HDFS原理介绍
HDFS(Hadoop Distributed File System )Hadoop分布式文件系统。是根据google发表的论文翻版的。论文为GFS(Google File System)Google 文件系统(中文,英文)。
1. 架构分析
基础名词解释:
- Block: 在HDFS中,每个文件都是采用的分块的方式存储,每个block放在不同的datanode上,每个block的标识是一个三元组(block id, numBytes,generationStamp),其中block id是具有唯一性,具体分配是由namenode节点设置,然后再由datanode上建立block文件,同时建立对应block meta文件
- Packet:在DFSclient与DataNode之间通信的过程中,发送和接受数据过程都是以一个packet为基础的方式进行
- Chunk:中文名字也可以称为块,但是为了与block区分,还是称之为chunk。在DFSClient与DataNode之间通信的过程中,由于文件采用的是基于块的方式来进行的,但是在发送数据的过程中是以packet的方式来进行的,每个packet包含了多个chunk,同时对于每个chunk进行checksum计算,生成checksum bytes
- 小结:
1. 一个文件被拆成多个block持续化存储(block size 由配置文件参数决定) 思考: 修改 block size 对以前持续化的数据有何影响?
2. 数据通讯过程中一个 block 被拆成 多个 packet
3. 一个 packet 包含多个 chunk
- Packet结构与定义: Packet分为两类,一类是实际数据包,另一类是heatbeat包。一个Packet数据包的组成结构,如图所示

上图中,一个Packet是由Header和Data两部分组成,其中Header部分包含了一个Packet的概要属性信息,如下表所示:

Data部分是一个Packet的实际数据部分,主要包括一个4字节校验和(Checksum)与一个Chunk部分,Chunk部分最大为512字节
在构建一个Packet的过程中,首先将字节流数据写入一个buffer缓冲区中,也就是从偏移量为25的位置(checksumStart)开始写Packet数据Chunk的Checksum部分,从偏移量为533的位置(dataStart)开始写Packet数据的Chunk Data部分,直到一个Packet创建完成为止。
当写一个文件的最后一个Block的最后一个Packet时,如果一个Packet的大小未能达到最大长度,也就是上图对应的缓冲区中,Checksum与Chunk Data之间还保留了一段未被写过的缓冲区位置,在发送这个Packet之前,会检查Chunksum与Chunk Data之间的缓冲区是否为空白缓冲区(gap),如果有则将Chunk Data部分向前移动,使得Chunk Data 1与Chunk Checksum N相邻,然后才会被发送到DataNode节点
hdfs架构
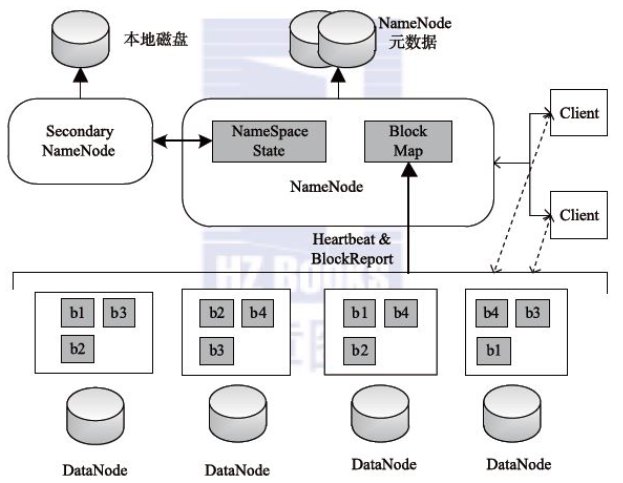
1、HDFS的组成:
- NameNode:Master节点(也称元数据节点),是系统唯一的管理者。负责元数据的管理(名称空间和数据块映射信息);配置副本策略;处理客户端请求
