Global Average Pooling Layers for Object Localization
For image classification tasks, a common choice for convolutional neural network (CNN) architecture is repeated blocks of convolution and max pooling layers, followed by two or more densely connected layers. The final dense layer has a softmax activation function and a node for each potential object category.
As an example, consider the VGG-16 model architecture, depicted in the figure below.
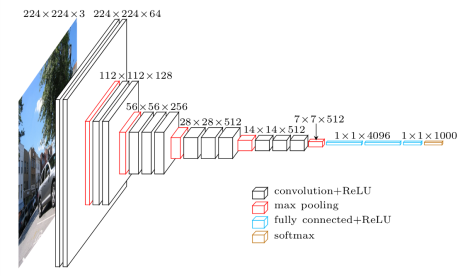
We can summarize the layers of the VGG-16 model by executing the following line of code in the terminal:
python -c 'from keras.applications.vgg16 import VGG16; VGG16().summary()'
Your output should appear as follows:
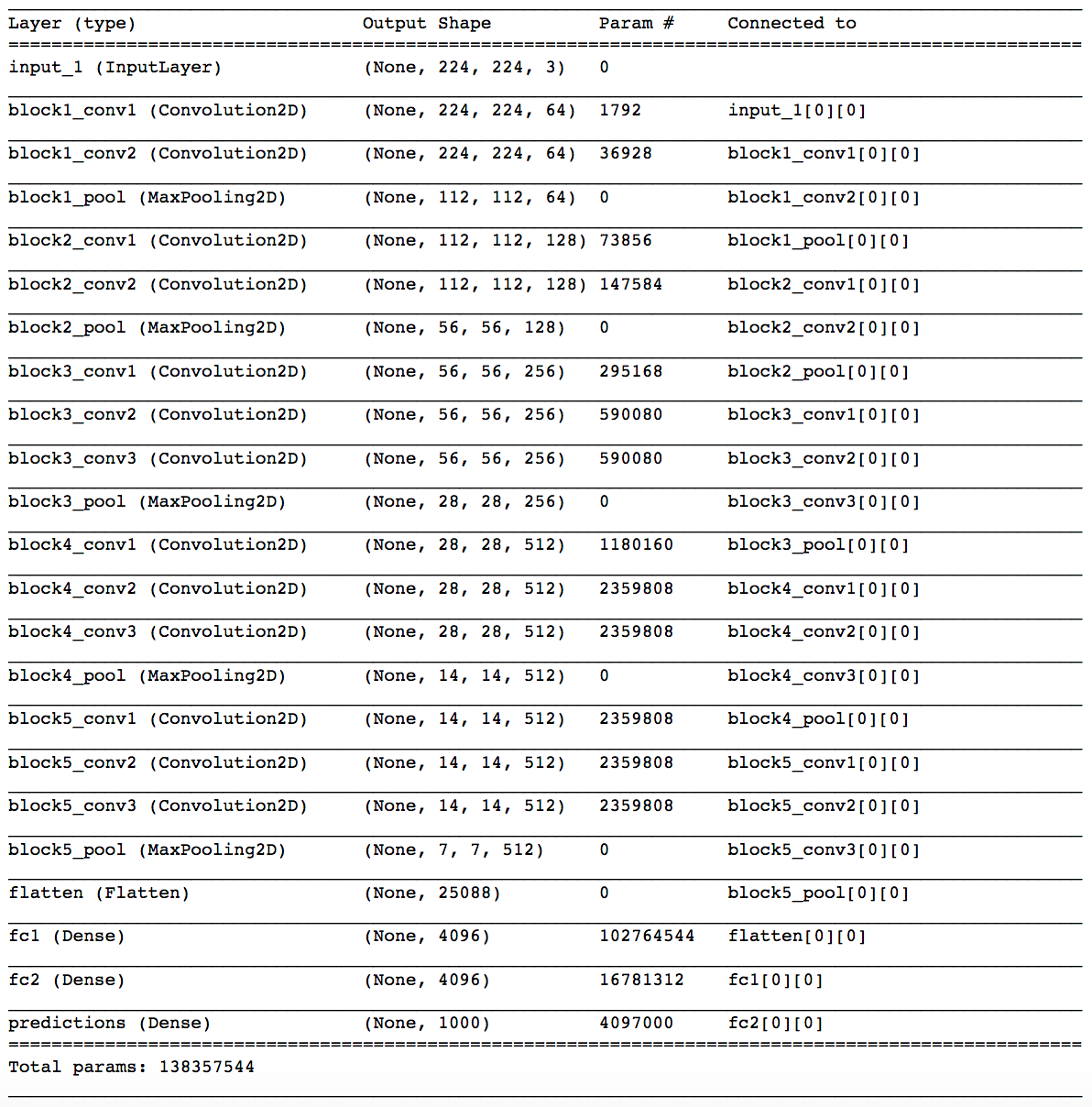
You will notice five blocks of (two to three) convolutional layers followed by a max pooling layer. The final max pooling layer is then flattened and followed by three densely connected layers. Notice that most of the parameters in the model belong to the fully connected layers!
