Python基础之--常用模块
Python 模块
为了实现对程序特定功能的调用和存储,人们将代码封装起来,可以供其他程序调用,可以称之为模块.
如:os 是系统相关的模块;file是文件操作相关的模块;sys是访问python解释器的变量和函数的方法的模块等...
模块分为三种:
- 自定义模块
- 内置模块
- 第三方模块

Python应用越来越广泛,在一定程度上也依赖于其为程序员提供了大量的模块以供使用,如果想要使用模块,则需要导入。
python有三种导入模块的方法:
import modname //import 语句 from modname import funcname as rename //from ...import ..as 语句 from modname import fa, fb, fc 或者 from modname import * //from ...import *(不推荐使用这种方式)
import sys print sys.path // 获取模块搜索路径的字符串集合 结果: ['/Users/wupeiqi/PycharmProjects/calculator/p1/pp1', '/usr/local/lib/python2.7/site-packages/setuptools-15.2-py2.7.egg', '/usr/local/lib/python2/
如果sys.path路径列表没有你想要的路径,可以通过 sys.path.append('路径') 添加。
导入模块其实就是告诉Python解释器去解释那个py文件:
- 导入一个py文件,解释器解释该py文件
- 导入一个包,解释器解释该包下的 __init__.py 文件
下载安装第三方模块:
第一种方法:
yum install 软件名 -y 第二种方式:
下载源码
解压源码
进入目录
编译源码 python setup.py build
安装源码 python setup.py install 注:在使用源码安装时,需要使用到gcc编译和python开发环境,所以,需要先执行:yum install gcc python-devel 安装成功后,模块会自动安装到 sys.path 中的某个目录中,如:/usr/lib/python2.7/site-packages/

一、OS模块:
Python的标准库中的os模块主要涉及普遍的操作系统功能。可以在Linux和Windows下运行,与平台无关.
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.curdir 返回当前目录: ('.')
os.pardir 获取当前目录的父目录字符串名:('..')
os.makedirs('dirname1/dirname2') 可生成多层递归目录
os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() 删除一个文件
os.rename("oldname","newname") 重命名文件/目录
os.stat('path/filename') 获取文件/目录信息
os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"
os.pathsep 输出用于分割文件路径的字符串
os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
os.system("bash command") 运行shell命令,直接显示
os.environ 获取系统环境变量
os.path.abspath(path) 返回path规范化的绝对路径
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
30 os.putenv(key, value) 用来设置环境变量
31 os.path.splitext(): 分离文件名与扩展名
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))路径解析:
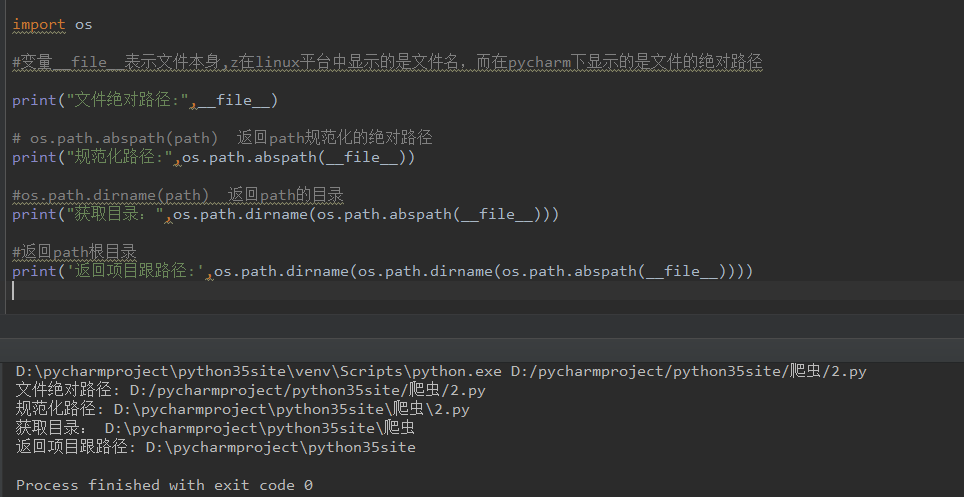
二、sys模块
用于提供对解释器相关的操作
sys.argv argv 列表包含了传递给脚本的所有参数, 列表的第一个元素为脚本自身的名称.
