深入剖析linq的联接
内联接
代码如下
from a in new List<string[]>{
new string[]{"张三","男"},
new string[]{"李四","女"},
new string[]{"王五","男"}
}
join b in new List<string[]>{
new string[]{"张三","英语",""},
new string[]{"张三","语文",""},
new string[]{"李四","数学",""}
}
on a[] equals b[]
select new {User=a,Score=b}
结果的结构如下
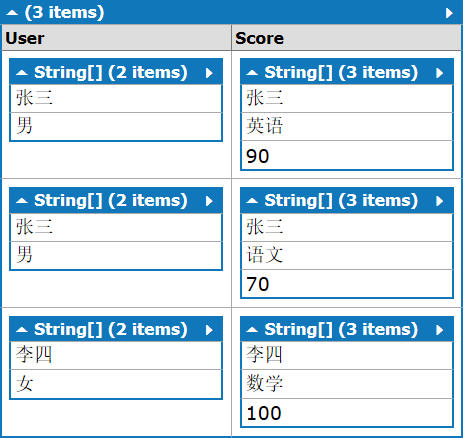
注意结果里没有a表的“王五”数据,在内联接查询里,内部联接会生成一个结果集,在该结果集中,第一个集合的每个元素对于第二个集合中的每个匹配元素都会出现一次。 如果第一个集合中的元素没有匹配元素,则它不会出现在结果集中。
总结:内联接用“join 数据源 on 条件"语法,会将左表(即写在前面的表)的每一条记录和右表(即写在后面的表)的每一条记录进行比较,如果左表有x条记录,右表有y条记录,比较会有x*y次比较,但最后的结果不会有x*y条,而是在x*y条里过滤出符合on条件的记录,有点类似“笛卡尔积+条件判断”的操作。
上面的内联接可完全改成两个from操作(进行笛卡尔积求值),结果的结构是完全一样的
from a in new List<string[]>{
new string[]{"张三","男"},
new string[]{"李四","女"},
new string[]{"王五","男"}
}
from b in new List<string[]>{
new string[]{"张三","英语",""},
new string[]{"张三","语文",""},
new string[]{"李四",""}
}
where a[]==b[]
select new {User=a,Score=b}
写到这,可能会问,那所有的内联接操作都改成几个from表就行,还用得着join on的内联接吗?答案是内联接比单纯对几个表进行笛卡尔积求值“效率高很多”,假设有a,b,c三个表,分别为x,y,z条记录,如果用笛卡尔积算法(linq代码如:from a in tab_a from b in tab_b from c in tab_c where ...... select ....),一共会进行x*y*z次连接操作,并对x*y*z条记录进行where过滤;但如果用内联接(linq代码如:from