As you can probably imagine, an architecture like this has the risk of overfitting to the training dataset. In practice, dropout layers are used to avoid overfitting.
Global Average Pooling
In the last few years, experts have turned to global average pooling (GAP) layers to minimize overfitting by reducing the total number of parameters in the model. Similar to max pooling layers, GAP layers are used to reduce the spatial dimensions of a three-dimensional tensor. However, GAP layers perform a more extreme type of dimensionality reduction, where a tensor with dimensions h×w×d" style="margin: 0px; padding: 0px; border: 0px; font-style: normal; font-variant: inherit; font-weight: normal; font-stretch: inherit; line-height: normal; font-family: inherit; vertical-align: baseline; display: inline; text-indent: 0px; text-align: left; text-transform: none; letter-spacing: normal; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; position: relative;">h×w×dh×w×d is reduced in size to have dimensions 1×1×d" style="margin: 0px; padding: 0px; border: 0px; font-style: normal; font-variant: inherit; font-weight: normal; font-stretch: inherit; line-height: normal; font-family: inherit; vertical-align: baseline; display: inline; text-indent: 0px; text-align: left; text-transform: none; letter-spacing: normal; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; position: relative;">1×1×d1×1×d. GAP layers reduce each h×w" style="margin: 0px; padding: 0px; border: 0px; font-style: normal; font-variant: inherit; font-weight: normal; font-stretch: inherit; line-height: normal; font-family: inherit; vertical-align: baseline; display: inline; text-indent: 0px; text-align: left; text-transform: none; letter-spacing: normal; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; position: relative;">h×wh×w feature map to a single number by simply taking the average of all hw" style="margin: 0px; padding: 0px; border: 0px; font-style: normal; font-variant: inherit; font-weight: normal; font-stretch: inherit; line-height: normal; font-family: inherit; vertical-align: baseline; display: inline; text-indent: 0px; text-align: left; text-transform: none; letter-spacing: normal; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; position: relative;">hwhw values.
