爬虫基础---HTTP协议理解、网页的基础知识、爬虫的基本原理
一、HTTP协议的理解
URL和URI
在学习HTTP之前我们需要了解一下URL、URI(精确的说明某资源的位置以及如果去访问它)
URL:Universal Resource Locator 统一资源定位符,描述了一台特定服务器上某资源的特定位置。
URI :Uniform Resource Identifier 统一资源标识符,URI有两种表现形式URL和URN。
HTTP和HTTPS
我们经常会在URL的首部会看到http或者https,这个就是访问资源需要的协议类型,除了http和https还有ftp,sftp,smb等。在爬虫中,我们常用的就是http和https。
http:HyperText Transfer Protocol 超文本传输协议是互联网上应用最为广泛的一种网络协议。所有的www文件都要遵守这个标准。HTTP是一个客户端和服务器端请求和应答的标准,它使用socke基于TCP建立的,所以http是可靠的数据传输协议,由于它是短链接的,也就是一次请求,一次响应断开,所以它表现处无状态的现象。目前广泛使用的是 HTTP 1.1 版本。
https : Hyper Text Transfer Protocol over Secure Socket Layer是以安全为目标的 HTTP 通道,简单讲是HTTP的安全版,即 HTTP 下加入 SSL 层,简称为 HTTPS。HTTPS的安全基础是SSL,所以他传输的内容都是经过SSL加密的,它的主要作用:
- 建立一个信息安全通道,来保证数据的传输安全
- 确认网站的真实性,凡是使用了 https 的网站,都可以通过点击浏览器地址栏的锁头标志来查看网站认证之后的真实信息,也可以通过 CA 机构颁发的安全签章来查询。
HTTP和HTTPS的区别:
- https协议需要到ca申请证书,一般免费证书很少,需要交费.
- http是超文本传输协议,信息是明文传输,https 则是具有安全性的ssl加密传输协议。
- http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
- http的连接很简单,是无状态的;HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,比http协议安全。
HTTP请求流程
一次HTTP操作称为一个事务,其工作过程可分为4步:
首先,在浏览器地址栏(或点击一个超链接)HTTP的工作就开始了
建立连接后,客户端向服务器端发送一个请求:
请求首行:请求方式 请求协议 协议版本
\r\n
请求头 键值组成的
\r\n\r\n
如果是post请求的话,还有一个请求体
请求体
formData
服务器接受到请求后,给其响应:
响应首航 : 协议类型和版本 响应状态码 状态码描述符
\r\n
响应头
\r\n\r\n
响应体
客户端浏览器接受响应之后,在用户的浏览器渲染显式。
然后客户端和服务器端断开连接。
二、网页的基础知识
网页的组成可分为三大部分:HTML CSS JavaScript。HTML负责语义,CSS负责样式,Javascript负责交互和行为。
HTML:
HTML 是用来描述网页的一种语言,其全称叫做 Hyper Text Markup Language,即超文本标记语言。
我们可以通过Chrome 浏览器中打开一个网址,右键单击审查元素或按 F12 打开开发者模式,切换到 Elements 选项卡即可看到网页的源代码。
菜鸟教程:http://www.runoob.com/html/html-tutorial.html
w3cshool: http://www.w3school.com.cn/
CSS:
CSS,全称叫做 Cascading Style Sheets,即层叠样式表。“层叠”是指当在 HTML 中引用了数个样式文件,并且样式发生冲突时,浏览器能依据层叠顺序处理。“样式”指网页中文字大小、颜色、元素间距、排列等格式。
JavaScript:
JavaScript,简称为 JS,是一种脚本语言,HTML 和 CSS 配合使用,提供给用户的只是一种静态的信息,缺少交互性。我们在网页里可能会看到一些交互和动画效果,如下载进度条、提示框、轮播图等,这通常就是 JavaScript 的功劳。
网页的基本结构:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>HelloWorld</title>
