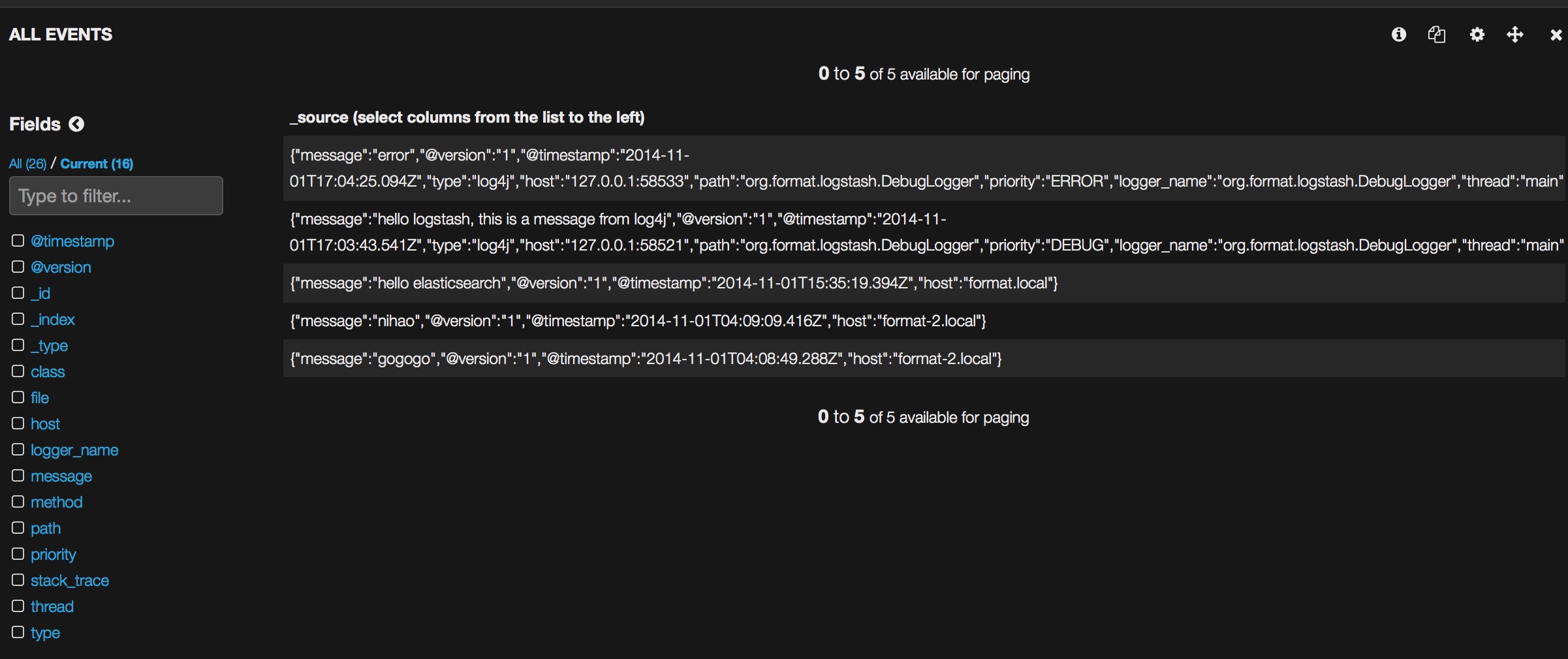
2个test方法跑完之后,刷新kibana界面:
总结
本文仅仅只是对logstash的搭建做一个总结,包括logstash内部的结构,还有一些配置语言的介绍都没有非常详细的解释,如果读者有兴趣,可以自行查阅相关资料。
参考资料:
http://logstash.net/
http://blog.yeradis.com/2013/10/logstash-and-apache-log4j-or-how-to.html
http://www.cnblogs.com/buzzlight/p/logstash_elasticsearch_kibana_log.html
logstash搭建日志追踪系统的更多相关文章
- filebeat+redis+logstash+elasticsearch+kibana搭建日志分析系统
filebeat+redis+elk搭建日志分析系统 官网下载地址:https://www.elastic.co/downloads 1.下载安装filebeat wget https://artif ...
- Docker搭建ElasticSearch+Redis+Logstash+Filebeat日志分析系统
一.系统的基本架构 在以前的博客中有介绍过在物理机上搭建ELK日志分析系统,有兴趣的朋友可以看一看-------------->>链接戳我<<.这篇博客将介绍如何使用Docke ...
- ELK(elasticsearch+logstash+kibana)入门到熟练-从0开始搭建日志分析系统教程
#此文篇幅较长,涵盖了elk从搭建到运行的知识,看此文档,你需要会点linux,还要看得懂点正则表达式,还有一个聪明的大脑,如果你没有漏掉步骤的话,还搭建不起来elk,你来打我. ELK使用elast ...
