基本数据结构 -- 栈简介(C语言实现)
栈是一种后进先出的线性表,是最基本的一种数据结构,在许多地方都有应用。
一、什么是栈
栈是限制插入和删除只能在一个位置上进行的线性表。其中,允许插入和删除的一端位于表的末端,叫做栈顶(top),不允许插入和删除的另一端叫做栈底(bottom)。对栈的基本操作有 PUSH(压栈)和 POP (出栈),前者相当于表的插入操作(向栈顶插入一个元素),后者则是删除操作(删除一个栈顶元素)。栈是一种后进先出(LIFO)的数据结构,最先被删除的是最近压栈的元素。栈就像是一个箱子,往里面放入一个小盒子就相当于压栈操作,往里面取出一个小盒子就是出栈操作,取盒子的时候,最后放进去的盒子会最先被取出来,最先放进去的盒子会最后被取出来,这即是后入先出。下面是一个栈的示意图:

二、栈的实现
由于栈是一个表,因此任何实现表的方法都可以用来实现栈。主要有两种方式,链表实现和数组实现。
2.1 栈的链表实现
可以使用单链表来实现栈。通过在表顶端插入一个元素来实现 PUSH,通过删除表顶端元素来实现 POP。使用链表方式实现的栈又叫动态栈。动态栈有链表的部分特性,即元素与元素之间在物理存储上可以不连续,但是功能有些受限制,动态栈只能在栈顶处进行插入和删除操作,不能在栈尾或栈中间进行插入和删除操作。
栈的链表实现代码如下,编译环境是 win10,vs2015:
#include "stdio.h"
#include "stdlib.h"
#include "string.h"
#include "windows.h" struct stack_node {
int data;
struct stack_node *next;
}; typedef struct stack_node *PtrToNode;
typedef PtrToNode Stack; Stack create_stack();
void push_stack(Stack s, int data);
void pop_stack(Stack s);
int top_stack(Stack s);
int stack_is_empty(Stack s); int main()
{
Stack stack = create_stack(); // 新建一个空栈
int top_data,i;
// 压栈操作,执行10次
for (i = ;i < ;i++) {
push_stack(stack, i);
}
// 出栈操作,执行1次
pop_stack(stack);
// 返回栈顶元素的值
top_data = top_stack(stack);
printf("%d\n", top_data); system("pause");
} /* 创建一个空栈 */
Stack create_stack()
{
Stack S; S = (Stack)malloc(sizeof(struct stack_node));
if (S == NULL)
printf("malloc fair!\n");
S->next = NULL; return S;
} /* PUSH 操作 */
void push_stack(Stack s,int data)
{
// 新建一个结点,用于存放压入栈内的元素,即新的栈顶
PtrToNode head_node = (PtrToNode)malloc(sizeof(struct stack_node));
if (head_node == NULL)
printf("malloc fair!\n"); head_node->data = data; // 添加数据
head_node->next = s->next; // 新的栈顶 head_node 的 next 指针指向原来的栈顶 s->next
s->next = head_node; // s->next 现在指向新的栈顶
} /* POP 操作 */
void pop_stack(Stack s)
{
PtrToNode head_node = (PtrToNode)malloc(sizeof(struct stack_node));
if (head_node == NULL)
printf("malloc fair!\n"); // 先判断栈是否为空,若栈为空,则不能再进行出栈操作,报错
if (stack_is_empty(s)) {
printf("Error! Stack is empty!\n");
}
else {
head_node = s->next; // head_node 为栈顶
s->next = head_node->next; // s->next 指向 head_node->next ,即新的栈顶
