LabelRank非重叠社区发现算法介绍及代码实现(A Stabilized Label Propagation Algorithm for Community Detection in Networks)
最近在研究基于标签传播的社区分类,LabelRank算法基于标签传播和马尔科夫随机游走思路上改装的算法,引用率较高,打算将代码实现,便于加深理解。
这个算法和Label Propagation 算法不同的是计算复杂度较高,对每个标签都确定了概率,但是准确性比Label Propagation算法好。
一、概念
相关概念不再累述,详情见前两篇文章
二、算法思路
首先建立一个标签集合,C={1,2,……n},n是节点的数量。标签概率向量Pi(1*n),Pi(c)=节点i对标签c的概率估计,迭代过程中每个节点的对标签c的概率估计等于其邻居节点对标签c的概率估计平均,详见公式(1)
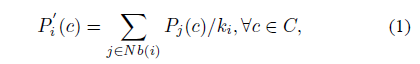
有此可得n*n维标签概率矩阵P(i→j)=[p1,p2,...pn],迭代过程可以用矩阵乘法表示A*P,其中A是网络的邻接矩阵(01矩阵)。这个思路其实可以追溯到eigenvector Centrality算法1,文献1已证明P会收敛下来。就这样就完了吗?并没有看到如何传递标签或者选择标签?

作者做的就是不停地缩放P中元素,然后删除一些概率较小的标签从P中,不停地减少标签个数,知道每个节点的标签序列不再变化,迭代停止,拥有最大概率的标签就是节点所属的社区。具体流程见下
(1)Propagation
初始阶段,每个节点访问邻居概率皆相等,见公式(3),每次迭代即左乘上一阶段的P,得到本阶段节点对每个标签的预估概率

(2)Inflation
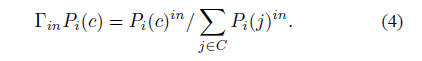
根据公式(2)不停地迭代,矩阵中0,计算复元素逐渐被取代,复杂度越来越高,流程(2)和(3)就是为减少复杂度而做的工作。首先利用公式(4)将矩阵中的元素极端处理,使值大的越来越大,值小的越来越小
(3)Cut off
这一阶段就是在公式(4)的基础上进行删除操作,将P中低于r的阈值全都置换成0,最终得到的P参与下一次迭代
(4)Explicit Conditional Update
减少算法的另一个途径就是满足某一条件的节点停止更新,具体操作就是如果节点的最大标签(对n个标签估计概率最高的那个标签)和他的邻居节点最大标签的吻合度高于q(提前给出,一般去0.7左右),那么这个节点就可以停止更新了

