@JVM中的几种垃圾收集算法
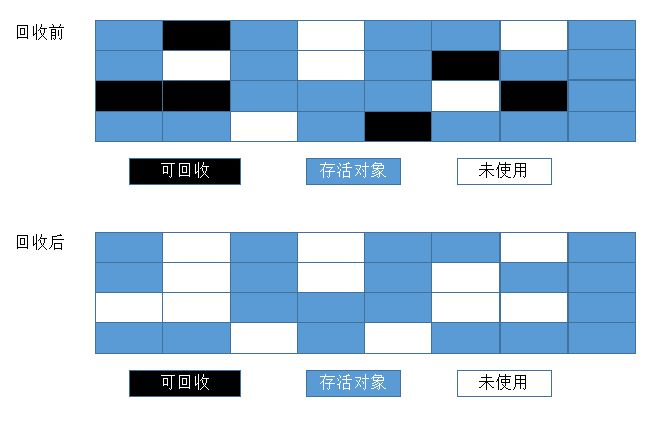
标记-清除(Mark-Sweep)
算法分为"标记"和"清除"两个阶段:首先标记出所有需要回收的对象,在标记完成后统一回收掉所有被标记的对象(没有与GC Roots相连接的引用链的对象)。它是最基础的收集算法,因为后续的收集算法都是基于这种思路并对其缺点进行改进而得到的。它的主要缺点有两个:一个是效率问题,标记和清除这两个过程的效率都不高;另外一个是碎片问题,标记清除之后会产生大量不连续的内存碎片,可能会导致程序在以后的运行过程中需要分配较大对象时由于无法找到足够的连续内存而不得不提前触发另一次垃圾收集动作。如下图:
复制算法(Copying)
复制算法是为了解决效率问题而出现的,它将可用内存按照容量划分为大小相等的两块,每次只使用其中的一块。当这一块的内存用完了,它将还存活着的对象复制到另一块上面,然后再把已经使用过的内存空间一次性清理掉,这样使得每一次都是对整个半区进行内存回收,内存分配的时候就不用考虑内存碎片的问题,只要移动堆顶的指针,按照顺序分配内存就可以了。实现简单,运行高效。如下图:
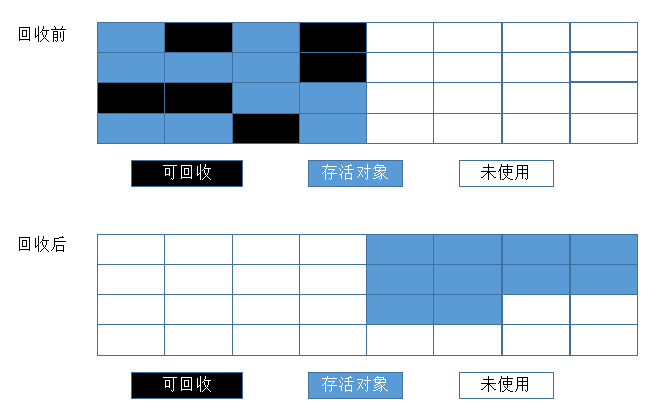
不过这种算法有个缺点,内存缩小为了原来的一半,这样代价太高了。
现在的商业虚拟机都采用这种收集算法来回收新生代,IBM的专门研究表明,新生代中的对象98%是朝生夕死的,所以并不需要按照1∶1的比例来划分内存空间,因此新生代的内存被划分为一块较大的Eden空间和两块较小的Survivor空间,每次使用Eden和其中一块Survivor。当回收时,将Eden和Survivor中还存活着的对象一次性地拷贝到另外一块Survivor空间上,最后清理掉Eden和刚才用过的Survivor的空间。HotSpot虚拟机默认Eden和Survivor的大小比例是8∶1,也就是每次新生代中可用内存空间为整个新生代容量的90%(80%+10%),只有10%的内存是会被"浪费"的。当然,98%的对象可回收只是一般场景下的数据,我们没有办法保证每次回收都只有不多于10%的对象存活,如果另外一块Survivor空间没有足够的空间存放上一次新生代收集下来的存活对象,这些对象将直接通过分配担保(HandlePromotion)机制进入老年代。
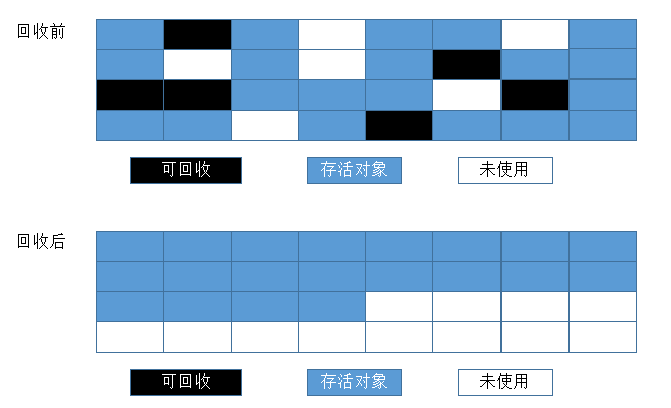