#argv.py
>>>Import sys
>>>Print sys.argv[number]
一般情况下,number为0是这个脚本的名字,1,2…则为命令行下传递的参数
sys.argv: //实现从程序外部向程序传递参数
sys.exit(): //程序中间的退出,exit(0):无错误退出
sys.path: //获取指定模块搜索路径的字符串集合.
sys.platform: //获取当前系统平台 出现如: "win32" "linux2" 等.
sys.getdefaultencoding(): //获取系统当前编码,一般默认为ascii.
sys.getfilesystemencoding(): //获取文件系统使用编码方式,Windows下返回'mbcs',mac下返回'utf-8'.
sys.setdefaultencoding(): //设置系统默认编码,执行dir(sys)时不会看到这个方法,在解释器中执行不通过,可以先执行reload(sys),在执
行 sys.setdefaultencoding('utf8'),此时将系统默认编码设置为utf8。(见设置系统默认编码 )
sys.stdin,sys.stdout,sys.stderr stdin , stdout , 以及stderr 变量包含与标准I/O 流对应的流对象. 如果需要更好地控制输出,而print 不能满足你的要求, 它们就是你所需 要的. 你也可以替换它们, 这时候你就可以重定向输出和输入到其它设备( device ), 或者以非标准的方式处理它们.
#!/usr/bin/env python
# coding:utf-8 import sys # li = sys.argv[0]
# print os.path.split(li)[1] 取出脚本的名称 def readfile(filename):
print "Print file information...."
f = open(filename)
while True:
line = f.readline()
if len(line) == 0:
break
else:
print line
f.close()
print "sys.argv[0]-------",sys.argv[0]
print "sys.argc[1]-------",sys.argv[1] if len(sys.argv) < 2:
print "No action specitfied."
sys.exit()
if sys.argv[1].startswith('--'):
option = sys.argv[1][2:]
if option == 'verson':
print "Verson1.2"
elif option == 'help':
print """
This program prints files to the standard output.
Any number of files can be specified.
Options include:
--version : Prints the version number
--help : Display this help''' """
else:
print "Unkown option"
sys.exit()
else:
for filename in sys.argv[1:]:
readfile(filename)
sys.argv用法实例
三、time模块:
时间相关的操作,时间有三种表示方式:
- 时间戳 1970年1月1日之后的秒,即:time.time()
- 格式化的字符串 2014-11-11 11:11, 即:time.strftime('%Y-%m-%d')
- 结构化时间 元组包含了:年、日、星期等... time.struct_time 即:time.localtime()
time.time()
time.mktime(time.localtime()) time.gmtime() #可加时间戳参数
time.localtime() #可加时间戳参数
time.strptime('2014-11-11', '%Y-%m-%d') time.strftime('%Y-%m-%d') #默认当前时间
time.strftime('%Y-%m-%d',time.localtime()) #默认当前时间
time.asctime()
time.asctime(time.localtime())
time.ctime(time.time()) import datetime
datetime.date: 表示日期的类。常用的属性有year, month, day
datetime.time: 表示时间的类。常用的属性有hour, minute, second, microsecond
datetime.datetime:表示日期时间
datetime.timedelta:表示时间间隔,即两个时间点之间的长度
timedelta([days[, seconds[, microseconds[, milliseconds[, minutes[, hours[, weeks]]]]]]])
strftime("%Y-%m-%d") datetime.datetime.now()
datetime.datetime.now() - datetime.timedelta(days=5) //计算当前时间向后5天的时间。
总结下这些百分号控制符的用法,如下:
%Y 对应年份四位数表示 %y 对应年份两位数表示
%m 对应月份 %d 对应日期
%H 对应时间 24小时制 %I 对应时间12小时制
%M 对应分钟 %S 对应秒钟
%j 对应一年中的第几天 %w 对应星期 %W一年中的星期数
四、hashlib
Python的hashlib提供了常见的摘要算法,如MD5,SHA1等等。
摘要算法又称哈希算法、散列算法。它通过一个函数,把任意长度的数据转换为一个长度固定的数据串(通常用16进制的字符串表示)。
import md5
hash = md5.new()
hash.update('admin')
print hash.hexdigest()
md5-废弃
import sha hash = sha.new()
hash.update('admin')
print hash.hexdigest()
sha-废弃
import hashlib #从python直接导入hashlib模块 # ######## md5 ######## hashlib自带有md5的加密功能 hash = hashlib.md5() #调用hashlib里的md5()生成一个md5 hash对象
hash.update('admin') #用update方法对字符串进行md5加密的更新处理
print hash.hexdigest() #加密后的十六进制结果 # ######## sha1 ######## hash = hashlib.sha1() #调用hashlib里面的sha1()生成一个sha1的hash对象.