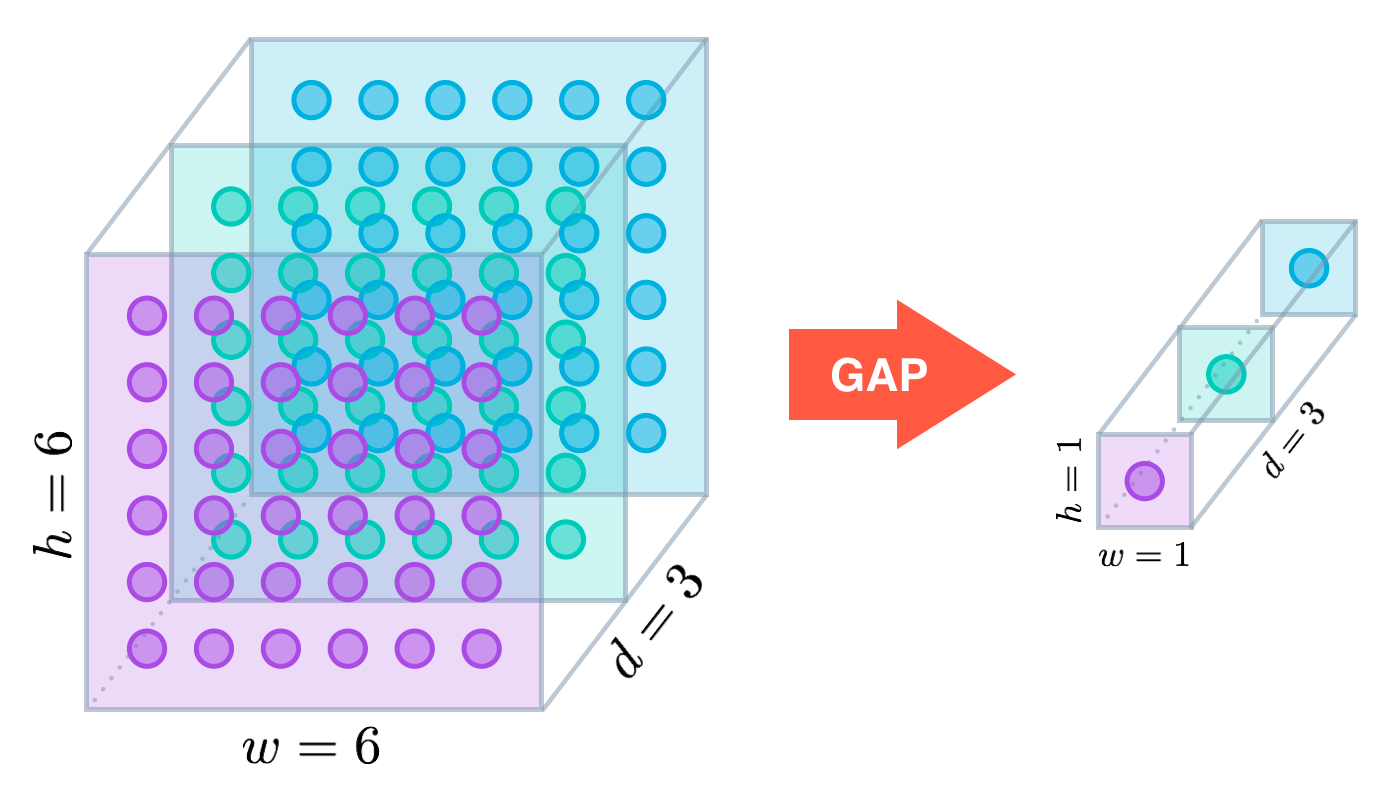
The first paper to propose GAP layers designed an architecture where the final max pooling layer contained one activation map for each image category in the dataset. The max pooling layer was then fed to a GAP layer, which yielded a vector with a single entry for each possible object in the classification task. The authors then applied a softmax activation function to yield the predicted probability of each class. If you peek at the original paper, I especially recommend checking out Section 3.2, titled “Global Average Pooling”.
The ResNet-50 model takes a less extreme approach; instead of getting rid of dense layers altogether, the GAP layer is followed by one densely connected layer with a softmax activation function that yields the predicted object classes.