a in tab_a join b in tab_b on ... join c in tab_c on ... select ....),每一次的内联接会基于上一次的结果来进行下一次的操作,即a表和b表进行x*y次操作后,最后可能只得出w条记录(此时的w可能远小于x*y),然后再对c表进行w*z次操作,两者比较x*y*z可能远大于w*z。如果不是a,b,c三个表,而是更多的表进行联接,效率就差距很大了。
组联接
代码如下:
from a in new List<string[]>{
new string[]{"张三","男"},
new string[]{"李四","女"},
new string[]{"王五","男"}
}
join b in new List<string[]>{
new string[]{"张三","英语",""},
new string[]{"张三","语文",""},
new string[]{"李四","数学",""}
}
on a[] equals b[] into b_group
select new {User=a,Score=b_group}
结果的结构如下

注意:此时“王五”出现在了结果里,在组联接里,第一个集合的每个元素都会出现在分组联接的结果集中(无论是否在第二个集合中找到关联元素)。 在未找到任何相关元素的情况下,该元素的相关元素序列为空。 因此,结果选择器有权访问第一个集合的每个元素。 这与非分组联接中的结果选择器不同,后者无法访问第一个集合中在第二个集合中没有匹配项的元素。
总结:内联接用“join 数据源 on 条件 into 新数据源"语法,会以左表(即写在前面的表)的每一条记录为一组,分别和右表(即写在后面的表)的每一条记录进行比较,如果左表有x条记录,右表有条记录,比较会有x*y次比较,但结果只有x组,而每一组可能有<=y条>=0条记录。
如果要对上面的代码进行输出操作,会有两次循环操作
var query=from a in new List<string[]>{
new string[]{"张三","男"},
new string[]{"李四","女"},
new string[]{"王五","男"}
}
join b in new List<string[]>{
new string[]{"张三","英语",""},
new string[]{"张三","语文",""},
new string[]{"李四","数学",""}
}
on a[] equals b[] into b_group
select new {User=a,Score=b_group};
