Java入门系列(五)JVM内存模型
概述

根据《Java 虚拟机规范》中的说法,Java 虚拟机的内存结构可以分为公有和私有两部分。
公有指的是所有线程都共享的部分,指的是 Java 堆、方法区、常量池。
私有指的是每个线程的私有数据,包括:PC寄存器、Java 虚拟机栈、本地方法栈。
Java虚拟机内存结构

JAVA的JVM的内存可分为3个区:堆(heap)、堆栈(stack)、方法区(method)、本地方法栈(Native Stack)、程序计数器(PC Register)
堆区(全局共享):
提供所有类实例和数组对象存储区域
jvm只有一个堆区(heap)被所有线程共享,堆中不存放基本类型和对象引用,只存放对象本身
栈区(线程独有):
每个线程包含一个栈区,栈中只保存基础数据类型的对象和自定义对象的引用(不是对象),对象都存放在堆区中
每个栈中的数据(原始类型和对象引用)都是私有的,其他栈不能访问。
方法区(全局共享):
方法区也是堆的一个组成部分,它主要存储的是运行时常量池、字段信息、方法信息、构造方法与普通函数的字节码内容以及一些特殊方法。它与JAVA堆的区别除了存储的信息与JAVA堆不一样之外,最大的区别就是这一部分JAVA虚拟机规范不强制要求实现自动内存管理系统(GC)。
本地方法栈(线程独有):
与虚拟机栈基本类似,区别在于虚拟机栈为虚拟机执行的java方法服务,而本地方法栈则是为Native方法服务。(栈的空间大小远远小于堆)
程序计数器(线程独有):
它记载着每一个线程当前运行的JAVA方法的地址,如果是当前执行的是本地方法,则程序计数器会是一个空地址。它的作用就是用来支持多线程,线程的阻塞、恢复、挂起等一系列操作,直观的想象一下,要是没有记住每个线程当前运行的位置,又如何恢复呢。依据这一点,每一个线程都有一个程序计数器,也就是说程序计数器是线程独有的。
堆(heap)
堆是什么?
堆可以被看成是一棵树,如堆排序;
jvm只有一个堆区(heap)被所有线程共享,堆中不存放基本类型和对象引用,只存放对象本身,几乎所有的对象实例和数组都在堆中分配。垃圾回收主要就是作用于这里的。
Java 语言避免直接访问堆内存中的数据可以保证程序更加健壮,如果程序直接访问并修改堆内存中数据,可能破坏内存中的数据完整性,从而导致程序 Crash。
堆中的对象的由垃圾回收器负责回收,因此大小和生命周期不需要确定,具有很大的灵活性。
在堆上创建的数据使用指针访问
为什么要设计堆?
栈(stack)
栈是什么?
一种先进后出的数据结构。
栈存储的是指向堆中数据的指针。
自动回收内存
在栈上的数据可以直接访问(堆中数据需要使用指针访问)
线程私有,生命周期与线程相同。每个方法执行的时候都会创建一个栈帧(stack frame)用于存放局部变量表、操作栈、动态链接、方法出口。
为什么要设计栈?
- 栈就是一张记录表。里面记录了各种对象的地址,如果你要找对象,去栈中遍历很快就能找到入口,但是如果在堆中遍历大而繁琐的对象,速度就会慢很多。
- https://blog.csdn.net/u011337556/article/details/73277600
Java中堆和栈有什么区别?

JVM 中堆和栈属于不同的内存区域,使用目的也不同。
栈常用于保存方法帧和局部变量,而对象总是在堆上分配。
栈通常都比堆小,也不会在多个线程之间共享,而堆被整个 JVM 的所有线程共享。
栈中的数据大小和生命周期是可以确定的,当没有引用指向数据时,这个数据就会消失。
堆中的对象的由垃圾回收器负责回收,因此大小和生命周期不需要确定,具有很大的灵活性。
栈是运行时的单位,而堆是存储的单位。
栈解决程序的运行问题,即程序如何执行,或者说如何处理数据;堆解决的是数据存储的问题,即数据怎么放、放在哪儿。
在Java中一个线程就会相应有一个线程栈与之对应,这点很容易理解,因为不同的线程执行逻辑有所不同,因此需要一个独立的线程栈。而堆则是所有线程共享的。栈因为是运行单位,因此里面存储的信息都是跟当前线程(或程序)相关信息的。
包括局部变量、程序运行状态、方法返回值等等;而堆只负责存储对象信息。
堆中存的是对象。栈中存的是基本数据类型和堆中对象的引用。一个对象的大小是不可估计的,或者说是可以动态变化的,但是在栈中,一个对象只对应了一个4btye的引用(堆栈分离的好处:))。
为什么不把基本类型放堆中呢?因为其占用的空间一般是1~8个字节——需要空间比较少,而且因为是基本类型,所以不会出现动态增长的情况——长度固定,因此栈中存储就够了,如果把他存在堆中是没有什么意义的(还会浪费空间,后面说明)。可以这么说,基本类型和对象的引用都是存放在栈中,而且都是几个字节的一个数,因此在程序运行时,他们的处理方式是统一的。但是基本类型、对象引用和对象本身就有所区别了,因为一个是栈中的数据一个是堆中的数据。
堆栈分离的好处
为什么要把堆和栈区分出来呢?栈中不是也可以存储数据吗?