标记-整理(Mark-Compact)
复制收集算法在对象存活率较高时就要执行较多的复制操作,效率将会变低。更关键的是,如果不想浪费50%的空间,就需要有额外的空间进行分配担保,以应对被使用的内存中所有对象都100%存活的极端情况,所以老年代都是不易被回收的对象,对象存活率高,因此一般不能直接选用复制算法。根据老年代的特点,有人提出"标记-整理"算法,标记过程仍然与"标记-清除"算法一样,但后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存。如图:
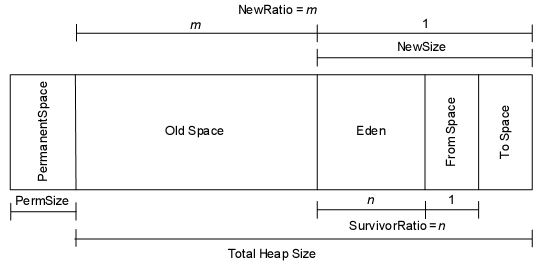
分代收集(Generational Collection)
当前商业虚拟机的垃圾收集都采用这种算法,这种算法没什么特别的,无非是上面内容的结合罢了,只是根据对象的存活周期的不同将内存划分为几块。一般是把Java堆分为新生代和老年代,这样就可以根据各个年代的特点采用最适当的收集算法。在新生代中,每次垃圾收集时都有大批对象死去,只有少量存活,那就选用复制算法。而老年代对象存活率高、没有额外空间对它进行分配担保,就必须使用"标记-清除"或"标记-整理"算法来进行回收。
@JVM中的几种垃圾收集算法的更多相关文章
- JVM三种垃圾收集算法思想及发展过程
JVM垃圾收集算法的具体实现有很多种,本文只是介绍实现这些垃圾收集算法的三种思想和发展过程.所有的垃圾收集算法的具体实现都是遵循这三种算法思想而实现的. 1.标记-清除算法 标记-清除(Mark-Sw ...
- 大话JVM(一):垃圾收集算法
系列介绍|本系列主要是记录学习jvm过程中觉得重要的内容,方便以后复习 在说垃圾收集算法之前,先要说一下垃圾收集,从大的讲,垃圾收集需要考虑三件事情: 1.哪些内存需要回收 2.什么时候回收 3.如 ...
- JVM笔记3:Java垃圾收集算法与垃圾收集器
当前商业虚拟机的垃圾收集都采用"分代收集"算法,即根据对象生命周期的不同,将内存划分几块,一般为新生代和老年代,不同的代根据其特点使用最合适的垃圾收集算法 一,标记-清除算法: 该 ...
- JVM常见的七种垃圾收集器的简单比较
1.Serial收集器曾经是虚拟机新生代收集的唯一选择,是一个单线程的收集器,在进行收集垃圾时,必须stop the world,它是虚拟机运行在Client模式下的默认新生代收集器. 2.Seria ...