Object Localization
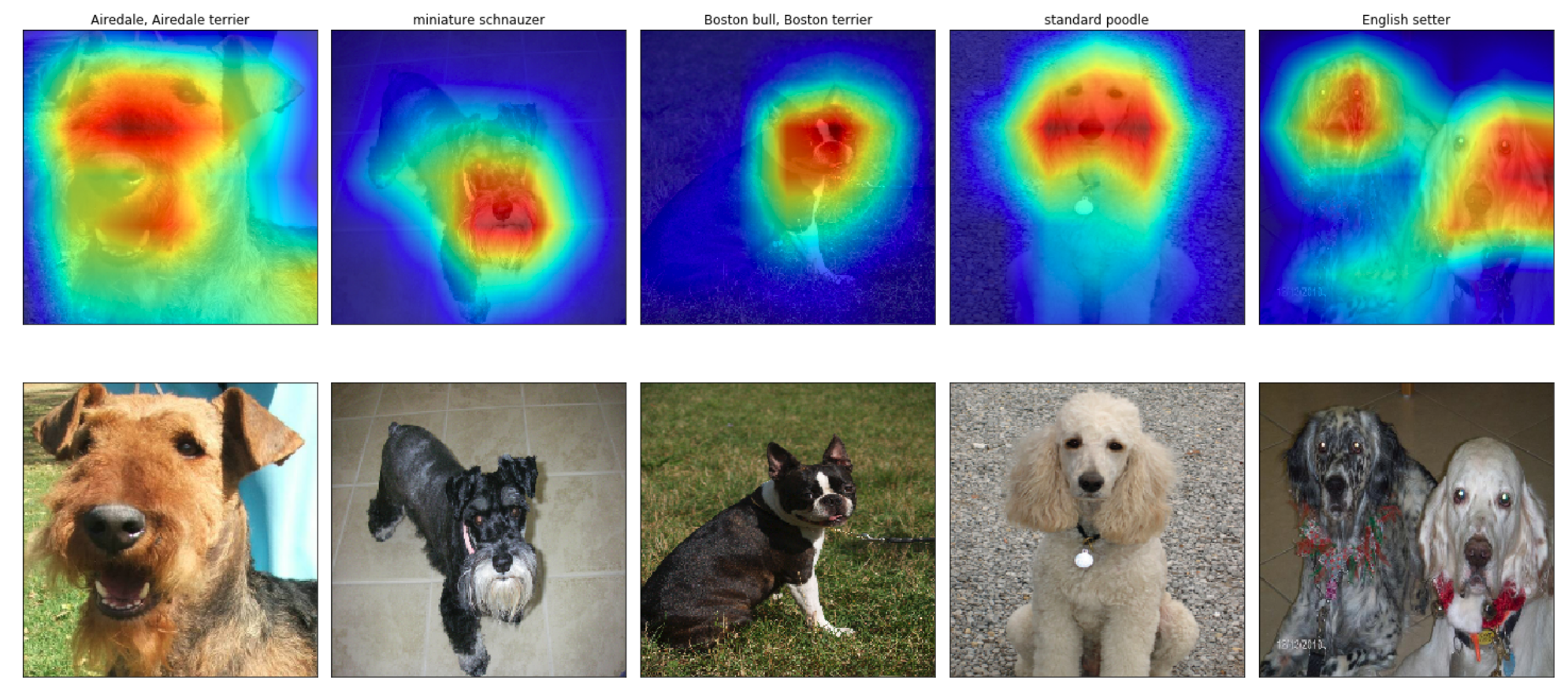
In mid-2016, researchers at MIT demonstrated that CNNs with GAP layers (a.k.a. GAP-CNNs) that have been trained for a classification task can also be used for object localization. That is, a GAP-CNN not only tells us what object is contained in the image - it also tells us where the object is in the image, and through no additional work on our part! The localization is expressed as a heat map (referred to as a class activation map), where the color-coding scheme identifies regions that are relatively important for the GAP-CNN to perform the object identification task. Please check out the YouTube video below for an awesome demo!
In the repository, I have explored the localization ability of the pre-trained ResNet-50 model, using the technique from this paper. The main idea is that each of the activation maps in the final layer preceding the GAP layer acts as a detector for a different pattern in the image, localized in space. To get the class activation map corresponding to an image, we need only to transform these detected patterns to detected objects.
This transformation is done by noticing each node in the GAP layer corresponds to a different activation map, and that the weights connecting the GAP layer to the final dense layer encode each activation map’s contribution to the predicted object class. To obtain the class activation map, we sum the contributions of each of the detected patterns in the activation maps, where detected patterns that are more important to the predicted object class are given more weight.