- 栈存储了处理逻辑、堆存储了具体的数据,这样隔离设计更为清晰
- 堆与栈分离,使得堆可以被多个栈共享。
- 栈保存了上下文的信息,因此只能向上增长;而堆是动态分配
程序计数器
这里记录了线程执行的字节码的行号,在分支、循环、跳转、异常、线程恢复等都依赖这个计数器。
方法区(method)
又叫静态区,跟堆一样,被所有的线程共享。它用于存储已经被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
值类型、引用类型
概念
Java虚拟机中,数据类型可以分为两类:基本类型和引用类型。基本类型的变量保存原始值,即:他代表的值就是数值本身;而引用类型的变量保存引用值。
“引用值”代表了某个对象的引用,而不是对象本身,对象本身存放在这个引用值所表示的地址的位置。
引用类型表是你操作的数据就是同一个 ,也就是说当你传一个参数给另一个方法时,你在另一个方法中改变这个变量的值,那么调用这个方法时传入的变量的值也将改变。
值类型表示复制一个当前变量传给方法,当你在这个方法中改变这个变量时,最初声明的值不会变。
通俗的说法:值类型就是现金,要用直接用;引用类型就是存折,要用还得先去银行取现。
值类型:也就是基本数据类型
基本数据类型常被称为四类八种。
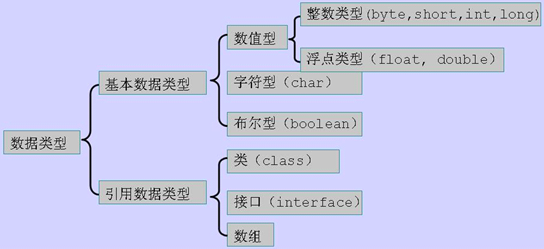

除了四类八种基本类型外,所有的类型都称为引用类型。
值传递和引用传递
值传递:基本数据类型赋值都属于值传递,值传递传递的是实实在在的变量值
引用传递:传递的是对象的引用地址,也就是它本身(自己最通俗的理解)。
引用传递:传的是地址,就是将实参的地址传给形参,形参改变了 ,实参当然也就变了,因为他们指向了相同的地址。
引用,和我们理解的指针差不多,但它又不需要我们具体去操作 。
既生瑜何生亮,绝大多数类型都是引用类型,那么为什么要有值类型呢?
如果所有的类型都是引用类型,那么我们程序的性能将显著下降。引用类型在性能方面还有一个重大的问题是垃圾回收。当没有变量指向某个对象时,
那么该对象就会成为垃圾,就会成为GC回收的对象,而GC是相当耗费资源的。而使用值类型是不需要垃圾回收的,对象超过了其作用域就会自动销毁。
上面这段解释了为什么我们需要值类型,讲解了值类型在性能上的优势,那么我们为何还需要引用类型呢?