hash.update('admin')
print hash.hexdigest()
14 print hash.digest() #加密后的二进制结果
如果只需对一条字符串进行加密处理,也可以用一条语句的方式: print hashlib.new("md5", "admin").hexdigest()
以上加密算法虽然依然非常厉害,但时候存在缺陷,即:通过撞库可以反解。所以,有必要对加密算法中添加自定义key再来做加密。
import hashlib
# ######## md5 ########
hash = hashlib.md5('898oaFs09f') //在hashlib.md5中添加自定义的key
hash.update('admin')
print hash.hexdigest()
python 还有一个 hmac 模块,它内部对我们创建 key 和 内容 再进行处理然后再加密.
import hmac
h = hmac.new('fdkadka;dds')
h.update('admin')
print h.hexdigest() 4497e0b76cf7b126d92063df0959b072
五、ConfigParser
用于对特定的配置进行操作,当前模块的名称在 python 3.x 版本中变更为 configparser.
读取配置文件:
-read(filename) 直接读取ini文件内容
-sections() 得到所有的section,并以列表的形式返回
-options(section) 得到该section的所有option
-items(section) 得到该section的所有键值对
-get(section,option) 得到section中option的值,返回为string类型
-getint(section,option) 得到section中option的值,返回为int类型,还有相应的getboolean()和getfloat() 函数。
基本的写入配置文件:
-add_section(section) 添加一个新的section
-set( section, option, value) 对section中的option进行设置,需要调用write将内容写入配置文件。
配置文件test.cfg内容如下:
[sec_a]
a_key1 = 20
a_key2 = 10 [sec_b]
b_key1 = 121
b_key2 = b_value2
b_key3 = $r
b_key4 = 127.0.0.1
测试文件test.py:
#!/usr/bin/env python
# -* - coding: UTF-8 -* - import ConfigParser conf = ConfigParser.ConfigParser() #生成conf对象 conf.read("test.cfg") #用conf对象读取配置文件 #读配置文件 secs = conf.sections() #以列表形式返回所有的section print 'secs :', secs #secs : ['sec_b', 'sec_a'] options = conf.options("sec_a") #得到指定section的所有option print 'options:', options #options: ['a_key1', 'a_key2'] options = conf.items("sec_a") #得到指定section的所有键值对 print 'sec_a:', options #sec_a: [('a_key1', '20'), ('a_key2', '10')] str_val = conf.get("sec_a", "a_key1") #指定section,option读取值
int_val = conf.getint("sec_a", "a_key2") print "value for sec_a's a_key1:", str_val #value for sec_a's a_key1: 20
print "value for sec_a's a_key2:", int_val #value for sec_a's a_key2: 10 #写配置文件 conf.set("sec_b", "b_key3", "new-yl") #更新指定section,option的值 conf.set("sec_b", "b_newkey", "new-value") #写入指定section增加新option和值 conf.add_section('a_new_section') #增加新的section conf.set('a_new_section', 'new_key', 'new_value') #写入指定section增加新option和值 conf.write(open("test.cfg", "w")) #写回配置文件
subprocess 模块:
subprocess模块用来生成子进程,并可以通过管道连接它们的输入/输出/错误,以及获得它们的返回值.
