Java内存模型(一)
主存储器和工作存储器
Java虚拟机在执行Java程序的过程中会把它管理的内存划分为若干个不同的数据区域,这些区域包括方法区,堆,虚拟机栈,本地方法栈,程序计数器。方法区存储类信息,常量,字节码等数据,堆内存存储所有生成的对象,方法区和堆内存为所有线程共享,而虚拟机栈是每个线程独有的,也就是说每个线程有自己的虚拟机栈,线程执行时,每调用一个方法,就会在虚拟机栈上创建一个栈帧,栈帧信息包括方法的局部变量表,操作数栈。
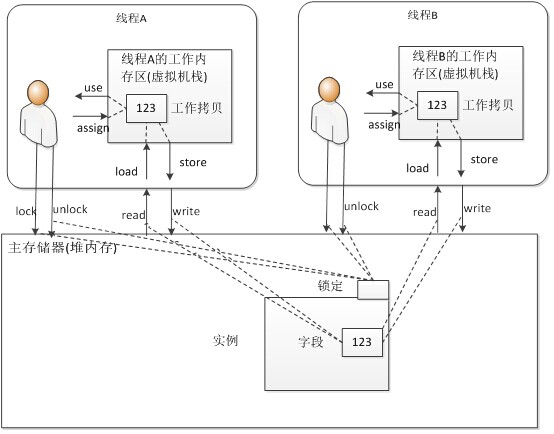
Java内存模型将内存分为主存储器和工作内存,主存储器也叫主内存,对应着Java内存区域划分的堆内存,工作内存对应着虚拟机栈和本地方法栈,所有线程共享主存储器,但是每个线程有各自的工作内存。所有对象在主内存分配,线程不能直接使用主内存的内容,必须先将主内存的内容加载到工作内存后,才能使用,修改工作内存里的内容后,也只有同步到主内存后,别的线程才可以看到。Java 内存模型如下图所示:
字段的引用
线程无法直接操作主存储器(堆内存),因此它无法直接引用字段的值。当线程需要引用字段时,需要经过3个操作:
- 1) read操作 将字段的值拷贝到工作内存区(虚拟机栈)
- 2) load操作 将read操作从主内存得到的变量值放入工作内存的变量副本
- 3) use操作 将变量副本的值传递给执行引擎
当线程再次引用同一字段时,线程可能直接引用刚才拷贝得到的工作拷贝,这时候执行的操作是use, 也可能再次从堆内存拷贝到工作内存区(虚拟机栈),然后拷贝到变量副本,最后才引用,这时候执行的操作是(read->load->use)。这两种方式的选择是由Java虚拟机执行子系统决定的。
字段的赋值
线程无法直接对主存储器进行操作,因此它也无法将值直接指定给主存储器的字段。当线程需要赋值给主存储器的字段时,需要经过以下三个步骤:
- 1) assign 将值指定给位于工作内存区的工作拷贝
- 2) store 将工作内存的值传递给主存储器
- 3) write 将store操作从工作内存得到的变量的值放入主内存的变量里
当同一线程反复给同一字段赋值时,可能只会对工作拷贝赋值,即只执行assign操作,只有指定的最后结果才会拷贝到主存储器,即执行store->write,也可能每次赋值,都会先赋值给工作拷贝,然后拷贝到主存储器,即执行assign->store->write。这两种方式的选择由Java执行处理系统决定。
内存间交互操作
Java内存模型定义了8种操作来完成关于主内存和工作内存之间具体的交互,这些操作都是原子的,不可分割(long double类型除外)。这8种操作如下所示:
- 1) lock(锁定) 作用于主内存的变量,它把一个变量标志为一条线程独占的状态
- 2) unlock(解锁) 作用于主内存的变量,它把一个处于锁定状态的变量释放出来,释放后的变量才可以被其它线程锁定
- 3) read(读取) 作用于主内存的变量,它把一个变量的值从主内存传输到线程的工作内存中,以便随后的load动作使用
- 4) load(载入) 作用于工作内存的变量,它把read操作从主内存得到的变量值放入工作内存的变量副本中
- 5) use(使用) 作用于工作内存的变量,它把变量副本的值传递给执行引擎,每当虚拟机遇到一个需要使用的变量的值的字节码指令时,将会执行这个操作。
- 6) assign(赋值) 作用于工作内存的变量,它把一个从执行引擎接收到的值赋值给工作副本变量,每当虚拟机遇到一个给变量赋值的字节码指令时执行这个操作
- 7) store(存储) 作用于工作内存的变量,将工作副本变量的值传输给主内存,以便随后的write操作使用
- 8) write(写入) 作用于主内存的变量, 它把store操作从工作内存得到的变量的值放入主内存的变量
如果要把一个变量从主内存复制到工作内存,那就要按顺序地执行read和load操作,如果要把变量从工作内存同步回主内存,那就要顺序地执行store和write操作。注意,Java内存模型只要求上述两个操作必须按顺序地执行,而没有保证必须是连续执行,也就是说read和load之间,store和write之间是可以插入其它指令的,如对内存中的变量a,b进行访问时,一种可能出现的顺序是read a, read b, load b, load a。除此之外,Java内存模型还规定了在执行上述8种基本操作时必须满足如下规则:
- 1) 不允许read和load, store和write操作之一单独出现,即不允许一个变量从主内存读取了但工作内存不接受,或者从工作内存发起会写了但主内存不接受的情况出现
- 2) 不允许一个线程丢弃它最近的assign操作,即变量在工作内存中改变了之后必须把该变化同步回主内存