foreach(var p1 in query){
Console.WriteLine($@"{p1.User[0]}的成绩如下:");
foreach(var p2 in p1.Score){
Console.Write($@"---{p2[1]}-{p2[2]}---");
}
Console.WriteLine();
}
结果输出如下:
张三的成绩如下:
---英语-90------语文-70---
李四的成绩如下:
---数学-100---
王五的成绩如下:
可以发现,单是用组联接其实返回的结果在有些情况下是不方便进行处理的,因为要对每一个组再进行循环才能取到我们最终想要的值,下面介绍用“内联接+组联接”来方便的得到我们想要的值
内联接+组联接
代码如下:
from a in new List<string[]>{
new string[]{"张三","男"},
new string[]{"李四","女"},
new string[]{"王五","男"}
}
join b in new List<string[]>{
new string[]{"张三","英语",""},
new string[]{"张三","语文",""},
new string[]{"李四","数学",""}
}
on a[] equals b[] into b_group
from b2 in b_group
select new {User=a,Score=b2}
即在组联接后的新表b_group再次联接:from b2 in b_group
结果的结构如下:
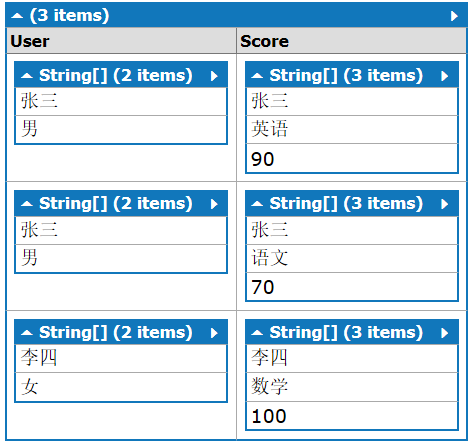
如果细心的朋友会注意到现在的结果和最前面“内联接”一节的结果是一样的。
这样的结果结构相比上一节的组联接的结构更容易获取结果内容,不再需要需要两次循环,取值代码如下
foreach(var p1 in query){
Console.WriteLine($@"{p1.User[0]}-{p1.User[1]}-{p1.Score[1]}-{p1.Score[2]}");
}
输出如下:
张三-男-英语-90
张三-男-语文-70
李四-女-数学-100
对代码稍作修改
from a in new List<string[]>{
new string[]{"张三","男"},
new string[]{"李四","女"},
new string[]{"王五","男"}
}
join b in new List<string[]>{
new string[]{"张三","英语",""},
new string[]{"张三","语文",""},