- 搭建日志收集系统时使用客户端连接etcd遇到的问题
问题: 在做日志收集系统时使用到etcd,其中server端在linux上,首先安装第三方包(windows)(安装过程可能会有问题,我遇到的是连接谷歌官网请求超时,如果已经出现下面的两个文件夹并且文 ...
- 本地搭建ELK(elasticsearch, logstash, kibana)日志收集系统
环境准备:macos 预先安装brew包管理器 1.安装elasticsearch流程 那么,咱们先去安装java8 接着,咱们继续按照elasticsearch 接着,咱们启动elasticsear ...
- Kibana+Logstash+Elasticsearch 日志查询系统
搭建该平台的目的就是为了运维.研发很方便的进行日志的查询.Kibana一个免费的web壳:Logstash集成各种收集日志插件,还是一个比较优秀的正则切割日志工具:Elasticsearch一个开源的 ...
- Kafka+Zookeeper+Filebeat+ELK 搭建日志收集系统
ELK ELK目前主流的一种日志系统,过多的就不多介绍了 Filebeat收集日志,将收集的日志输出到kafka,避免网络问题丢失信息 kafka接收到日志消息后直接消费到Logstash Logst ...
- docker搭建日志收集系统EFK
EFK Elasticsearch是一个数据搜索引擎和分布式NoSQL数据库的组合,提过日志的存储和搜索功能. Fluentd是一个消息采集,转化,转发工具,目的是提供中心化的日志服务. Kibana ...
- 日志收集系统搭建-BELK
前言 日志是我们分析系统运行情况.问题定位.优化分析等主要数据源头.目前,主流的业务系统都采用了分布式.微服务的形式.如果想要查看日志,就需要从不同的节点上去查看,而且对于整个业务链路也非常不清晰.因 ...
随机推荐
- SQL Server 2014新特性——事务持久性控制
控制事务持久性 SQL Server 2014之后事务分为2种:完全持久, 默认或延迟的持久. 完全持久,当事务被提交之后,会把事务日志写入到磁盘,完成后返回给客户端. 延迟持久,事务提交是异步的,在 ...
- Spring中@Autowired注解、@Resource注解的区别
Spring不但支持自己定义的@Autowired注解,还支持几个由JSR-250规范定义的注解,它们分别是@Resource.@PostConstruct以及@PreDestroy. @Resour ...
- .NET领域驱动设计—实践(穿过迷雾走向光明)
阅读目录 开篇介绍 1.1示例介绍 (OnlineExamination在线考试系统介绍) 1.2分析.建模 (对真实业务进行分析.模型化) 1.2.1 用例分析 (提取系统的所有功能需求) 1.3系 ...
- 深入理解JavaScript系列(1):编写高质量JavaScript代码的基本要点
深入理解JavaScript系列(1):编写高质量JavaScript代码的基本要点 2011-12-28 23:00 by 汤姆大叔, 139489 阅读, 119 评论, 收藏, 编辑 才华横溢的 ...
- Iterator(迭代器)的使用
迭代对于我们搞Java的来说绝对不陌生.我们常常使用JDK提供的迭代接口进行Java集合的迭代. Iterator iterator = list.iterator(); while(iterator ...
- js有关时间日期的操作
var myDate = new Date();var date_string = myDate.getFullYear()+""+((myDate.getMonth()+1)&l ...
- Android 的提权 (Root) 原理是什么?
作者:Kevin链接:https://www.zhihu.com/question/21074979/answer/18176410来源:知乎著作权归作者所有,转载请联系作者获得授权. Android ...
- stanford coursera 机器学习编程作业 exercise 3(使用神经网络 识别手写的阿拉伯数字(0-9))
本作业使用神经网络(neural networks)识别手写的阿拉伯数字(0-9) 关于使用逻辑回归实现多分类问题:识别手写的阿拉伯数字(0-9),请参考:http://www.cnblogs.com ...
- TopCoder SRM 639 Div.2 500 AliceGameEasy --乱搞
题意: 一个游戏有n轮,有A和B比赛,谁在第 i 轮得胜,就获得 i 分,给出x,y,问A得x分,B得y分有没有可能,如果有,输出A最少赢的盘数. 解法: 这题是我傻逼了,处理上各种不优越,要使n*( ...
- java分层开发
既然是分层开发,首先我们需要知道的是分为那几个层,并且是干什么的? 1.实体层(entity) 对应数据库中的一张表,有了它可以降低耦合性,同时也是数据的载体. 2.数据访问对象(data acces ...