我们都知道值类型的传值是要复制整个对象的,而引用类型仅仅是复制指向实例对象的指针。而且值类型不能被继承,所以值类型适合一些比较轻量和简单的
类型,否则同样会出现性能问题。
内存分配
一个具有值类型(value type)的数据存放在栈内的一个变量中, 即是在栈中分配内存空间,直接存储所包含的值,其值就代表数据本身。值类型的数据具有较快的存取速度。
一个具有引用类型(reference type)的数据并不驻留在栈中,而是存储于堆中。即是在堆中分配内存空间,不直接存储所包含的值 ,而是指向所要存储的值,其代表的是所指向的地址。
当访问一个具有引用类型的数据时 ,需要到栈中检查变量的内容,改变两引用堆中的一个实际数据。引用类型的数据比值类型的数据具有更大的存储规模和较低的访问速度。
Java中的垃圾回收机制
当一个堆内存中的对象没有被栈内存中表示地址的值“引用”时,这个对象就被称为垃圾对象,它无法被使用但却占据着内存中的区域,好比这样:
String s = new String("person");
S = new String ("man");
S本来指向堆内存中值person的对象的,但是s突然讨厌person了 ,它指向了堆内存中的man对象,person就像一个孤儿一样被s遗弃了 ,但是person比孤儿还要惨,因为没有什么能找到它 ,除了位高权重的“垃圾回收器”,
不过被当官的找到往往没什么好事,尤其是这个“垃圾回收器”,它会毫不留情的把垃圾清理走,并无情的销毁,以便释放内存。
垃圾回收只负责回收堆内存中的对象,不会回收任何物理资源(例如数据集、网络IO等资源)
装箱和拆箱
装箱拆箱的概念
装箱和拆箱就是值类型和引用类型的转化的过程。
将一个值类型转换成引用类型的称为装箱。将一个引用类型的转换成值类型的称为拆箱。
通俗点说就是值类型和引用类型放在不同的地方,在互相转换的时候需要把数据搬过来搬过去,这就是装箱和拆箱了.
值类型变量装箱成为一个引用类型的变量时,首先会在托管上为新的引用类型变量分配内存空间,然后将值类型变量拷贝到托管堆上新分配的对象内存中,最后
返回新分配的对象内存地址。
装箱操作是可逆的,所有就有了拆箱的操作,拆箱操作获取指向对象中包含值类型部分的指针,然后由程序员手动将其对应的值拷贝给值类型变量。
为什么需要装箱和拆箱呢?
装箱和拆箱是为了编程模式的简单,任何对象都应当可以赋给Object,对于引用类型赋给Object没问题,都是引用类型,只是一个引用的赋值,但是值类型赋给Object就有问题了,因为值类型没有引用,为了造出一个引用,也就有了装箱。
值类型是数据的容器,它存储在堆栈上,不具备多态性,而面向对象在整个对象层次的设计中,使用System.Object作为所有类型的基类,但是Obejct是引用类
型,而作为值类型的基类System.ValueType,是从System.Object派生出来的,这就产生了矛盾,装箱和拆箱就是为了解决这两种类型之间的差异。
装箱会将一个值类型放入一个未具名类型(untyped)的引用对象中,从而允许该值类型应用于那些只能使用引用类型的场合。拆箱则会从前面的装箱对象中提
取出一个值类型的副本。装箱和拆箱都是比较耗时的操作。
装箱过程
装箱就是值类型到 object 类型或者到该值类型所实现的接口类型所实现的一个隐式转换过程(可显式)。装箱的时候会在堆中自动创建一个对象实例,然后将该值复制到新对象内。
- var i = ; //System.Int32
- //对 i 装箱(隐式)进对象 o
- object o = i;

从图可知,对象 o 存的是地址引用,指向的是堆上的值,这个值的类型和变量 i 一样,也是 int 类型,值(123)也就是从变量 i Copy 过来的一个副本值而已。
【备注】装箱默认是隐式的,当然,你可以选择显式,但这并不是必须的。
拆箱过程
拆箱是从 object 类型到值类型,或从接口类型到实现该接口的值类型的显式转换的一个过程。
拆箱:检查对象实例,确保它是给定值类型的一个装箱值后,再将该值从实例复制到值类型变量中。
- int i = ; // 值类型
- object o = i; // 装箱
- int j = (int)o; // 拆箱

要在运行时成功拆箱值类型,被拆箱的项必须是对一个对象的引用,该对象是先前通过装箱该值类型的实例创建的。
拆箱时需要注意,转换出现异常的情形:

虽然,decimal 类型可以直接强转为 int 类型,但从调式的结果来看,拆箱时是会引发“转换无效”的异常。要记住,拆箱时强转的值类型,应以装箱时的值类型一致。
装箱和拆箱的意义
装箱和拆箱是为了编程模式的简单,任何对象都应当可以赋给Object,对于引用类型赋给Object没问题,都是引用类型,只是一个引用的赋值,但是值类型赋给
Object就有问题了,因为值类型没有引用。
.net 2.0开始支持的泛型就减少了这种‘痛苦’。
不过,装箱拆箱又有它灵活的一面,至少他不会预先确定要存储的是值类型还是引用类型。
便于类型装换.比如给个函数参数 预先并不知道传入的是什么类型object 定义就很有效。
关于装箱和拆箱,往往是在对值类型进行的操作,目的是将值类型数据从在栈上的存储转移到堆上,这样就和普通Object具有了同样的存储解构:栈上存储地址,
堆上存储数据.这样就可以达到统一处理的效果.