How the Code Operates
Let’s examine the ResNet-50 architecture by executing the following line of code in the terminal:
python -c 'from keras.applications.resnet50 import ResNet50; ResNet50().summary()'
The final few lines of output should appear as follows (Notice that unlike the VGG-16 model, the majority of the trainable parameters are not located in the fully connected layers at the top of the network!):
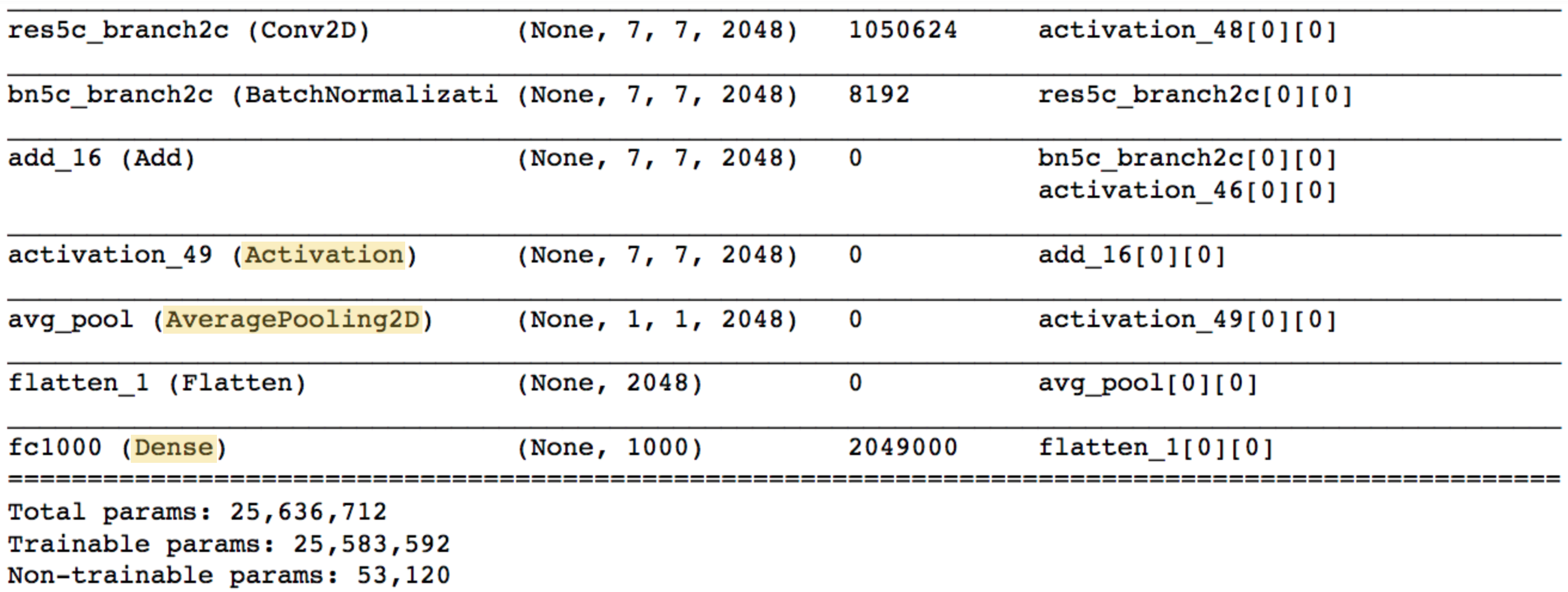
The Activation, AveragePooling2D, and Dense layers towards the end of the network are of the most interest to us. Note that the AveragePooling2D layer is in fact a GAP layer!