- DataNode:数据存储节点(也称Slave节点),存储实际的数据;执行数据块的读写;汇报存储信息给NameNode
- Sencondary NameNode:分担namenode的工作量;是NameNode的冷备份;合并fsimage和fsedits然后再发给namenode。注意:在hadoop 2.x 版本,当启用 hdfs ha 时,将没有这一角色
- client:系统使用者,调用HDFS API操作文件;与NameNode交互获取文件元数据;与DataNode交互进行数据读写。注意:写数据时文件切分由Client完成
热备份:b是a的热备份,如果a坏掉。那么b立即运行代替a的工作
冷备份:b是a的冷备份,如果a坏掉。那么b不能立即代替a工作。但是b上存储a的一些信息,减少a坏掉之后的损失
2、hdfs构架原则:
- 元数据与数据分离:文件本身的属性(即元数据)与文件所持有的数据分离
- 主/从架构:一个HDFS集群是由一个NameNode和一定数目的DataNode组成
- 一次写入多次读取:HDFS中的文件在任何时间只能有一个Writer。当文件被创建,接着写入数据,最后,一旦文件被关闭,就不能再修改
- 移动计算比移动数据更划算:数据运算,越靠近数据,执行运算的性能就越好,由于hdfs数据分布在不同机器上,要让网络的消耗最低,并提高系统的吞吐量,最佳方式是将运算的执行移到离它要处理的数据更近的地方,而不是移动数据
NameNode:
- NameNode是整个文件系统的管理节点,也是HDFS中最复杂的一个实体,它维护着HDFS文件系统中最重要的两个关系:
- HDFS文件系统中的文件目录树,以及文件的数据块索引,即每个文件对应的数据块列表
- 数据块和数据节点的对应关系,即某一块数据块保存在哪些数据节点的信息
- 第一个关系即目录树、元数据和数据块的索引信息会持久化到物理存储中,实现是保存在命名空间的镜像fsimage和编辑日志edits中,注意:在fsimage中,并没有记录每一个block对应到哪几个Datanodes的对应表信息
- 第二个关系是在NameNode启动后,每个Datanode对本地磁盘进行扫描,将本Datanode上保存的block信息汇报给Namenode,Namenode在接收到每个Datanode的块信息汇报后,将接收到的块信息,以及其所在的Datanode信息等保存在内存中。HDFS就是通过这种块信息汇报的方式来完成 block -> Datanodes list的对应表构建
- fsimage记录了自最后一次检查点之前HDFS文件系统中所有目录和文件的序列化信息;
- edits是元数据操作日志(记录每次保存fsimage之后到下次保存之间的所有hdfs操作)
- 在NameNode启动时候,会先将fsimage中的文件系统元数据信息加载到内存,然后根据eidts中的记录将内存中的元数据同步至最新状态,将这个新版本的 FsImage 从内存中保存到本地磁盘上,然后删除 旧的 Editlog,这个过程称为一个检查 点 (checkpoint)。
- 类似于数据库中的检查点,为了避免edits日志过大,在Hadoop1.X中,SecondaryNameNode会按照时间阈值(比如24小时)或者edits大小阈值(比如1G),周期性的将fsimage和edits的合并,然后将最新的fsimage推送给NameNode。而在Hadoop2.X中,这个动作是由Standby NameNode来完成.