free(head_node); // 释放原来栈顶元素所占的内存
}
} /* 查看栈顶元素 */
int top_stack(Stack s)
{
if (stack_is_empty(s)) {
printf("Error! Stack is empty!\n");
return ;
}
else {
return s->next->data;
}
} /* 判断栈是否为空 */
int stack_is_empty(Stack s)
{
return s->next == NULL;
}
该程序将数字 1-9 分别压栈,然后执行一次出栈操作,最后打印栈顶元素,结果为8。
2.2 栈的数组实现
同样,栈也可以用数组来实现。使用数组方式实现的栈叫静态栈。
用数组实现栈很简单,每个栈都有一个 TopOfStack,用来表示栈顶在数组中的下标,对于空栈,该值为 -1(这就是空栈的初始化)。当需要压栈时,只需要将 TopOfStack 加 1,然后将数组中该下标处的值置为压入栈的值即可;出栈操作更简单,只需要将 TopOfStack 减 1 即可。需要注意的是,对空栈的 POP 操作和对满栈的 PUSH 操作都会产生数组越界并引起程序崩溃。
栈的数组实现方法如下,编译环境是 win10,vs2015:
#include "stdio.h"
#include "stdlib.h"
#include "string.h"
#include "windows.h" #define MinStackSize 5
#define EmptyTOS -1 struct stack_array {
int capacity; // 栈的容量
int top_of_stack; // 栈顶的下标
int *array; // 用于存放栈的数组
}; typedef struct stack_array *ArrayRecord;
typedef ArrayRecord Stack; Stack create_stack(int stack_capacity);
void make_empty(Stack s);
void push_stack(Stack s, int data);
int top_stack(Stack s);
void pop_stack(Stack s);
int stack_is_empty(Stack s);
int stack_is_full(Stack s); int main()
{
Stack stack = create_stack();
int topdata, i;
for (i = ;i < ;i++) {
push_stack(stack, i);
}
pop_stack(stack);
pop_stack(stack);
topdata = top_stack(stack);
printf("%d\n", topdata); system("pause");
} /* 创建一个栈 */
Stack create_stack(int stack_capacity)
{
Stack S; if (stack_capacity < MinStackSize)
printf("Error! Stack size is too small!\n"); S = (Stack)malloc(sizeof(struct stack_array));
if (S == NULL)
printf("malloc error!\n"); S->array = (int *)malloc(sizeof(struct stack_array) * stack_capacity);
if (S->array == NULL)
printf("malloc error!\n");
S->capacity = stack_capacity; make_empty(S);
return S;
} /* 创建一个空栈 */
void make_empty(Stack s)
{
// 栈顶的下标为 -1 表示栈为空
s->top_of_stack = EmptyTOS;
} /* PUSH 操作 */
void push_stack(Stack s, int data)
{
if (stack_is_full(s)) {
printf("Error! Stack is full!\n");
}
else {
s->top_of_stack++;
s->array[s->top_of_stack] = data;
}
} /* POP 操作 */
void pop_stack(Stack s)
{
if (stack_is_empty(s)) {
printf("Error! Stack is empty!\n");