We’ll begin with the Activation layer. This layer contains 2048 activation maps, each with dimensions 7×7" style="margin: 0px; padding: 0px; border: 0px; font-style: normal; font-variant: inherit; font-weight: normal; font-stretch: inherit; line-height: normal; font-family: inherit; vertical-align: baseline; display: inline; text-indent: 0px; text-align: left; text-transform: none; letter-spacing: normal; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; position: relative;">7×77×7. Let fk" style="margin: 0px; padding: 0px; border: 0px; font-style: normal; font-variant: inherit; font-weight: normal; font-stretch: inherit; line-height: normal; font-family: inherit; vertical-align: baseline; display: inline; text-indent: 0px; text-align: left; text-transform: none; letter-spacing: normal; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; position: relative;">fkfk represent the k" style="margin: 0px; padding: 0px; border: 0px; font-style: normal; font-variant: inherit; font-weight: normal; font-stretch: inherit; line-height: normal; font-family: inherit; vertical-align: baseline; display: inline; text-indent: 0px; text-align: left; text-transform: none; letter-spacing: normal; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; position: relative;">kk-th activation map, where k∈{1,…,2048}" style="margin: 0px; padding: 0px; border: 0px; font-style: normal; font-variant: inherit; font-weight: normal; font-stretch: inherit; line-height: normal; font-family: inherit; vertical-align: baseline; display: inline; text-indent: 0px; text-align: left; text-transform: none; letter-spacing: normal; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; position: relative;">k∈{1,…,2048}k∈{1,…,2048}.
The following AveragePooling2D GAP layer reduces the size of the preceding layer to (1,1,2048)" style="margin: 0px; padding: 0px; border: 0px; font-style: normal; font-variant: inherit; font-weight: normal; font-stretch: inherit; line-height: normal; font-family: inherit; vertical-align: baseline; display: inline; text-indent: 0px; text-align: left; text-transform: none; letter-spacing: normal; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; position: relative;">(1,1,2048)(1,1,2048) by taking the average of each feature map. The next Flatten layer merely flattens the input, without resulting in any change to the information contained in the previous GAP layer.