- 由此可看出,这两个文件一旦损坏或丢失,将导致整个HDFS文件系统不可用。
- 在hadoop1.X为了保证这两种元数据文件的高可用性,一般的做法,将dfs.namenode.name.dir设置成以逗号分隔的多个目录,这样,多个目录至少不要在一块磁盘上,最好放在不同的机器上,比如:挂载一个共享文件系统
- fsimage\edits 是序列化后的文件,想要查看或编辑里面的内容,可通过 hdfs 提供的 oiv\oev 命令,如下:
- 命令: hdfs oiv (offline image viewer) 用于将fsimage文件的内容转储到指定文件中以便于阅读,,如文本文件、XML文件,该命令需要以下参数:
1. -i (必填参数) –inputFile <arg> 输入FSImage文件
2. -o (必填参数) –outputFile <arg> 输出转换后的文件,如果存在,则会覆盖
3. -p (可选参数) –processor <arg> 将FSImage文件转换成哪种格式: (Ls|XML|FileDistribution).默认为Ls
示例:hdfs oiv -i /data1/hadoop/dfs/name/current/fsimage_0000000000019372521 -o /home/hadoop/fsimage.txt
- 命令:hdfs oev (offline edits viewer 离线edits查看器)的缩写, 该工具只操作文件因而并不需要hadoop集群处于运行状态。
示例: hdfs oev -i edits_0000000000000042778-0000000000000042779 -o edits.xml
支持的输出格式有binary(hadoop使用的二进制格式)、xml(在不使用参数p时的默认输出格式)和stats(输出edits文件的统计信息)
- 小结:
- NameNode管理着DataNode,接收DataNode的注册、心跳、数据块提交等信息的上报,并且在心跳中发送数据块复制、删除、恢复等指令;同时,NameNode还为客户端对文件系统目录树的操作和对文件数据读写、对HDFS系统进行管理提供支持
- Namenode 启动后会进入一个称为安全模式的特殊状态。处于安全模式的 Namenode 是不会进行数据块的复制的。Namenode 从所有的 Datanode 接收心跳信号和块状态报告。块状态报告包括了某个 Datanode 所有的数据块列表。每个数据块都有一个指定的最小副本数。当Namenode检测确认某 个数据块的副本数目达到这个最小值,那么该数据块就会被认为是副本安全 (safely replicated) 的;在一定百分比(这个参数可配置)的数据块被 Namenode 检测确认是安全之后(加上一个额外的 30 秒等待时间), Namenode 将退出安全模式状态。接下来它会确定还有哪些数据块的副本没有达到指定数目,并将这些数据块复制到其他 Datanode 上。
Secondary NameNode:在HA cluster中又称为standby node

Secondary NameNode 定期合并 fsimage 和 edits 日志,将 edits 日志文件大小控制在一个限度下,其过程如下:
- namenode 响应 Secondary namenode 请求,将 edit log 推送给 Secondary namenode , 开始重新写一个新的 edit log
- Secondary namenode 收到来自 namenode 的 fsimage 文件和 edit log
- Secondary namenode 将 fsimage 加载到内存,应用 edit log , 并生成一 个新的 fsimage 文件
- Secondary namenode 将新的 fsimage 推送给 Namenode
- Namenode 用新的 fsimage 取代旧的 fsimage , 在 fstime 文件中记下检查点发生的时
工作原理
写操作:
有一个文件FileA,100M大小。Client将FileA写入到HDFS上。HDFS按默认配置(块大小为64M)。HDFS分布在三个机架上Rack1,Rack2,Rack3。

a. Client将FileA按64M分块。分成两块,block1和Block2;
b. Client向nameNode发送写数据请求,如图蓝色虚线①------>。
c. NameNode节点,记录block信息。并返回可用的DataNode,如粉色虚线②--------->。
Block1: host2,host1,host3
Block2: host7,host8,host4
原理:
NameNode具有RackAware机架感知功能(这个可以配置)。
若client为DataNode节点,那存储block时,规则为:副本1,同client的节点上;副本2,不同机架节点上;副本3,同第二个副本机架的另一个节点上;其他副本随机挑选。
若client不为DataNode节点,那存储block时,规则为:副本1,随机选择一个节点上;副本2,不同副本1,机架上;副本3,同副本2相同的另一个节点上;其他副本随机挑选。