}
else {
s->top_of_stack--;
}
} /* 返回栈顶元素 */
int top_stack(Stack s)
{
if (stack_is_empty(s)) {
printf("Error! Stack is empty!\n");
return ;
}
else {
return s->array[s->top_of_stack];
}
} /* 检测栈是否为空栈 */
int stack_is_empty(Stack s)
{
// 栈顶的下标为 -1 表示栈为空
return s->top_of_stack == EmptyTOS;
} /* 检测栈是否为满栈 */
int stack_is_full(Stack s)
{
// 栈顶的下标为 capacity - 1 表示栈满了(数组下标从 0 开始)
return s->top_of_stack == --s->capacity;
}
该程序将数字 1-9 分别压栈,然后执行两次出栈操作,最后打印栈顶元素,结果为7。
2.3 栈的链表实现和数组实现的优缺点
使用链表来实现栈,内存动态分配,可以不必担心内存分配的问题,但是 malloc 和 free 的调用开销会比较大。
使用数组实现的栈,需要提前声明一个数组的大小,如果数组大小不够,则可能会发生数组越界,如果数组太大,则会浪费一定的空间。一般而言,会给数组声明一个足够大而不至于浪费太多空间的大小。除了这个问题,用数组实现的栈执行效率会比用链表来实现的高。
这两种实现方式中,栈的操作如 PUSH、POP 均是以常数时间运行的,执行速度很快,因此,栈的执行效率通常很高。
三、栈的应用
栈的应用十分广泛 ,在函数调用、中断处理、表达式求值、内存分配等操作中都需要用到栈。本文接下来描述一下栈在函数调用中的应用:
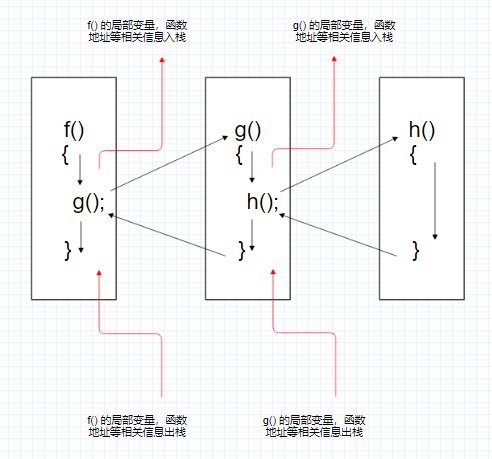
假设有一个函数 f(),现在函数 f() 要调用函数 g() ,而函数 g() 又需要调用函数 h() 。当函数 f() 开始调用函数 g() 时,函数 f() 的所有局部变量需要由系统存储起来,否则被调用的新函数 g() 将会覆盖调用函数 f() 的变量;不仅如此,主调函数当前的位置也是需要保存的,以便被调函数执行完后知道回到哪里接着执行调用函数。同样的,函数 g() 调用函数 h() 时,g() 的相关信息也需要存储起来。在函数 h() 执行完成后,再从系统中取出函数 g() 的相关信息接着执行函数 g();当函数 g() 执行完成后,从系统中取出函数 f() 的相关信息然后接着执行函数 f()。从这里的描述中可以看到,函数调用时,调用函数的信息是存放在一个后进先出结构中的,显然,用栈来存放再好不过,用一幅图演示一下:
参考资料:
《算法导论 第三版》
《数据结构与算法分析--C语言描述》
基本数据结构 -- 栈简介(C语言实现)的更多相关文章
- 数据结构——栈(C语言实现)
#include <stdio.h> #include <stdlib.h> #include<string.h> #include<malloc.h> ...
- C语言数据结构-栈的实现-初始化、销毁、长度、取栈顶元素、查找、入栈、出栈、显示操作
1.数据结构-栈的实现-C语言 #define MAXSIZE 100 //栈的存储结构 typedef struct { int* base; //栈底指针 int* top; //栈顶指针 int ...
- C语言学习书籍推荐《数据结构与算法分析:C语言描述(原书第2版)》下载
维斯 (作者), 冯舜玺 (译者) <数据结构与算法分析:C语言描述(原书第2版)>内容简介:书中详细介绍了当前流行的论题和新的变化,讨论了算法设计技巧,并在研究算法的性能.效率以及对运行 ...
- 数据结构与抽象 Java语言描述 第4版 pdf (内含标签)
数据结构与抽象 Java语言描述 第4版 目录 前言引言组织数据序言设计类P.1封装P.2说明方法P.2.1注释P.2.2前置条件和后置条件P.2.3断言P.3Java接口P.3.1写一个接口P.3. ...
- 数据结构算法集---C++语言实现
//数据结构算法集---C++语言实现 //各种类都使用模版设计,可以对各种数据类型操作(整形,字符,浮点) /////////////////////////// // // // 堆栈数据结构 s ...
- python算法与数据结构-栈(43)
一.栈的介绍 栈作为一种数据结构,是一种只能在一端进行插入和删除操作.它按照先进后出的原则存储数据,先进入的数据被压入栈底,最后的数据在栈顶,需要读数据的时候从栈顶开始弹出数据(最后一个数据被第一个读 ...