The object category predicted by ResNet-50 corresponds to a single node in the final Dense layer; and, this single node is connected to every node in the preceding Flattenlayer. Let wk" style="margin: 0px; padding: 0px; border: 0px; font-style: normal; font-variant: inherit; font-weight: normal; font-stretch: inherit; line-height: normal; font-family: inherit; vertical-align: baseline; display: inline; text-indent: 0px; text-align: left; text-transform: none; letter-spacing: normal; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; position: relative;">wkwk represent the weight connecting the k" style="margin: 0px; padding: 0px; border: 0px; font-style: normal; font-variant: inherit; font-weight: normal; font-stretch: inherit; line-height: normal; font-family: inherit; vertical-align: baseline; display: inline; text-indent: 0px; text-align: left; text-transform: none; letter-spacing: normal; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; position: relative;">kk-th node in the Flatten layer to the output node corresponding to the predicted image category.
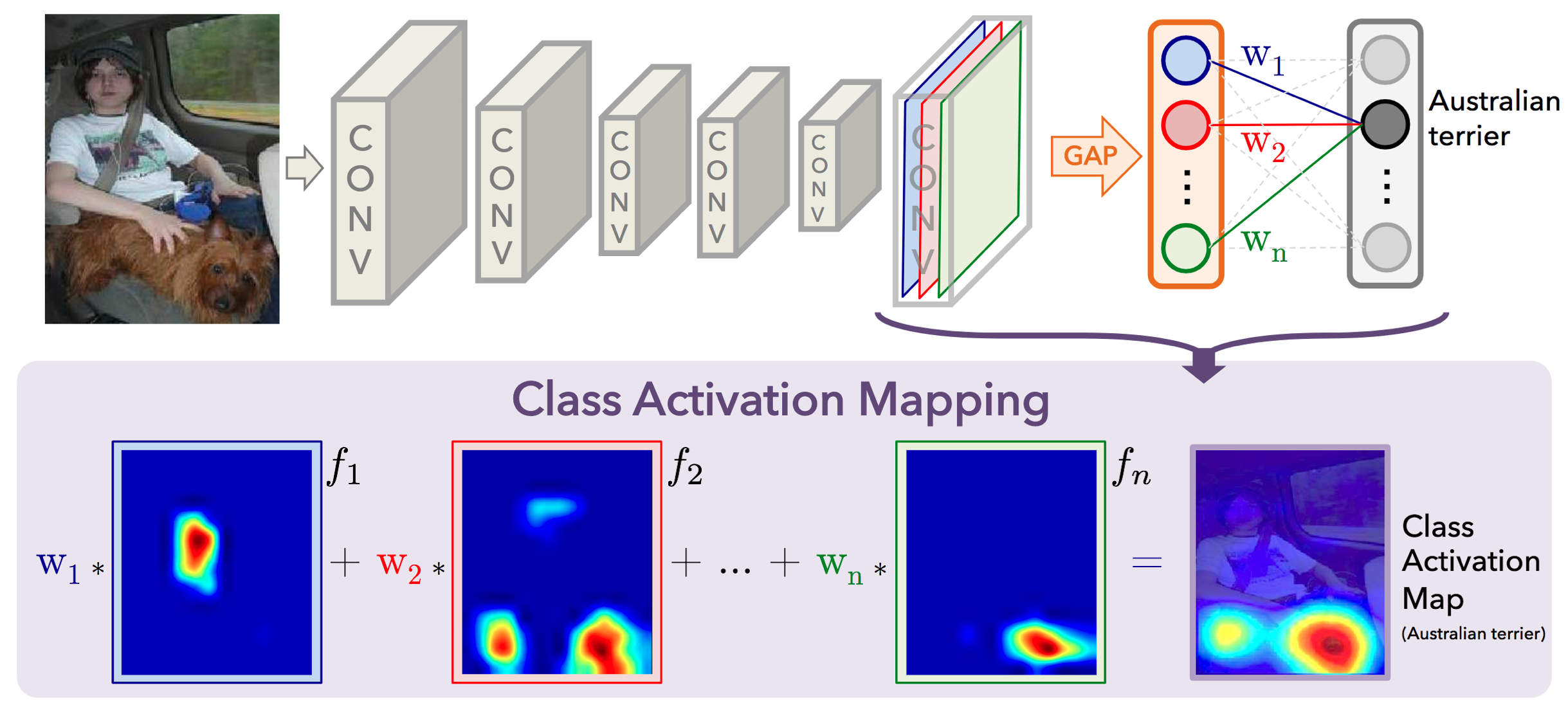
Then, in order to obtain the class activation map, we need only compute the sum
w1⋅f1+w2⋅f2+…+w2048⋅f2048" style="margin: 0px; padding: 0px; border: 0px; font-style: normal; font-variant: inherit; font-weight: normal; font-stretch: inherit; line-height: normal; font-family: inherit; vertical-align: baseline; display: inline; text-indent: 0px; text-align: left; text-transform: none; letter-spacing: normal; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; position: relative;">w1⋅f1+w2⋅f2+…+w2048⋅f2048w1⋅f1+w2⋅f2+…+w2048⋅f2048.
You can plot these class activation maps for any image of your choosing, to explore the localization ability of ResNet-50. Note that in order to permit comparison to the original image, bilinear upsampling is used to resize each activation map to 224×224" style="margin: 0px; padding: 0px; border: 0px; font-style: normal; font-variant: inherit; font-weight: normal; font-stretch: inherit; line-height: normal; font-family: inherit; vertical-align: baseline; display: inline; text-indent: 0px; text-align: left; text-transform: none; letter-spacing: normal; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; position: relative;">224×224224×224. (This results in a class activation map with size 224×224" style="margin: 0px; padding: 0px; border: 0px; font-style: normal; font-variant: inherit; font-weight: normal; font-stretch: inherit; line-height: normal; font-family: inherit; vertical-align: baseline; display: inline; text-indent: 0px; text-align: left; text-transform: none; letter-spacing: normal; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; position: relative;">224×224224×224.)
If you’d like to use this code to do your own object localization, you need only download the repository.
Global Average Pooling Layers for Object Localization的更多相关文章
- 深度学习基础系列(十)| Global Average Pooling是否可以替代全连接层?
Global Average Pooling(简称GAP,全局池化层)技术最早提出是在这篇论文(第3.2节)中,被认为是可以替代全连接层的一种新技术.在keras发布的经典模型中,可以看到不少模型甚至 ...
- 深度拾遗(06) - 1X1卷积/global average pooling
什么是1X1卷积 11的卷积就是对上一层的多个feature channels线性叠加,channel加权平均. 只不过这个组合系数恰好可以看成是一个11的卷积.这种表示的好处是,完全可以回到模型中其 ...