new string[]{"李四","数学",""}
}
on a[] equals b[] into b_group
from b2 in b_group
select new {User=a,Score=b_group}
只是将
select new {User=a,Score=b2}改成了
select new {User=a,Score=b_group}
结果的结构变成如下
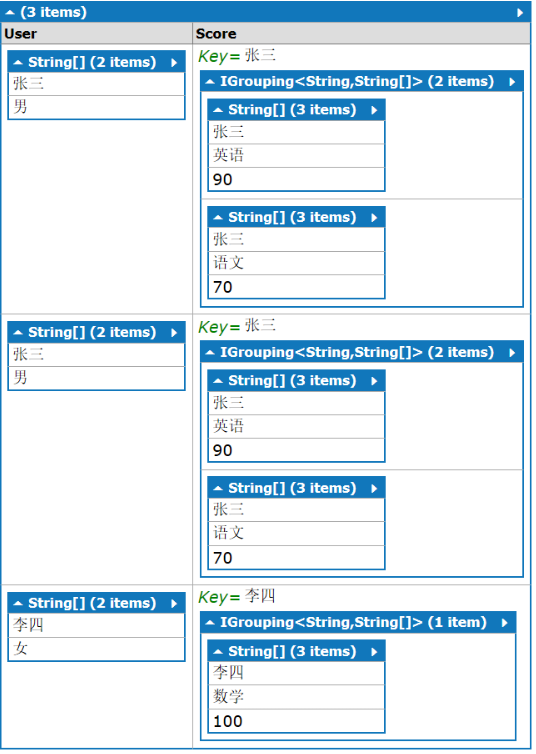
每条结果的结构变成string[]和IGrouping<string,string[]>,不管结果的结构如何,记录里已经没有“王五”的数据。
再改下代码,看看b_group,b2和a的全部结构是怎样的
代码如下:
from a in new List<string[]>{
new string[]{"张三","男"},
new string[]{"李四","女"},
new string[]{"王五","男"}
}
join b in new List<string[]>{
new string[]{"张三","英语",""},
new string[]{"张三","语文",""},
new string[]{"李四",""}
}
on a[] equals b[] into b_group
from b2 in b_group.DefaultIfEmpty()
select new{User=a, Scores=b_group,Score=b2}
结果的结构如下:
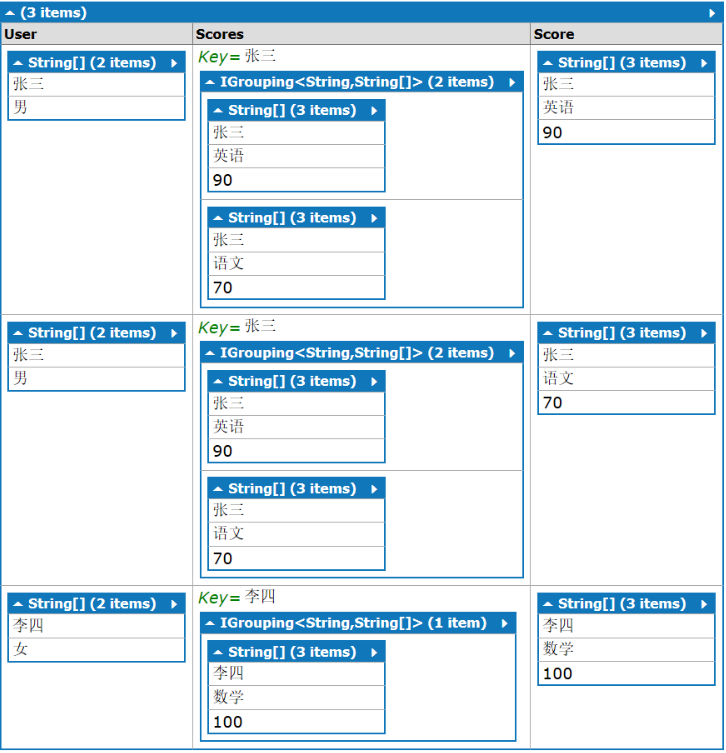
左外联接
代码如下
from a in new List<string[]>{
new string[]{"张三","男"},
new string[]{"李四","女"},
new string[]{"王五","男"}
}
join b in new List<string[]>{
new string[]{"张三","英语",""},
new string[]{"张三","语文",""},
new string[]{"李四",""}
}
on a[] equals b[] into b_group
from b2 in b_group.DefaultIfEmpty()
select new{User=a, Score=b2}
只是在“内联接+组联接”的代码上做了一点改动,将from b2 in b_group改成了from b2 in b_group.DefaultIfEmpty()
结果如下

代码稍作修改,看看内部所有结构