值类型操作简便高效,而引用类型更符合OO设计的基本准则。
比如int as value type只占4字节,最小的Object(不含数据)也要8字节。value type如果用栈操作的话不需要而外的创建对象和GC开销。
但是.NET框架是统一在Object继承的基础上,所以所有的类型都必须符合Object的引用类型定义和操作,所以才可能有Dosomething(Object param);这样的抽象。
如何避免装箱
我们之所以研究装箱和拆箱,是因为装箱和拆箱会造成相当大的性能损耗(相比之下,装箱要比拆箱性能损耗大),性能问题主要体现在执行速度和字段复制上。因此我们在编写代码时要尽量避免装箱和拆箱,常用的手段为:
1. 使用重载方法。为了避免装箱,很多FCL中的方法都提供了很多重载的方法。比如我们之前讨论过的Console.WriteLine方法,提供了多达19个重载方法,目的就是为了减少值类型装箱的次数。比如看下面的这段代码:
2. 使用泛型。因为装箱和拆箱的性能问题,所以泛型的主要目的就是避免值类型和引用类型之间的装箱和拆箱。
3. 如果在项目中一个值类型变量需要多次拆装箱,那么可以将这个变量提出来在前面显式装箱。
4. ToString。这点单独列出来是因为虽然小,但是很实用。虽然表面上看值类型调用ToString方法是要进行装箱的,因为ToString是从基类继承的方法。但是ToString方法是一个虚方法,值类型一般都重写了这个方法,所以调用ToString方法不会装箱。之前说过String.Format方法容易造成装箱,避免的最佳方法就是在调用这个方法前将所有的值类型参数都调用一次ToString方法。
字符串常量池
常量池的好处
常量池是为了避免频繁的创建和销毁对象而影响系统性能,其实现了对象的共享。
例如字符串常量池,在编译阶段就把所有的字符串文字放到一个常量池中。
(1)节省内存空间:常量池中所有相同的字符串常量被合并,只占用一个空间。
(2)节省运行时间:比较字符串时,==比equals()快。对于两个引用变量,只用==判断引用是否相等,也就可以判断实际值是否相等。


静态常量池
动态常量池
资料
https://blog.csdn.net/GV7lZB0y87u7C/article/details/79662413
https://www.cnblogs.com/itdragon/p/9026994.html
https://www.cnblogs.com/wmyskxz/p/9045972.html
https://www.jianshu.com/p/883260941da8
Java入门系列(五)JVM内存模型的更多相关文章
- JVM内存模型入门
JVM内存模型入门 本文是学习笔记,原文地址在:https://www.bilibili.com/video/av62009886 综述 其实没有太多新东西 JVM主要分为五个区域:栈区.堆区.本地方 ...
- java中栈内存与堆内存(JVM内存模型)
java中栈内存与堆内存(JVM内存模型) Java中堆内存和栈内存详解1 和 Java中堆内存和栈内存详解2 都粗略讲解了栈内存和堆内存的区别,以及代码中哪些变量存储在堆中.哪些存储在栈中.内存中的 ...
- JVM内存模型总结,有各版本JDK对比、有元空间OOM监控案例、有Java版虚拟机,综合实践学习!
作者:小傅哥 博客:https://bugstack.cn Github:https://github.com/fuzhengwei/CodeGuide/wiki 沉淀.分享.成长,让自己和他人都能有 ...
- Java内存管理-JVM内存模型以及JDK7和JDK8内存模型对比总结(三)
勿在流沙住高台,出来混迟早要还的. 做一个积极的人 编码.改bug.提升自己 我有一个乐园,面向编程,春暖花开! 上一篇分享了JVM及其启动流程,今天介绍一下JVM内部的一些区域,以及具体的区域在运行 ...
- 深入理解java虚拟机学习笔记(一)JVM内存模型
上周末搬家后,家里的宽带一直没弄好,跟电信客服反映了N遍了终于约了个师傅明天早上来迁移宽带,可以结束一个多星期没网的痛苦日子了.这段时间也是各种忙,都一个星期没更新博客了,再不写之前那种状态和激情都要 ...