它用来代替多个旧模块和函数:
os.system
os.spawn*
os.popen*
popen2.*
commands.*
subprocess.call() 执行程序,并等待它完成
def call(*popenargs, **kwargs):
return Popen(*popenargs, **kwargs).wait()
--------------------------------------------------------------- subprocess.call(["ls", "-l"])
subprocess.call(["ls", "-l"], shell=False)
shell=False:False时,如果args只是一个字符串,则被当作要执行的程序的路径名,其中不能有命令行参数;shell=True时,如果args是一个字符串,它作为shell的命令行进行执行。注意:这个区别只限于Unix系统,对于Windows系统,两者基本是相同的。
subprocess.check_call() 调用前面的call,如果返回值非零,则抛出异常.
def check_call(*popenargs, **kwargs):
retcode = call(*popenargs, **kwargs)
if retcode:
cmd = kwargs.get("args")
raise CalledProcessError(retcode, cmd)
return 0
subprocess.check_output() 执行程序,并返回其标准输出:
def check_output(*popenargs, **kwargs):
process = Popen(*popenargs, stdout=PIPE, **kwargs)
output, unused_err = process.communicate()
retcode = process.poll()
if retcode:
cmd = kwargs.get("args")
raise CalledProcessError(retcode, cmd, output=output)
return output
Popen对象
该对象提供有不少方法函数可用。而且前面已经用到了wait()/poll()/communicate()
| poll() | 检查是否结束,设置返回值 |
| wait() | 等待结束,设置返回值 |
| communicate() | 参数是标准输入,返回标准输出和标准出错 |
| send_signal() | 发送信号 (主要在unix下有用) |
| terminate() | 终止进程,unix对应的SIGTERM信号,windows下调用api函数TerminateProcess() |
| kill() | 杀死进程(unix对应SIGKILL信号),windows下同上 |
| stdin stdout stderr |
参数中指定PIPE时,有用 |
| pid | 进程id |
| returncode | 进程返回值 |
import subprocess
obj = subprocess.Popen("mkdir t3", shell=True, cwd='/home/dev',)
import subprocess obj = subprocess.Popen(["python"], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
obj.stdin.write('print 1 \n ')
obj.stdin.write('print 2 \n ')
obj.stdin.write('print 3 \n ')
obj.stdin.write('print 4 \n ') cmd_out = obj.stdout.read()
cmd_error = obj.stderr.read()
print cmd_out
print cmd_error
import subprocess obj = subprocess.Popen(["python"], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
out_error_list = obj.communicate('print "hello"')
print out_error_list
random模块
Python中的random模块用于生成随机数。下面介绍一下random模块中最常用的几个函数。
random.random() #random.random()用于生成一个0到1的随机符点数: 0 <= n < 1.0
例如:
>>> random.random()
0.085891554608514942 random.randint()
random.randint()的函数原型为:random.randint(a, b),用于生成一个指定范围内的整数。其中参数a是下限,参数b是上限,生成的随机数n: a <= n <= b >>> random.randint(1,100)
76 random.randrange
random.randrange的函数原型为:random.randrange([start], stop[, step]),从指定范围内,按指定基数递增的集合中 获取一个随机数。
如:random.randrange(10, 100, 2),结果相当于从[10, 12, 14, 16, ... 96, 98]序列中获取一个随机数 random.sample
random.sample的函数原型为:random.sample(sequence, k),从指定序列中随机获取指定长度的片断。sample函数不会修改原有序列。
list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
slice = random.sample(list, 5) #从list中随机获取5个元素,作为一个片断返回
print slice
print list #原有序列并没有改变.