(5)Stop Criterion
每个节点的最大评估概率的标签不再变化,迭代停止,具有相同标签的节点归为一个社区
三、参考文献
[1]Poulin R, Boily M C, Mâsse B R. Dynamical systems to define centrality in social networks[J]. Social Networks, 2000, 22(3):187-220.
Dynamical systems to define centrality in social networks
[2]Xie J, Szymanski B K. LabelRank: A stabilized label propagation algorithm for community detection in networks[C]// Network Science Workshop. IEEE, 2013:138-143.
A Stabilized Label Propagation Algorithm for Community Detection in Networks
四、代码(matlab)
代码目前还有一点点问题,后期调试后再更新
function [R,count]=LabelR(A,in,r,q)
% LabelRank LabelRank: " A Stabilized Label Propagation
% Algorithm for Community Detection in Networks "
% Author: YY
% Created on 2017.05.09
% Inputs :
% A : adjacent matrix
% in : Inflation parameter
% : default =2
% q : Conditional Update parameter
% default = 0.7
% r : Cut off parameter
% : default = 0.1
% Output :
% R : community classfication
%%
% Step1 : Propagation
Aori=A;
A=A+eye(length(A));% add selfloop
k=repmat(sum(A,2),[1,length(A)]);
P0=A./k;
Ppre=A*P0;
a=1;
COM={};
count=0;
%%
% Step2: Inflation
while a
Pnow=A*Ppre;
Pin=Pnow.^in ;
k=repmat(sum(Pin,2),[1,length(A)]);
Pnow=Pin./k;
%%
% Step3: Cutoff
index= Pnow<r;
Pnow(index)=0;
%%
% Step4: Explicit Conditional Update
MaNow=max(Pnow,[],2);
MaPre=max(Ppre,[],2);
restart=[];
for i=1:length(A)
gain=0;
Nb=find( Aori(i,:));
MaxI=max(Pnow(i,:));
MaxI=find(Pnow(i,:)==MaxI);
MaxNb=MaNow(Nb);
for k=1:length(Nb)
MaxNbID=find(Pnow(Nb(k),:)==MaxNb(k));
if all(ismember(MaxI,MaxNbID));% 1,2和1;1和1,2;1,2和1,2,4或者1,3,4
gain=gain+1;
end
end
if gain>=q*length(Nb)
restart=[i,restart];
end
end
Pnow(restart,:)=Ppre(restart,:);
%%
% Step5: Stop Criterion
if all(ismember(find(Pnow(i,:)==MaNow(i)),find(Ppre(i,:)==MaPre(i))))
a=0;
end
Ppre=Pnow;
count=count+1;
end
R=Pnow;
end
LabelRank非重叠社区发现算法介绍及代码实现(A Stabilized Label Propagation Algorithm for Community Detection in Networks)的更多相关文章
- A Node Influence Based Label Propagation Algorithm for Community detection in networks 文章算法实现的疑问
这是我最近看到的一篇论文,思路还是很清晰的,就是改进的LPA算法.改进的地方在两个方面: (1)结合K-shell算法计算量了节点重重要度NI(node importance),标签更新顺序则按照NI ...
- Top Leaders社区发现算法(top leaders community detection approach in information networks)
一.概念 复杂网络:现实生活中各种系统都可以看做成复杂网络,复杂网络构成包括节点和边,节点是网络中的基本组成单元,节点之间的联系或者关系是网络中的边.例如 电力网络:基站代表节点,基站之间是否互通表示 ...
- 社区发现算法问题&&NetworkX&&Gephi
在做东西的时候用到了社区发现,因此了解了一下有关社区发现的一些问题 1,社区发现算法 (1)SCAN:一种基于密度的社团发现算法 Paper: <SCAN: A Structural Clust ...
- SLAP(Speaker-Listener Label Propagation Algorithm)社区发现算法
其中部分转载的社区发现SLPA算法文章 一.概念 社区(community)定义:同一社区内的节点与节点之间关系紧密,而社区与社区之间的关系稀疏. 设图G=G(V,E),所谓社区发现是指在图G中确定n ...
- GNN 相关资料记录;GCN 与 graph embedding 相关调研;社区发现算法相关;异构信息网络相关;
最近做了一些和gnn相关的工作,经常听到GCN 和 embedding 相关技术,感觉很是困惑,所以写下此博客,对相关知识进行索引和记录: 参考链接: https://www.toutiao.com/ ...
- 模块度与Louvain社区发现算法
Louvain算法是基于模块度的社区发现算法,该算法在效率和效果上都表现较好,并且能够发现层次性的社区结构,其优化目标是最大化整个社区网络的模块度. 模块度(Modularity) 模块度是评估一个社 ...
- 社区发现算法 - Fast Unfolding(Louvian)算法初探
1. 社团划分 0x1:社区是什么 在社交网络中,用户相当于每一个点,用户之间通过互相的关注关系构成了整个网络的结构. 在这样的网络中,有的用户之间的连接较为紧密,有的用户之间的连接关系较为稀疏.其中 ...
- 采样方法(二)MCMC相关算法介绍及代码实现
采样方法(二)MCMC相关算法介绍及代码实现 2017-12-30 15:32:14 Dark_Scope 阅读数 10509更多 分类专栏: 机器学习 版权声明:本文为博主原创文章,遵循CC 4 ...
- 标签传播算法(Label Propagation Algorithm, LPA)初探
0. 社区划分简介 0x1:非重叠社区划分方法 在一个网络里面,每一个样本只能是属于一个社区的,那么这样的问题就称为非重叠社区划分. 在非重叠社区划分算法里面,有很多的方法: 1. 基于模块度优化的社 ...
随机推荐
- 学习Java的方法
许多人在刚开始学习Java时,会因为学习方法的不正确,而丧失信心,从而半途而废.所以,今天,巩固就要教教大家学习Java的方法. 1.多练习 编程其实是一个非常抽象的东西,要想学好它,就不能只是看看书 ...
- ABP框架系列之七:(About-关于ABP)
Considerations Source codes Contributors Contact ASP.NET Boilerplate is designed to help us to devel ...
- Android 长时间运行任务说明
android 4.0 后,小米手机需要授权 自动启动 (在安全中心权限里设置),不然AlarmManager设置系统闹钟将不起作用
- RAC环境数据库重启实例
1.重启之前最好先看一下节点信息和运行状态 可以通过srvctl status database -d 数据库名 //查看节点信息 Crs_stat //查看节点状态 可以看到数据节点它由两个实例组成 ...
- 笔记:记录两个新接触的东东- required + placeholder
1.1 required="required" 1.2 placeholder 当用户还没有输入值时,输入型控件可能通过placeholder向用户显示描述性说明文字或者提示信息, ...
- codevs 1012
题目描述 Description 给出n和n个整数,希望你从小到大给他们排序 输入描述 Input Description 第一行一个正整数n 第二行n个用空格隔开的整数 输出描述 Output De ...
- hdu 1505,1506
1506题目 1505题目 1506: #include<stdio.h> #include<string.h> #include<iostream> using ...
- [Delphi]带进度条的ListView
带进度条的ListView unit Unit1; interface uses Windows, Messages, SysUtils, Variants, Classes, Graphics, C ...
- string 和String的区别
string 是 System.String 的别名,习惯上,我们把字符串当作对象时(有值的对象实体),我们用string.而我们把它当类时(需要字符串类中定义的方法),我们用String,比如: s ...
- 曲演杂坛--Update的小测试
今天偶然想起一个UPDATE相关的小问题,正常情况下,如果我们将UPDATE改写成与之对应的SELECT语句,其SELECT查询结果应与UPDATE的目标表存在一对一的关系,例如: 对于UPDATE语 ...