- JVM学习笔记二:垃圾收集算法
垃圾回收要解决的问题: 哪些内存需要回收? 线程私有区域不需要回收,如PC.Stack.Native Stack:Java 堆和方法区需要 什么时候回收? 以后的文章解答 如何回收? 首先进行对象存活 ...
- C语言中的七种排序算法
堆排序: void HeapAdjust(int *arraydata,int rootnode,int len) { int j; int t; *rootnode+<len) { j=*ro ...
- php中的四种排序算法
. 冒泡排序 思路分析:在要排序的一组数中,对当前还未排好的序列,从前往后对相邻的两个数依次进行比较和调整,让较大的数往下沉,较小的往上冒.即,每当两相邻的数比较后发现它们的排序与排序要求相反时,就将 ...
- JVM的7种垃圾收集器:主要特点 应用场景 设置参数 基本运行原理
原文地址:https://blog.csdn.net/tjiyu/article/details/53983650 下面先来了解HotSpot虚拟机中的7种垃圾收集器:Serial.ParNew.Pa ...
- 【004】【JVM——垃圾收集算法】
Java虚拟机学习总结文件夹 垃圾收集算法 垃圾收集算法的实现涉及大量的程序细节,并且各个平台的虚拟机操作内存的方法又各不同样,介绍几种垃圾收集算法的思想及其发展过程. 标记-清除算法 垃圾收集 ...
随机推荐
- flex布局防止被挤压 flex-shrink: 0
lex布局非常好用,但在开发过程中可能会碰到的一些坑 1.内容超出容器大致情况是:在一个设置了display:flex布局的大容器A中并排放置两个子容器,并且子容器设置flex:1,子容器中都有一个元 ...
- Git配置用户名密码
配置Git 在Linux下和windows下配置Git的方法差不多,只是在Linux下,可以在命令行里直接使用git config进行配置, 而在windows下则要先打开“Git Bash”,进入m ...
- [CodeChef - STREETTA] The Street 李超线段树
大致题意: 给出两个序列A,B,A初始为负无穷,B初始为0,有三种操作 1.在A上区间[u,v]上加一个等差数列,取与原本A序列的最大值. 2.在B上区间[u,v]上加一个等差数列. 3.给出一个点X ...
- 海康威视 - 萤石云开放平台 js 版
开放平台 https://open.ys7.com/mobile/download.html API http://open.ys7.com/doc/zh/uikit/uikit_javascript ...
- 在centOS使用systemctl配置启动多个tomcat
公司服务器使用的是阿里云CentOS7,CentOS7和CentOS6目前最大区别就是service变成了现在的systemctl,简单的查了一下并结合使用,发现systemctl功能上等同于6上面的 ...
- ACM 水果 hdu 1263 一题多解
题目:http://acm.hdu.edu.cn/showproblem.php?pid=1263 文章末有相应的一些测试数据供参考. 传统的数组解题方式 思路一: 三种属性的数据放在一个结构体里面, ...
- Codeforces.724G.Xor-matic Number of the Graph(线性基)
题目链接 \(Description\) 给定一张带边权无向图.若存在u->v的一条路径使得经过边的边权异或和为s(边权计算多次),则称(u,v,s)为interesting triple(注意 ...
- ST-PUZZLE-2.0(一个益智游戏)
注:未经博主允许不得转载. 原文链接:http://www.cnblogs.com/Blog-of-Eden/p/9060300.html 和 https://i-m-eden.github.io/2 ...
- 【BZOJ】4720: [Noip2016]换教室
4720: [Noip2016]换教室 Time Limit: 20 Sec Memory Limit: 512 MBSubmit: 1690 Solved: 979[Submit][Status ...
- bzoj 2844 子集异或和名次
感谢: http://blog.sina.cn/dpool/blog/s/blog_76f6777d0101d0mr.html 的讲解(特别是2^(n-m)的说明). /*************** ...