client向DataNode发送block1;发送过程是以流式写入。流式写入过程:
将64M的block1按64k的package划分;
然后将第一个package发送给host2;
host2接收完后,将第一个package发送给host1,同时client向host2发送第二个package;
host1接收完第一个package后,发送给host3,同时接收host2发来的第二个package。
以此类推,如图红线实线所示,直到将block1发送完毕。
host2,host1,host3向NameNode,host2向Client发送通知,说“消息发送完了”。如图粉红颜色实线所示。
client收到host2发来的消息后,向namenode发送消息,说我写完了。这样就真完成了。如图黄色粗实线
发送完block1后,再向host7,host8,host4发送block2,如图蓝色实线所示。
发送完block2后,host7,host8,host4向NameNode,host7向Client发送通知,如图浅绿色实线所示。
client向NameNode发送消息,说我写完了,如图黄色粗实线。。。这样就完毕了。
分析,通过写过程,我们可以了解到:
①写1T文件,我们需要3T的存储(有3个副本),3T的网络流量贷款。
②在执行读或写的过程中,NameNode和DataNode通过HeartBeat进行保存通信,确定DataNode活着。如果发现DataNode死掉了,就将死掉的DataNode上的数据,放到其他节点去。读取时,要读其他节点去。
③挂掉一个节点,没关系,还有其他节点可以备份;甚至,挂掉某一个机架,也没关系;其他机架上,也有备份。
说明:
- 当客户端向 HDFS 文件写入数据的时候,一开始是写到本地临时文件中。假设该文件的副本系数设置为 3 ,当本地临时文件累积到一个数据块的大小时,客户端会从 Namenode 获取一个 Datanode 列表用于存放副本。然后客户端开始向第一个 Datanode 传输数据,第一个 Datanode 一小部分一小部分 (4 KB) 地接收数据,将每一部分写入本地仓库,并同时传输该部分到列表中 第二个 Datanode 节点。第二个 Datanode 也是这样,一小部分一小部分地接收数据,写入本地 仓库,并同时传给第三个 Datanode 。最后,第三个 Datanode 接收数据并存储在本地。因此, Datanode 能流水线式地从前一个节点接收数据,并在同时转发给下一个节点,数据以流水线的 方式从前一个 Datanode 复制到下一个
- 时序图如下:

读操作:

读操作流程为:
- 客户端通过调用FileSystem对象的open()方法来打开希望读取的文件,对于HDFS来说,这个对象是分布文件系统的一个实例;
- DistributedFileSystem通过使用RPC来调用NameNode以确定文件起始块的位置,同一Block按照重复数会返回多个位置,这些位置按照Hadoop集群拓扑结构排序,距离客户端近的排在前面
- 前两步会返回一个FSDataInputStream对象,该对象会被封装成DFSInputStream对象,DFSInputStream可以方便的管理datanode和namenode数据流,客户端对这个输入流调用read()方法
- 存储着文件起始块的DataNode地址的DFSInputStream随即连接距离最近的DataNode,通过对数据流反复调用read()方法,将数据从DataNode传输到客户端
- 到达块的末端时,DFSInputStream会关闭与该DataNode的连接,然后寻找下一个块的最佳DataNode,这些操作对客户端来说是透明的,客户端的角度看来只是读一个持续不断的流
- 一旦客户端完成读取,就对FSDataInputStream调用close()方法关闭文件读取
block持续化结构:
DataNode节点上一个Block持久化到磁盘上的物理存储结构,如下图所示:
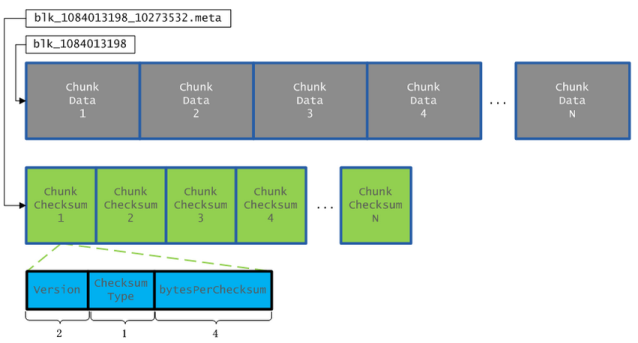
每个Block文件(如上图中blk_1084013198文件)都对应一个meta文件(如上图中blk_1084013198_10273532.meta文件),Block文件是一个一个Chunk的二进制数据(每个Chunk的大小是512字节),而meta文件是与每一个Chunk对应的Checksum数据,是序列化形式存储
参考:
HDFS原理介绍的更多相关文章
- Hadoop基础-Hdfs各个组件的运行原理介绍
Hadoop基础-Hdfs各个组件的运行原理介绍 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.NameNode工作原理(默认端口号:50070) 1>.什么是NameN ...
- Hadoop介绍-3.HDFS介绍和YARN原理介绍
一. HDFS介绍: Hadoop2介绍 HDFS概述 HDFS读写流程 1. Hadoop2介绍 Hadoop是Apache软件基金会旗下的一个分布式系统基础架构.Hadoop2的框架最核心的 ...