- JVM系列一:JVM内存模型
今天起开始总结JVM.自己也看了好多JVM相关的知识,在此做个总结. 打算分为五个部分来讲:JVM内存模型.JVM类加载机制.JVM垃圾回收机制.JVM启动参数设置及优化.JVM其他相关. 今天首先来 ...
- 直通BAT必考题系列:深入详解JVM内存模型与JVM参数详细配置
VM基本是BAT面试必考的内容,今天我们先从JVM内存模型开启详解整个JVM系列,希望看完整个系列后,可以轻松通过BAT关于JVM的考核. BAT必考JVM系列专题 1.JVM内存模型 2.JVM垃圾 ...
- Java基础知识强化100:JVM 内存模型
一. JVM内存模型总体架构图: 方法区和堆由所有线程共享,其他区域都是线程私有的 二. JVM内存模型的结构分析: 1. 类装载器(classLoader) 类装载器,它是在java虚拟机中用途是 ...
- Java面试- JVM 内存模型讲解
经常有人会有这么一个疑惑,难道 Java 开发就一定要懂得 JVM 的原理吗?我不懂 JVM ,但我照样可以开发.确实,但如果懂得了 JVM ,可以让你在技术的这条路上走的更远一些. JVM 的重要性 ...
- java 深入理解jvm内存模型 jvm学习笔记
jvm内存模型 这是java堆和方法区内存模型 参考:https://www.cnblogs.com/honey01/p/9475726.html Java 中的堆也是 GC 收集垃圾的主要区域.GC ...
随机推荐
- 循环队列的C语言实现
生活中有很多队列的影子,比如打饭排队,买火车票排队问题等,可以说与时间相关的问题,一般都会涉及到队列问题:从生活中,可以抽象出队列的概念,队列就是一个能够实现“先进先出”的存储结构.队列分为链式队列和 ...
- 蜗牛慢慢爬 LeetCode 7. Reverse Integer [Difficulty: Easy]
题目 Reverse digits of an integer. Example1: x = 123, return 321 Example2: x = -123, return -321 Have ...
- Powershell笔记之MVA课程
很早之前看过MVA的Powershell课程,最近准备回顾一下,还是有一些意外的收获. <<快速入门 : PowerShell 3.0 高级工具和脚本>> 1. Invoke- ...
- ArrayList底层实现
ArrayList 底层是有数组实现,实际上存放的是对象的引用,而不是对象本身.当使用不带参的构造方法生成ArrayList对象时,实际会在底层生成一个长度为10的数组 当添加元素超过10的时候,会进 ...
- javascript中boolean类型和其他类型的转换
在javascript中,if语句括号中的表达式返回值可以是任何类型,即:if(a)中的a可以是boolean.number.string.object.function.undefined中的任何类 ...
- 每日一问(常用的集合接口和类有哪些【二】)—ArrayList类和数组之间的转换
ArrayList的实质是数组,但是在类的实例中所存储的数组是无法访问的,因此实际上是无法直接作为数组使用,那么如何将这两者进行转化呢? Collection接口定义了toArray的方法,可将实现该 ...
- python selenium2 有关cookie操作实例及如何绕开验证码
1.先看一下cookie是啥 cookie是访问web时服务器记录在用户本地的一系列用户信息(比如用户登录信息),以便对用户进行识别 from selenium import webdriver im ...
- Life Forms POJ - 3294(不小于k个字符串中的最长子串)
题意: 求不小于字符串一半长度个字符串中的最长字串 解析: 论文题例11 将n个字符串连起来,中间用不相同的且没有出现在字符串中的字符隔开, 求后缀数组, 然后二分答案变为判定性问题, 然后判断每组的 ...
- Cryptography Reloaded UVALive - 4353(BigInteger)
写写式子就出来了方程.. 然后解方程..不过数很大..用Java就好啦.. 就不贴呃的代码了...贴别人的..https://blog.csdn.net/qq_15714857/article/det ...
- [HDU4787]GRE Words Revenge 解题报告
这是我之前博客里提到的一道AC自动机的练手题,但是要完成这道题,我之前博客里提到的东西还不够,这里总结一下这道题. 这道题不是一般的裸的AC自动机,它的询问和插入是交叉出现的所以用我之前写的板子不大合 ...