- 3) 不允许一个线程无原因地(没有发生任何assign操作)把数据从线程的工作内存同步回主内存中
- 4) 一个新的变量只能在主内存中“诞生”,不允许在工作内存中直接使用一个未被初始化(load或assign)的变量,换句话说就是对一个变量实施use和store操作之前,必须先执行了load和assign操作
- 5) 一个变量在同一个时刻只允许一条线程对其进行lock操作,但lock操作可以被同一条线程重复执行多次,多次执行lock后,只有执行相同次数的unlock操作,变量才会被解锁
- 6) 如果对一个变量执行lock操作,将会清空工作内存中此变量的值,在执行引擎使用这个变量前,需要重新执行load操作初始化变量的值。synchronized与lock原语操作并不存在直接关系。详见synchronized的两项功能。
- 7) 如果一个变量事先没有被lock操作锁定,则不允许对它执行unlock操作;也不允许unlock一个被其它线程锁定住的变量
- 8) 对一个变量执行unlock之前,必须先把此变量同步回主内存中(执行store和write操作)synchronized与unlock原语操作并不存在直接关系。详见synchronized的两项功能。
synchronized的两项功能
synchronized有两项功能,线程同步和内存同步。
线程同步是指使用synchronized来制作临界区时,该区间仅让一个线程进行操作。在一个线程进入临界区后,其它线程必须在临界区的入口处等待,直到先前在临界区的线程执行完临界区代码后退出临界区,其它线程再竞争入口,谁胜利了,谁就能进入临界区执行操作。synchronized所规定的范围控制了线程的操作,这就是线程的同步。
内存的同步是指工作内存和主内存的同步问题。以下所陈述的内容可适用于synchronized方法与synchronized块两者。
1) 欲进入synchronized时
进入synchronized时,如果工作内存有未映射到主内存的工作拷贝,则工作拷贝的值会被强制写入主内存,成为其它线程可以看得见的状态。然后工作内存上的所有工作拷贝都会被丢弃。之后,欲引入主内存上的值的线程,必定会从主内存将值拷贝到工作内存。
总而言之,工作内存的内容会和主内存的内容予以同步。
2) 欲退出synchronized时
如果工作内存有未映像到主内存的工作拷贝,则工作拷贝的值会被强制写入主内存。但是退出synchronized时,不会清空工作内存的工作拷贝,也就是说后续会直接使用工作内存上的工作拷贝。
注意synchronized关键字与内存交互操作的lock、unlock并无直接关系,进入synchronized块和退出synchronized块时怎么执行lock和unlock操作,要看虚拟机如何实现。
synchronized方法编译后对应的方法字节码里有属性ACC_SYNCHRONIZED,而synchronized代码块编译生成的字节码里有monitorenter和monitorexit指令,而关于这两条指令以及带有ACC_SYNCHRONIZED属性的方法如何执行要看虚拟机如何实现,可参考《Java虚拟机规范》以及《Java语言规范》
volatile的两项功能
volatile仅进行内存同步,并不进行线程同步。当线程引用volatile字段时,通常都会发生从主内存器到工工作的拷贝,当线程给volatile字段赋值时,会发生从工作内存到主内存的拷贝。
Java内存模型要求lock,unlock,read,load,assign,use,store和write这八个操作都具有原子性,但是对于64位的数据类型(long和double),在模型中定义了一条宽松的规定:允许虚拟机将没有被volatile修饰的64位数据的读写操作划分为两次32的操作来进行,即允许虚拟机可以不保证64位数据类型的load,store,read和write操作的原子性,这点就是long和double的非原子协定。如果有多个线程共享一个未声明为volatile的long或double类型的变量,并且同时对它们进行读取和修改操作,那么某些线程可能会读到一个既非原值,也不是其他线程修改值的代表了“半个变量”的数值。
实际开发中,目前各种平台下的商用虚拟机几乎都把64位数据的读写操作为原子操作来对待,因此我们在编写代码时一般不需要将用到的long和double变量专门声明为volatile。
Double Checked Locking Pattern的危险性
早期内置锁synchronized的性能比较低,所以在实现懒汉式单例模式时采取Double Checked Locking Pattern模式,它通过尽量少执行内置锁的锁定以提高性能,如下面的代码所示:
1 |
public class MySystem {
|
在(a)if语句的条件检查下(第一次test),当instance等于null时,便会进入(b)的synchronized块,取得锁定的对象为MySystem.class,亦即MySystem Class对象。
(a)的条件检查位于临界区之外,在(c)重新执行条件检查时(第二次test),进行了同步,synchronized可以保证别的线程如果确实创建好了instance,本线程可以看到,当instance确实等于null时,便会在(d)处生成MySystem的实例。(d)的实例实在(b)~(c)的临界区中产生,因此不会产生两个以上的MySystem实例。
只有在(a)的条件测试下instance等于null时,才会进入(b)的synchronized块。因此,第二次及以后调用getInstance方法时,几乎都不会进入synchronized块。故此不用担心内置锁synchronized带来的性能问题。
表面上看Double Checked Locking模式完美地解决了synchronized引入的性能问题,只要创建好实例,就不会再进入synchronized块。但是Double Checked Locking Pattern引入了一个新的问题,就是当单例对象还没有完全构造好时,别的线程调用getInstance可能返回单例对象,此时单例对象的某些字段可能为空。以上述程序为例,某个线程调用MySystem.getInstance().getDate()方法可能返回null,这看起来有点不可思议,我们来分析一下,假设有如下的线程执行顺序(只是一种可能):
| 线程A | 线程B |
|---|---|
| (A-1)在(a)处判断instance == null | |
| (A-2)在(b)处进入synchronized块 | |
| (A-3)在(c)判断instance==null | |
| (A-4)在(d)制作MySystem的实例,指定给instance字段 | |
| 线程在此处更新,线程A将instance字段从工作内存拷贝到主内存, 线程B就可以看到instance不为null | |
| (B-1)在(a)判断instance=null | |
| (B-2)在(f)将instance的值设为getInstance的返回值 | |
| (B-3)调用getInstance返回值之getDate方法 | |
在制作MySystem的实例时,New Date()的值会指定给实例字段date,但这只是线程A对工作内存上的date工作拷贝进行赋值。若线程A退出synchronized块,date字段的值肯定会写入到主内存,但在退出前,date字段的值不保证会写入到主内存。instance=MySystem()也是一样,退出synchronized前instance字段的值可能也没有写入到主内存,但是也可能写入到主内存了。这里假设的线程执行顺序里,退出synchronized前,instance字段的值已经被写入到主内存,但是date字段的值并未写入到主内存,这是符合Java虚拟机规范的。
此时,线程B在(B-1)判断instance!=null,如此线程便不会进入synchronized块,而会立刻将getInstance的值当作返回值予以返回(return)。然后,线程B会在(B-3)调用getInstance的返回值的getDate方法,GetDate的返回值为date字段的值,线程B会引用date字段的值,这时候线程B会引用自己工作内存的date字段的值,结果date字段不在工作内存里,需要从主内存拷贝到工作内存,然而主内存里date字段的值为空,故此线程B调用MySystem.getInstance().getDate()方法返回null。
安全实现懒汉式单例模式的示范代码:
1 |
public class MySystem {
|
实现原理:Java虚拟机在加载类的时候会在使用某个类时才会加载该类,调用MySystem.getInstance()方法会执行return MySystemHodler.instance,此时才会加载MySystemHolder类,另外Java虚拟机会保证加载类是线程安全的,故此上述代码是线程安全的。
转载 http://www.cloudchou.com/softdesign/post-631.html
Java内存模型(一)的更多相关文章
- JVM学习(3)——总结Java内存模型
俗话说,自己写的代码,6个月后也是别人的代码……复习!复习!复习!涉及到的知识点总结如下: 为什么学习Java的内存模式 缓存一致性问题 什么是内存模型 JMM(Java Memory Model)简 ...