- 深度学习方法(十):卷积神经网络结构变化——Maxout Networks,Network In Network,Global Average Pooling
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld. 技术交流QQ群:433250724,欢迎对算法.技术感兴趣的同学加入. 最近接下来几篇博文会回到神经网络结构 ...
- Network in Network(2013),1x1卷积与Global Average Pooling
目录 写在前面 mlpconv layer实现 Global Average Pooling 网络结构 参考 博客:blog.shinelee.me | 博客园 | CSDN 写在前面 <Net ...
- [CVPR2015] Is object localization for free? – Weakly-supervised learning with convolutional neural networks论文笔记
p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px "Helvetica Neue"; color: #323333 } p. ...
- 论文笔记之:Active Object Localization with Deep Reinforcement Learning
Active Object Localization with Deep Reinforcement Learning ICCV 2015 最近Deep Reinforcement Learning算 ...
- [CVPR2017] Deep Self-Taught Learning for Weakly Supervised Object Localization 论文笔记
http://openaccess.thecvf.com/content_cvpr_2017/papers/Jie_Deep_Self-Taught_Learning_CVPR_2017_paper. ...
- 【37】池化层讲解(Pooling layers)
池化层(Pooling layers) 除了卷积层,卷积网络也经常使用池化层来缩减模型的大小,提高计算速度,同时提高所提取特征的鲁棒性,我们来看一下. 先举一个池化层的例子,然后我们再讨论池化层的 ...
- Spark UDAF实现举例 -- average pooling
目录 1.UDAF定义 2.向量平均(average pooling) 2.1 average的并行化 2.2 代码实现 2.3 使用 参考 1.UDAF定义 spark中的UDF(UserDefin ...
随机推荐
- (转)用Python写堡垒机项目
原文:https://blog.csdn.net/ywq935/article/details/78816860 前言 堡垒机是一种运维安全审计系统.主要的功能是对运维人员的运维操作进行审计和权限控制 ...
- 编译Qt-mingw使用的opencv
set path=D:\dev\IDE\Qt5.7.0\Tools\mingw530_32\bin;%path% cd build_mingw530_32 cmake -G "MinGW M ...
- puppet的使用:puppet的hello world
这个例子完成将master节点上的一个文件放至agent节点上的功能 创建要传输的文件 echo "helloWorld" > /etc/puppet/modules/pup ...
- [转]ASP.NET MVC 4 最佳实践宝典
原文:http://www.cnblogs.com/sonykings/archive/2013/05/30/3107531.html ASP.NET MVC最佳实践 本文档提供了一套旨在帮助创建最佳 ...
- 如何虚拟机里安装Win8操作系统
不多说,直接上干货! Windows Server 2003.2008.2012系统的安装 推荐网址:打开MSDN网站(http://msdn.itellyou.cn ) 关于给电脑换系统,很多人会花 ...
- 在word中优雅地插入代码
PlanetB:带行号 http://www.planetb.ca/syntax-highlight-word Pygments(推荐):不带行号,多种样式可选 http://pygments.o ...
- 面试题28:单链表一次遍历删除从后往前的第n个节点
class Solution { public: ListNode *removeNthFromEnd(ListNode *head, int n) { ListNode* fake = ); fak ...
- 笔记六:python字符串运算与函数
一:学习内容 字符串运算 字符串函数-strip() 字符串函数-大小写互换 字符串函数-字符串对齐 字符串函数-搜索 字符串函数-替换 字符串函数-split切割 字符串函数-连接join 字符串函 ...
- mysql2
第三章 保证数据完整性 3.1 数据完整性的概述:实体完整性 域完整性 引用完整性 用户自定义完整性 3.2 数据完整性的实现 3.2.1 创建非空约束 (在定义列后加上 not n ...
- angular 下载文件
后台直接返回文件即可,以wcf为例:读取目录文件返回,或直接生成文件并返回. public Stream GetCodeSn() { return File.OpenRead("e:\\工作 ...