- 《数据结构与算法分析-Java语言描述》 分享下载
书籍信息 书名:<数据结构与算法分析-Java语言描述> 原作名:Data Structures and Algorithm Analysis in Java 作者: 韦斯 (Mark A ...
- 数据结构与算法分析——C语言描述 第三章的单链表
数据结构与算法分析--C语言描述 第三章的单链表 很基础的东西.走一遍流程.有人说学编程最简单最笨的方法就是把书上的代码敲一遍.这个我是头文件是照抄的..c源文件自己实现. list.h typede ...
- 数据结构与算法C语言实现笔记(1)--表
声明:此一系列博客为阅读<数据结构与算法分析--C语言描述>(Mark Allen Weiss)笔记,部分内容参考自网络:转载请注明出处. 1.表 表是最简单的数据结构,是形如A1.A2. ...
随机推荐
- 1208. [HNOI2004]宠物收养场【平衡树-splay】
Description 最近,阿Q开了一间宠物收养所.收养所提供两种服务:收养被主人遗弃的宠物和让新的主人领养这些宠物.每个领养者都希望领养到自己满意的宠物,阿Q根据领养者的要求通过他自己发明的一个特 ...
- chrome的uget扩展程序红色 Unable to connect with uget-integrator问题
我们根据网上的教程在ubuntu16.04中安装下载工具uget+aria2并配置chrome时,最后重新打开chrome浏览器,发现uget扩展程序是红色的,点开看到”Unable to conne ...
- C语言偏冷知识点汇总
1.C语言函数声明中参数类型写在右括号后是什么意思?如下代码所示: int add(a, b) int a; int b; { return a + b; } 像这样的声明是什么意思,我测试过在gcc ...
- Spring源码分析(十五)获取单例
本文结合<Spring源码深度解析>来分析Spring 5.0.6版本的源代码.若有描述错误之处,欢迎指正. 之前我们讲解了从缓存中获取单例的过程,那么,如果缓存中不存在已经加载的单例be ...
- 《Mysql必知必会》笔记
两年前买的书,因为种种原因一直没看,零碎抽点时间看一遍,感觉对自己有用的就顺手记录下.之后转身就把这本书甩了,因为这本书的内容大多是增删改查语句,不实操只看的话,没有什么意义.而且作为一个测试,其实在 ...
- ios开发UI篇—UITextfield
概述 UITextField在界面中显示可编辑文本区域的对象. 您可以使用文本字段来使用屏幕键盘从用户收集基于文本的输入.键盘可以配置许多不同类型的输入,如纯文本,电子邮件,数字等等.文本字段使用目标 ...
- 阿里云CentOS自动备份MySql 8.0并上传至七牛云
本文主要介绍一下阿里云CentOS7下如何对MySql 8.0数据库进行自动备份,并使用.NET Core 将备份文件上传至七牛云存储上,并对整个过程所踩的坑加以记录. 环境.工具.准备工作 服务器: ...
- CodeIgniter Doctrine2基本使用(一)(转)
CodeIgniter Doctrine2基本使用(一) 之前写了一篇文章叫作<CodeIgniter 3.0整合Doctrine2>里面介绍了一些简单的Doctrine2的用法,当然我也 ...
- Hadoop的HDFS和MapReduce的安装(三台伪分布式集群)
一.创建虚拟机 1.从网上下载一个Centos6.X的镜像(http://vault.centos.org/) 2.安装一台虚拟机配置如下:cpu1个.内存1G.磁盘分配20G(看个人配置和需求,本人 ...
- SAP RANG语法
Range 和select-option 的变量是差不多的 sign = 'I' 或 sign = 'E' 是指INCLUED 和 EXCLUDE OPTION = 'EQ' 或其他操作符.. LO ...