</head>
<body>
<p>HelloWorld</p>
<div class="content">
主体内容
</div>
</body>
</html>
一般网页形式,首行标识html版本,两个html包裹head和body,head通常放一些配置和一些资源引用,body是网页的主体内容。
节点之间的关系
在网页中,组织页面的对象被渲染成一个树形结构,用来表示文档中对象的标准模型称为DOM,文档对象模型(Document Object Model,简称DOM)。
表示和处理一个HTML或XML文档的常用方法。
DOM实际上是以面向对象方式描述的文档模型。DOM定义了表示和修改文档所需的对象、这些对象的行为和属性以及这些对象之间的关系。可以把DOM认为是页面上数据和结构的一个树形表示,不过页面当然可能并不是以这种树的方式具体实现。
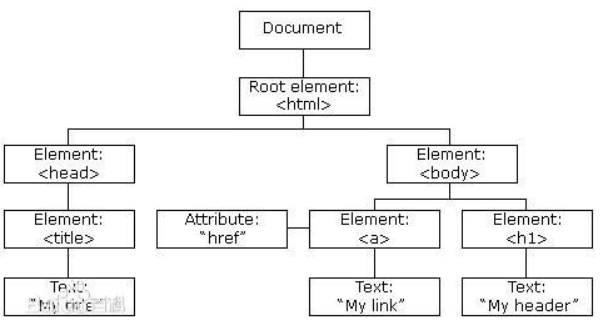
节点:根据DOM,HTML 文档中的每个成分都是一个节点。
节点层次:
HTML 文档中的所有节点组成了一个文档树(或节点树)。HTML 文档中的每个元素、属性、文本等都代表着树中的一个节点。树起始于文档节点,并由此继续伸出枝条,直到处于这棵树最低级别的所有文本节点为止。
举例,<head> 和 <body> 的父节点是 <html> 节点,文本节点 "Hello world!" 的父节点是 <p> 节点。
三、 爬虫的基本原理
网络爬虫(又被称为网页蜘蛛)是一种按照一定的规则,自动抓取万维网信息的程序或者脚本。
获取网页->提取信息->保存数据
获取网页
爬虫的首要工作就是获取网页源代码,然后从中提取我们想要的数据。
在python中,提供了许多库来帮助我们实现这个操作,如 Urllib、Requests 等,我们可以用这些库来帮助我们实现 HTTP 请求操作,Request 和 Response 都可以用类库提供的数据结构来表示,得到 Response 之后只需要解析数据结构中的 Body 部分即可,即得到网页的源代码,这样我们可以用程序来实现获取网页的过程了。
提取信息
我们获取网页源代码后,接下来的工作就是分析网页源代码,从中提取我们想要的数据,最通用的方法就是使用正则表达式,但是使用正则表达式比较复杂。在Python中,如 BeautifulSoup、PyQuery、LXML 等,使用这些库可以高效的从源代码中提取网页信息。
保存数据
提取信息之后,我们可以将数据保存到本地,以便后续使用,保存方式有很多种,比如TXT,Json也可以保存到数据库中,如Mysql,MangoDB等。
动态渲染页面的抓取
现在越来越多的网页使用js来构建网页,所以我们经常使用requests等获取的网页源代码和浏览器看到的不同,使用requests,我们只能得到静态的HTML源代码,他不会帮我们去加载js文件,我们可以借助Selenium、Splash 这样的库来实现模拟 JavaScript 渲染,这样我们便可以爬取 JavaScript 渲染的网页的内容了。
爬虫基础---HTTP协议理解、网页的基础知识、爬虫的基本原理的更多相关文章
- node.js基础模块http、网页分析工具cherrio实现爬虫
node.js基础模块http.网页分析工具cherrio实现爬虫 一.前言 说是爬虫初探,其实并没有用到爬虫相关第三方类库,主要用了node.js基础模块http.网页分析工具cherri ...
- 小白学 Python 爬虫(8):网页基础
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 《Python爬虫技术:深入理解原理、技术与开发》已经出版,送Python基础视频课程
好消息,<Python爬虫技术:深入理解原理.技术与开发>已经出版!!! JetBrains官方推荐图书!JetBrains官大中华区市场部经理赵磊作序!送Python基础视频课程!J ...
- 浅谈HTTPS和SSL/TLS协议的背景和基础
相关背景知识要说清楚HTTPS协议的实现原理,至少要需要如下几个背景知识.大致了解几个基础术语(HTTPS.SSL.TLS)的含义大致了解HTTP和TCP的关系(尤其是"短连接"和 ...
- 爬虫开发7.scrapy框架简介和基础应用
scrapy框架简介和基础应用阅读量: 1432 scrapy 今日概要 scrapy框架介绍 环境安装 基础使用 今日详情 一.什么是Scrapy? Scrapy是一个为了爬取网站数据,提取结构性数 ...