- 浅析java内存模型--JMM(Java Memory Model)
在并发编程中,多个线程之间采取什么机制进行通信(信息交换),什么机制进行数据的同步? 在Java语言中,采用的是共享内存模型来实现多线程之间的信息交换和数据同步的. 线程之间通过共享程序公共的状态,通 ...
- JMM(java内存模型)
What is a memory model, anyway? In multiprocessorsystems, processors generally have one or more laye ...
- 《深入理解Java内存模型》读书总结
概要 文章是<深入理解Java内容模型>读书笔记,该书总共包括了3部分的知识. 第1部分,基本概念 包括"并发.同步.主内存.本地内存.重排序.内存屏障.happens befo ...
- Java内存模型深度解析:final--转
原文地址:http://www.codeceo.com/article/java-memory-6.html 与前面介绍的锁和Volatile相比较,对final域的读和写更像是普通的变量访问.对于f ...
- Java内存模型深度解析:volatile--转
原文地址:http://www.codeceo.com/article/java-memory-4.html Volatile的特性 当我们声明共享变量为volatile后,对这个变量的读/写将会很特 ...
- Java内存模型深度解析:顺序一致性--转
原文地址:http://www.codeceo.com/article/java-memory-3.html 数据竞争与顺序一致性保证 当程序未正确同步时,就会存在数据竞争.java内存模型规范对数据 ...
- Java内存模型深度解析:基础部分--转
原文地址:http://www.codeceo.com/article/java-memory-1.html 并发编程模型的分类 在并发编程中,我们需要处理两个关键问题:线程之间如何通信及线程之间如何 ...
- 深入理解java内存模型系列文章
转载关于java内存模型的系列文章,写的非常好. 深入理解java内存模型(一)--基础 深入理解java内存模型(二)--重排序 深入理解java内存模型(三)--顺序一致性 深入理解java内存模 ...
- Java内存模型深度解读
Java内存模型规范了Java虚拟机与计算机内存是如何协同工作的.Java虚拟机是一个完整的计算机的一个模型,因此这个模型自然也包含一个内存模型——又称为Java内存模型. 如果你想设计表现良好的并发 ...
随机推荐
- [图解tensorflow源码] 入门准备工作
tensorflow使用了自动化构建工具bazel.脚本语言调用c或cpp的包裹工具swig.使用EIGEN作为矩阵处理工具.Nvidia-cuBLAS GPU加速计算库.结构化数据存储格式prot ...
- 吴裕雄 实战python编程(3)
import requests from bs4 import BeautifulSoup url = 'http://www.baidu.com'html = requests.get(url)sp ...
- 在hadoop运行tensor flow
http://www.infoq.com/cn/articles/deeplearning-tensorflow-casestudy http://www.tuicool.com/articles/a ...
- JAVA数据类型(转载)
JAVA中值类型的只有short,char,byte,int,long,double,float,boolean八大基本类型,其他的所有类型都是引用类型. 首先我们都知道在编程中赋值运算“=”的意思是 ...
- thymeleaf 拼接字符串与变量
参考https://www.thymeleaf.org/doc/tutorials/3.0/usingthymeleaf.html <span th:text="'The name o ...
- javascript基础代码
1.点击改变HTML内容 <html> <head> <meta charset="UTF-8"> <script> functio ...
- ubuntu下 openvpn客户端的配置
1.安装openvpn sudo apt-get install openvpn 2.配置openvpn 作为客户端,OpenVPN并没有特定的配置文件,而是由服务器提供方给出一个配置文件.对于认证, ...
- JavaScript对象继续总结
1.字符串对象 18_1.查看字符串的长度 var a = "hello world" alert(a.length) 18_2.遍历整个字符串的,这里的是索引 for (var ...
- 如何给a标签绑定ajax事件
<a href="review?action=delete&id=${review.id}&articleId=${review.articleId}"cla ...
- Html使用Iframe无刷新上传文件,后台接收
html代码:我是发送请求到teacher_center.aspx,不是到.ashx一般处理程序里,需要加 runat="server",有空我再试试发送请求到 .ashx 里 & ...