随机字符:
>>> random.choice('qiwsir.github.io')
'g'
多个字符中选取特定数量的字符:
random.sample('qiwsir.github.io',3)
['w', 's', 'b']
随机选取字符串:
random.choice ( ['apple', 'pear', 'peach', 'orange', 'lemon'] )
洗牌:把原有的顺序打乱,按照随机顺序排列
>>> items = [1, 2, 3, 4, 5, 6]
>>> random.shuffle(items)
>>> items
[3, 2, 5, 6, 4, 1]
随机验证码实例:
import random
checkcode = '' #定义一个空字符串
for i in range(4): #在[0, 1, 2, 3]中进行循环
current = random.randrange(0,4)
if current != i:
temp = chr(random.randint(65,90))
else:
temp = random.randint(0,9)
checkcode += str(temp)
print checkcode
logging模块:
用于便捷记录日志且线程安全的模块
import logging
logging.basicConfig(filename='log.log', #通过logging.basicConfig函数对日志的输出格式及方式做相关配置
format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',
level=10)
logging.debug('debug')
logging.info('info')
logging.warning('warning')
logging.error('error')
logging.critical('critical')
logging.log(10,'log')
###############################################
日志等级:
日志级别大小关系为:CRITICAL > ERROR > WARNING > INFO > DEBUG > NOTSET,当然也可以自己定义日志级别。
1 CRITICAL = 50
2 FATAL = CRITICAL
ERROR = 40
WARNING = 30
5 WARN = WARNING
6 INFO = 20
7 DEBUG = 10
NOTSET = 0
将日志同时输出到文件和屏幕:
import logging
#创建一个logger
3 logger = logging.getLogger('logger') #name名称
4 logger.setLevel(logging.DEBUG) #全局日志级别
#创建一个handler,用于写入日志文件
6 fh = logging.FileHandler('test.log') #输出到日志文件test.log
7 fh.setLevel(logging.DEBUG) #debug级别以上的日志信息全部输出到文件test.log中
#再创建一个handler,用于输出到控制台
ch = logging.StreamHandler() #输出屏幕
ch.setLevel(logging.ERROR) #error级别以上的日志全部输出到屏幕
#定义handler的输出格式
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') ch.setFormatter(formatter)
fh.setFormatter(formatter)
#给logger添加handler
logger.addHandler(ch) #把屏幕和文件句柄交给logger接口执行
logger.addHandler(fh) # 'application' code
logger.debug('debug message')
logger.info('info message')
logger.warn('warn message')
logger.error('error message')
logger.critical('critical message')
Python 正则表达式之 re模块:
Python中有关正则表达式的知识和语法,不作过多解释,网上有许多学习的资料。这里主要介绍Python中常用的正则表达式处理函数。
re.match
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配不成功的话,match()就返回none。
re.match(pattern, string, flags=0)
import re
m = re.match(r'www','www.baidu.com') #只匹配首行开头的字符.
print m.group() #返回被www 匹配的字符串
re.search
re.search 扫描整个字符串并返回第一个成功的匹配,如果字符串没有匹配,则返回None。
import re
obj = re.search('\d+', 'u123uu888asf') #'d+'表示以数字进行分割.
if obj:
print obj.group()
re.match与re.search的区别:re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配。
re.sub
re.sub函数进行以正则表达式为基础的替换工作
import re
text = "123abc456def789"
#text = re.sub('\d+', 'QQ', text) #匹配任何十进制(\d+),并将其替换为QQ
text = re.sub('\d+', 'BB', text, 1) #匹配任何十进制数字,并将第一次出现的替换为QQ
print text
re.split
可以使用re.split根据指定匹配进行分割,示例如下.
content = "'1+2*(3+4)(7+8)*10/2+5'"
#li = re.split('\*', content) #以*号对content进行分割.
li = re.split('\*', content, 1)
print li
re.findall
上述re.match和re.search均用于匹配单值,即:只能匹配字符串中的一个,如果想要匹配到字符串中所有符合条件的元素,则需要使用 findall。
import re text = "fa123uu888asfabc456def789"
obj = re.findall('\d+', text)
print obj #####################################
['', '', '', '']
re.compile
可以把那些经常使用的正则表达式编译成正则表达式对象,再次使用时不用再编译,这样可以提高一定的效率.
import re
text = "JGood is a handsome boy, he is cool, clever, and so on..."
regex = re.compile(r'\w*oo\w*')
print regex.findall(text) #查找所有包含'oo'的单词
print regex.sub(lambda m: '[' + m.group(0) + ']', text) #将字符串中含有'oo'的单词用[]括起来.
##############################################################结果如下. ['JGood', 'cool']
[JGood] is a handsome boy, he is [cool], clever, and so on...
Python预定义字符集如下:
字符: . 匹配除换行符以外的任意字符
\w 匹配字母或数字或下划线或汉字
\s 匹配任意的空白符
\d 匹配数字
\b 匹配单词的开始或结束
^ 匹配字符串的开始
$ 匹配字符串的结束 次数: * 重复零次或更多次
+ 重复一次或更多次
? 重复零次或一次
{n} 重复n次
{n,} 重复n次或更多次
{n,m} 重复n到m次
Python基础之--常用模块的更多相关文章
- 十八. Python基础(18)常用模块
十八. Python基础(18)常用模块 1 ● 常用模块及其用途 collections模块: 一些扩展的数据类型→Counter, deque, defaultdict, namedtuple, ...