- 理解RxJava:(一)基础知识
理解RxJava:(一)基础知识 本文翻译自Grokking RxJava, Part 1: The Basics,著作权归原作者danlew所有.译文由JohnTsai翻译.转载请注明出处,并保留此 ...
- #WEB安全基础 : HTTP协议 | 文章索引
本系列讲解WEB安全所需要的HTTP协议 #WEB安全基础 : HTTP协议 | 0x0 TCP/IP四层结构 #WEB安全基础 : HTTP协议 | 0x1 TCP/IP通信 #WEB安全基础 : ...
- python网络爬虫(2)——scrapy框架的基础使用
这里写一下爬虫大概的步骤,主要是自己巩固一下知识,顺便复习一下. 一,网络爬虫的步骤 1,创建一个工程 scrapy startproject 工程名称 创建好工程后,目录结构大概如下: 其中: sc ...
- 『Python基础-1 』 编程语言Python的基础背景知识
#『Python基础-1 』 编程语言Python的基础背景知识 目录: 1.编程语言 1.1 什么是编程语言 1.2 编程语言的种类 1.3 常见的编程语言 1.4 编译型语言和解释型语言的对比 2 ...
随机推荐
- c++11 右尖括号>改进
c++11 右尖括号>改进 #define _CRT_SECURE_NO_WARNINGS #include <iostream> #include <string> # ...
- BZOJ1443 [JSOI2009]游戏Game 【博弈论 + 二分图匹配】
题目链接 BZOJ1443 题解 既然是网格图,便可以二分染色 二分染色后发现,游戏路径是黑白交错的 让人想到匹配时的增广路 后手要赢[指移动的后手],必须在一个与起点同色的地方终止 容易想到完全匹配 ...
- 【ZOJ3899】State Reversing 解题报告
[ZOJ3899]State Reversing Description 有\(N\)个不同的怪兽,编号从\(1\) 到\(N\).Yukari有\(M\)个相同的房间,编号为\(1\)到\(M\). ...
- 洛谷 P4363 [九省联考2018]一双木棋chess 解题报告
P4363 [九省联考2018]一双木棋chess 题目描述 菲菲和牛牛在一块\(n\)行\(m\)列的棋盘上下棋,菲菲执黑棋先手,牛牛执白棋后手. 棋局开始时,棋盘上没有任何棋子,两人轮流在格子上落 ...
- 如何在低速率网络中测试 Web 应用
大家看到标题后的第一个问题可能是:“我们需要这样做吗?” 如果我们开发的是局域网 Web 应用的话,可能没有必要这样做.但如果我们的 Web 应用面向的是互联网上的成千上万的用户,这样做就很必要了.因 ...
- Java之JDBC连接池
数据库连接池 连接池的概述 概念:其实就是一个容器(集合),存放数据库连接的容器. 当系统初始化好后,容器被创建,容器中会申请一些连接对象,当用户来访问数据库时, 从容器中获取连接对象,用户访问完之后 ...
- bzoj 1914: [Usaco2010 OPen]Triangle Counting 数三角形
USACO划水中... 题目中要求经过原点的三角形数目,但这种三角形没什么明显的特点并不好求,所以可以求不经过原点的三角形数量. 对于一个非法三角形,它离原点最近的那条边连接的两个点所连的两条边一定在 ...
- 《剑指offer》— JavaScript(24)二叉树中和为某一值的路径
二叉树中和为某一值的路径 题目描述 输入一颗二叉树和一个整数,打印出二叉树中结点值的和为输入整数的所有路径.路径定义为从树的根结点开始往下一直到叶结点所经过的结点形成一条路径. 思路 前序遍历二叉树, ...
- 团体程序设计天梯赛-练习集 L1-031. 到底是不是太胖了
比较两个实型的数: 若两者相等,也许用a>/b会出错... 我又想到了codeforces有很多这样的坑... #include <stdio.h> #include <std ...
- error: failed to connect to the hypervisor error: Failed to connect socket to '/var/run/libvirt/libvirt-sock': No such file or directory 解决办法
服务器版本:CentOS Linux release 7.4 Linux lb 3.10.0-693.el7.x86_64 #1 SMP Tue Aug 22 21:09:27 UTC 2017 x8 ...