- HDFS 原理、架构与特性介绍--转载
原文地址:http://www.uml.org.cn/sjjm/201309044.asp 本文主要讲述 HDFS原理-架构.副本机制.HDFS负载均衡.机架感知.健壮性.文件删除恢复机制 1:当前H ...
- HDFS 原理、架构与特性介绍
本文主要讲述 HDFS原理-架构.副本机制.HDFS负载均衡.机架感知.健壮性.文件删除恢复机制 1:当前HDFS架构详尽分析 HDFS架构 •NameNode •DataNode •Senc ...
- 03 Yarn 原理介绍
Yarn 原理介绍 大纲: Hadoop 架构介绍 YARN 产生的背景 YARN 基础架构及原理 Hadoop的1.X架构的介绍 在1.x中的NameNodes只可能有一个,虽然可以通过Se ...
- 04 MapReduce原理介绍
大数据实战(上) # MapReduce原理介绍 大纲: * Mapreduce介绍 * MapReduce2运行原理 * shuffle及排序 定义 * Mapreduce 最早是由googl ...
- HDFS原理讲解
简介 本文是笔者在学习HDFS的时候的学习笔记整理, 将HDFS的核心功能的原理都整理在这里了. [广告] 如果你喜欢本博客,请点此查看本博客所有文章:http://www.cnblogs.com/x ...
- Hadoop之HDFS原理及文件上传下载源码分析(上)
HDFS原理 首先说明下,hadoop的各种搭建方式不再介绍,相信各位玩hadoop的同学随便都能搭出来. 楼主的环境: 操作系统:Ubuntu 15.10 hadoop版本:2.7.3 HA:否(随 ...
- Hadoop之HDFS原理及文件上传下载源码分析(下)
上篇Hadoop之HDFS原理及文件上传下载源码分析(上)楼主主要介绍了hdfs原理及FileSystem的初始化源码解析, Client如何与NameNode建立RPC通信.本篇将继续介绍hdfs文 ...
随机推荐
- ASP.NET WebForm中用async/await实现异步
1. 在.aspx中添加异步标记 <%@ Page Language="C#" Async="true"%> 2. 在.aspx.cs或者.ascx ...
- Python之路【第八篇】python实现线程池
线程池概念 什么是线程池?诸如web服务器.数据库服务器.文件服务器和邮件服务器等许多服务器应用都面向处理来自某些远程来源的大量短小的任务.构建服务器应用程序的一个过于简单的模型是:每当一个请求到达就 ...
- Python之路【第三篇补充】:Python基础(三)
参考老师:http://www.cnblogs.com/wupeiqi lambda表达式 学习条件运算时,对于简单的 if else 语句,可以使用三元运算来表示,即: # 普通条件语句 if 1 ...
- 在linux命令行中直接执行php命令
有时候用浏览器调试太麻烦,想在linux命令下直接执行php代码 php -r 'echo 0500;'
- [PHP知识点乱炖]四、全局变量——小偷从良记
本章要讲的是PHP的全局变量. 这里讲个小故事: 很多年前,一个很聪明的小偷,想去偷一户人家的钱.可是他偷不到主人的钥匙,怎么办呢? 他想到了一个办法,去之前嚼了一块口香糖,口香糖的牌子是“大大泡泡糖 ...
- [译]Mongoose指南 - Model
编译你的第一个model var xxSchema = new Schema({name: 'string', size: 'string'}); var Tank = mongoose.model( ...
- nyoj 14 会场安排问题(贪心专题)java
会场安排问题 时间限制:3000 ms | 内存限制:65535 KB 难度:4 描述 学校的小礼堂每天都会有许多活动,有时间这些活动的计划时间会发生冲突,需要选择出一些活动进行举办.小刘的工 ...
- java练手 韩信点兵
Problem C 韩信点兵 时间限制:3000 ms | 内存限制:65535 KB 描述 相传韩信才智过人,从不直接清点自己军队的人数,只要让士兵先后以三人一排.五人一排.七人一排地变换队 ...
- HDOJ 3652 B-number
B-number Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total Su ...
- css的计数器
更多关于计数器的问题可以参考:https://developer.mozilla.org/zh-CN/docs/Web/Guide/CSS/Getting_Started/Lists