from a in new List<string[]>{
new string[]{"张三","男"},
new string[]{"李四","女"},
new string[]{"王五","男"}
}
join b in new List<string[]>{
new string[]{"张三","英语",""},
new string[]{"张三","语文",""},
new string[]{"李四",""}
}
on a[] equals b[] into b_group
from b2 in b_group.DefaultIfEmpty()
select new{User=a, Scores=b_group,Score=b2}
结果的结构如下
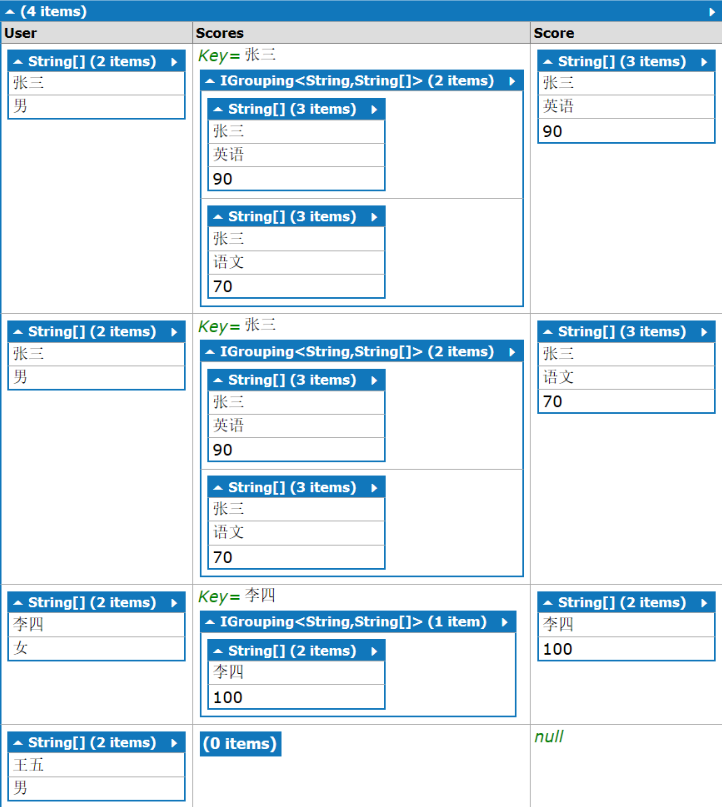
结构和“内联接+组联接"的结构是完成一样的,只是找不到成绩的“王五”也出现在结果集里。
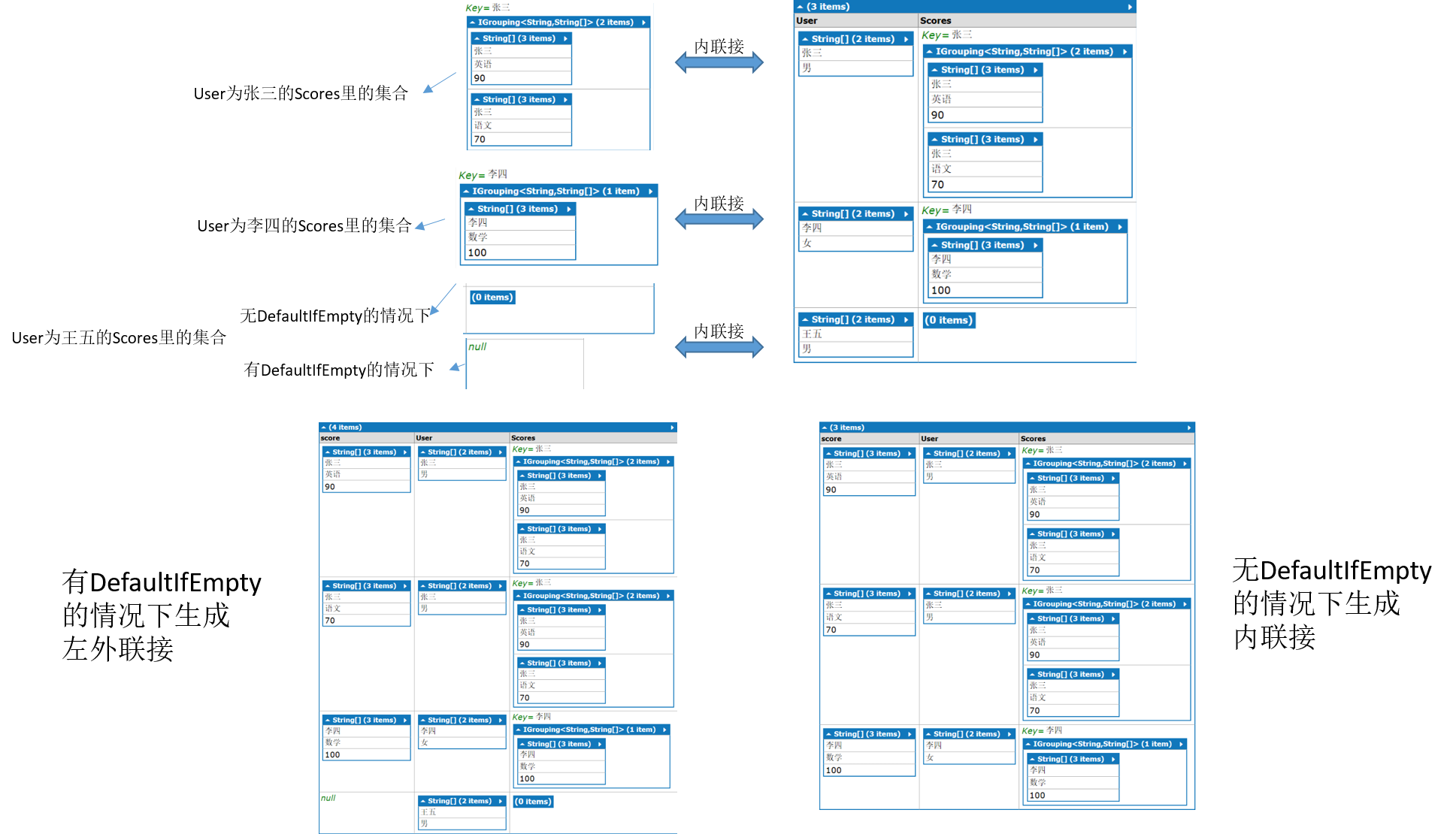
很多资料只写了怎么用“左联接”,但为什么要这么“别扭”写的原因却没有说明,特别是熟悉sql语句的对这种方式很不理解,觉得太绕了。要理解linq,先要抛开之前sql语句的影响,linq既然是c#里对象的sql语句,那我们就要以对象的方式去思考,微软的目的是为了保证linq to object、linq to sql、linq to xml的语法是一样的。先理解linq to object,至于linq to sql最终生成的sql语句是由linq底层的算法来实现的。的下面用图说明下“组联接”--》“内联接+组联接”--》“左外联接“是怎么生成的
深入剖析linq的联接的更多相关文章
- LINQ查询表达式(4) - LINQ Join联接
内部联接 按照关系数据库的说法,“内部联接”产生一个结果集,对于该结果集内第一个集合中的每个元素,只要在第二个集合中存在一个匹配元素,该元素就会出现一次. 如果第一个集合中的某个元素没有匹配元素,则它 ...
- LINQ系列:Linq to Object联接操作符
联接是指将一个数据源对象与另一个数据源对象进行关联或联合的操作.这两个数据源对象通过一个共同的值或属性进行关联. LINQ的联接操作符将包含可匹配(或相同)关键字的两个或多个数据源中的值进行匹配. L ...
- Linq世界走一走
什么是Linq?它是用来做什么的?怎么用? Linq的优点是不管数据源是什么,都可以统一查询.换言之,它是一种包含一套标准查询操作符的查询语言,可以对多个数据源进行查询 ⑴Linq俗称语言集成查询(L ...