- python基础31[常用模块介绍]
python基础31[常用模块介绍] python除了关键字(keywords)和内置的类型和函数(builtins),更多的功能是通过libraries(即modules)来提供的. 常用的li ...
- Python全栈开发之路 【第六篇】:Python基础之常用模块
本节内容 模块分类: 好处: 标准库: help("modules") 查看所有python自带模块列表 第三方开源模块: 自定义模块: 模块调用: import module f ...
- python基础之常用模块以及格式化输出
模块简介 模块,用一砣代码实现了某个功能的代码集合. 类似于函数式编程和面向过程编程,函数式编程则完成一个功能,其他代码用来调用即可,提供了代码的重用性和代码间的耦合.而对于一个复杂的功能来,可能需要 ...
- Day5 - Python基础5 常用模块学习
Python 之路 Day5 - 常用模块学习 本节大纲: 模块介绍 time &datetime模块 random os sys shutil json & picle shel ...
- Python基础之常用模块
一.time模块 1.时间表达形式: 在Python中,通常有这三种方式来表示时间:时间戳.元组(struct_time).格式化的时间字符串: 1.1.时间戳(timestamp) :通常来说,时间 ...
- Python基础5 常用模块学习
本节大纲: 模块介绍 time &datetime模块 random os sys shutil json & picle shelve xml处理 yaml处理 configpars ...
- python基础(11)-常用模块
re(正则)模块 常用方法 findall() 以列表返回所有满足条件的结果 import re print(re.findall('\d','a1b2c2abc123'))#['1', '2', ' ...
- Python基础之常用模块(三)
1.configparser模块 该模块是用来对文件进行读写操作,适用于格式与Windows ini 文件类似的文件,可以包含一个或多个节(section),每个节可以有多个参数(键值对) 配置文件的 ...
随机推荐
- 01python算法--算法和数据结构是什么鬼?
我不想直接拷贝google 上面所有对算法的解释.所以我想怎么说就怎么说了,QAQ 1:什么是程序? 解决问题的范式 2:什么是问题? 程序输入与输出之间的联系 3:什么是算法: 算法就是解决问题的思 ...
- java -日期
package com.qinghuainvest.tsmarket.util; import java.text.ParseException; import java.text.SimpleDat ...
- navigate连接MySQL报错:navigate your password has expired to log in your must change it using a client that supports
如图: 终端进入mysql: 第一次show databases的的时候,密码过期了,然后重置密码为12345,再次就可以显示了 参考连接:http://www.jb51.net/article/79 ...
- bzoj4418&&bzoj4419&&bzoj4420:SHOI2013Day2题解
这三题截止现在(2016.3.11)窝居然都是跑的最快的……可啪…… T1 bzoj4418 这题叫做扇形面积并,看到这个名字我就方了,因为我不会计算几何啊QAQ 一看题目,发现是傻逼题……(雾) 又 ...
- 随机验证码生成(python实现)
需求:生成随机不重复验证码. 代码: #!/usr/bin/env python # encoding: utf-8 """ @author: 侠之大者kamil @fi ...
- linux软件包的安装和卸载
这里分两种情况讨论:二进制包和源代码包. 一.linux二进制分发软件包的安装和卸载 Linux软件的二进制分发是指事先已编译好二进制形式的软件包的发布形式,其长处是安装使用容易,缺点则是缺乏灵活性, ...
- 【poj1019】 Number Sequence
http://poj.org/problem?id=1019 (题目链接) 题意 给出一个数:1 12 123 1234 12345 123456 1234567 12345678 123456789 ...
- sql查找最后一个字符匹配
DECLARE @str AS VARCHAR(25)='123_234_567' select substring(@str,1,LEN(@str)-CHARINDEX('_',reverse(@s ...
- WAF(Web Appliction Firewall) Bypass Technology Research
catalog . What is Firewall . Detecting the WAF . Different Types of Encoding Bypass . Bypass本质 1. Wh ...
- DedeCMS Xss+Csrf Getshell \dede\file_manage_control.php
目录 . 漏洞描述 . 漏洞触发条件 . 漏洞影响范围 . 漏洞代码分析 . 防御方法 . 攻防思考 1. 漏洞描述 对这个漏洞的利用方式进行简单的概括 . 这个漏洞的利用前提是需要登录到后台进行操作 ...