- 认识LINQ的第一步---从查询表达式开始
学习和使用C#已经有2个月了,在这两个月的学习中,深刻体会到,C#这门语言还真不适合编程初学者学习,因为它是吸取了很多其他语言,不仅是面向对象,还包括函数式语言的很多特性,导致它变成特性大爆炸的语言. ...
- LINQ入门与标准查询运算符
LINQ的体系结构 查询表达式的完整语法 一.查询表达式必须以from子句开头,以select 或group子句结束.中间可以使用where,orderby ,join,let和其他子句.具有“延迟计 ...
- .NET LINQ 联接运算
联接运算 将两个数据源“联接”就是将一个数据源中的对象与另一个数据源中共享某个通用特性的对象关联起来. 当查询所面向的数据源相互之间具有无法直接领会的关系时,联接就成为一项重要的运 ...
- LINQ to Sql系列二 简单查询和联接查询
这一篇文章主要总结LINQ to sql的简单查询(单表查询)和联接查询(多表查询) 单表查询 需求是我们要输出TClass表中的结果.使用了from-in-select语句,代码如下: public ...
- NHibernate3剖析:Query篇之NHibernate.Linq增强查询
系列引入 NHibernate3.0剖析系列分别从Configuration篇.Mapping篇.Query篇.Session策略篇.应用篇等方面全面揭示NHibernate3.0新特性和应用及其各种 ...
- linq性能剖析
Orcas(VS2008&Framework3.5)给我们带来了很多令人兴奋的新特性,尤其是LINQ的引进,可以说方便了一大批开发 人员和框架设计人员.过去,当我们使用O/RMapping的一 ...
随机推荐
- 软件项目的开发之svn的使用
Svn简介 SVN全名Subversion,即版本控制系统.SVN与CVS一样,是一个跨平台的软件,支持大多数常见的操作系统.作为一个开源的版本控制系统,Subversion管理着随时间改变的数据.这 ...
- 进阶系列(2)—— C#集合
一.集合介绍 集合是.NET FCL(Framework Class Library)的重要组成部分,我们平常撸C#代码时免不了和集合打交道,FCL提供了丰富易用的集合类型,给我们撸码提供了极大的便利 ...
- Enterprise Library 3.1 参考源码索引
http://www.projky.com/entlib/3.1/Microsoft/Practices/EnterpriseLibrary/AppSettings/Configuration/Des ...
- 蜗牛慢慢爬 LeetCode 7. Reverse Integer [Difficulty: Easy]
题目 Reverse digits of an integer. Example1: x = 123, return 321 Example2: x = -123, return -321 Have ...
- Beta阶段冲刺前准备
第 1 篇 Scrum 冲刺博客 1.新成员 暂无新成员,等一个有缘人 团队成员: 刘阳航(captain) 陈文俊 林庭亦 郑子熙 2.讨论是否需要更换团队的PM 经过团队讨论,我们决定不更换团队P ...
- httpstat的简单使用
httpstat 应该是一个 python 封装后的 curl 工具能够展现 一些客户端连接网站的时间消耗,最近在看tls 感觉挺有用处的 简单学习一下 1. centos7 安装python 和 p ...
- matlab for 运算的提速
[1]主要思想:matlab是按列存储,定义s(nums,1)比定义s(1,nums)要快哦 需要重复query的元素看看能不能再for之前就定义好 经典案 ...
- PostgreSQL窗口函数
窗口函数允许在查询的SELECT列表和ORDER BY子句中使用. 如果有排序,要保证唯一,否则会有下面的错误: 修改方式是:保证唯一,修改方法如下:
- Google Gson用法
the latest version is 2.8.0. If you're using Gradle, add the following line: compile 'com.google.cod ...
- java 批量文件后缀重命名
import java.io.File; public class BatchFileSuffixRename { public static void main(String[] args) { / ...